一、前言
哪怕在互联网时代高速发展的今天,文档依然是人们在日常生活、工作中产生的信息的重要载体。
学生的作业、开具的发票、医生的医嘱、合同、简历、金融票据等都是通过文档来呈现的,它在我们的生活中随处可见。
现在我们为了更高效、安全的开展业务,常常需要对文档信息进行识别提取,比如:检测传递的证件是否有效,通过识别身份证照自动录入其对应的信息,以及提取手写稿的文字等场景。因此,让计算机具备阅读、理解和解释这些文档图像的能力在许多领域都具有广阔的应用价值。
然而在现阶段,文档图像的处理过程中还面临着诸多挑战:文档类型的多样产生了繁杂的版式与结构;受拍摄器材、背景环境影响,图像时常存在噪声和质量问题等:

因为有这些问题的存在,导致在文档处理上很容易“翻车”!
幸运的是,业界有很多大佬都在努力攻克这些难点,也取得了一些进展。在这次CCIG(中国图象图形大会)上,这些大咖也做了分享,让我们来看看他们是如何面对这些问题的以及他们对文档处理的看法是怎样的。
二、大会分享
1)文档分析与识别快速进步,但仍有很大的研究空间
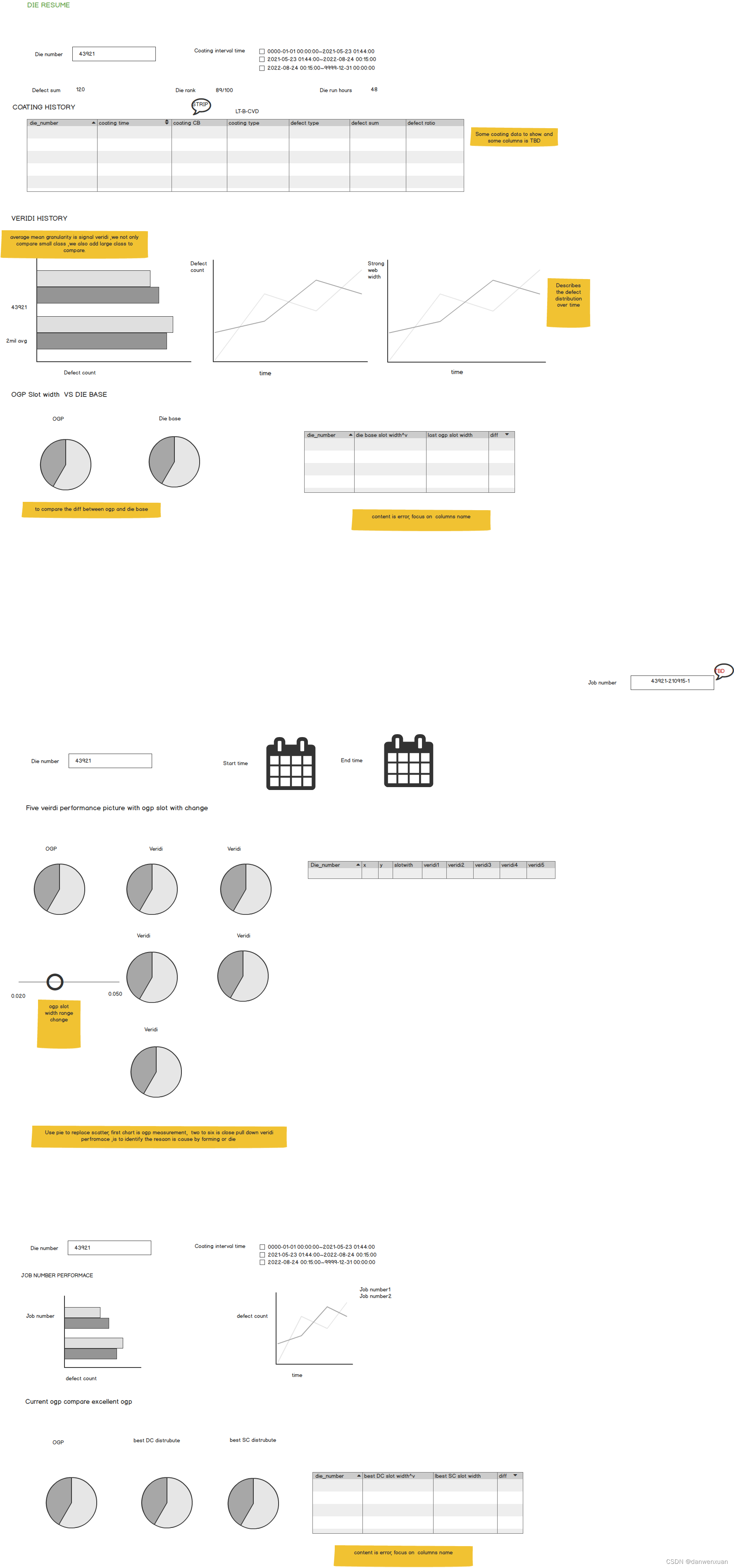
来自中国科学院自动化研究所的副所长刘成林分享了在人工智能大模型时代下,他对文档识别的理解。
他们团队的主要研究内容是在版面分析(分割),文本定位、文本识别、表格识别,信息提取、公式、图形、符号等:

刘成林所长在会上带我们回顾了文档识别的研究简史,介绍了文档的种类以及现存的问题:
还分享了他们的研究现状:

一句话概括就是部分场景成功应用,大部分场景还不好用,在可靠性、可解释性、自适应性方面还需要提升。
另外,也分享了大模型GPT-4在文档处理中的应用:

他认为现阶段的大模型仍有很多不足,大模型现在未进行大规模的验证,识别精度可能不高,OCR模型的设计仍然很重要。但我们还是可以在文档处理上充分利用大模型的特征表示及语言能力。
未来他们会以设计自动化,应用无人化为目标,通过深度学习+结构化模型,生成模型、领域知识,迁移学习,领域泛化(利用相关领域数据和知识)、弱监督学习,跨模态学习、预训练(自监督学习)等方法来解决文档中各种元素和内容,多语言,多场景,多类型文档这类的广度研究问题,和文档语义理解,可解释性,可信度,字符结构分析,小样本学习,自适应之类的深度研究问题。
我很认同刘成林的观点,虽然现阶段文档处理在大多场景的应用并不乐观,但利用大模型的特征表示及语言能力会是一个不错的改善方案。
2)篡改文本图像的生成与检测
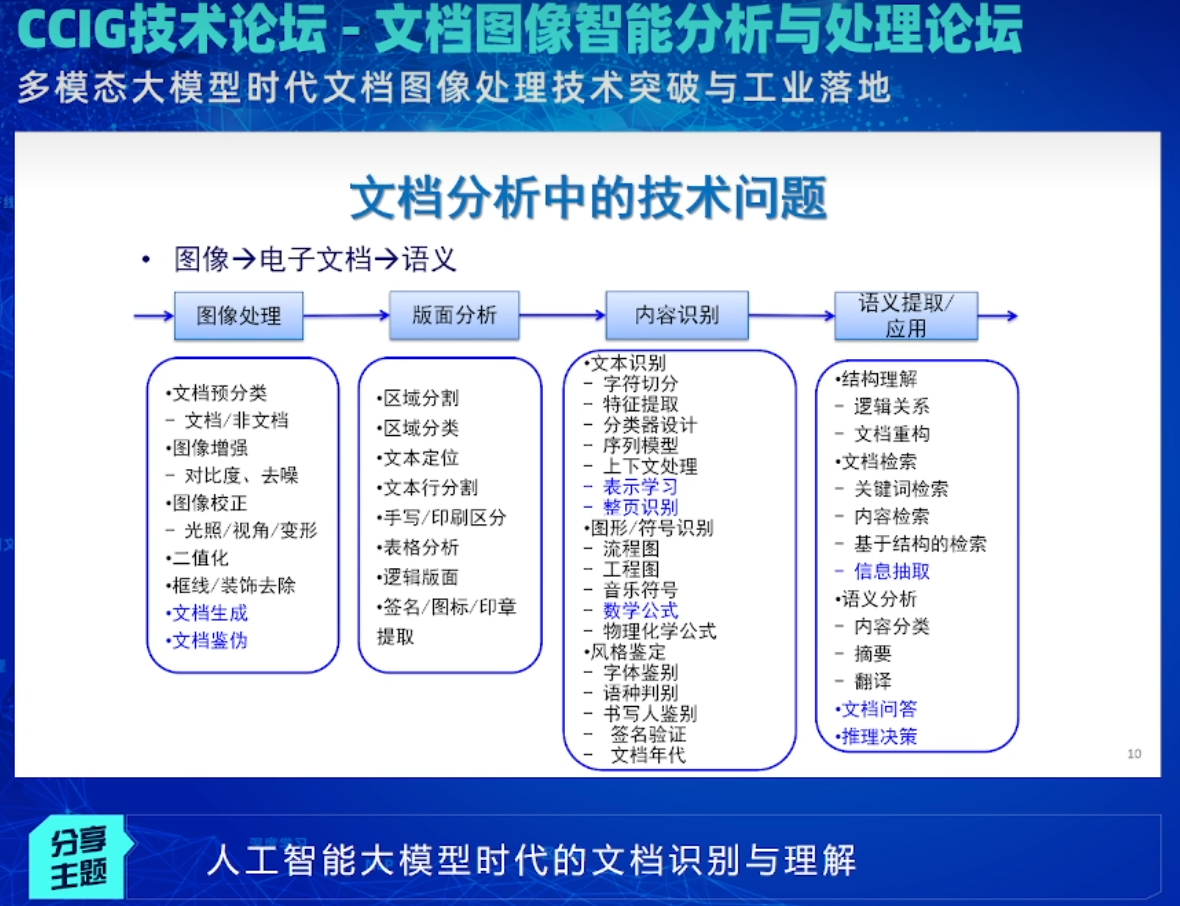
随着人工智能合成技术的发展,伪造多媒体信息在网络上泛滥成灾,干扰社会舆论和秩序,严重危害国家安全和社会稳定:
目前图像篡改生成与检测的研究都集中在自然图像,针对文本图像篡改生成与检测的相关研究较少。
2.1篡改文本图像生成
篡改文本图像生成指的是对场景图像中的指定文本进行编辑,在保留原始字体风格和背景纹理的同时,使目标文本尽可能清晰、容易辨认:

中国科学技术大学教授谢洪涛指出生成检测的任务难点是文字、字体、背景多样性:

也总结了现阶段几种常见模型的优缺点:
端到端场景文本擦除
1)EnsNet模型—通过条件对抗生成网络构建文本擦除器
优点:模型简单,提出文本擦除基本解决思路;
缺点:对复杂文本图像擦除效果较差;
2)EraseNet模型—引入文本感知分支,提升网络对文本区域的捕捉能力
优点:引入多级擦除策略,对擦除效果提升明显;
缺点:网络结构相较复杂,参数量较厚重;
3)CTRNet模型—以低维结构信息和高维上下文特征作为先验知识指导文本擦除和背景重建过程
优点:多维语义先验引入指导文字擦除和背景重建,针对复杂背景效果好;
缺点:同样依赖于GAN loss,训练过程相对复杂;
端到端场景文本篡改
1)SRNet模型—将文本部分和背景部分的生成方法分开学习,然后通过融合算法生成篡改图像
优点:模型简单,对简单文本篡改效果不错;
缺点:对复杂背景的文本图像篡改效果较差,对复杂字型有较重篡改痕迹;
2)SwapText模型—对目标文本形状先进行TPS变换,降低目标风格文本的合成难度
优点:对于曲形文本的篡改效果较好;
缺点:网络对整幅图像块进行编辑,存在对非文本区域的过度篡改;
3)TextStyleBrush模型—基于StyleGAN的篡改生成框架,能够自监督训练
优点:能够在真实数据集上训练;
缺点:网络结构复杂,模型难以收敛;
他们认为在场景文本图像擦除方面,之前的方法存在这些问题:没有显性解耦定位和重建操作,极大地增加了网络的学习难度,导致背景过度擦除,所有多阶段网络都采用相同的标签进行监督,无法平衡每个阶段的学习难度和网络结构,导致文字擦除不彻底。
所以他们的方法是基于迭代局部擦除的场景文本擦除,构建显性解耦的擦除网络,提出基于局部编辑的擦除策略,提升背景纹理完整性,构建平衡的多阶段擦除网络,提升文字擦除彻底性。
在场景文本图像篡改方面,存在需要文本风格图的监督,使其只能在合成数据集上训练。合成数据集与真实数据集的差异,导致网络在真实场景下篡改效果不佳;都是对图像块的所有像素点进行编辑,并未区分前景和背景区域,存在对非文本区域的过度篡改,所以他们以简化篡改文本生成网络,去掉不必要的监督过程;针对性地篡改,仅对文字区域进行编辑操作给出了针对笔迹级修改的篡改文本图像生成网络的方法。
现阶段他们还面临一些问题:

2.2 篡改文档检测
篡改文档检测是检测文本图像中所有文本实例,并在此基础上对文本真伪性进行鉴别,包含文本定位和文本真伪性鉴别两个步骤。
篡改文档检测的应用场景是非常广泛的且非常重要:
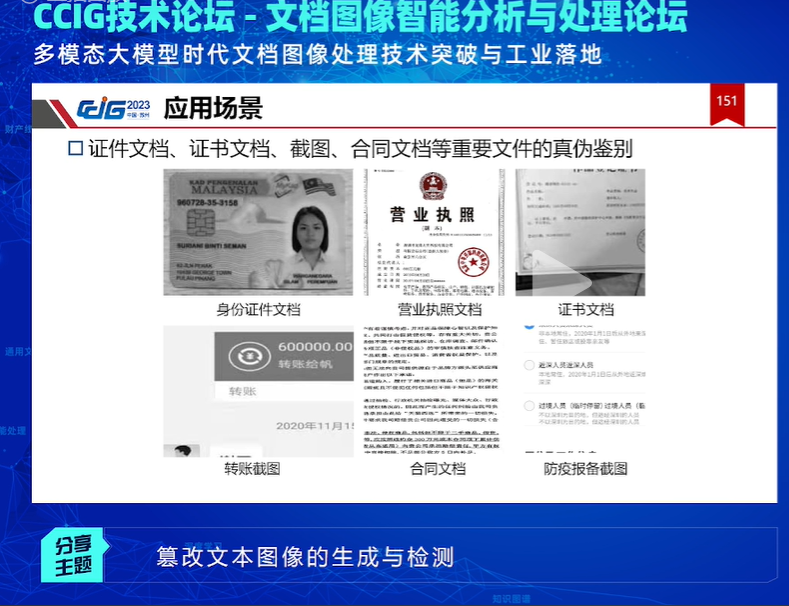
谢洪涛教授认为篡改文档检测的难点在于篡改文本和真实文本具有相同的语义(文本位置、几何结构),仅在局部纹理中存在一定差异,高质量的篡改文档图像数据获取困难,导致篡改文本检测网络很难在小规模样本下学到具有区分力的篡改特征:

他也分析了主流的检测方法优缺点,分享了他们课题组的检测方法——构建通用篡改文本检测器,进行多分类目标检测任务,继承场景文本检测其对文本检测的有效性及低数据依赖。
现阶段,同样存在一些问题:

谢洪涛教授认为篡改文本的生成与检测是矛与盾的良性互动的发展过程,还需要多领域的持续关注。
3)智能文档处理技术让世界更高效
来自上海合合信息科技股份有限公司智能技术平台事业部副总经理,高级工程师丁凯介绍了他们公司的一些产品服务和使命:致力于通过智能文字识别及商业大数据领域的核心技术、C端和B端产品以及行业解决方案为全球企业和个人用户提供创新的数字化、智能化服务,以此来让世界更高效!

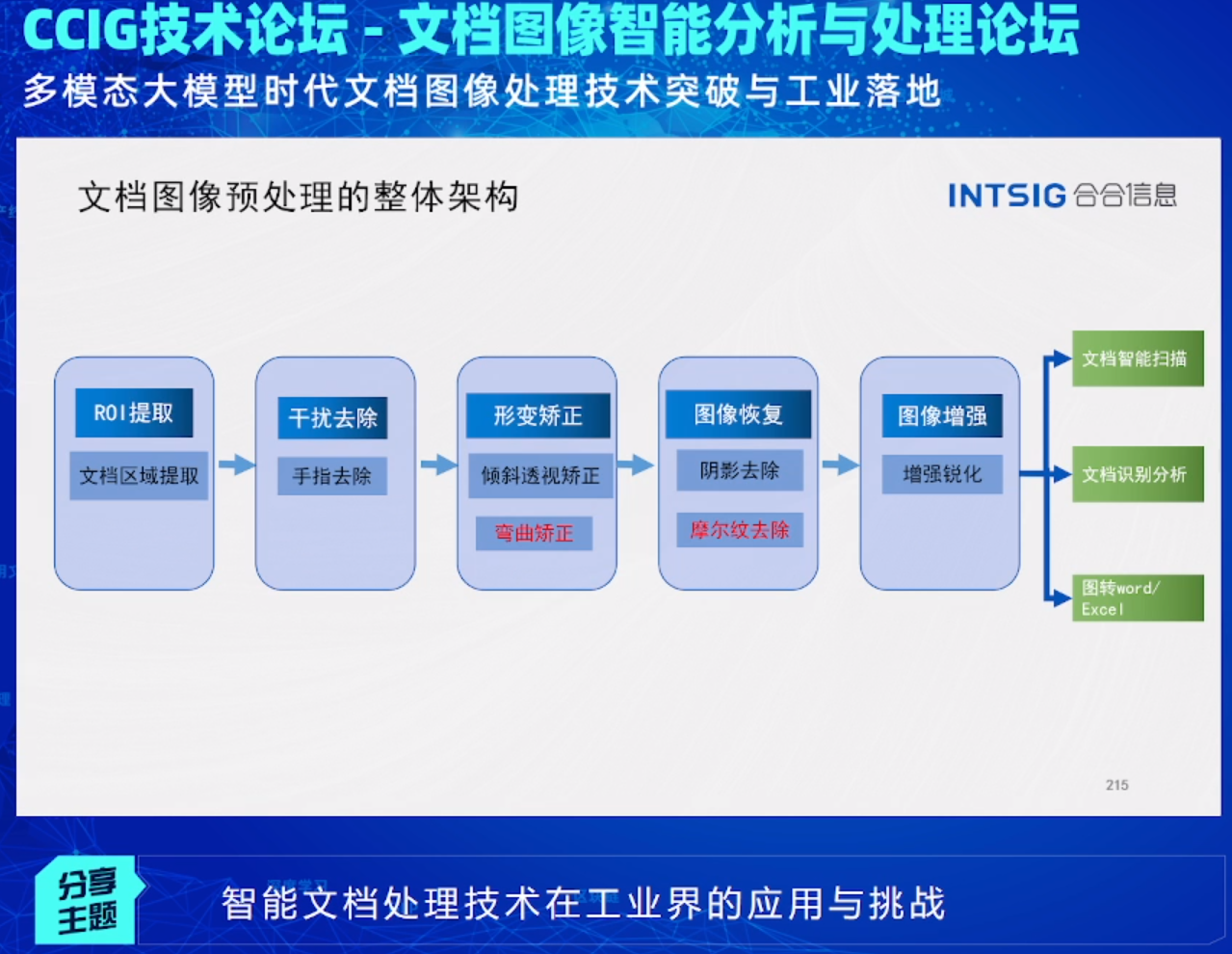
丁凯工程师介绍了他们在预处理存在弯曲、阴影、摩尔纹、不清晰的图像时的整体架构:
以及图像弯曲矫正的方法从“只取头尾”到坐标变化再到基于偏移场的方法,建立起弯曲矫正系统的pipeline:


在黑板、手写板上进行拍摄时,无可避免的遇到反光的影响,他们团队通过反光擦除技术,保留笔画细节,清晰还原反光板内容:

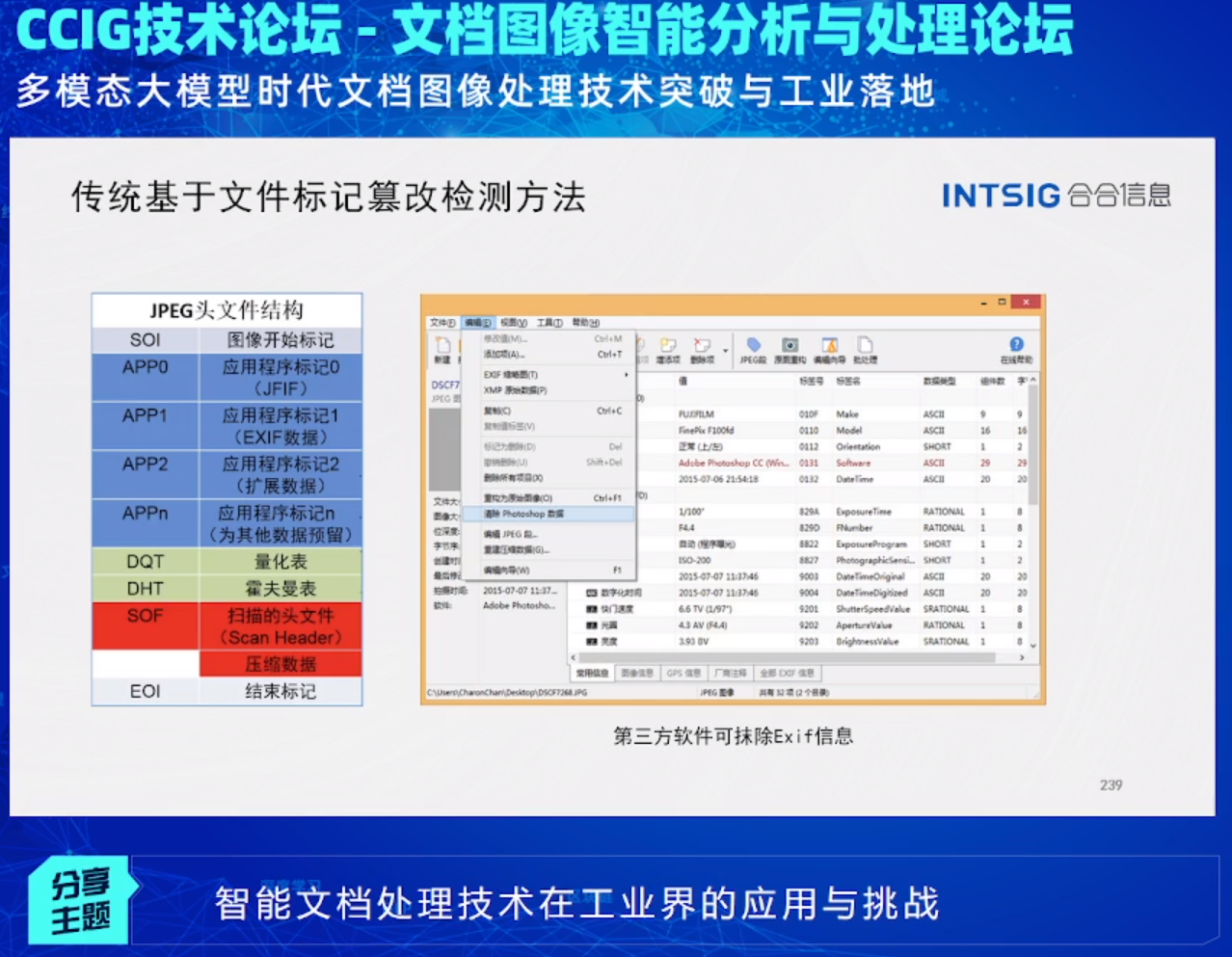
合合信息同样在文档图像篡改检测领域上有所建树,丁凯工程师指出了传统的基于文件标记篡改检测方法并不能有效的判断图片是否有被篡改,因为第三方软件可以抹除Exif信息:
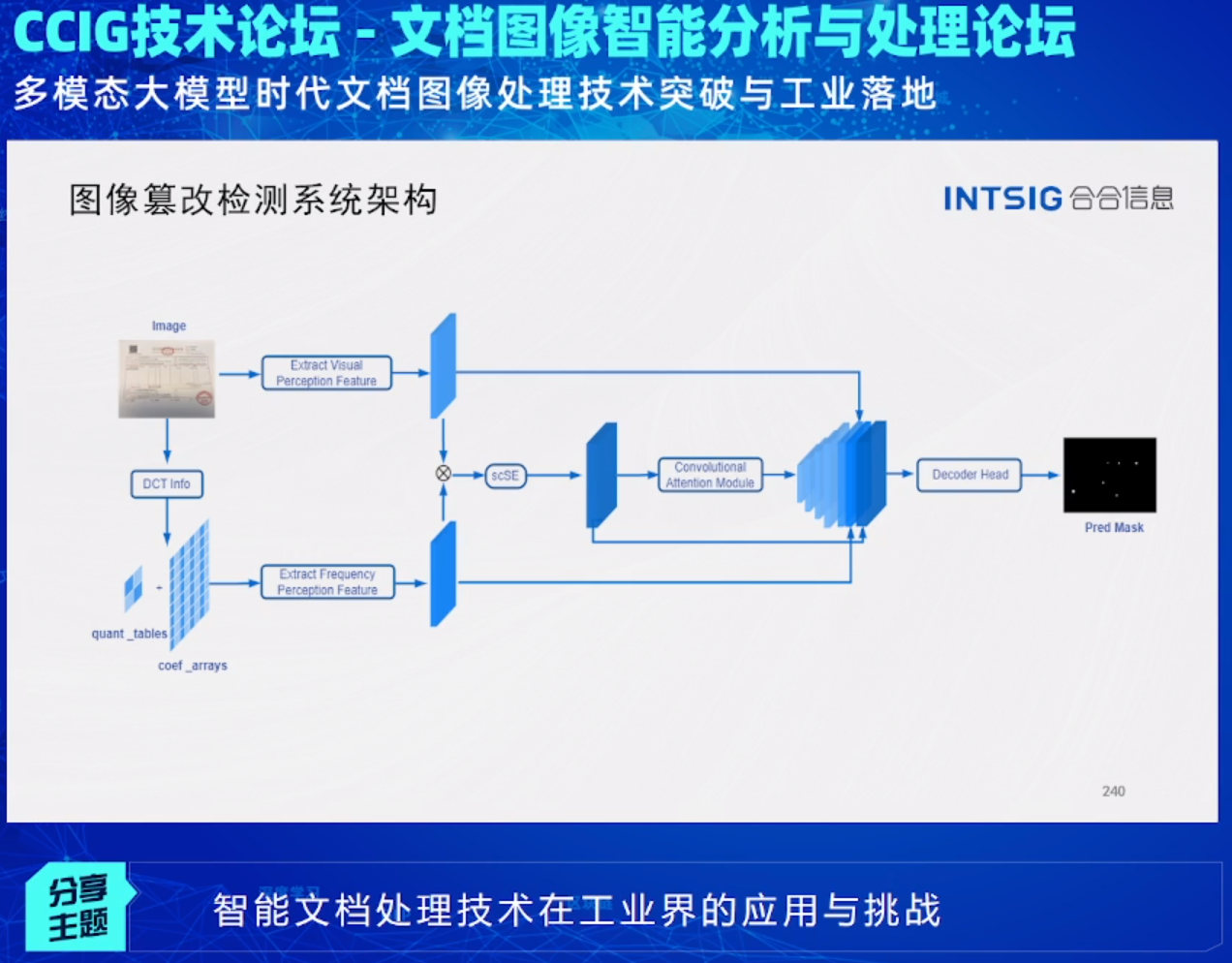
之后他分享了他们检测系统的架构和技术:
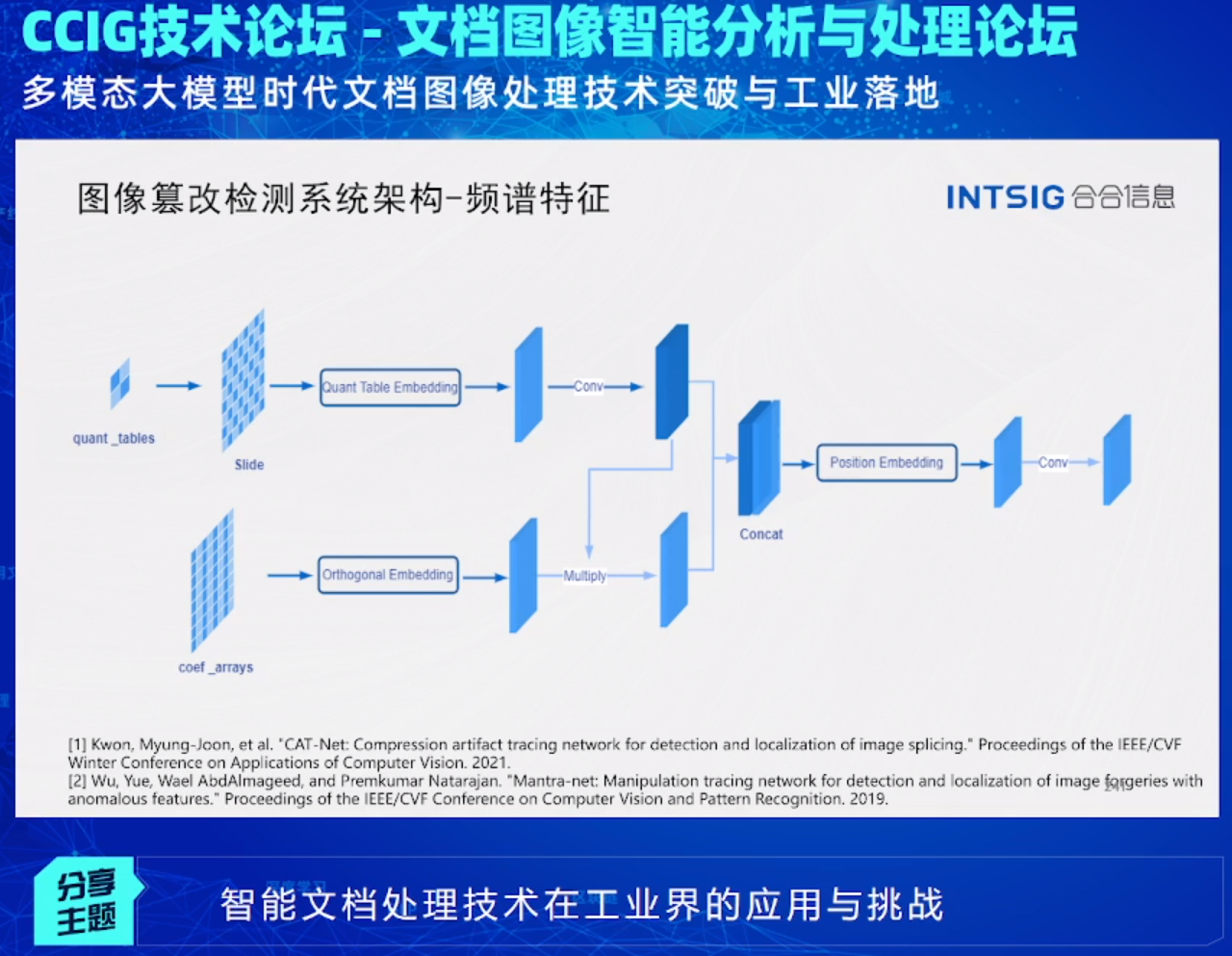
此外,他们的PS检测和摩尔纹去除等服务我之前也使用过,效果都很不错,特别是PS检测方面,它也一直是很多行业迫切需要的,尤其是在保险、金融、银行等领域,如果将虚假篡改过的信息资料审核通过可能会带来巨大的影响甚至是经济上的损失:

三、总结
众所周知,现在是数字化的时代,越来越多的企业都在走向数字化的转型。然而,现实中80%的商业数据都是非结构化格式,比如邮件、图片和各种企业文档,其中非结构化文档占据了绝大多数。这样让数字化转型变得非常困难。因此,如果能实现让企业实现文档自动化处理、智能审核、自动录入等文档处理方面的功能,那一定是非常有商业前景和价值的事情。
而且随着人工智能技术的飞速发展,文档图像智能处理在医疗、教育、金融等诸多领域都会被应用,为各行各业提供更加高效、智能的文档管理和数据分析解决方案。
经过这次大会我认为,即便现在依然面临着许多困难,但我相信在不久的将来都会迎刃而解!