"How do we do we do go refarming~"
如何理解序列化和反序列化?
序列化: 把 对象 转换为 字节序列 的过程 称为对象的序列化。
反序列化: 把 字节序列 恢复为 对象 的过程 称为对象的反序列化。
这两对反义词从概念上来说并不难理解,但是为什么有事没事来一个序列化、反序列化的操作增加我们这些 "愚钝" 初学者的学习成本呢?序列化、反序列化的应用场景又是在哪里呢?
序列化反序列化场景:
存储数据:当你想把的内存中的 "对象状态" 保存到⼀个 "⽂件中或者存到数据库" 中时。⽹络传输:⽹络直接传输数据,但是⽆法直接传输对象,所以要在"传输前序列化",传输完成后 “反序列化成对象”。
很典型的序列化反序列化的模型,就存在于我们最初学习socket编程时,那一套htons() ntohs()、inet_addr() 、inet_ntoa()……这样做本质上无非强调的是一种格式、规范,降低通信成本和耦合性。
当然还有其他实现序列化的远程数据传输交换格式:
xml json 以及我们本节将要谈到的 protobuf。
一、ProtoBuf初始
(1)ProtoBuf是什么?

protobuf是Google公司提出的一种轻便高效的结构化数据存储格式,常用于结构化数据的序列化,具有语⾔⽆关、平台⽆关、可扩展的序列化结构数据的⽅法,它⽤于(数据)通信协议、数据存储等。
• 语⾔⽆关、平台⽆关:即 ProtoBuf ⽀持 Java、C++、Python 等多种语⾔,⽀持多个平台。• ⾼效:即⽐ XML 更⼩、更快、更为简单。• 扩展性、兼容性好:你可以更新数据结构,⽽不影响和破坏原有的旧程序
(2)ProtoBuf的使用特点
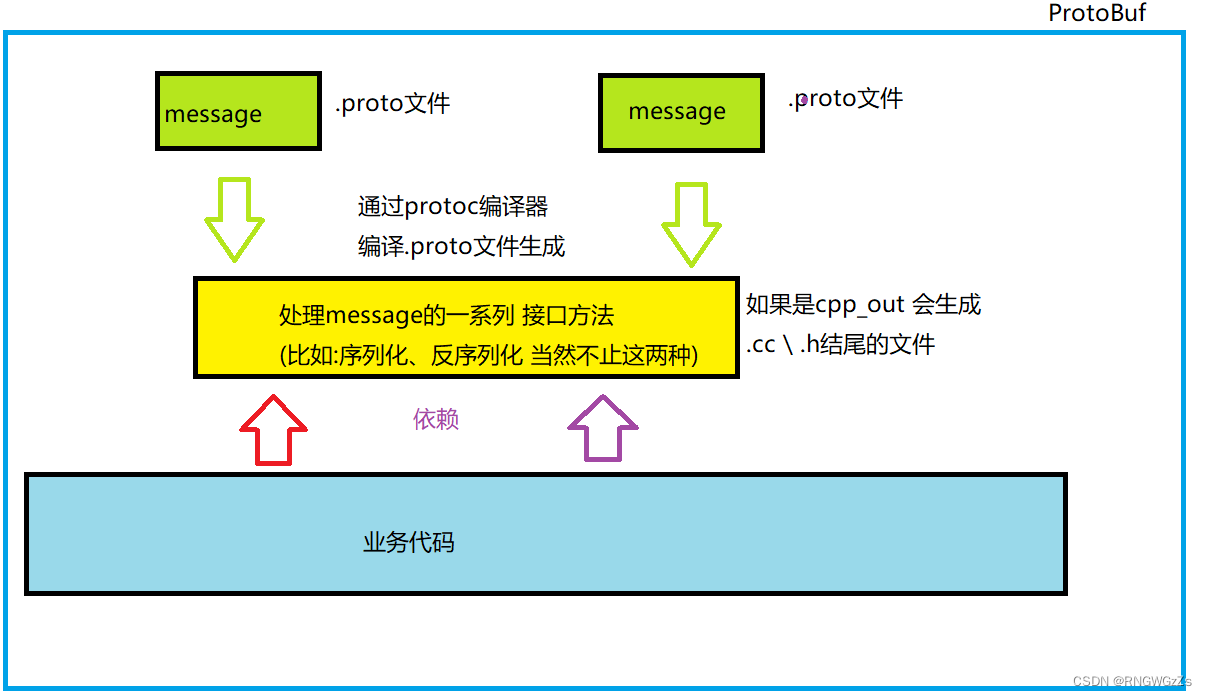
①编写 .proto ⽂件,⽬的是为了定义结构对象(message)及属性内容。
②使⽤ protoc 编译器编译 .proto ⽂件,⽣成⼀系列接⼝代码,存放在新⽣成头⽂件和源⽂件中。
③依赖⽣成的接⼝,将编译⽣成的头⽂件包含进我们的代码中,实现对 .proto ⽂件中定义的字段进⾏设置和获取,和对 message 对象进⾏序列化和反序列化。
总的来说:ProtoBuf 是需要依赖通过编译⽣成的头⽂件和源⽂件来使⽤的。有了这种代码⽣成机制,能够便于开发人员编写那些协议解析的代码了。
(3) Protobuf安装
Windos版:
①下载protobuf编译器:下载链接
 下载完成后,我们对zip进行解压,得到下面的文件。
下载完成后,我们对zip进行解压,得到下面的文件。
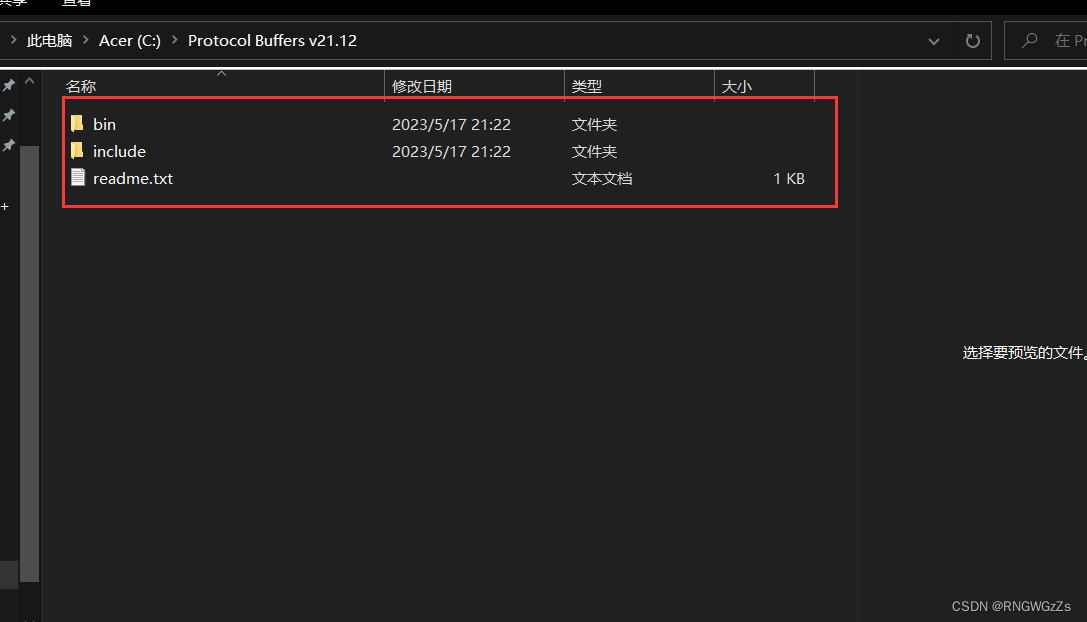
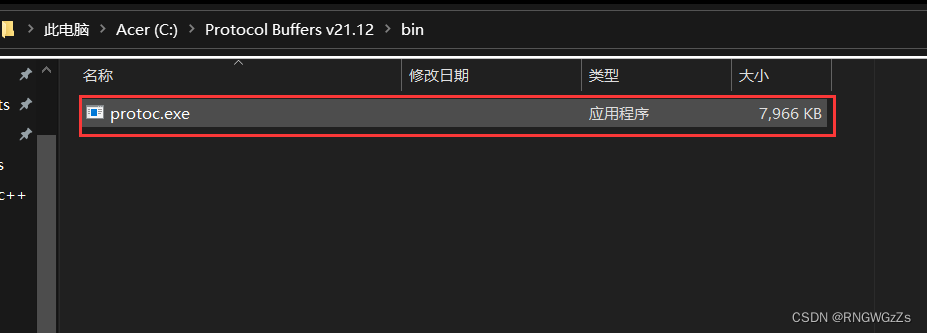
下载之后将压缩包解压到本地⽬录下。解压后的⽂件内包含 bin、include⽂件,以及⼀个
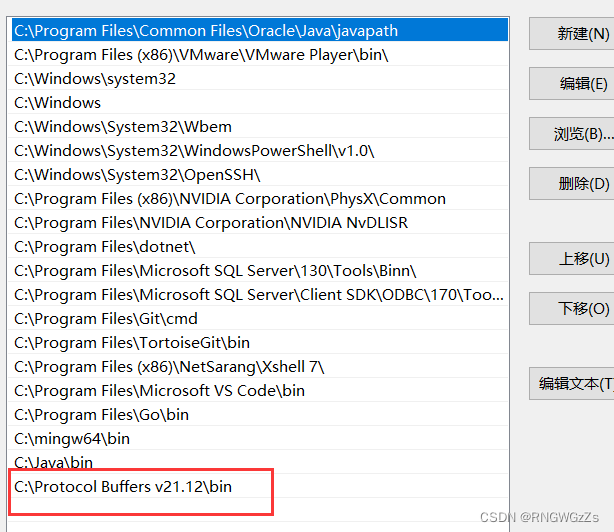
我们此时能够查到该文件,也就说明我们配置成功了。
Linux版:
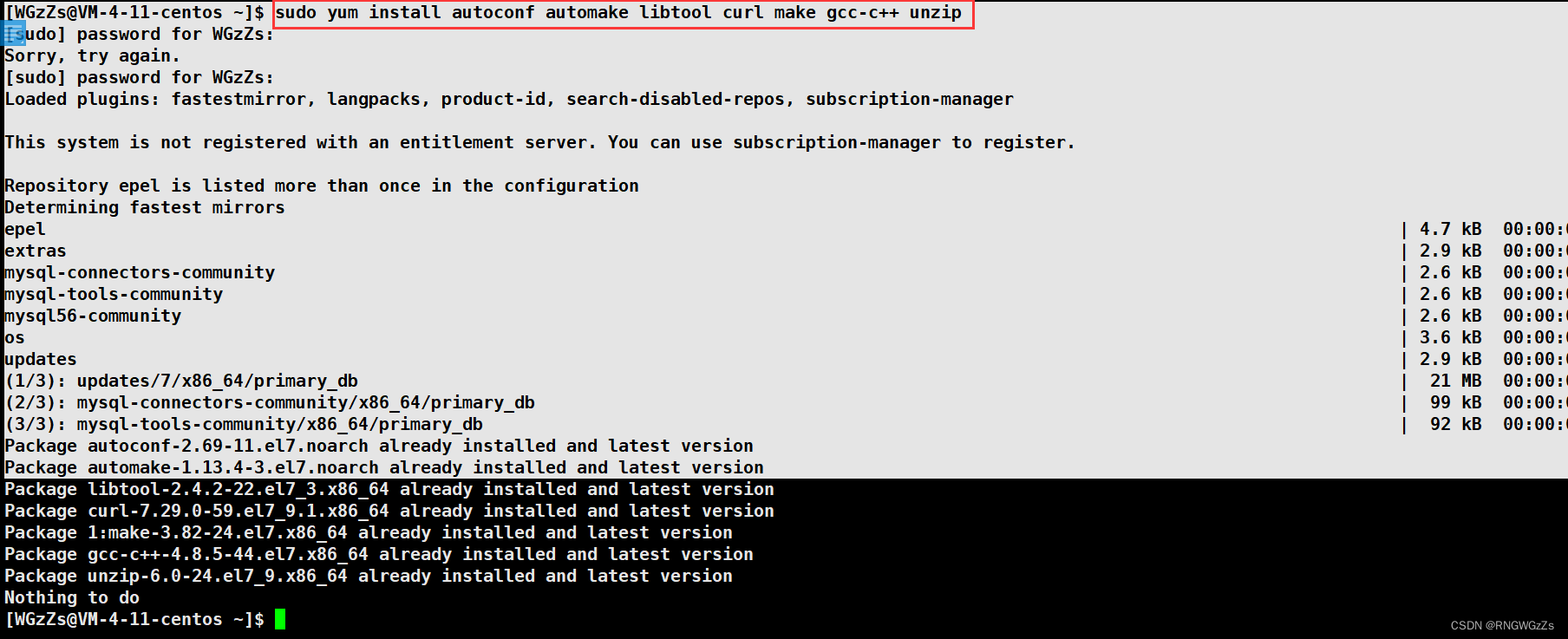
①下载 ProtoBuf依赖库:
CentOS用户:sudo yum install autoconf automake libtool curl make gcc-c++ unzip
② 下载protobuf:
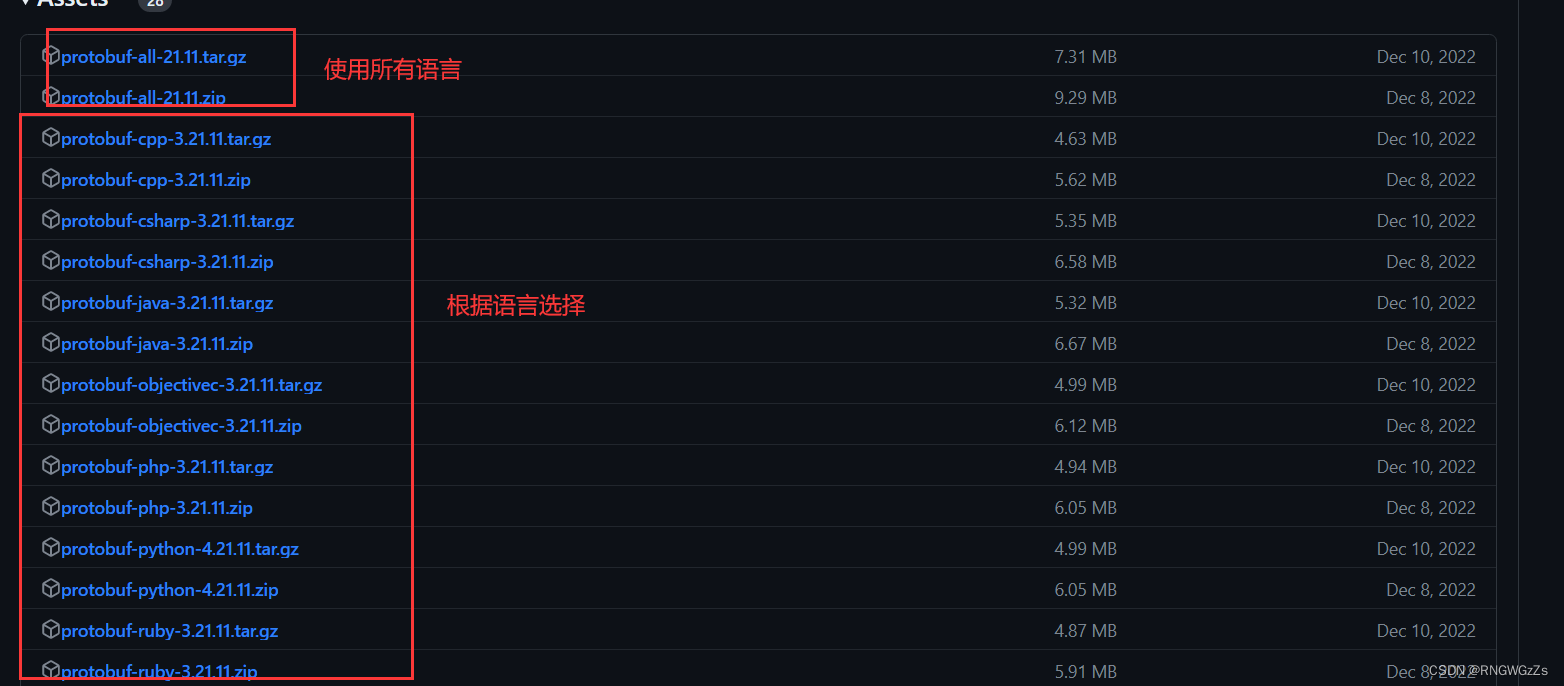
• 如果要在 C++ 下使⽤ ProtoBuf,可以选择cpp.zip ;• 如果要在 JAVA 下使⽤ ProtoBuf,可以选择 java.zip;• 其他语⾔选择对应的链接即可。• 希望⽀持全部语⾔,选择 all.zip 。
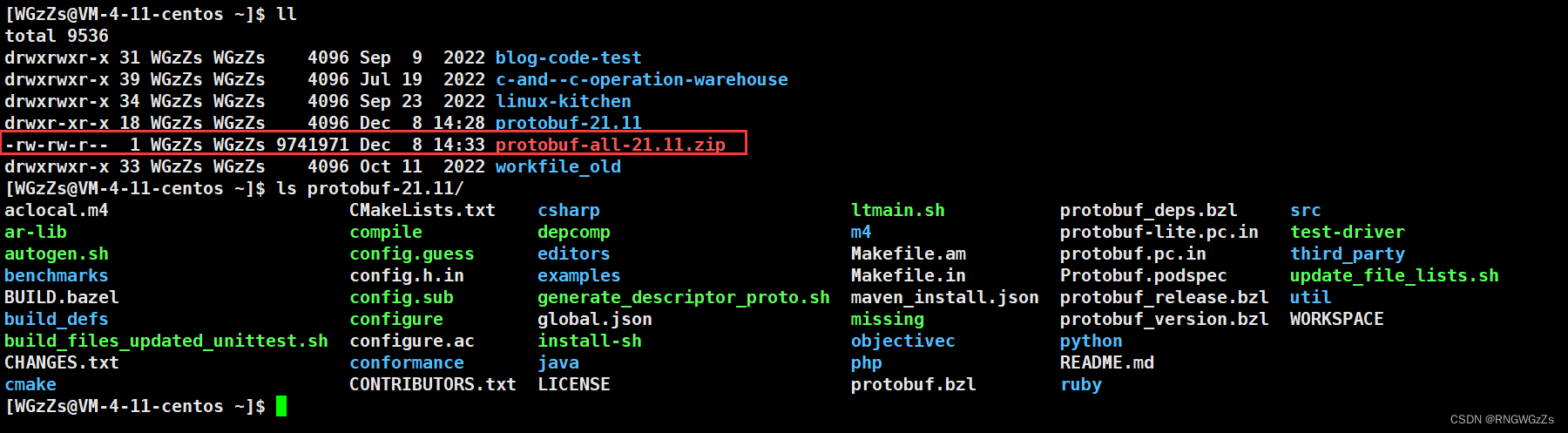
我们可以使用linux命名 wget + 该压缩包下载链接,完成资源的获取,进行unzip解压后得到以下的目录以及文件:
③ 安装 ProtoBuf:
第一步: ./autogen.sh 注:如果下载的具体语言 则不用使用
第二步: ./configure --> 这里的lib 与 bin是分开的
./configure -prefix=/usr/local/protobuf -> 这里的lib 与 bin是一起的。
第三步: make
make checksudo make install 注:依次执行命令,过程会很耗时。

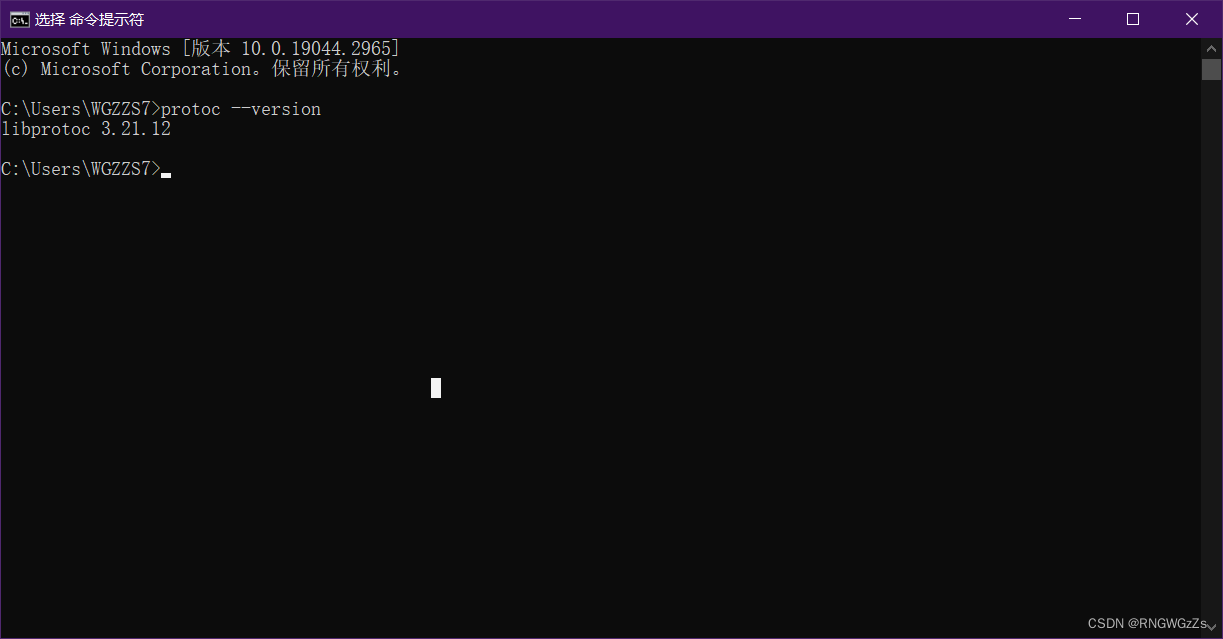
我们再次在命令行输入 protoc --version,检测protobuf编译器的版本。 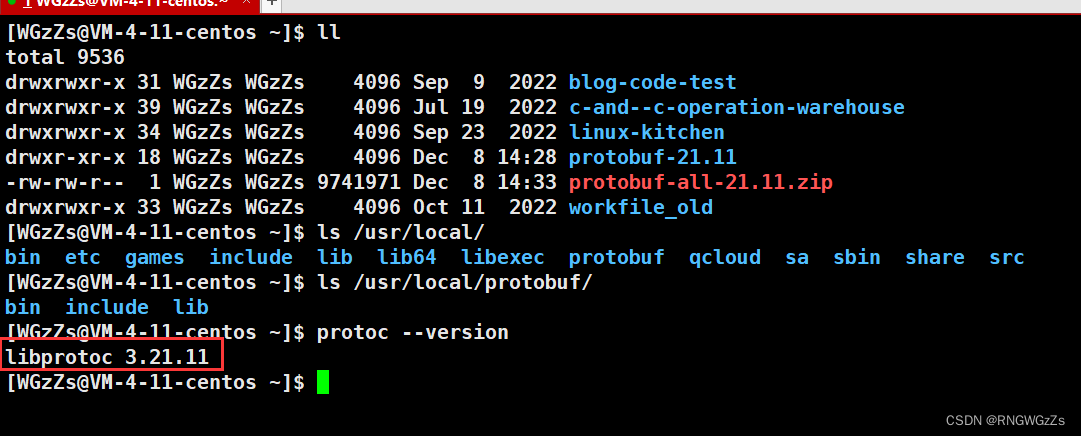
此时,我们也就完成了对protobuf的下载、安装。
本篇也就到此结束了,感谢你的阅读~


![基于Kruskal和Prim的最小生成树算法[matlab版本]](https://img-blog.csdnimg.cn/36093856c9db4002bca97153a1ef744e.png)