前言
本文是该专栏的第26篇,后面会持续分享python的爬虫干货知识,记得关注。
很多时候,在用爬虫采集数据的时候,采集到的源码内容并非我们想要的正确信息,使用正则或者Xpath匹配到的信息也需要我们再次解码才能拿到精准的数据。最近也正是球迷朋友们非常关注卡塔尔世界杯的时候,那直接以世界杯数据为例进行分析,如下:
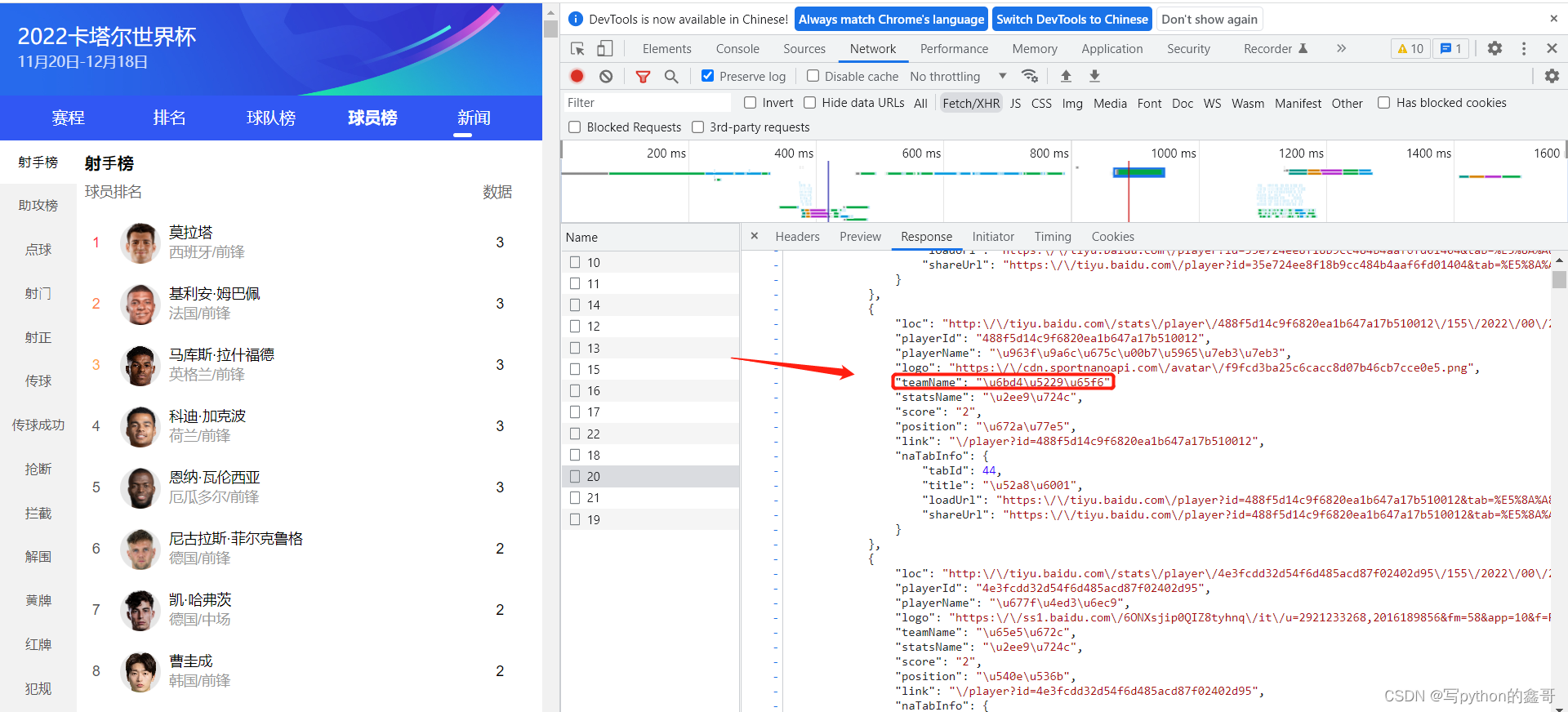
如上面看到的情况,目标数据找到了,但却是一些以\u开头的特殊字符,需要怎么解决呢?
废话不多话,跟着笔者直接往下深入探讨。
正文
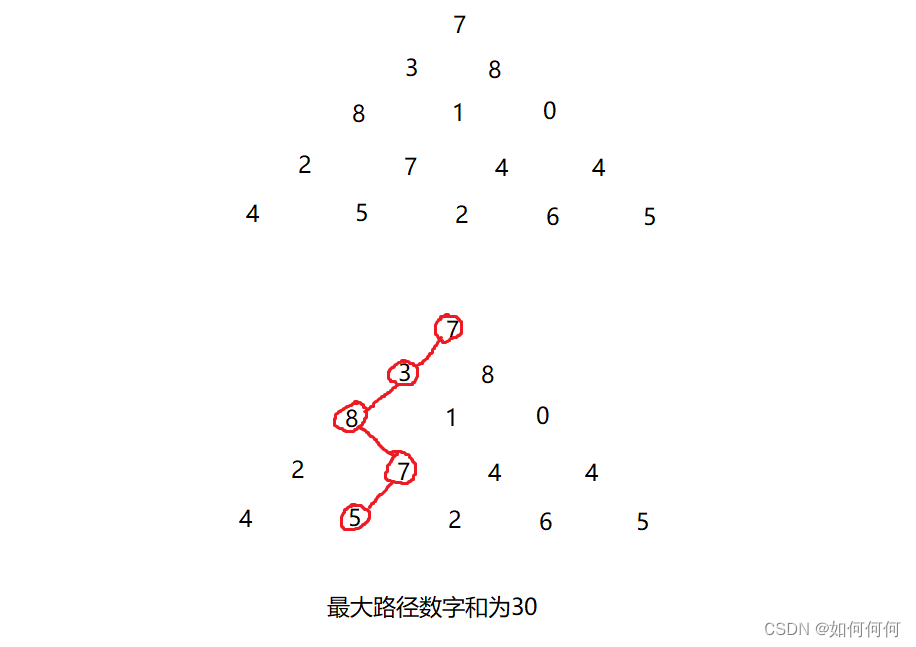
案例:2022卡塔尔世界杯球员榜
需求:解决目标数据解码的问题
打开目标网站并点击刷新,右侧开发者工具并没有看到可疑url,
![[操作系统笔记]基本分段存储管理](https://img-blog.csdnimg.cn/7a92a4177f8145b0b7c3772d121742b5.png)







![[附源码]计算机毕业设计springboot学生宿舍维修管理系统](https://img-blog.csdnimg.cn/5e6c1d0ef6fa47bca850f1e9a7551e24.png)