目录
前言
两数相加
删除链表的倒数第N个结点
环形链表
相交链表
合并 K 个升序链表
复制带随机指针的链表
前言
初学者在做链表的题目时有一个特点,就是每看一个链表的题都觉得很简单,但真正到了扣代码的时候不是这卡一块就是那卡一块。这是因为链表的题目往往并不会涉及很难的算法,但确很考验对边界问题的处理以及扣代码的能力。所以链表的题目看似简单,却不可忽视。初学者切忌好高骛远,觉得一看就会、很简单就不做了,最终只会害了自己。
两数相加
题目描述
2. 两数相加![]() https://leetcode.cn/problems/add-two-numbers/
https://leetcode.cn/problems/add-two-numbers/
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
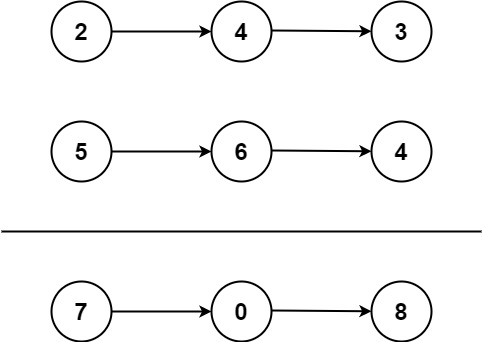
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
示例 2:输入:l1 = [0], l2 = [0]
输出:[0]
示例 3:输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
提示:
每个链表中的节点数在范围 [1, 100] 内
0 <= Node.val <= 9
题目数据保证列表表示的数字不含前导零来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/add-two-numbers
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题目分析
这题一看感觉很简单,不就是我们小学学的列竖式的加法运算吗。但小白本人在第一次做这道题的时候却被卡了很多次。虽然我们一看题目就知道思路,但在前期代码能力不强的情况下,把想法落实到代码上却是一个很艰难的过程。
我们就模拟竖式加法来做。首先让两个链表中对应位置的数字相加,然后将和的个位添加到新的需要返回的链表中。此时需要借助一个额外的变量用来存储进位的数,然后在下一个位置的时候再另外把这这个数加上。循环往复,直至最后。但有一个很容易被卡住的点,就是如果两个链表中如果有一个链表先走到最后的NULL位置,就很容易出现访问NULL的错误点(这是新手很容易忽略的一个点)。另外,在走到最后的时候还需要检查一下是否还有一个需要进位的数,以防止结果的遗漏。具体的代码实现可以参照下方内容。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2)
{
int tmp_quotient = 0;
ListNode* ListHead = nullptr, *ListTail = nullptr;
//l1或l2:当l1和12都为nullptr(都走到尾结点)
while(l1 || l2)
{
//提取当前位数的数字,如果当前节点为nullptr就用0代替
int tmp_num1 = l1 != nullptr ? l1 -> val : 0;
int tmp_num2 = l2 != nullptr ? l2 -> val : 0;
//将提出来的两位数与上次进位的数相加
int tmp_sum = tmp_num1 + tmp_num2 + tmp_quotient;
//将余数存入链表,满十进一
if(ListHead != nullptr)
{
ListTail -> next = new ListNode(tmp_sum % 10);
ListTail = ListTail -> next;
}
else
{
ListHead = ListTail = new ListNode(tmp_sum % 10);
}
tmp_quotient = tmp_sum / 10;
//l1、l2没到头就继续向后走
if(l1)
l1 = l1 -> next;
if(l2)
l2 = l2 -> next;
}
//检查是否需要插入最后一位
if(tmp_quotient > 0)
{
ListTail -> next = new ListNode(tmp_quotient);
}
return ListHead;
}
};删除链表的倒数第N个结点
题目描述
19. 删除链表的倒数第 N 个结点![]() https://leetcode.cn/problems/remove-nth-node-from-end-of-list/
https://leetcode.cn/problems/remove-nth-node-from-end-of-list/
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
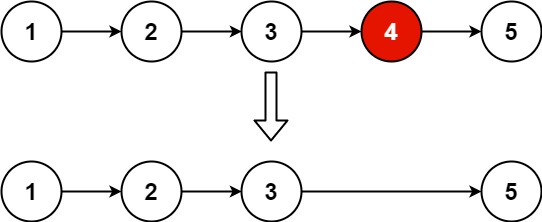
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:输入:head = [1], n = 1
输出:[]
示例 3:输入:head = [1,2], n = 1
输出:[1]
提示:
链表中结点的数目为 sz
1 <= sz <= 30
0 <= Node.val <= 100
1 <= n <= sz来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/remove-nth-node-from-end-of-list
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题目分析
这题很会很容易理解的一个思路就是双指针,即设置两个指针fast和slow。fast先走n-1步,然后fast和slow一起走,当fast走到最后就停止。但这里如果没拿捏好是很容易出错的,首先为什么fast先走n-1步而不是n步呢?这里我们可以通过分析示例的方式来理解。实例分析是一个很好用的方法,当遇到这种不确定具体需要走多少步之类的问题时,结合实例分析之后会很容易得出结论,而且并不需要浪费很多时间。比如这里假定删除的是倒数第1个个数,那么fast最终是和slow一起走到最后的,所以fast要往前走0步,那么n-1就得出来了。
那么具体实现时还需要考虑另一个问题,即如果删除的是头节点,即刚好倒数第n个位置刚好为链表的head,那么我们还需要对这种情况额外进行单独讨论处理。这是比较麻烦的,而对于这种需要考虑删除头节点情况的问题,我们一般选择借助一个额外的哑节点来解决。让哑节点的next指向需要处理链表的head节点,那么从哑节点开始操作,最后返回哑节点的next就很好的避免了还要对头节点额外讨论的冗杂情况。这两种写法都在下面了。
不带哑节点的写法:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution
{
public:
ListNode* removeNthFromEnd(ListNode* head, int n)
{
//先找到倒数第n+1个节点
ListNode* fast = head;
ListNode* slow = head;
while(n--)
fast = fast->next;
while(fast && fast->next)
{
fast = fast->next;
slow = slow->next;
}
//删除头节点的情况需要额外判断
if(fast == nullptr)
return head->next;
ListNode* next = slow->next;
slow->next = next->next;
delete next;
return head;
}
};带哑节点的写法:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummy = new ListNode;
dummy->next = head;
int len = 0;
while(head)
head = head->next, len++;
ListNode* cur = dummy;
while(len-- > n)
cur = cur->next;
cur->next = cur->next->next;
return dummy->next;
}
};环形链表
题目分析
141. 环形链表![]() https://leetcode.cn/problems/linked-list-cycle/
https://leetcode.cn/problems/linked-list-cycle/
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:
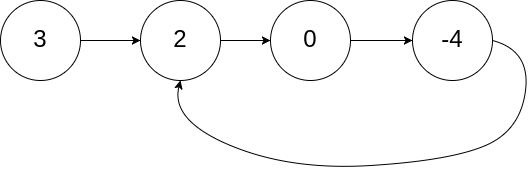
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
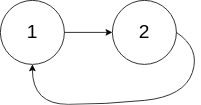
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
提示:
链表中节点的数目范围是 [0, 104]
-105 <= Node.val <= 105
pos 为 -1 或者链表中的一个 有效索引 。来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/linked-list-cycle
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

题目分析
这题就是属于那种知道就会,不知道就不会的那种。因为大多数人第一次接触这题很难有思路,但一旦知道怎么做之后很快就记住了。所以这题的重点并不在于如何解出来,而是在于如何证明这样解是就是对的。
好了我们不多废话,直接看解法:先定义一对快慢指针fast和slow,它们分别都从头开始,fast每次向后走两步,slow每次向后走一步。如果出现fast==slow的情况,那么就是有环。否则如果fast如果走到了NULL,那就说明没环。写法如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head)
{
if(head == NULL)
return false;
struct ListNode *fast = head, *slow = head;
while(fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
if(slow == fast)
return true;
}
return false;
}接下来我们开始证明:
如果没有环,那么fast就不会进入到环中循环,那么最终就会遇到NULL,说明此链表没环。
如果链表中存在环,我们设fast刚走到带环部分时的位置为f1,当slow刚走到带环部分的位置时fast的位置为f2,令f2-f1=x。设环的长度为C,那么此时fast与slow的距离即为C-x,令C-x=L。那么此时就是一个典型的追及相遇问题。
小红和小明都在一个环形跑道上跑步,小红在小明前方L处,小明的速度是小红的2倍,问小明可以追上小红吗?答案是当然可以,由于小明的速度是小红的2倍,所以小红每走a的距离,那么小明就走2a的距离,即它们之间的距离就缩小a,那么当a恰好为L的时候就刚好追上,而且还是在第一圈就追上了。
注意,这里的fast并不是严格的每次需要走2步,其实走3步、4步也是可以的,但这样很容易在“第一圈”的时候错过,需要多走几圈,效率就变低了。
相交链表
题目描述
160. 相交链表![]() https://leetcode.cn/problems/intersection-of-two-linked-lists/
https://leetcode.cn/problems/intersection-of-two-linked-lists/
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0
listA - 第一个链表
listB - 第二个链表
skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数
skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。示例 1:
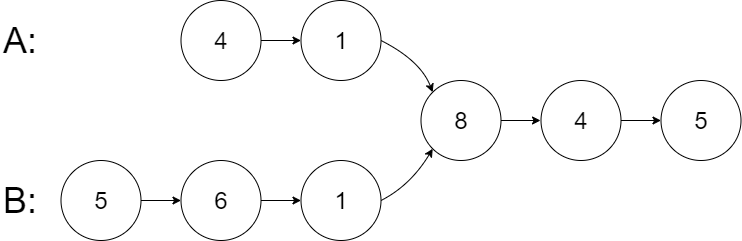
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
示例 2:
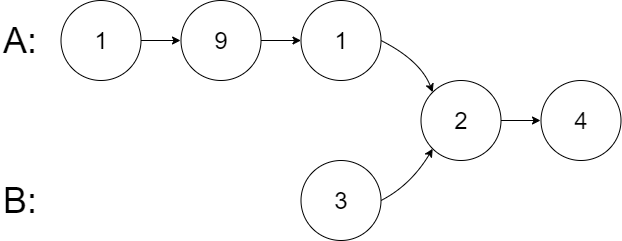
输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
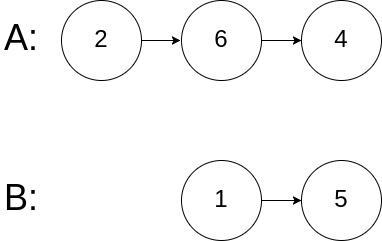
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
提示:
listA 中节点数目为 m
listB 中节点数目为 n
1 <= m, n <= 3 * 104
1 <= Node.val <= 105
0 <= skipA <= m
0 <= skipB <= n
如果 listA 和 listB 没有交点,intersectVal 为 0
如果 listA 和 listB 有交点,intersectVal == listA[skipA] == listB[skipB]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/intersection-of-two-linked-lists
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

题目分析
这题一个很好理解的思路是快慢指针,先求出两个链表的长度,然后让长的链表先走它们的长度之差步(这里也要分析好具体是先走多少步),然后再让两个链表一起走,当走到相同链表时就是相交点了。代码如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)
{
if(headA == NULL || headB == NULL)
return NULL;
struct ListNode *pA = headA, *pB = headB;
int lenA = 0, lenB = 0;
while(pA) lenA++, pA = pA->next;
while(pB) lenB++, pB = pB->next;
int len = abs(lenB - lenA);
struct ListNode* longList = lenA > lenB ? headA : headB;
struct ListNode* shortList = longList == headA ? headB : headA;
while(len--) longList = longList->next;
while(shortList)
{
if(longList == shortList)
return longList;
longList = longList->next;
shortList = shortList->next;
}
return NULL;
}但这题想介绍的并不是这个思路,而是下面这个思路:让两个链表一起走,当走到NULL时就让其从另一个链表的头部,这样当走到相同链表时就是相交点。
这个思路很好记,但也是重在理解。我们设两个链表不相交的部分长度分别为m和n,相交部分长度为L,那么当第一个链表走到NULL时就已经走了m+L的距离,此时其跑到另一个链表的头部,而另一个链表此时也是走了m+L的距离(不论它是否已经走到NULL并跑到另一个链表中,并且一定没有第二次走到相交部分),而当第一个链表再次走到首个相交位置时,其已经走过了m+L+n的距离,那么同理另一个链表也是走过这么多距离,所以此时他们一定是位于同一个节点的。
通过上面两个题我们可以发现,对于链表相交、有环的这一类的题目,一般都是双指针或者快慢指针的思路,然后分析两个指针之间的数量关系,进而得出一个“公式”,利用这个“公式”就可以解决题目了
合并 K 个升序链表
题目描述
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例 2:输入:lists = []
输出:[]
示例 3:输入:lists = [[]]
输出:[]
提示:
k == lists.length
0 <= k <= 10^4
0 <= lists[i].length <= 500
-10^4 <= lists[i][j] <= 10^4
lists[i] 按 升序 排列
lists[i].length 的总和不超过 10^4来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/merge-k-sorted-lists
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题目分析
为了便于理解,我们在解决这道题之前先有一个函数可以排序两个升序链表,并返回排序后的链表。其实就是21. 合并两个有序链表这题,因为这题也不怎么难,所以就不再写题解了。
那么我们很容易想到的一个思路就是从头到尾将lists遍历一遍,每次合并头上的两个链表,直至最后。具体写法如下:
//写法1:顺序合并
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution
{
public:
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
if(list1 == NULL && list2 == NULL)
return NULL;
if(list1 == NULL)
return list2;
if(list2 == NULL)
return list1;
struct ListNode* preHead = (struct ListNode*) calloc (1,sizeof(struct ListNode));
struct ListNode* tail = preHead;
while(list1 || list2)
{
if(list1 == NULL)
{
tail->next = list2;
break;
}
if(list2 == NULL)
{
tail->next = list1;
break;
}
if(list1->val > list2->val)
{
tail->next = list2;
list2 = list2->next;
}
else
{
tail->next = list1;
list1 = list1->next;
}
tail = tail->next;
}
return preHead->next;
}
ListNode* mergeKLists(vector<ListNode*>& lists)
{
if(lists.empty())
return NULL;
int len = lists.size();
ListNode* cur = lists[0];
for(int i = 0; i < len - 1; i++)
{
ListNode* next = lists[i + 1];
cur = mergeTwoLists(cur, next);
}
return cur;
}
};其实还可以进一步优化,我们可以将这个链表分为左右两部分,然后将左右两部分各自合并,最后将左右部分再合并就可以了。即分治的思路。不了解分治的可以看一下这篇博客的最后一个例题
递归详解 - C语言描述_小白麋鹿的博客-CSDN博客![]() https://yt030917.blog.csdn.net/article/details/128678166代码实现如下:
https://yt030917.blog.csdn.net/article/details/128678166代码实现如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution
{
public:
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
if(list1 == NULL && list2 == NULL)
return NULL;
if(list1 == NULL)
return list2;
if(list2 == NULL)
return list1;
struct ListNode* preHead = (struct ListNode*) calloc (1,sizeof(struct ListNode));
struct ListNode* tail = preHead;
while(list1 || list2)
{
if(list1 == NULL)
{
tail->next = list2;
break;
}
if(list2 == NULL)
{
tail->next = list1;
break;
}
if(list1->val > list2->val)
{
tail->next = list2;
list2 = list2->next;
}
else
{
tail->next = list1;
list1 = list1->next;
}
tail = tail->next;
}
return preHead->next;
}
ListNode* mergeKLists(vector<ListNode*>& lists)
{
if(lists.empty())
return NULL;
if(lists.size() == 1)
return lists[0];
if(lists.size() == 2)
return mergeTwoLists(lists[0], lists[1]);
int len = lists.size();
int mid = len / 2;
vector<ListNode*> left_list(lists.begin(), lists.begin() + mid);
vector<ListNode*> right_list(lists.begin() + mid, lists.end());
ListNode* left = mergeKLists(left_list);
ListNode* right = mergeKLists(right_list);
return mergeTwoLists(left, right);
}
};复制带随机指针的链表
题目描述
138. 复制带随机指针的链表![]() https://leetcode.cn/problems/copy-list-with-random-pointer/
https://leetcode.cn/problems/copy-list-with-random-pointer/
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。示例 1:
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:
输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:
输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000
-104 <= Node.val <= 104
Node.random 为 null 或指向链表中的节点。来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/copy-list-with-random-pointer
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。



题目分析
题目看起来有些长,简单说明一下就是:有一个链表,其节点不光有val和next还有有一个指向随机几点的random指针,要求我们完全拷贝这个链表,其中random的指向也要相同。
这题的一个思路就是用一个哈希表,将新链表和旧链表的节点一一对应,从前往后遍历旧的链表,其旧的random指向的节点在哈希表中与之对应的就是新的节点,所以可以根据这个来完成随机链表的拷贝。
但另一个更好理解并且效率更高的思路是:在原链表中每一个节点后面添加一个节点,并复制其val值,其random就应该指向与之对应的原链表节点的下一个,然后将新节点分离出来即可。具体写法如下:
/**
* Definition for a Node.
* struct Node {
* int val;
* struct Node *next;
* struct Node *random;
* };
*/
struct Node* copyRandomList(struct Node* head)
{
/*思路:
将原始链表中的每一个节点后面放一个newnode,然后填充好newnode之后再把newnode分出来。这三个步骤分别用三个循环搞定。
*/
if(head == NULL)
return NULL;
struct Node* tmp;
tmp = head;
while(tmp)
{
struct Node* next = tmp->next;
struct Node* newNode = (struct Node*) malloc (sizeof(struct Node));
newNode->val = tmp->val;
newNode->next = next;
tmp->next = newNode;
tmp = next;
}
tmp = head;
while(tmp)
{
struct Node* next = tmp->next;
next->random = tmp->random != NULL ? tmp->random->next : NULL;
tmp = next->next;
}
tmp = head;
struct Node* newNode = head->next;
while(tmp->next->next)
{
struct Node* next = tmp->next;
struct Node* nnext = next->next;
next->next = nnext->next;
tmp->next = nnext;
tmp = tmp->next;
}
return newNode;
}