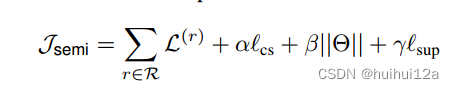目录
- 1.Learning with Noisy Correspondence for Cross-modal Matching(NCR)
- 1-1.贡献和创新点
- 1-2.图
- 1-2-1.总图
- 1-2-2.Co-divide
- 1-2-3. Co-Rectify
- 1-2-4.Robust Cross-modal Matching
1.Learning with Noisy Correspondence for Cross-modal Matching(NCR)
1-1.贡献和创新点
- 提出了Noisy Correspondence,其意思是不对齐(not correctly aligned)的数据对(传统noisy labels意思是错误地打上类标签)。
- 提出了新方法Noisy Correspondence Rectifier(NCR)解决Noisy Correspondence问题。(1)NCR具体功能为,先基于神经网络的记忆性将数据分为clean和noisy,然后通过an adaptive prediction model in a co-teaching manner来rectifies the correspondence。(2)NCR的创新点是使用了有soft margin的triplet loss来实现鲁棒的跨模态匹配。
- 在Flickr30K, MS-COCO, and Conceptual Captions数据集上验证了方法的有效性。
1-2.图
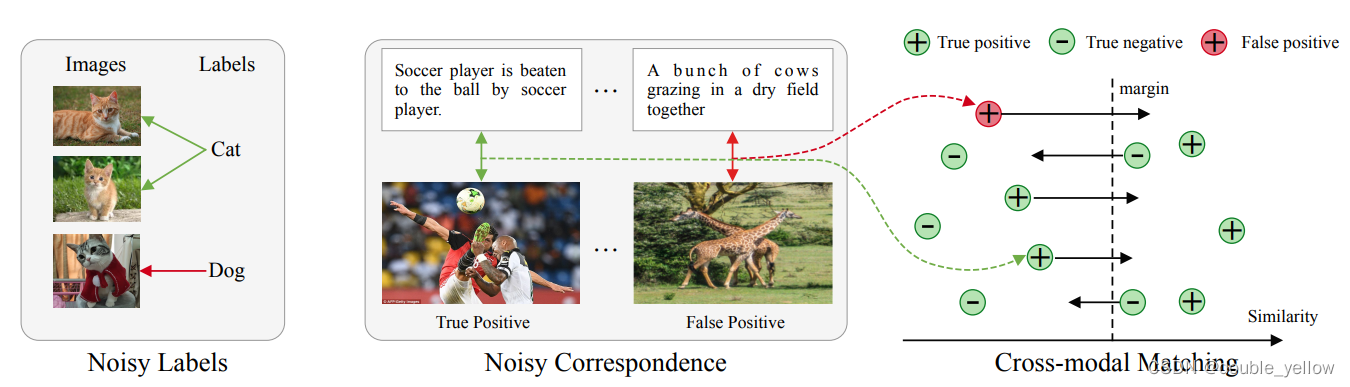
1-2-1.总图

1-2-2.Co-divide
- 式(1)是loss的集合,数据对从1到N
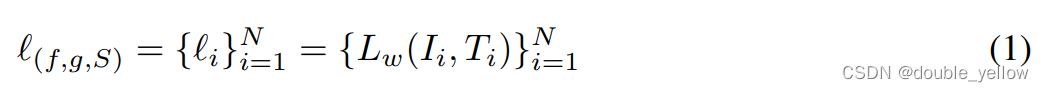
- 式(2)是用于GMM的loss,^意思是非原配,Σ下的符号代表遍历所有满足条件的数据对求和
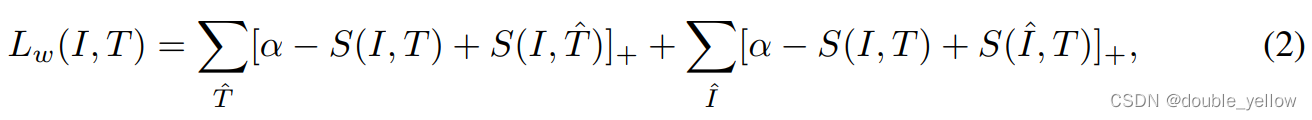
- 式(3)是GMM的先验概率(这个算法里没有用到先验概率),l是某组数据对,θ是当前概率分布(我猜的),k是component即第k个高斯分布(该算法K=2),βk是混合系数,Φ(l|k)是k-component的概率密度,p(l|θ)是在该概率分布下(θ)数据对l出现的概率
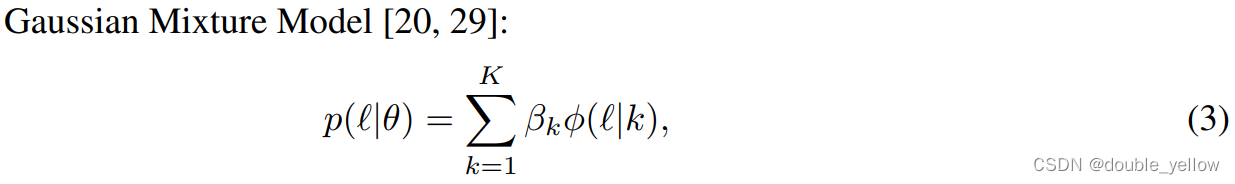
- 下式是GMM的后验概率(用到了),k是component(该算法k是平均值较小的那个高斯分布,作为clean数据的高斯分布),li是第i组数据对,wi是取第i组数据对,其为clean数据的概率
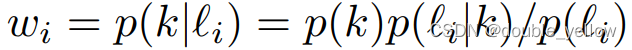
- 下图是clean/noisy数据对的per-sample loss的概率分布,虚线是拟合两种数据的高斯分布,实线是混合高斯分布
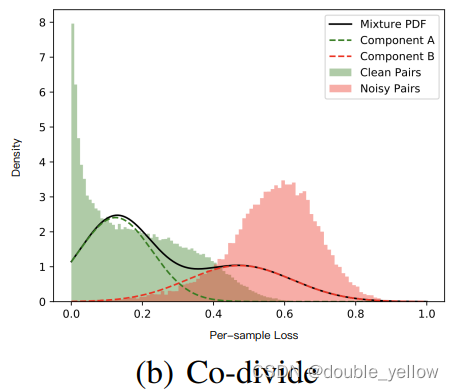
- 总结:在这个阶段,通过loss和GMM求出每对数据对为clean的概率wi,通过wi和阈值0.5,将数据分为clean和noisy
1-2-3. Co-Rectify
- 式(4)用于求数据新标签y-hat。第一行意思是数据对i若被判为clean则新标签求法,y-hatCi是第i对数据对若被判为clean后的新标签,wi是Co-divide阶段获得的数据为clean的概率, yCi是第i数据对若被判为clean后的原标签(这里yCi都取1),Pk是用网络输出的S(相似度)求出来的数据为clean的程度,k表示与wi来自不同网络(wi来自A则Pk来自B的S);第二行意思是数据对i若被判为noisy则新标签求法,PA/B来源分别是A/B的S,
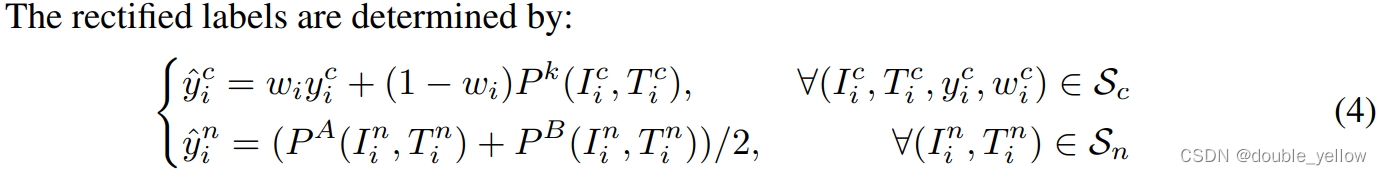
- 式(5)是通过A/B网络输出的S相似度求数据对为clean的程度。Θ(s)指将s控制在一定范围内,即设置超过上限的数据为上限
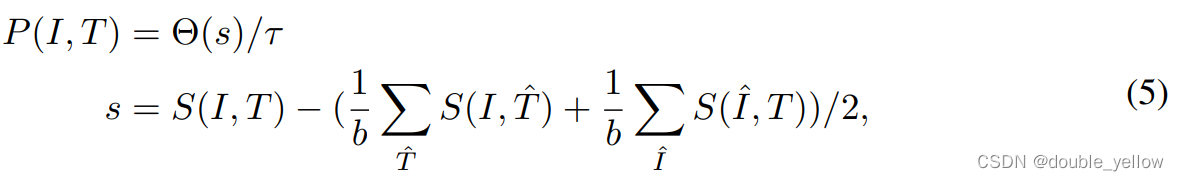
1-2-4.Robust Cross-modal Matching