Zookeeper
- 1. Zookeeper介绍
- 1.1 什么是Zookeeper
- 1.2 Zookeeper的应用场景
- 2. 搭建ZooKeeper服务器
- 2.1 下载安装包
- 2.2 配置文件
- 2.3 启动测试
- 3. Zookeeper内部的数据模型
- 3.1 zk如何保存数据?
- 3.2 zk中的znode是什么样的数据结构
- 3.3 zk中节点znode的类型
- 3.4 zk的数据持久化
- 4. Zookeeper客户端(zkCli)的使用
- 4.1 多节点类型创建
- 4.2 查询节点
- 4.3 删除节点
- 4.4 权限设置
- 5. kazoo客户端的使用(python)
- 5.1 基本操作
- 5.2 创建节点
- 5.3 删除节点
- 5.4 更改节点
- 5.5 一键清空zookeeper
- 5.6 watches 事件
- 6. zk实现分布式锁
- 6.1 zk中锁的种类:
- 6.2 zk如何上读锁
- 6.3 zk如何上写锁
- 6.4 羊群效应
- 7. zk的watch机制
- 7.1 Watch机制介绍
- 7.2 zkCli客户端使用Watch
- 8. Zookeeper集群实战
- 8.1 Zookeeper集群角色
- 8.2 集群搭建
- 8.3 连接Zookeeper集群
- 9. ZAB协议
- 9.1 什么是ZAB协议
- 9.2 ZAB协议定义的四种节点状态
- 9.3 集群上线Leader选举过程
- 9.4 崩溃恢复时的Leader选举
- 9.5 主从服务器之间的数据同步
- 9.6 Zookeeper中的NIO与BIO的应用
- 10. CAP理论
- 10.1 CAP理论
- 10.2 BASE理论
- 10.3 Zookeeper追求的一致性

1. Zookeeper介绍
官网 https://zookeeper.apache.org/
1.1 什么是Zookeeper
Zookeeper 是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程,ZooKeeper通过其简单的架构和API解决了这个问题。ZooKeeper 能让开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
1.2 Zookeeper的应用场景
-
分布式协调组件
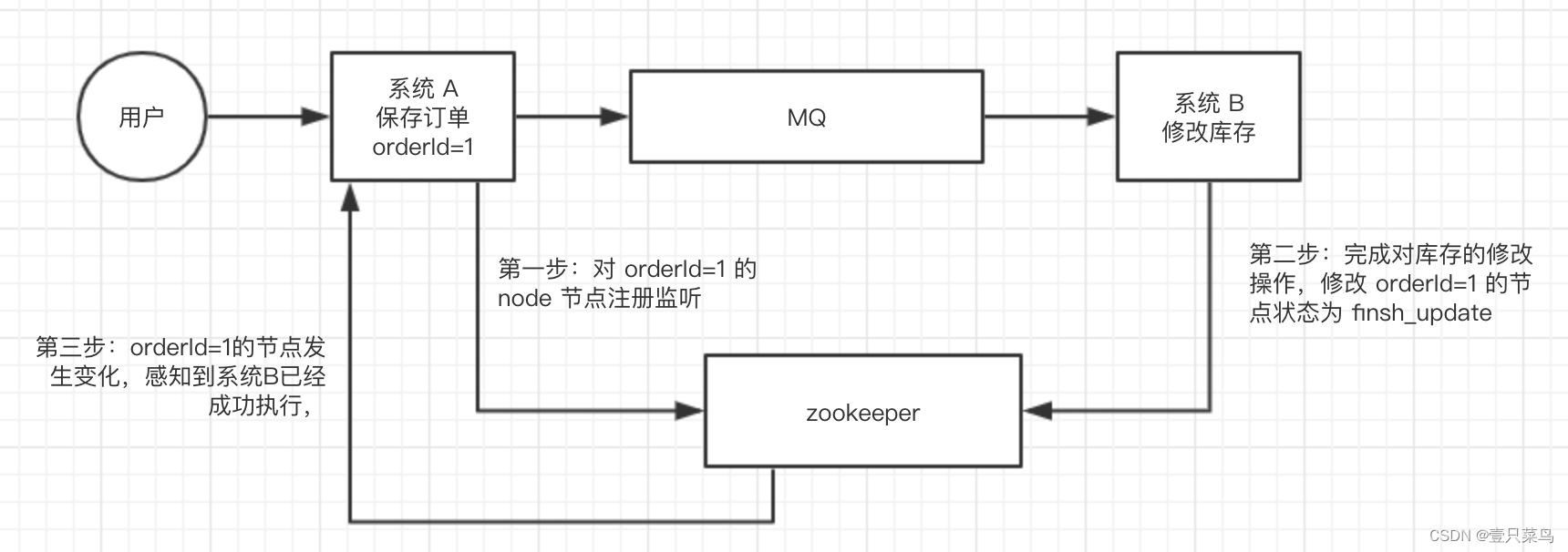
这个其实是 zookeeper 很经典的一个用法,简单来说,就好比,你 A 系统发送个请求到 mq,然后 B 系统消息消费之后处理了。那 A 系统如何知道 B 系统的处理结果?用 zookeeper 就可以实现分布式系统之间的协调工作。A 系统发送请求之后可以在 zookeeper 上对某个节点的值注册个监听器,一旦 B 系统处理完了就修改 zookeeper 那个节点的值,A 系统立马就可以收到通知,完美解决。
-
分布式锁
zk在实现分布式锁上,可以做到强一致性例如:对某一个数据连续发出两个修改操作,两台机器同时收到了请求,但是只能一台机器先执行完另外一个机器再执行。那么此时就
可以使用 zookeeper 分布式锁,一个机器接收到了请求之后先获取 zookeeper 上的一把分布式锁,就是可以去创建一个 znode,接着执行
操作;然后另外一个机器也尝试去创建那个 znode,结果发现自己创建不了,因为被别人创建了,那只能等着,等第一个机器执行完了自己再执行。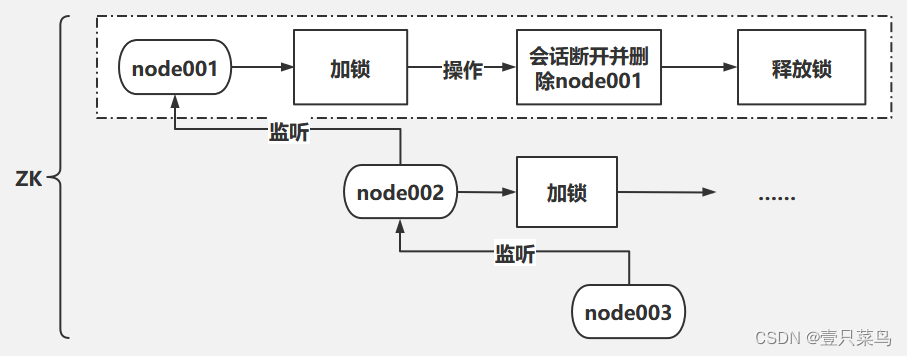
-
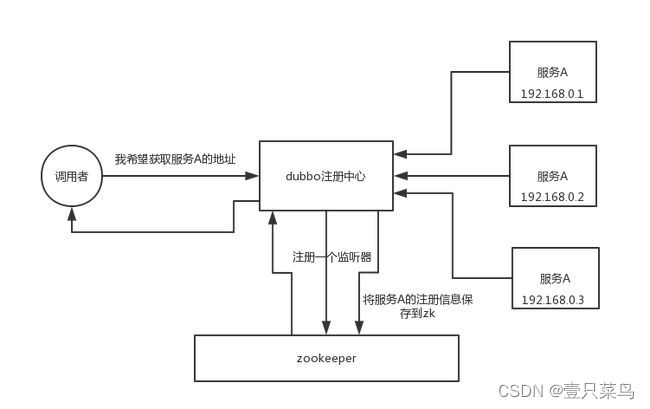
元数据/配置信息管理
zookeeper 可以用作很多系统的配置信息的管理,比如 kafka、storm 等等很多分布式系统都会选用 zookeeper 来做一些元数据、
配置信息的管理,包括 dubbo 注册中心不也支持 zookeeper 么?
-
高可用性
这个应该是很常见的,比如 hadoop、hdfs、yarn 等很多大数据系统,都选择基于 zookeeper 来开发 HA 高可用机制,就是一个
重要进程一般会做主备两个,主进程挂了立马通过 zookeeper 感知到切换到备用进程。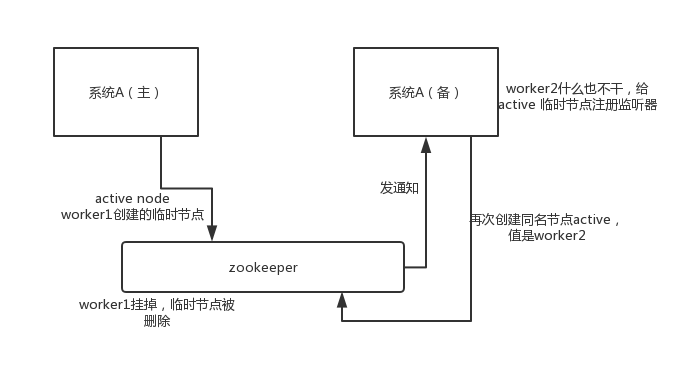
2. 搭建ZooKeeper服务器
依赖:JDK 必须是7或以上版本
2.1 下载安装包
下载地址
[root@node-251 conf]# cd /opt/;wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
[root@node-251 opt]# tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz
[root@node-251 opt]# cp apache-zookeeper-3.8.0-bin /usr/share/zookeeper -r
[root@node-251 opt]# ll /usr/share/zookeeper/
total 36
drwxr-xr-x 2 root root 4096 May 19 01:10 bin
drwxr-xr-x 2 root root 72 May 19 01:10 conf
drwxr-xr-x 5 root root 4096 May 19 01:10 docs
drwxr-xr-x 2 root root 4096 May 19 01:10 lib
-rw-r--r-- 1 root root 11358 May 19 01:10 LICENSE.txt
-rw-r--r-- 1 root root 2084 May 19 01:10 NOTICE.txt
-rw-r--r-- 1 root root 2335 May 19 01:10 README.md
-rw-r--r-- 1 root root 3570 May 19 01:10 README_packaging.md
2.2 配置文件
进入zookeeper目录下的conf目录,将目录中的zoo_sample.cfg改成zoo.cfg
[root@node-251 conf]# cp zoo_sample.cfg zoo.cfg
[root@node-251 conf]# vim zoo.cfg
[root@node-251 conf]# cat zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
配置文件说明:
-
tickTime
(tickTime=2000):Client-Server通信心跳时间 zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳。 tickTime以毫秒为单位 -
initLimit
(initLimit=10):Leader - Follower 初始通信时限。 用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器 集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5 个心跳的时 间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的 时间长度就是 5*2000 = 10 秒。 -
syncLimit
(syncLimit=5):Leader- Follower 同步通信时限。 这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度, 总的时间长度就是 5*2000 = 10 秒。 -
dataDir
(dataDir=/tmp/zookeeper):数据文件目录。 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。 -
clientPort
(clientPort=2181):客户端连接端口。 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。 -
maxClientCnxns
(maxClientCnxns=60):对于一个客户端的连接数最大限制。 默认是 60,这在大部分时候是足够了。但是在我们实际使用中发现,在测试环境经常超过这个数,经过调查发现有的团队 将几十个应用全部部署到一台机器上,以方便测试,于是这个数字就超过了。 -
autopurge.snapRetainCount、autopurge.purgeInterval
设置清除时间和保留个数。 客户端在与 zookeeper 交互过程中会产生非常多的日志,而且 zookeeper 也会将内存中的数据作为 snapshot 保存下来, 这些数据是不会被自动删除的,这样磁盘中这样的数据就会越来越多。不过可以通过这两个参数来设置,让 zookeeper 自动 删除数据。 autopurge.purgeInterval 就是设置多少小时清理一次。 autopurge.snapRetainCount 是设置保留多少个 snapshot ,之前的则删除。 -
集群信息的配置
在zoo.cfg这个文件中,配置集群信息是存在一定的格式:service.N =YYY: A:BN:代表服务器编号(也就是myid里面的值)
YYY:服务器地址
A:表示 Flower 跟 Leader的通信端口,简称服务端内部通信的端口(默认2888)
B:表示 是选举端口(默认是3888)
例如:
server.1=hadoop05:2888:3888
server.2=hadoop06:2888:3888
server.3=hadoop07:2888:3888
2.3 启动测试
进入bin目录下,启动服务端
[root@node-251 bin]# ./zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/share/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node-251 bin]# ss -nltp
...
LISTEN 0 50 [::]:2181 [::]:* ...
jps查看进程
[root@node-251 opt]# jps
59140 Bootstrap
72861 Jps
如果jps命令找不到,安装一下就可以了
yum install java-1.8.0-openjdk-devel.x86_64
启动/停止/重启/状态 zk服务器:
./zkServer.sh start/stop/restart/status ../conf/zoo.cfg
回到zookeeper目录下,启动客户端
[root@node-251 bin]# ./zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 0] quit
3. Zookeeper内部的数据模型
3.1 zk如何保存数据?
zk中的数据是保存在节点上的,节点就是znode,多个znode之间构成一棵树的目录结构。Zookeeper的数据模型是什么样子呢?类似于数据结构中的树,同时也很像文件系统的目录。树是由节点所组成,Zookeeper的数据存储也同样是基于节点,这种节点叫做Znode,但是不同于树的节点,Znode的引用方式是路径引用,类似于文件路径:
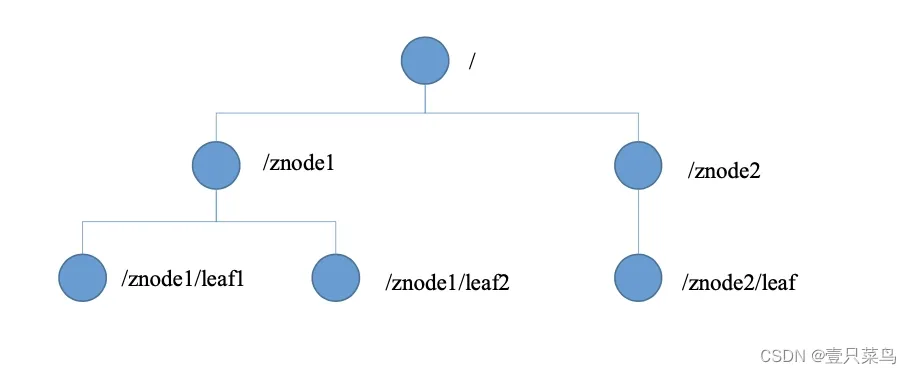
这样的层级结构,让每一个Znode的节点拥有唯一的路径,就像命名空间一样对不同信息做出清晰的隔离。
3.2 zk中的znode是什么样的数据结构
zk中的znode包含了四个部分:
-
data:保存数据
-
acl:权限:
c:create 创建权限,允许在该节点下创建子节点 w:write 更新权限,允许更新该节点的数据 r:read 读取权限,允许读取该节点的内容以及子节点的列表信息 d:delete 删除权限,允许删除该节点的子节点信息 a:admin 管理者权限,允许对该节点进行acl权限设置 -
stat:描述当前znode的元数据
cZxid 就是 Create ZXID,表示节点被创建时的事务ID。 ctime 就是 Create Time,表示节点创建时间。 mZxid 就是 Modified ZXID,表示节点最后⼀次被修改时的事务ID。 mtime 就是 Modified Time,表示节点最后⼀次被修改的时间。 pZxid 表示该节点的⼦节点列表最后⼀次被修改时的事务 ID。只有⼦节点列表变更才会更新 pZxid, ⼦节点内容变更不会更新。 cversion 表示⼦节点的版本号。 dataVersion 表示内容版本号。 aclVersion 标识acl版本 ephemeralOwner 表示创建该临时节点时的会话 sessionID,如果是持久性节点那么值为 0 dataLength 表示数据⻓度。 numChildren 表示直系⼦节点数 -
child:当前节点的子节点
3.3 zk中节点znode的类型
1、持久节点:创建出的节点,在会话结束后依然存在。保存数据
2、持久序号节点:创建出的节点,根据先后顺序,会在节点之后带上一个数值,越后执行数值越大,适用于分布式锁的应用场景-单调递增
3、临时节点:临时节点是在会话结束后,自动被删除的,通过这个特性,zk可以实现服务注册与发现的效果。
4、临时序号节点:跟持久序号节点相同,适用于临时的分布式锁
5、Container节点(3.5.3版本新增):Container容器节点,当容器中没有任何子节点,该容器节点会被zk定期删除
6、TTL节点:可以指定节点的到期时间,到期后被zk定时删除。只能通过系统配置zookeeper.extendedTypeEnablee=true开启
3.4 zk的数据持久化
zk的数据运行在内存中,zk提供了两种持久化机制:
- 事务日志
zk把执行的命令以日志形式保存在dataLogDir指定的路径中的文件中(如果没有指定dataLogDir,则按照 dataDir指定的路径)。 - 数据快照
zk会在一定的时间间隔内做一次内存数据快照,把时刻的内存数据保存在快照文件中。
zk通过两种形式的持久化,在恢复时先恢复快照文件中的数据到内存中,再用日志文件中的数据做增量恢复,这样恢复的速度更快。
4. Zookeeper客户端(zkCli)的使用
4.1 多节点类型创建
创建节点指令
[-s]表示节点是序号节点
[-e]表示节点是临时节点
[-c]表示节点是Container节点
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
- 创建持久节点 create path [data] [acl]
- 创建持久序号节点 create -s path [data] [acl]
- 创建临时节点 create -e path [data] [acl]
- 创建临时序号节点 create -e -s path [data] [acl]
- 创建容器节点 create -c path [data] [acl]
[zk: localhost:2181(CONNECTED) 0] create /lasting_node
Created /lasting_node
[zk: localhost:2181(CONNECTED) 1] create -s /lasting_serial_node
Created /lasting_serial_node0000000001
[zk: localhost:2181(CONNECTED) 2] create -e /temporary_node
Created /temporary_node
[zk: localhost:2181(CONNECTED) 3] create -e -s /temporary_serial_node
Created /temporary_serial_node0000000003
[zk: localhost:2181(CONNECTED) 4] create -c /container_node
Created /container_node
[zk: localhost:2181(CONNECTED) 5] ls
ls [-s] [-w] [-R] path
[zk: localhost:2181(CONNECTED) 6] ls /
[container_node, lasting_node, lasting_serial_node0000000001, temporary_node, temporary_serial_node0000000003, zookeeper]
4.2 查询节点
普通查询
ls [-s -R] path
# -s 详细信息
# -R 当前目录和子目录中的所有信息
[zk: localhost:2181(CONNECTED) 1] ls -s /lasting_node
[]
cZxid = 0x4
ctime = Fri May 19 19:22:49 CST 2023
mZxid = 0x4
mtime = Fri May 19 19:22:49 CST 2023
pZxid = 0x4
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0
[zk: localhost:2181(CONNECTED) 2] ls -R /lasting_node
/lasting_node
查询节点相关信息
- cZxid:创建节点的事务ID
- mZxid:修改节点的事务ID
- pZxid:添加和删除子节点的事务ID
- ctime:节点创建的时间
- mtime:节点最近修改的时间
- dataVersion:节点内数据的版本,每更新一次数据,版本会+1
- aclVersion:此节点的权限版本
- ephemeralOwner:如果当前节点是临时节点,该是是当前节点所有者的session id。如果节点不是临时节点,则该值为零
- dataLength:节点内数据的长度
- numChildren:该节点的子节点个数
查询节点的内容
get [-s] path
# -s 详细信息
[zk: localhost:2181(CONNECTED) 0] get -s /lasting_node
null
cZxid = 0x4
ctime = Fri May 19 19:22:49 CST 2023
mZxid = 0x4
mtime = Fri May 19 19:22:49 CST 2023
pZxid = 0x4
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0
ls和get
ls命令可以列出Zookeeper指定节点下的所有子节点,只能查看指定节点下的第一级的所有子节点;get命令可以获取Zookeeper指定节点的数据内容和属性信息
4.3 删除节点
普通删除
delete path [dataVersion]
乐观锁删除
delete [-v version] path
# -v 版本
deleteall path [-b batch size]
想要删除某个节点,极其后代节点,可以使用递归删除
rmr path
4.4 权限设置
注册当前会话的账号和密码:
addauth digest xiaowang:123456
创建节点并设置权限(指定该节点的用户,以及用户所拥有的权限s)
create /test-node abcd auth:xiaowang:123456:cdwra
在另一个会话中必须先使用账号密码,才能拥有操作节点的权限
addauth digest xiaowang:123456
5. kazoo客户端的使用(python)
环境:
- python 2.7.8
- kazoo 2.6.1 下载地址
5.1 基本操作
#coding:utf-8
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.71.251:2181') #如果是本地那就写127.0.0.1
zk.start() #与zookeeper连接
zk.stop() #与zookeeper断开
5.2 创建节点
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.71.251:2181') #如果是本地那就写127.0.0.1
zk.start() #与zookeeper连接
#makepath=True是递归创建,如果不加上中间那一段,就是建立一个空的节点
zk.create('/abc/JQK/XYZ/0001',b'this is my house',makepath=True)
node = zk.get_children('/') # 查看根节点有多少个子节点
print(node)
zk.stop() #与zookeeper断开
5.3 删除节点
如果要删除这个/abc/def/ghi/0001的子node,但是想要上一级ghi这个node还是存在的
#coding:utf-8
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.71.251:2181') #如果是本地那就写127.0.0.1
zk.start() #与zookeeper连接
#zk.create('/abc/def/ghi/0001', b'this is test', makepath=True)
node = zk.get_children('/abc/def/ghi/')
zk.delete('/abc/def/ghi/0001',recursive=True)
print node
zk.stop() #与zookeeper断开
-----------------------
[]
5.4 更改节点
现在假如要在0001这个node里更改value,比如改成:“this is my horse!”,
由于上面节点已经被删除掉了,需要先创建一次。
#coding:utf-8
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.71.251:2181') #如果是本地那就写127.0.0.1
zk.start() #与zookeeper连接
zk.create('/abc/JQK/XYZ/0001',b'this is my house',makepath=True)
zk.set('/abc/JQK/XYZ/0001',b"this is my horse!")
node = zk.get('/abc/JQK/XYZ/0001')
print node
zk.stop() #与zookeeper断开
-------------------------------
('this is my horse!', ZnodeStat(czxid=48, mzxid=49, ctime=1684503782537L, mtime=1684503782540L, version=1, cversion=0, aversion=0, ephemeralOwner=0, dataLength=17, numChildren=0, pzxid=48))
注意!set这种增加节点内容的方式是覆盖式增加,并不是在原有基础上增添。而且添加中文的话可能在ZooInspecter里出现的是乱码
5.5 一键清空zookeeper
有些时候,需要将zookeeper的数据全部清空,可以使用以下代码
#coding:utf-8
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.71.251:2181') #如果是本地那就写127.0.0.1
zk.start() #与zookeeper连接
jiedian = zk.get_children('/') # 查看根节点有多少个子节点
print(jiedian)
for i in jiedian:
if i != 'zookeeper': # 判断不等于zookeeper
print(i)
# 删除节点
zk.delete('/%s'%i,recursive=True)
zk.stop() #与zookeeper断开
注意:默认的zookeeper节点,是不允许删除的,所以需要做一个判断。
5.6 watches 事件
zookeeper 所有读操作都有设置 watch 选项(get_children() 、get() 和 exists())。watch 是一个触发器,当检测到 zookeeper 有子节点变动 或者 节点value发生变动时触发。下面以 get() 方法为例。
#coding:utf-8
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.71.251:2181')
zk.start()
def test(event):
print('触发事件')
if __name__ == "__main__":
zk.create('/testplatform/test',b'this is test',makepath=True)
zk.get('/testplatform/test',watch = test)
print("第一次获取value")
zk.set('/testplatform/test',b'hello')
zk.get('/testplatform/test',watch = test)
print("第二次获取value")
zk.stop()
------------------------------------------------
第一次获取value
触发事件
第二次获取value
高阶运用
好文推荐 - 详细参考
6. zk实现分布式锁
6.1 zk中锁的种类:
- 读锁(读锁共享):大家都可以读。上锁前提:之前的锁没有写锁
- 写锁(写锁排他):只有得到写锁的才能写。上锁前提:之前没有任何锁
6.2 zk如何上读锁
- 创建一个临时序号节点,节点的数据是read,表示是读锁
- 获取当前zk中序号比自己小的所有节点
- 判断最小节点是否是读锁
- 如果不是读锁的话,则上锁失败,为最小节点设置监听。阻塞等待,zk的watch机制会当最小节点发生变化时通知当前节点,再执行第二步的流程
- 如果是读锁的话,则上锁成功。
6.3 zk如何上写锁
- 创建一个临时序号节点,节点的数据是write,表示写锁
- 获取zk中所有的子节点
- 判断自己是否是最小的节点:
- 如果是,则上写锁成功
- 如果不是,说明前面还有锁,则上锁失败,监听最小节点,如果最小节点有变化,则再执行第二步。
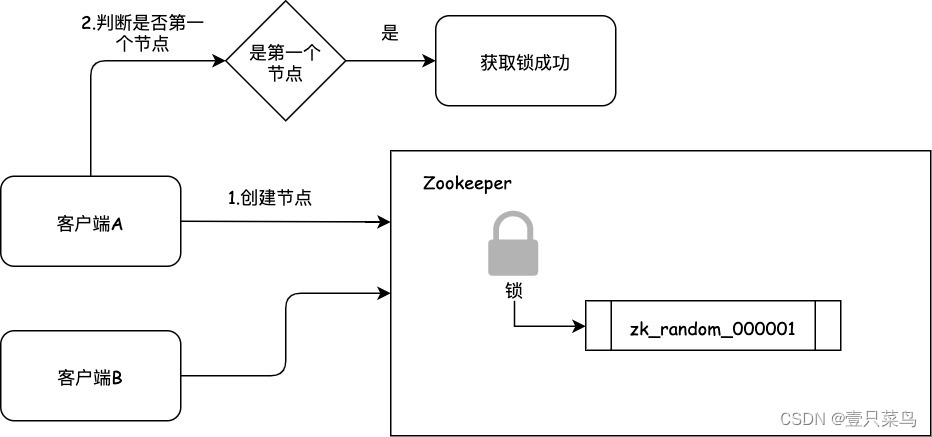
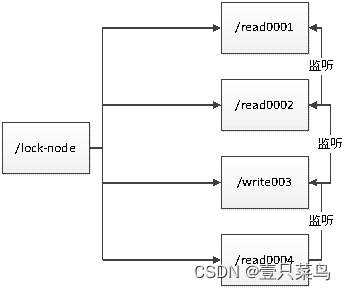
6.4 羊群效应
如果用上述的上锁方式,只要有节点发生变化,就会触发其他节点的监听事件,这样对zk的压力非常大,而羊群效应,可以调整成链式监听。zookeeper的羊群效应
7. zk的watch机制
7.1 Watch机制介绍
我们可以把Watch理解成是注册在特定Znode上的触发器。当这个Znode发生改变,也就是调用了create,delete,set方法的时候,将会触发Znode上注册的对应事件,请求Watch的客户端会收到异步通知。
具体交互过程如下:
- 客户端调用getData方法,watch参数是true。服务端接到请求,返回节点数据,并且在对应的哈希表里插入被Watch的Znode路径,以及Watcher列表。
- 当被Watch的Znode已删除,服务端会查找哈希表,找到该Znode对应的所有Watcher,异步通知客户端,并且删除哈希表中对应的key-value。
7.2 zkCli客户端使用Watch
create /test date
get -w /test # 一次性监听节点
ls -w /test # 监听目录,创建和删除子节点会收到通知。但是子节点中新增节点不会被监听到
ls -R -w /test # 监听子节点中节点的变化,但内容的变化不会收到通知
8. Zookeeper集群实战
8.1 Zookeeper集群角色
zookeeper集群中的节点有三种角色:
- Leader:处理集群的所有事务请求,集群中只有一个Leader
- Follower:只能处理读请求,参与Leader选举
- Observer(观察者):只能处理读请求,提升集群读的性能,但不能参与Leader选举
8.2 集群搭建
搭建4个节点,其中一个节点为Observer
- 创建4个节点的myid并设值,在usr/local/zookeeper中创建一下四个文件
/usr/local/zookeeper/zkdata/zk1# echo 1 > myid
/usr/local/zookeeper/zkdata/zk2# echo 2 > myid
/usr/local/zookeeper/zkdata/zk3# echo 3 > myid
/usr/local/zookeeper/zkdata/zk4# echo 4 > myid
- 编写4个zoo.cfg
# The number of milliseconds of each tick
tickTime=2000 --基本时间单位
# The number of ticks that the initial
# synchronization phase can take
initLimit=10 --允许follower连接到leader的最大时长 tickTime*initLimit 2000*10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5 --允许与leader同步的最大时长
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes. 修改对应的zk1 zk2 zk3 zk4
dataDir=/usr/local/zookeeper/zkdata/zk1 --数据及日志保存路径
# the port at which the clients will connect
clientPort=2181
#2001为集群通信端口,3001为集群选举端口,observer(观察者身份)
server.1=192.168.200.128:2001:3001
server.2=192.169.200.128:2002:3002
server.3=192.168.200.128:2003:3003
server.4=192.168.200.128:2004:3004:observer
8.3 连接Zookeeper集群
./bin/zkCli.sh -server 192.168.200.128:2181,192.168.200.128:2182,192.168.200.128:2183
9. ZAB协议
9.1 什么是ZAB协议
zookeeper作为非常重要的分布式协调组件,需要进行集群部署,集群中会以一主多从的形式进行部署。zookeeper为了保证数据的一致性,使用了ZAB(Zookeeper Atomic Broadcast,zookeeper的原子广播协议)协议,这个协议解决了Zookeeper的崩溃恢复和主从数据同步的问题。
9.2 ZAB协议定义的四种节点状态
- Looking:选举状态
- Following:Following节点(从节点)所处的状态
- Leading:Leader节点(主节点)所处状态
- Observing:观察者节点所处的状态
9.3 集群上线Leader选举过程
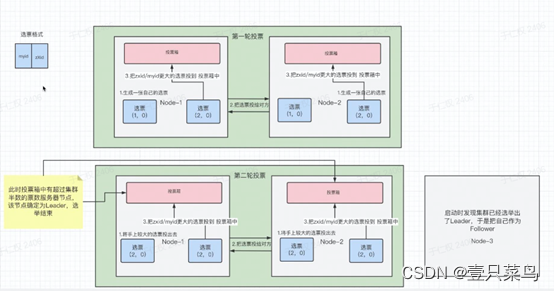
前提:本次4台机器,其中一台observer不参加选举,剩3台
第一轮:
- 1.选票格式:
Myid:节点ID
ZXid:事务ID
生成这一张自己的选票 - 2.把选票给对方
- 3.把zxid/myid更大的选票投入投票箱,zxid/myid表示先按zxid比较,如果相同再按myid比较
- 4.由于每个节点的投票箱只有一票,而要求拥有超过半数以上的节点,才算选举成功,需要至少2票以上
第二轮:
- 1.把上一轮较大的票给对方
- 2.再次统计,节点2获胜,选举结束
当3进入的时候,发现已有leader,把自己当为follower
9.4 崩溃恢复时的Leader选举
Leader建立完后,Leader周期性地不断向Follower发送心跳(ping命令,没有内容的socket)。当Leader崩溃后,Follower发现socket通道已关闭,于是Follower开始进入到Looking状态,重新回到上一节中的Leader选举状态,此时集群不能对外提供服务。
9.5 主从服务器之间的数据同步
ACK:(Acknowledge character)即是确认字符
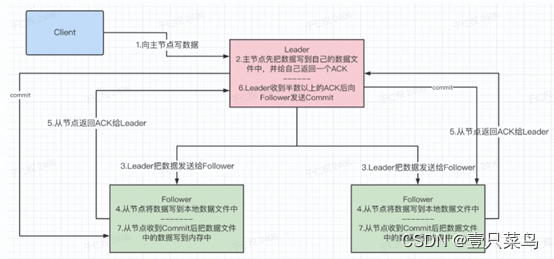
9.6 Zookeeper中的NIO与BIO的应用
NIO(NIO全称 java non-blocking IO,NIO是可以做到用一个线程处理多个操作的。假设有10000个请求过来,根据实际情况,可以分配50或100个线程来处理。不像BIO一样需要分配10000个线程来处理)
- 用于被客户端连接的2181端口,使用的是NIO模式与客户端建立连接
- 客户端开启Watch时,也使用NIO,等待Zookeeper服务器的回调
BIO(BIO(blocking I/O):同步阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销)
- 集群在选举时,多个节点之间的投票通信端口,使用BIO进行通信
10. CAP理论
10.1 CAP理论
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
-
—致性(Consistency)
一致性指"all nodespsee the same data at the same time",即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。 -
可用性(Availability)
可用性指"Reads and writes always succeed",即服务一直可用,而且是正常响应时间。 -
分区容错性(Partition tolerance)
分区容错性指"the system continues to operate despite arbitrary message loss or failure of part of the system",即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。——避免单点故障,就要进行冗余部署,冗余部署相当于是服务的分区,这样的分区就具备了容错性。
10.2 BASE理论
eBay的架构师Dan Pritchett源于对大规模分布式系统的实践总结,在ACM上发表文章提出BASE理论,BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性《Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency) 。
-
基本可用(Basically Available)
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用,电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。 -
软状态(Soft State)
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。 -
最终一致性(Eventual Consistency)
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的—种特殊情况。
10.3 Zookeeper追求的一致性
Zookeeper在数据同步时,追求的并不是强一致性,而是顺序一致性(事务id的单调递增)