Stage 1: 目标是 使用QPN 生成 Occupancy Field
读取 需要读取 pseudo 的 vox_path
实际的 test 发生在 lmsnet.py 这个文件
input :25625632 的 pseudo point
output: 12812816 的 Occupancy Grid
代码中 实际inference 的输入是 img_metas[0]["pseudo_pc"]
-
因此,首先需要借助 MobileStereoNet 生成 disparity 图
-
然后借助 disparity 生成 lidar 的bin
python utils/depth2lidar.py --calib_dir
./kitti360_images/01/image_2/calib --depth_dir
./mobilestereonet/depths_kitti/sequences/01/ --save_dir ./lidar
- 再使用 lidar2voxel 的脚本,将lidar 生成的 pointcloud 转化成 pseudo_pc, 然后网络实际输入的是这个 pseudo_pc 这个文件,输出的是 12812816 的 Voxel。 即QPN 网络的输出
Stage 2: 生成一个 Semantic Vox field
Input:
- 每一个 sequence 的 pose.txt
还不知道这个 pose.txt 表示的是什么意思,如何在代码中使用;单张图像用不上
- 每一个 sequence 的 calib.txt
读取每一个 sequence 的 内参矩阵 P2 和 Tr。
在Semantic Kitti 的数据集当中,Tr 表示 Rigid transform from Velodyne coord to reference camera coord。 即表示从激光Lidar 的坐标系 到图像坐标系的 刚体转换。
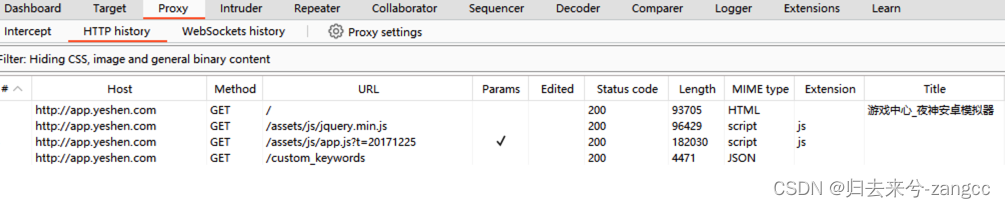
3. 实际上 读入的 Scan 数据在代码当中使用一个 dict 去表示:
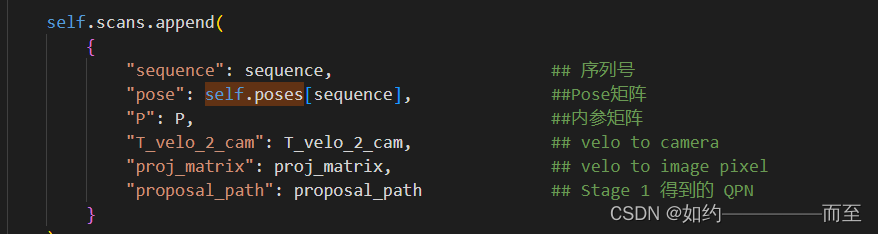
4. 在DataLoader 加载的过程当中 去构建 meta_info:
4. 构建 meta之后 去 Read 出image
image 的 shape 是 ([1, 3, 370, 1220]). batch_size = 1; channel =3.
5. 在 Dataloader 的过程当中,最后返回的是 data_info

6. 在 Dataloader 的过程当中,关于外参 pose.txt 的使用进行 debug
目前的理解: Voxformer 可以对于一帧图像进行 3D Voxel 的 进行生成,但是 如果当 batch_size 不为1的话,其他帧生成的 Voxel 的3D 坐标应该都是相对与 target 帧来进行生成的。
因此,在Dataset 中读取的 pose.txt 实际上是计算其他帧对应的 lidar 坐标系 转化到 target image 的 camera 坐标系。当如果从一张图像进行 infer 的时候自然不需要 pose.txt 提供的外参信息。
在 cfg 文件加载的时候, 指定了在**temporal 参数 来给定 一个序列的图像当中图像的 ref 帧**,也就是好几个image 生成的 Voxel 映射到 ref image 上面去。 造成一种动态前行的 video 的效果。
在Kitti360 Datasets 上去 inference 一张图像的 Semantic Voxel Field
- Input: 图像 image
- calib.txt 给定 相机内参 P2 和 Lidar 坐标系 到 Cam 坐标系的 Transform
- QPN 从 Stage 1 输出





![[网鼎杯 2020 青龙组]jocker 题解](https://img-blog.csdnimg.cn/cecf98eac1cf43a0a4ce46c9f41af6a1.png)