本文内容节选自 Paxi.ai 文章分享,Paxi.ai是一个基于GPT-4打造的帮助用户快速使用AI的AI工具,对内容感兴趣的朋友可以上他们官网查看。
从OpenAI发布GPT以来,AI尤其以LLM为代表的项目发展迅速,相信大家已经了解到大语言模型的魅力了,我们基于大语言模型的能力可以开发很多应用。提到这些应用,那么很大概率离不开向量数据库了。向量数据库是大语言模型计算句子相关性中最重要的环节,市面上的向量数据库也随着AI的火热如雨后春笋般出现,例如有:Annoy, AtlasDB, AnalyticDB, DeepLake, DocArrayHnswSearch, DocArrayInMemorySearch, FAISS, LanceDB, Milvus, MyScale, OpenSearch, PGVector, SuperbaseVectorStore, Tair, Waviate, Qdrant, Pincone, Chroma, ElasticSearch, Redis, Typesense, Zilliz…
这些里面有一些已经是很成熟的商业产品了,还有的只是Github上的社区小项目,我们认真研究后挑选其中最具代表性的5款产品进行了调研。按介绍顺序分别是: Pincone, Qdrant, Waviate, Milvus, Chroma。今天先介绍Pincone

Pincone
Pincone 可以算是当前最火的商业向量数据库产品了,它最近获得了1亿美元的B轮融资,估值达到7.5 亿美元,它还是OpenAI官方首推的向量数据库。
他们公司2021年才推出自己的向量数据库产品,可以算一个很年轻的公司。目标是为大语言模型带来长期记忆功能。付费的客户有 Shopify, Gong, HubSpot, Paxi 和 Zapier 等。
它的逻辑如下:
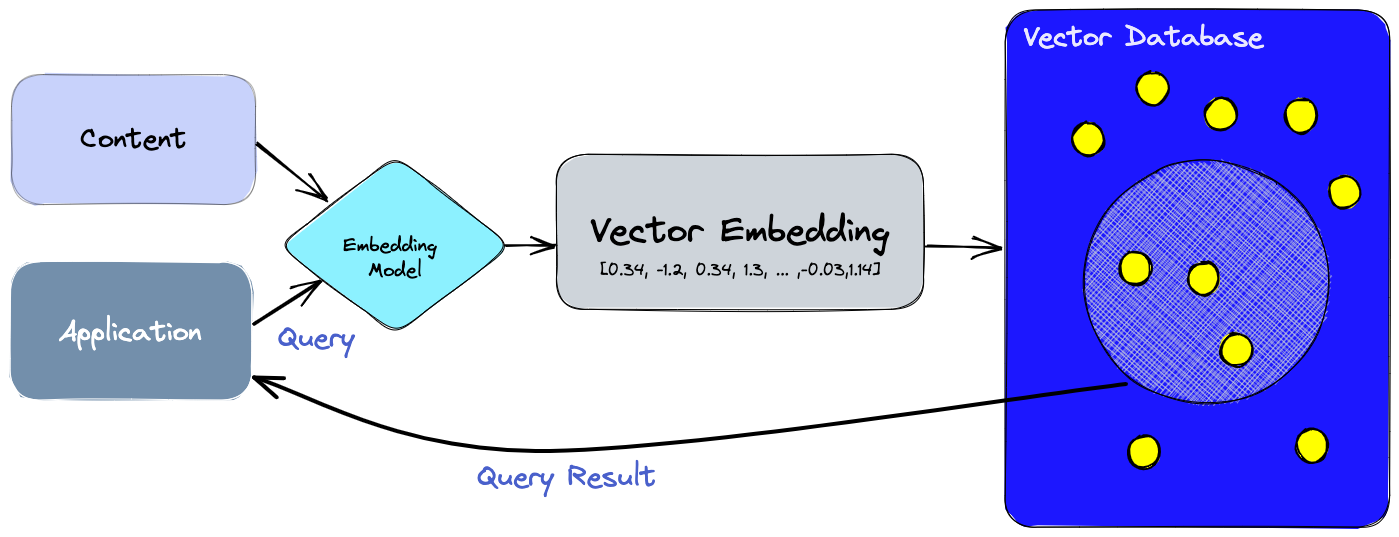
当用户输入文本内容后,通过嵌入模型计算出文本对应的向量数据。将向量数据带入向量数据库利用距离函数计算出高维空间中距离相似的内容,也就是我们常说的语义搜索。最后将结果返回给应用层处理后反馈给用户。
Pincone有以下几个特点
- 高性能搜索
Pincone只提供了网络部署,通过高性能服务器搭配自研索引查找算法,可以快速的计算内容之间的相似性,即便有数十亿数量级的内容利用Pincone也能低延迟响应,给用户提供最好的体验。
- 提供容易上手API
提供Python、NodeJS、RestFulAPI,轻松对接数据管理。
- 全功能管理
通过独特的索引生成算法,对于添加、编辑或删除的数据能进行索引实时更新,立即生效。通过提供的WebUI终端实时就能看到数据变动。另外将矢量数据和元数据进行绑定结合,快速找到对应内容。
- 轻松扩容
完全托管在 AWS 或 Google 的高性能计算平台上,自动扩容,无需担心架构或算法,也无需安排专业运维团队,这一切都自动帮你搞定。一开始提供免费容量,只有超过免费容量后按使用量收费,可根据产品运营状态随时调整成本。
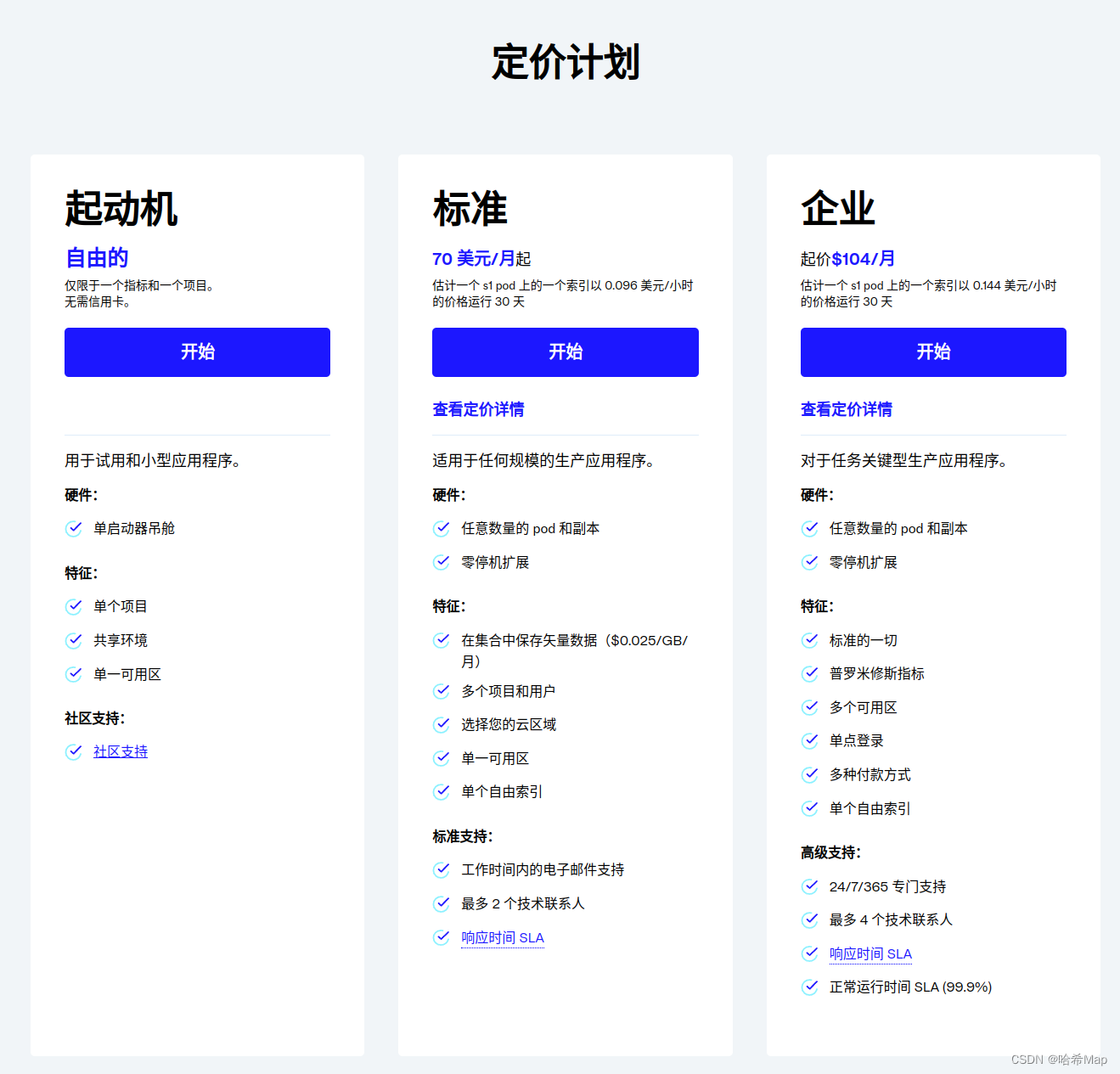
Pincone能干什么?
当你逐步了解到ChatGPT能力后,你就会迫切希望它能有长期记忆能力,那么向量数据库就是做这个事的。利用向量数据库后可以实现很多功能,例如:
- 搜索: 包括语义搜索,产品搜索,多模态搜索和问答。
- 生成: 包括聊天机器人、文本生成、图像生成等。
- 安全: 异常检测、欺诈识别、机器人/威胁检测、身份验证。
- 个性化: 建议、排名、广告、候补等。
- 分析与机器学习: 数据标注、模型训练、分子搜索、生成式人工智能。
- 数据管理: 模式匹配、去重、分组、标记。
目前AI产品80%都需要用到向量数据库提供的这些能力。
如何接入Pincone
首先打开官网: Vector Database for Vector Search | Pinecone, 点击右上角“免费注册”
 填入邮箱密码后进入WebUI管理后台。
填入邮箱密码后进入WebUI管理后台。
这里左边一共有5个功能,分别是:
项目:
免费帐号只能创建一个默认工程,与其他用户共享设备硬件性能。做测试调试完全够用了,如果想商业化应用最好还是付费。
索引:
这里的索引可以理解为传统的数据库概念,一个索引即一个数据库,另外向量数据库没有表的概念,因此这里一个索引也是一张表,稍后会介绍如何在一个索引里实现多个表的能力。
点击索引后会让你创建一个: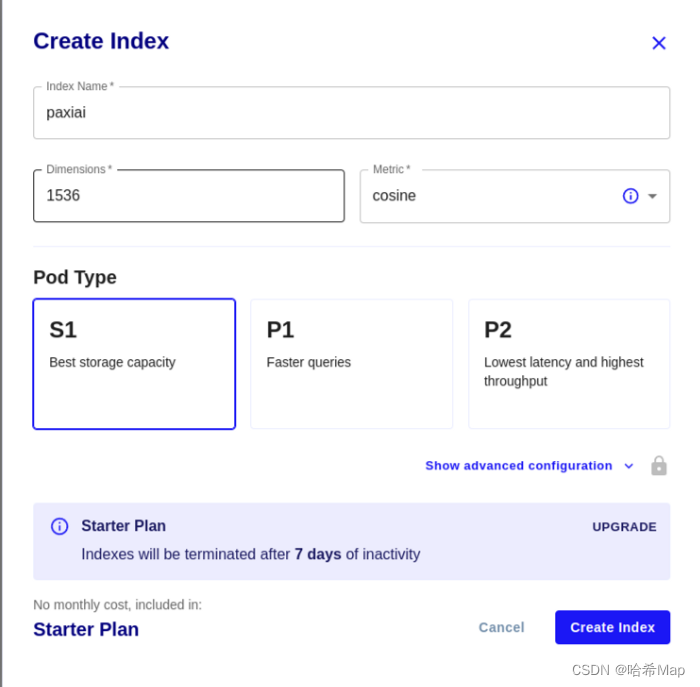
这里的索引名填数据库名字,也可以填项目名,例如”paxi”,他会要求全小写。
维度这里填你的嵌入数据维度,如果使用chatGPT那么就是1536维,每个模型具体维度不同,需要仔细研究你使用的模型。
距离函数可以根据你的需要勾选,默认选择余弦函数。
Pod的类型根据自己需要选择。
S1: 高存储
P1: 高性能
P2: 顶配
这里有点需要注意的是:
免费用户如果数据库7天内没有交互就会被清空
创建成功后就是这个样子了。
集合:
集合是索引数据库的快照。
创建集合非常简单,给它起个名字就行
快照可以理解为当时的索引备份,用于任何时候恢复数据用,也可以当作各个版本的数据备份。免费用户只能创建一个集合。
APIKey:
使用Python、NodeJS、RestFul API对数据库进行增删查改工作。这里不演示APIKey的用法,具体示例可以参考官方文档。 Overview
成员:
邀请其他成员共同管理项目。
数据管理
数据管理部分介绍如何使用WebUI对数据进行管理,其实它的API也相当简单,就是基础的RestFulAPI调用,这里不做介绍。
这里分别显示了索引名字,索引网址,配置环境,距离算法,Pod类型,维度,使用情况等。
 索引部分显示了当前的总向量数,命名空间,和各命名空间的索引数。这里的命名空间就可以对应到传统数据库里的表概念了。
索引部分显示了当前的总向量数,命名空间,和各命名空间的索引数。这里的命名空间就可以对应到传统数据库里的表概念了。
度量部分用来查看数据使用情况。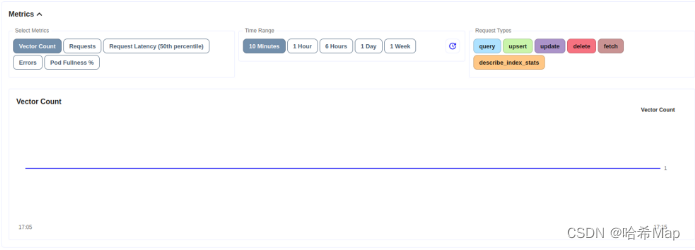
最下面的部分就是对数据库进行操作了
UPSERT 增加或修改数据
QUERY 查询数据
UPDATE 修改数据
FETCH 获取数据
DELETE 删除数据
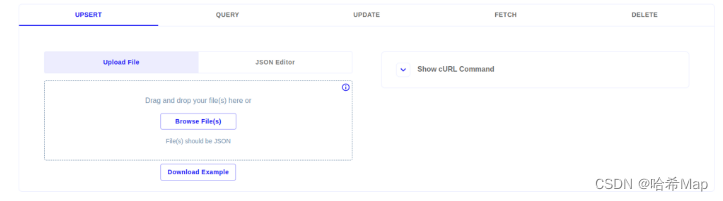
这些操作都支持文件批量操作,Json编辑器提交,也支持cURL调用。
值得一提的是,文件批量操作对中文不友好,上传中文内容会变成乱码,JSON编辑器和cURL操作没这个问题
总结
坦率的说,Pincone确实是一款简单易上手对初学者友好的向量数据库。其提供的免费空间也够大多数场景使用了,方便的API,简单的WebUI,无需部署,自动扩容等都做的非常易用。唯一的缺点是相对其他产品,费用起点较高。对于刚接触向量数据库的伙伴来说,强烈推荐!