本文对国内外公司、科研机构等组织开源的 LLM 进行了全面的整理。
Large Language Model (LLM) 即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。
所谓"语言模型",就是只用来处理语言文字(或者符号体系)的 AI 模型,发现其中的规律,可以根据提示 (prompt),自动生成符合这些规律的内容。
LLM 通常基于神经网络模型,使用大规模的语料库进行训练,比如使用互联网上的海量文本数据。这些模型通常拥有数十亿到数万亿个参数,能够处理各种自然语言处理任务,如自然语言生成、文本分类、文本摘要、机器翻译、语音识别等。
LLaMA
由 Meta(Facebook)公司发布,是一套优秀的预训练模型,现在很多LLM都是基于此模型。
此模型的特点是参数体量小(7billion/13billion/33billion/65billion),而训练token多(1.2Trillion),并且仅使用公开可用的数据集进行训练。
参数小使得模型可用较少的资源就可以完成相关的微调和使用,从而推动了 alpaca 等模型的诞生。
各模型在“常识推理”任务中的零样本(Zero-shot)性能表现:

LLaMA :https://github.com/facebookresearch/llama
Alpaca
斯坦福团队基于上面的 LLaMA 7B 和 Text-davinci-003 训练得来,过程如下:

可以看到, Alpaca 在 LLaMA 的基础上仅仅使用了 Self-Instruct 框架和Text-davinci-003 训练出来的 52k 数据,就训练出了处理一个优秀的模型,这里可以极大的体现出指令微调的威力(fine-tuned)。
Alpaca:https://crfm.stanford.edu/2023/03/13/alpaca.html
Self-Instruct
Self-Instruct 非常优秀,这里也专门介绍一下:它使用了几乎不需要人工标注的方法,实现了预训练语言模型与指令对齐。它很好的解决 ChatGPT 三步训练中两步需要人工参与的问题,这就大大降低了门槛。
ChatGPT 三步如下图:

这里简单介绍下Self-Instruct的过程:
1. 初始设定一个手动编写的指令任务的种子池(比如 175 个),用于指导整个生成。
2. 提示模型生成新任务的指令(取随机 8 条指令用来提示,如果有新的指令已加入池子,其中 2 条会取非初始种子池中的指令)
3. 任务分类
4. 提示模型为新任务生成指令
5. 过滤掉重复(0.7 关联度以上)和无效(包含图片等不合适的),合格的加入任务池
6. 多次重复以上过程

Self-Instruct :《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》https://arxiv.org/pdf/2212.10560.pdf
Vicuna
Vicuna是伯克利主导的团队训练出来的模型,基于 Alpaca 发展而来。从当前来看,可能是开源里和ChatGPT最接近(上面有提到当前在Arena 评测上分数排名第一),而 13b 版本训练成本仅 300 刀。
团队训练的数据集主要是来从自http://ShareGPT.com 上爬取用户分享的对话,并过滤掉不合适的和低质量的,最后留下了大概 70K 对话样本;然后增强了 Alpaca 提供的训练脚本,有针对性的加强了多轮对话和长序列。
下图是他们的项目过程(数据、训练、demo 服务、效果评价):

其中效果评价部分,团队是将每个模型的输出组合成每个问题的单个提示,将提示发送到 GPT-4,由 GPT-4 评估哪个模型提供更好的响应。
下图是团队总结的几个模型的对比情况:

Mini GPT-4
由沙特大学推出的支持视觉信息的多模态 LLM,主要是基于BLIP-2+上文提到的Vicuma+一层映射层。
团队在 4 张 A100 上基于 5 百万对齐的【图片-文本对】数据训练了 10 个小时,然后团队再用模型本身和 chatgpt 结合起来去训练了 3500 对高质量的【图片-文本对】数据,然后在单 A100 上进行了 7 分钟的微调(finetuning )。
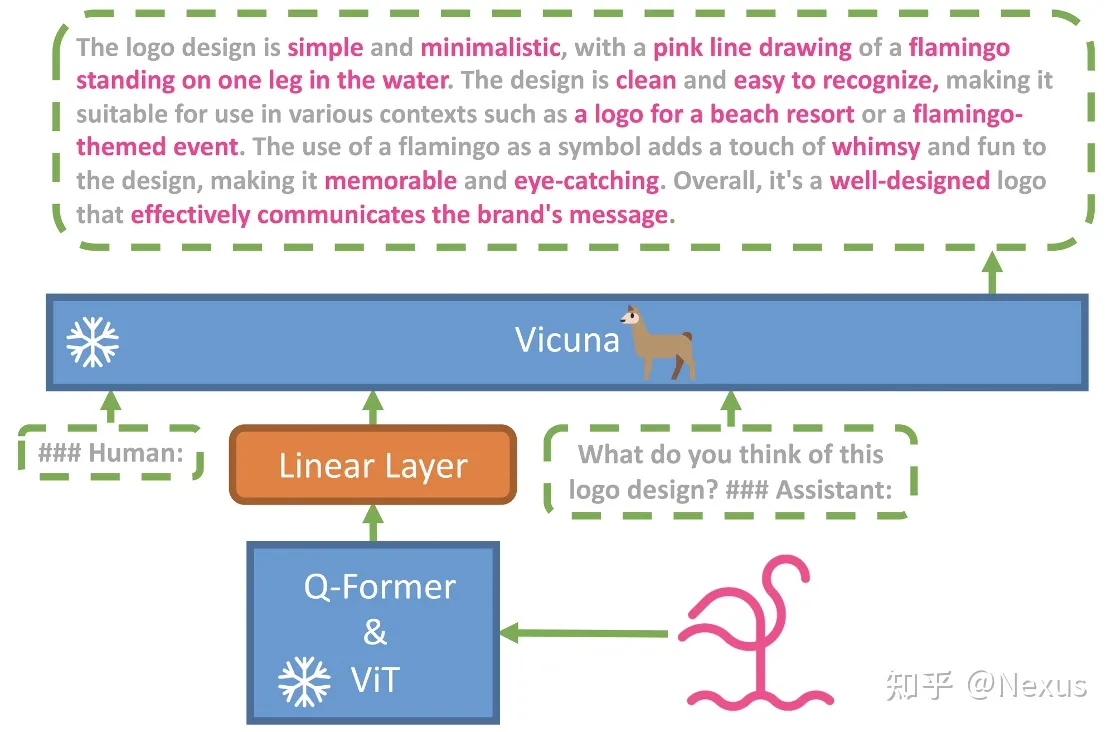
此模型可以在线使用体验,也可以自行部署,相关数据集都已经开源,根据实操经验,在云服务上进行部署消耗并不大,主要时间花费是下载(几十 G 数据)。