学习目标/Target
掌握各区域热门商品Top3分析实现思路
掌握如何创建Spark连接并读取数据集
掌握利用Spark获取业务数据
掌握利用Spark过滤商品的行为类型
掌握利用Spark转换数据格式
掌握利用Spark统计每个区域中的不同商品
掌握利用Spark根据区域进行分组
掌握利用Spark根据区域内商品的查看次数进行排序
掌握将数据持久化到HBase数据库
熟悉通过Spark On YARN运行程序
用户在访问电商网站时,网站在存储用户行为数据的同时,还会通过IP地址或位置信息存储用户触发行为所在的区域数据。通过统计各区域不同商品被查看的次数,获取每个区域内比较热门的商品。本章将通过对电商网站存储的用户行为数据进行分析,从而统计出各区域排名前3的热门商品。
1. 实现思路分析
获取数据集中所有用户数据,过滤出用户行为类型为查看的数据,通过商品被查看的次数为依据判断哪些商品属于热门商品。对过滤后的数据进行聚合操作,统计每个区域不同商品的查看次数。按照区域对聚合后的数据进行分组处理,将分组后的数据进行降序排序,获取各区域排名前3的商品,就是各区域热门商品Top3。
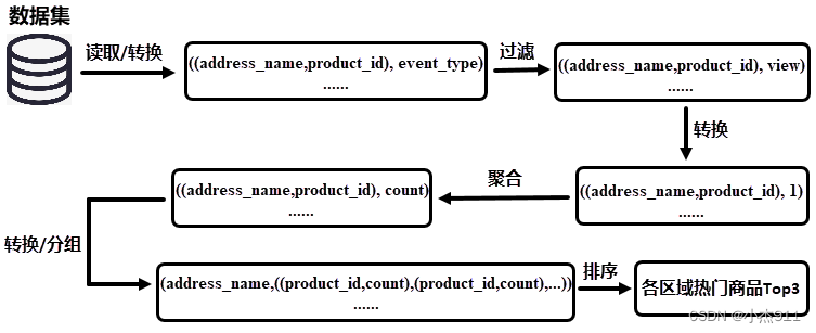
读取/转换:读取数据集中的区域名称(address_name)、行为类型(event_type)和商品ID(product_id)数据;
过滤:过滤行为类型为view(查看)的数据;
转换:便于后续聚合处理时,将相同Key的Value值进行累加,这里需要对数据格式进行转换处理,将区域名称和商品ID作为Key,值1作为Value。由于过滤后的数据行为类型都是查看,在后续的处理中便不再需要行为类型数据;
聚合:统计每个区域中不同商品的查看次数;
转换/分组:对数据格式进行转换,将区域名称作为Key,商品ID和商品被查看的次数作为Value。接下来,将转换后的数据根据Key进行分组,统计各个区域被查看的商品及每个商品查看的次数;
排序:对每一组数据的值进行排序,即对各个区域每个商品被查看的次数进行降序排序。
2. 实现各区域热门商品Top3
2.1 创建Spark连接并读取数据集
在项目SparkProject的 java目录新建Package包“cn.itcast.top3”,用于存放实现各区域热门商品Top3的Java文件。在包“cn.itcast.top3”中创建文件AreaProductTop3.java,用于实现各区域热门商品Top3。
public class AreaProductTop3{
public static void main(String[] arg){
//实现各区域热门商品Top3分析
}f
}
在main()方法中,创建JavaSparkContext和SparkConf对象,JavaSparkContext对象用于实现Spark程序,SparkConf对象用于配置Spark程序相关参数。
SparkConf conf = new SparkConf(); //设置Application名称为top3_area_product conf.setAppName("top3_area_product"); JavaSparkContext sc = new JavaSparkContext(conf);
在main()方法中,调用JavaSparkContext对象的textFile()方法读取外部文件,将文件中的数据加载到textFileRDD。
JavaRDD<String> textFileRDD = sc.textFile(arg[0]);
2.2 获取业务数据
在main()方法中,使用mapToPair()算子转换textFileRDD的每一行数据,用于获取每一行数据中的行为类型、区域名称和商品ID数据,将转换结果加载到transProductRDD。
JavaPairRDD<Tuple2<String,String>,String> transProductRDD = textFileRDD.mapToPair(new PairFunction<String,Tuple2<String, String>,String>() {
@Override
public Tuple2<Tuple2<String, String>, String> call(String s) throws Exception {
JSONObject json = JSONObject.parseObject(s);
String address_name = json.getString("address_name").replaceAll("\\u00A0+",""); String product_id = json.getString("product_id");
String event_type = json.getString("event_type");
Tuple2<Tuple2<String,String>,String> tuple2 =
new Tuple2<>( new Tuple2<>(address_name,product_id), event_type);
return tuple2;
}
});
2.3 过滤商品的行为类型
在main()方法中,使用filter()算子过滤transProductRDD每一行数据中行为类型为加入购物车和购买的数据,只保留行为类型为查看的数据,将过滤结果加载到getViewRDD。
JavaPairRDD<Tuple2<String, String>, String> getViewRDD =
transProductRDD.filter(new Function<Tuple2<
Tuple2<String, String>, String>, Boolean>() {
@Override
public Boolean call(
Tuple2<Tuple2<String, String>, String> tuple2)
throws Exception {
String event_type = tuple2._2;
return event_type.equals("view");
}
});
2.4 转换数据格式
在main()方法中,使用mapToPair()算子转换getViewRDD的每一行数据,用于替换行为类型数据为1,将转换结果加载到productByAreaRDD。
JavaPairRDD<Tuple2<String,String>,Integer> productByAreaRDD = getViewRDD.mapToPair(
new PairFunction<Tuple2<Tuple2<String, String>, String>,
Tuple2<String, String>,
Integer>() {
@Override
public Tuple2<Tuple2<String, String>, Integer> call(
Tuple2<Tuple2<String, String>, String> tuple2)
throws Exception {
return new Tuple2<>(tuple2._1,new Integer(1));
}
});
2.5 统计每个区域中的不同商品
在main()方法中,使用reduceByKey()算子对productByAreaRDD进行聚合操作,用于统计每个区域中不同商品的查看次数,将统计结果加载到productCountByAreaRDD。
JavaPairRDD<Tuple2<String,String>,Integer> productCountByAreaRDD = productByAreaRDD.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2)
throws Exception {
return integer+integer2;
}
});
2.6 根据区域进行分组
在main()方法中,使用mapToPair()算子转换productCountByAreaRDD的每一行数据,将转换结果加载到transProductCountByAreaRDD
JavaPairRDD<String,Tuple2<String,Integer>> transProductCountByAreaRDD =productCountByAreaRDD.mapToPair(new PairFunction<Tuple2<Tuple2<String, String>, Integer>,String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Tuple2<String, Integer>> call(Tuple2<Tuple2<String, String>, Integer> tuple2) throws Exception {
return new Tuple2<>(tuple2._1._1, new Tuple2<>(tuple2._1._2,tuple2._2));
}
});
在main()方法中,使用groupByKey()算子对transProductCountByAreaRDD进行分组操作,将同一区域内的商品以及商品被查看的次数合并在一起,通过productGroupByAreaRDD加载分组结果。
JavaPairRDD<String, Iterable<Tuple2<String, Integer>>>
productGroupByAreaRDD = transProductCountByAreaRDD.groupByKey();
2.7 根据区域内商品的查看次数进行排序
在main()方法中,使用mapToPair()算子转换productGroupByAreaRDD的每一行数据,将同一区域内的商品按照商品被查看的次数进行逆序排序,通过productSortByAreaRDD加载排序结果。
JavaPairRDD<String, Iterable<Tuple2<String, Integer>>> productSortByAreaRDD =productGroupByAreaRDD
.mapToPair( new PairFunction<Tuple2<String, Iterable<Tuple2<String, Integer>>>,String,Iterable<Tuple2<String, Integer>>>() {
@Override
public Tuple2<String, Iterable<Tuple2<String, Integer>>> call(Tuple2<String, Iterable<Tuple2<String, Integer>>> tuple2)
throws Exception {
List<Tuple2<String,Integer>> list = new ArrayList<>(); Iterator<Tuple2<String,Integer>> iter = tuple2._2.iterator(); while (iter.hasNext()){
list.add(iter.next());
}
list.sort(new Comparator<Tuple2<String, Integer>>() {
@Override
public int compare(Tuple2<String, Integer> o1,Tuple2<String, Integer> o2) {
return o2._2 - o1._2;
}
});
return new Tuple2<>(tuple2._1,list);
}
});
2.8 数据持久化
获取各区域热门商品Top3数据
在类AreaProductTop3的main()方法中,使用mapToPair()算子转换productSortByAreaRDD的每一行数据,获取每个区域排名前3的商品,通过productSortByAreaRDD加载转换结果。
JavaPairRDD<String, Iterable<Tuple2<String, Integer>>> top3AreaProductRDD=productSortByAreaRDD.mapToPair(new PairFunction<Tuple2<String, Iterable<Tuple2<String, Integer>>>,String,Iterable<Tuple2<String, Integer>>>() {
@Override
public Tuple2<String, Iterable<Tuple2<String, Integer>>> call(Tuple2<String, Iterable<Tuple2<String, Integer>>> tuple2) throws Exception {
List<Tuple2<String,Integer>> list = new ArrayList<>();
Iterator<Tuple2<String,Integer>> iter = tuple2._2.iterator();
int i = 0;
while (iter.hasNext()){
list.add(iter.next());
i++;
if (i == 3){
break;
}
}
return new Tuple2<>(tuple2._1,list);
}
});
持久化各区域热门商品Top3数据
在类AreaProductTop3的main()方法中,添加方法top3ToHbase(),用于将各区域热门商品Top3分析结果持久化到HBase数据库中,该方法包含参数rdd,表示各区域热门商品Top3分析结果数据。
public static void top3ToHbase(JavaPairRDD<String, Iterable<Tuple2<String, Integer>>> rdd) throws IOException {
}
在方法top3ToHbase()中创建数据表top3和列族top3_area_product,并且创建数组column用于存储数据表top3的列名。
HbaseUtils.createTable("top3","top3_area_product");
String[] column ={"area","product_id","viewcount"};
持久化各区域热门商品Top3数据
在方法top3ToHbase()中通过foreach()算子遍历各区域热门商品Top3分析结果数据。
rdd.foreach(new VoidFunction<Tuple2<String,Iterable<Tuple2<String, Integer>>>>()
{
@Override
public void call(Tuple2<String, Iterable<Tuple2<String, Integer>>> tuple2) throws Exception { String area = tuple2._1,product_id = "",viewcount = "";
Iterator<Tuple2<String,Integer>> iter = tuple2._2.iterator();
List<Tuple2<String,Integer>> myList = Lists.newArrayList(iter);
for (Tuple2<String,Integer> tuple : myList) {
product_id = tuple._1;
viewcount = String.valueOf(tuple._2);
String [] value = {area,product_id,viewcount};
try { HbaseUtils.putsToHBase("top3",area+product_id,"top3_area_product",column,value); } catch (Exception e) {
e.printStackTrace();
}
}
}
});
}
在类AreaProductTop3的main()方法中,调用top3ToHbase()方法并传入参数top3AreaProductRDD,用于在Spark程序中实现top3ToHbase()方法,将各区域热门商品Top3分析结果持久化到HBase数据库中的数据表top3。
try {
top3ToHbase(top3AreaProductRDD);
} catch (IOException e) {
e.printStackTrace();
}
HbaseConnect.closeConnection();
sc.close();
3. 运行程序
 在IntelliJ IDEA中将各区域热门商品Top3分析程序封装成jar包,并上传到集群环境中,通过spark-submit将程序提交到YARN中运行。
在IntelliJ IDEA中将各区域热门商品Top3分析程序封装成jar包,并上传到集群环境中,通过spark-submit将程序提交到YARN中运行。
封装jar包:
由于在封装热门品类Top10分析程序jar包时,将程序主类指向了“cn.itcast.top10.CategoryTop10”,因此这里需要将pom.xml文件中的程序主类修改为“cn.itcast.top3.AreaProductTop3”。根据封装热门品类Top10分析程序jar包的方式封装各区域热门商品Top3分析程序。将封装完成的jar包重命名为“AreaProductTop3”,通过远程连接工具SecureCRT将AreaProductTop3.jar上传到虚拟机Spark01的/export/SparkJar/目录下。
提交各区域热门商品Top3分析程序到YARN集群
通过Spark安装目录中bin目录下的shell脚本文件spark-submit提交各区域热门商品Top3分析程序到YARN集群运行。

查看程序运行结果:
在虚拟机Spark01执行“hbase shell”命令,进入HBase命令行工具。
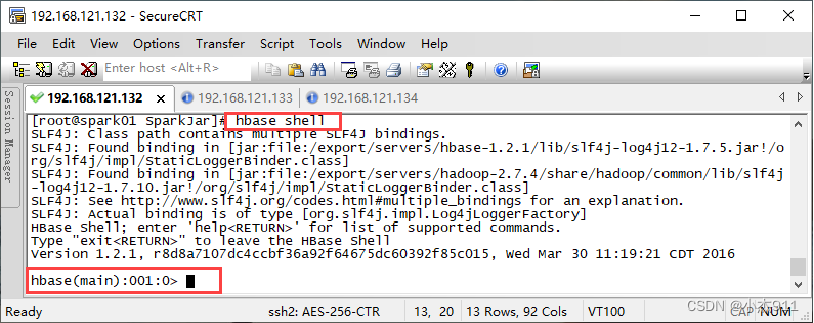
在HBase命令行工具中执行“list”命令,查看HBase数据库中的所有数据表。
> list TABLE
test
top10 top3
2 row(s) in 0.1810 seconds
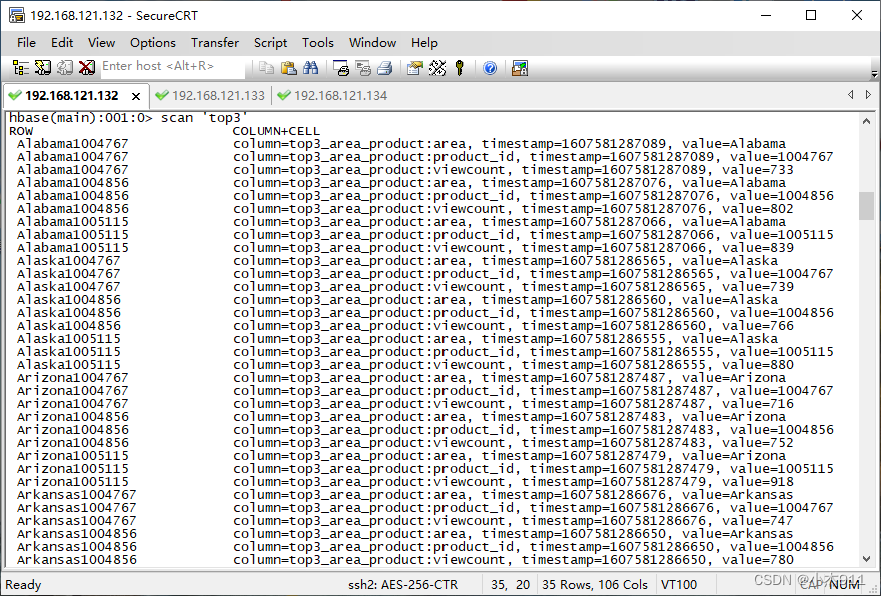
在HBase命令行工具执行“scan 'top3'”命令,查看数据表top3中所有数据。
本文主要讲解了如何通过用户行为数据实现各区域热门商品Top3分析,首先通过分析实现思路,使读者了解各区域热门商品Top3分析的实现流程。然后通过IntelliJ IDEA开发工具实现各区域热门商品Top3分析程序并将分析结果存储到HBase数据库,使读者掌握运用Java语言编写Spark Core和HBase程序的能力。最后封装各区域热门商品Top3分析程序并提交到集群运行,使读者掌握运用IntelliJ IDEA开发工具封装Spark Core程序以及Spark ON YARN模式运行Spark Core程序的方法。