目录
- tail命令
- 语法说明
- 基本参数
- 命令举例
- grep命令
- 语法说明
- 匹配模式选择
- 杂项
- 输入控制
- 文件控制
- sed命令
- 语法格式
- 举例
- 使用命令组合查询日志信息
业务需求需要对软件日志进行查询和呈现,查询的条件是时间区间和关键词,系统运行在linux环境下,为此对tail、grep、sed命令进行了基本的学习,现做一个总结。
tail命令
语法说明
Usage: tail [OPTION]... [FILE]...
Print the last 10 lines of each FILE to standard output.
With more than one FILE, precede each with a header giving the file name.
With no FILE, or when FILE is -, read standard input.
上述语法说明是通过tail --help输出的内容,解释起来是默认输出10文件末尾或者标准输入的末尾10行内容。如果有多个文件,请在每个文件之前加一个提供文件名的标头。,如果没有文件或者文件为-那么久会读取标准输入。
基本参数
-c, --bytes=K output the last K bytes; or use -c +K to output
bytes starting with the Kth of each file
# 从读取文件或者标准输入的末尾k字节,或者使用-c +k
# 的形式读取第k字节处的数据
-f, --follow[={name|descriptor}]
output appended data as the file grows;
an absent option argument means 'descriptor'
#等同于--follow=descriptor
#该参数会实时读取文件状态,输入crtl + c退出,默认实时读取
#末尾10行,当文件删除时停止读取
-F same as --follow=name --retry
#等同于--follow=name --retry,该参数会实时读取指定文件,默认
#10行,当文件删除时不会停止,直到文件重新创建时重新继续读取。
-n, --lines=K output the last K lines, instead of the last 10;
or use -n +K to output starting with the Kth
# -n k 参数表示输出文件末尾k行数据,如果使用+k则从头开始输出k行
--max-unchanged-stats=N
with --follow=name, reopen a FILE which has not
changed size after N (default 5) iterations
to see if it has been unlinked or renamed
(this is the usual case of rotated log files);
with inotify, this option is rarely useful
#这个参数大概意思应该是,配合-f使用,然后默认会迭代5次,也就是
#查询5次文件的更新情况。
--pid=PID with -f, terminate after process ID, PID dies
#当指定的进程号终止后,进程结束,配合f使用,我的理解是当用tail -f
#实时读取文件数据时,指定了pid,如果该pid对应进程终止了,则读取结束。
-q, --quiet, --silent never output headers giving file names
#当有多个文件参数时,不输出各个文件名
--retry keep trying to open a file if it is inaccessible
#当tail打开命令文件时,文件不可修改和访问,与-f结合使用
-s, --sleep-interval=N with -f, sleep for approximately N seconds
(default 1.0) between iterations;
with inotify and --pid=P, check process P at
least once every N seconds
#和-f一起使用时,睡眠大约N秒(默认值为1.0);
#在inotify和--pid=P的情况下,检查进程P至少每N秒一次
-v, --verbose always output headers giving file names
# 总是输出文件的文件名
--help display this help and exit
--version output version information and exit
命令举例
这里举例使用mysql的日志文件mysqld.log为例
默认读取文件或者标准输入末尾10行或任意行数
tail 10 mysqld.log 或 tail -n 10 mysqld.log
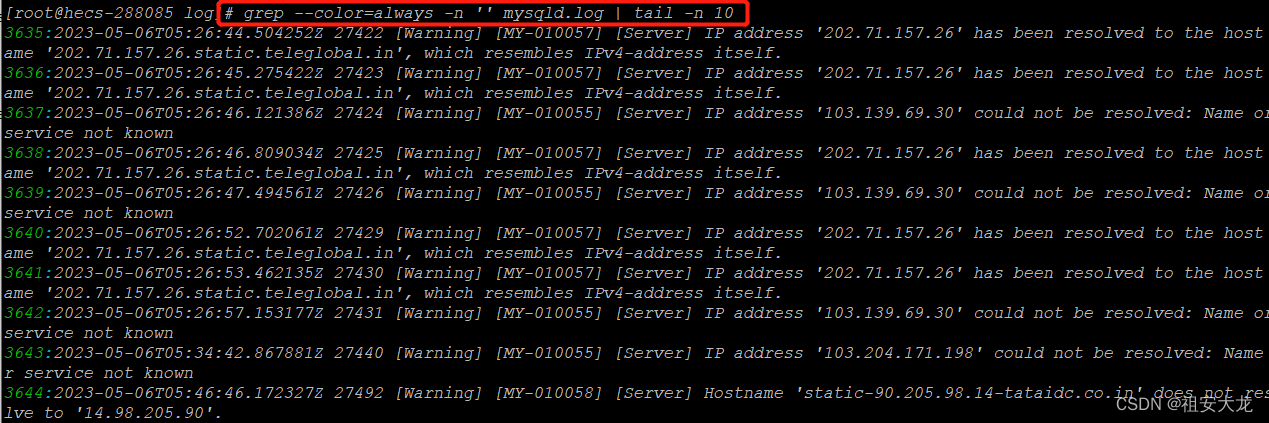
直接不输入数字和其他参数,则默认查询文件的末尾10行,同样也可以使用参数-n,数字选择10或者其他数字,查询文件末尾行数,命令如下,我查询时结合grep -n '' mysql.log来输出文件行号,让大家更直观的看到查询的行号。grep中的--color=always会将查询到的且匹配的结果高亮显示。关于grep下面的内容会写。
实时读取文件数据
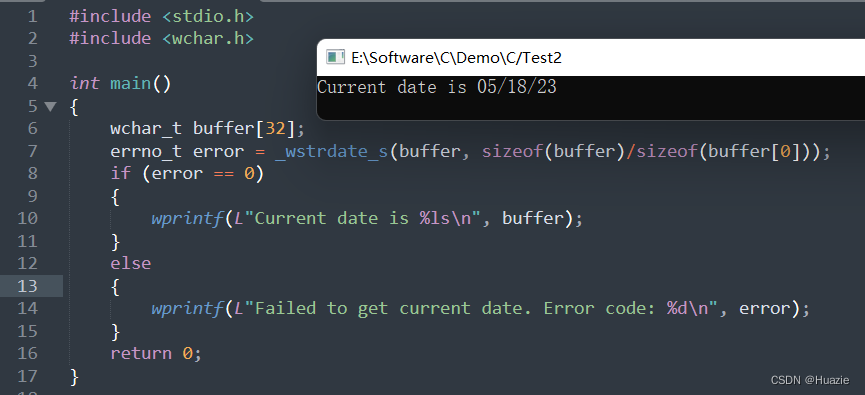
tail -f mysqld.log
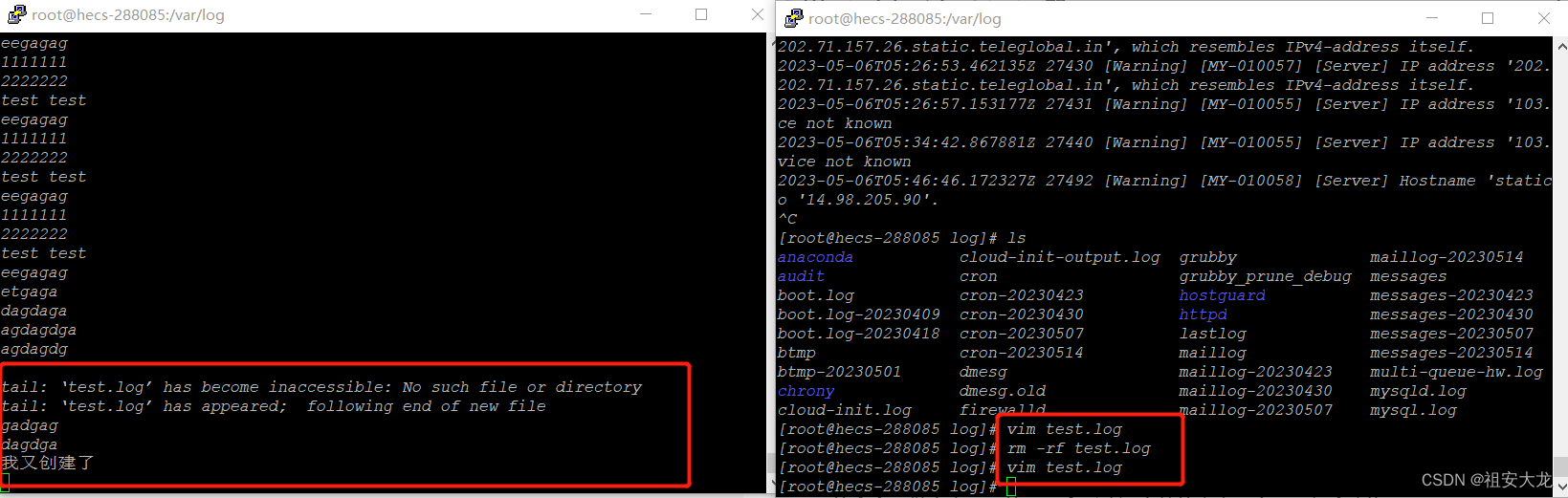
该参数可以实时查询文件,默认查询末尾10行,可以组合使用-n k来实时查询文件末尾行数,当文件被删除时停止。如下图所示。

tail -F mysqld.log
该参数可以实时查询文件,默认查询末尾10行,可以组合使用-n k来实时查询文件末尾行数,当文件被删除时不会停止,直至文件被重新创建后继续读取,crtl+c停止读取。如下图所示。
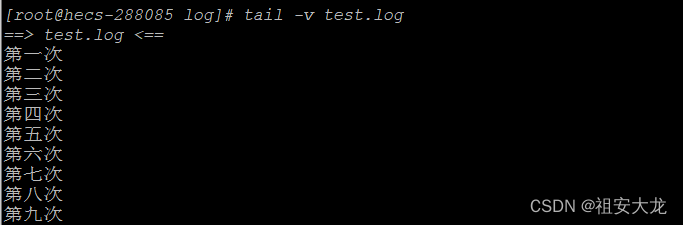
输出时总是输出文件的标头(文件名)
tail -v test.log
grep命令
grep命令是linux中一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep的命令是做文本匹配的,不会影响源文件的内容。多用于组合查询。
语法说明
Usage: grep [OPTION]... PATTERN [FILE]...
Search for PATTERN in each FILE or standard input.
PATTERN is, by default, a basic regular expression (BRE).
Example: grep -i 'hello world' menu.h main.c
上面的语法说明是使用grep --help打印出来的。其实就是在每个文件和标准输入找查找与pattern相匹配的内容,pattern默认是一个基本的正则表达式。例如grep -i 'hello world' menu.h main.c命令将会在menu.h和main.c两个文件中查找和hello world匹配的行并输出,-i表示不区分大小写,即HELLO world也是符合查询结果的。
匹配模式选择
-E, --extended-regexp 扩展正则表达式egrep
-F, --fixed-strings 一个换行符分隔的字符串的集合fgrep
-G, --basic-regexp 基本正则
-P, --perl-regexp 调用的perl正则
-e, --regexp=PATTERN 后面根正则模式,默认无
-f, --file=FILE 从文件中获得匹配模式
**-i, --ignore-case 不区分大小写**
-w, --word-regexp 匹配整个单词
-x, --line-regexp 匹配整行
-z, --null-data 一个 0 字节的数据行,但不是空行
上面的匹配模式种,比较重要和常用的是-i,命令为grep -i pattern filepath,该命令能够不区分匹配的大小写

我这里日志文件内容太多,所以使用了一个grep进行匹配后再使用一个grep进行查询演示,减少输出数量。
杂项
-s, --no-messages 不显示错误信息
**-v, --invert-match 显示不匹配的行**
-V, --version 显示版本号
--help 显示帮助信息
--mmap use memory-mapped input if possible
杂项中比较常用的是-v,使用命令 grep -v pattern filepath,能够将不匹配的行输出

输入控制
-m, --max-count=NUM 匹配的最大数
-b, --byte-offset 打印匹配行前面打印该行所在的块号码。
**-n, --line-number 显示的加上匹配所在的行号**
--line-buffered 刷新输出每一行
-H, --with-filename 当搜索多个文件时,显示匹配文件名前缀
-h, --no-filename 当搜索多个文件时,不显示匹配文件名前缀
--label=LABEL print LABEL as filename for standard input
**-o, --only-matching 只显示一行中匹配PATTERN 的部分**
-q, --quiet, --silent 不显示任何东西
--binary-files=TYPE 假定二进制文件的TYPE 类型;
TYPE 可以是`binary', `text', 或`without-match'
-a, --text 匹配二进制的东西
-I 不匹配二进制的东西
-d, --directories=ACTION 目录操作,读取,递归,跳过
-D, --devices=ACTION 设置对设备,FIFO,管道的操作,读取,跳过
**-R, -r, --recursive 递归调用**
--include=PATTERN 只查找匹配FILE_PATTERN 的文件
--exclude=PATTERN 跳过匹配FILE_PATTERN 的文件和目录
--exclude-from=FILE 跳过所有除FILE 以外的文件
-L, --files-without-match 匹配多个文件时,显示不匹配的文件名
**-l, --files-with-matches 匹配多个文件时,显示匹配的文件名**
**-c, --count 显示匹配的行数**
-Z, --null 在FILE 文件最后打印空字符
其中重要的分别是:
-n, --line-number 显示的加上匹配所在的行号
-o, --only-matching 只显示一行中匹配PATTERN 的部分
-R, -r, --recursive 递归调用
-l, --files-with-matches 匹配多个文件时,显示匹配的文件名
-c, --count 显示匹配的行数
grep -o pattern filename能够获取与pattern相匹配的内容,一般与正则表达式一起用。只输出匹配成功的内容。如图所示的比对情况。

grep -r pattern foldername当查询的是目录时,就必须带入-r或者-R,用于目录的递归查询。如果不带r就无法递归查询。

grep -l pattern [filename1 filename2]当要查询多个文件,或者递归查询的时候,可以用-l来找到与字符相匹配的文件名,如下

grep -c pattern filename使用-c会返回与pattern相匹配的文本行数

grep -n pattern filename返回匹配的行时也会返回其对应的行号

文件控制
-B, --before-context=NUM 打印匹配本身以及前面的几个行由NUM控制
-A, --after-context=NUM 打印匹配本身以及随后的几个行由NUM控制
-C, --context=NUM 打印匹配本身以及随后,前面的几个行由NUM控制
-NUM 根-C的用法一样的
--color[=WHEN],
--colour[=WHEN] 使用标志高亮匹配字串;
-U, --binary 使用标志高亮匹配字串;
-u, --unix-byte-offsets 当CR 字符不存在,报告字节偏移(MSDOS 模式)
grep -B1 pattern filename
表示查询到与pattern的行后再打印匹配行的前面若干行,这里写1则表示输入前1行。

如上图可以看到输出了匹配行的前3行,同理,-A命令就是输出匹配行的后面若干行,-C就是输入匹配行的前后各若干行。grep --color=[always,auto,nerver] pattern filename
表示对匹配到的行的匹配文本是否高亮显示,有三种选择,大致如下

综上差不多是grep基本的使用方法,grep很灵活,一般都是与其他查询组合使用,这里如果单独使用grep进行日志查询的,我建议查询的匹配条件是到日期过,因为没法查询区间,所以很难匹配到想要的结果,只能按照日期来找到当天或者某一天的结果,然后查询日志。
grep -n '2023-05-18' logs.log
也可以查询到当前日期的日志信息后,再结合关键词查询相应日志信息
grep -n '2023-05-18' logs.log | grep -i '关键词'
sed命令
语法格式
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]...
上面的语法格式是使用sed --help输出来的。sed [选项] '[动作]' 文件名
-n, --quiet, --silent
suppress automatic printing of pattern space
#使用-n会只返回匹配的行或者说只返回符合匹配条件的行
-e script, --expression=script
add the script to the commands to be executed
#使用-e可以执行多个动作,但是每个动作之间要用;分割
-f script-file, --file=script-file
add the contents of script-file to the commands to be executed
#从 sed 脚本中读入 sed 操作
--follow-symlinks
follow symlinks when processing in place
-i[SUFFIX], --in-place[=SUFFIX]
edit files in place (makes backup if SUFFIX supplied)
#在文件中进行编辑,编辑时将命令放在插入字符串开头。
#常用命令:
#a:追加 向匹配行后面插入内容
#c:更改 更改匹配行的内容
#i:插入 向匹配行前插入内容
#d:删除 删除匹配的内容
#s:替换 替换掉匹配的内容
#p:打印 打印出匹配的内容,通常与-n选项和用
#例如:sed -i 'atest' test.log 表示在匹配行后追加一test
-c, --copy
use copy instead of rename when shuffling files in -i mode
#不直接改写文件,复制的模式
-b, --binary
does nothing; for compatibility with WIN32/CYGWIN/MSDOS/EMX (
open files in binary mode (CR+LFs are not treated specially))
#匹配二进制
-l N, --line-length=N
specify the desired line-wrap length for the `l' command
--posix
disable all GNU extensions.
-r, --regexp-extended
use extended regular expressions in the script.
#使用正则表达式
-s, --separate
consider files as separate rather than as a single continuous
long stream.
-u, --unbuffered
load minimal amounts of data from the input files and flush
the output buffers more often
-z, --null-data
separate lines by NUL characters
--help
display this help and exit
--version
output version information and exit
举例
输出匹配的行
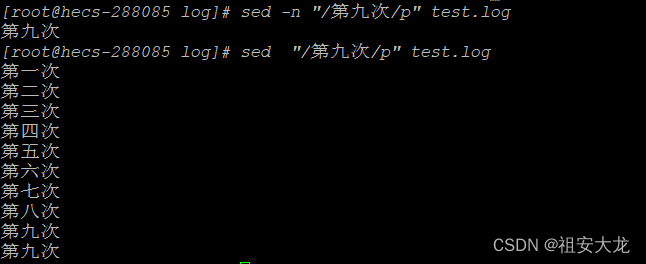
sed -n '/第一次/p' test.log
使用-n参数只会返回匹配到的行,如果不加-n则会返回所有行,因为sed是会将整个数据读到缓存里去比对的,所以其实它吧所有数据都比对过了,不加-n也就吧所有比对过的数据都输出。还有就是/表示数据未完结,/p表示数据结束,上面的代码语句查询文本中包含‘第一次’的记录,命令使用如下图
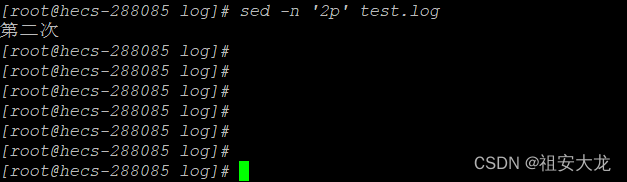
sed -n '2p' test.log
输出第二行匹配的内容
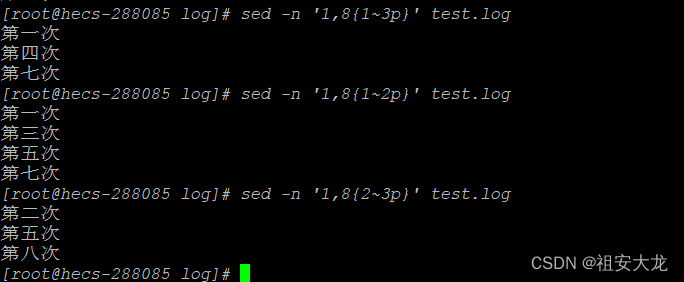
sed -n '1,3p' test.log #输出1~3行数据
sed -n '1,8{1~3p}' test.log #花括号里的1表示在后面3行里面的第几行,输出1~8行中,3行为1块,每1块中的第1行
sed -n '1,8{1~2p}' test.log #1~8行中切块,每块2行,输出每行中的第1行,即输出奇数,其他的举一反三
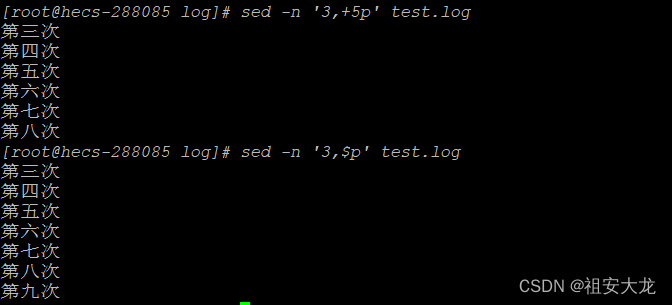
sed -n '3,+5p' test.log #从第3行开始输出,输出5行
sed -n '3,$p' test.log #从第3行开始输出,直到文件结尾。
执行多个动作脚本
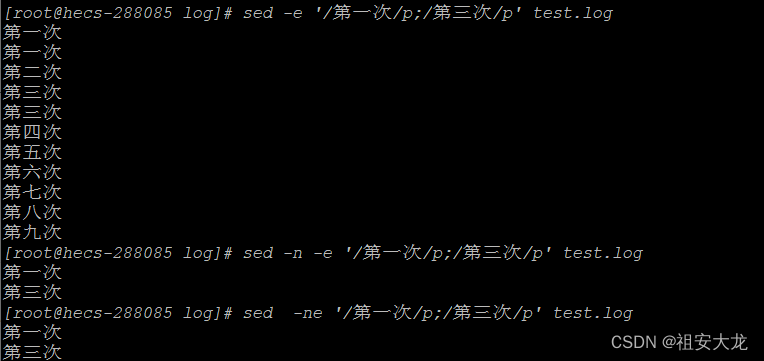
sed -e '/第一次/p;/第三次/p' test.log
使用-e时,有多个动作脚本就要冒号分开。
这篇博客写的比较详细:https://blog.csdn.net/a1158321146/article/details/123532275
使用命令组合查询日志信息
首先要查询日志信息,想grep和sed都能查询日志,可以有以下几种方式
mysqld.log日志格式

假设需求要查某一天的日志,可以有如下方法
grep -n --color=auto '2023-05-06T' mysqld.log #查询2023-05-06日的全天日志
grep -n --color=auto '2023-05-06T0[5-9]' mysqld.log #查询05点到09点的日志
sed -n '/2023-05-06T/p' mysqld.log #查询2023-05-06日的全天日志
sed -en '/2023-05-05T/p,/2023-05-06T/p' mysqld.log #查询05-05和05-06之间的数据。
其实综上,主要是对一个文本匹配的处理,真正想要实现日志的具体时间段读取,还是要通过后端代码的处理,而且不同软件日志格式不一样,可以用python的循环和文本匹配之类的操作对读出来的大概范围内的日志进行处理,比对时间大小,然后返回给客户端。