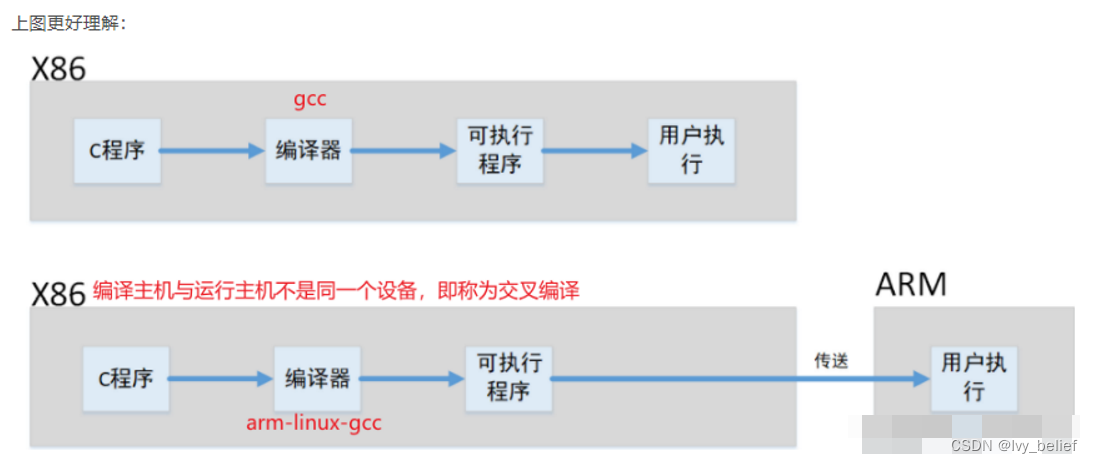
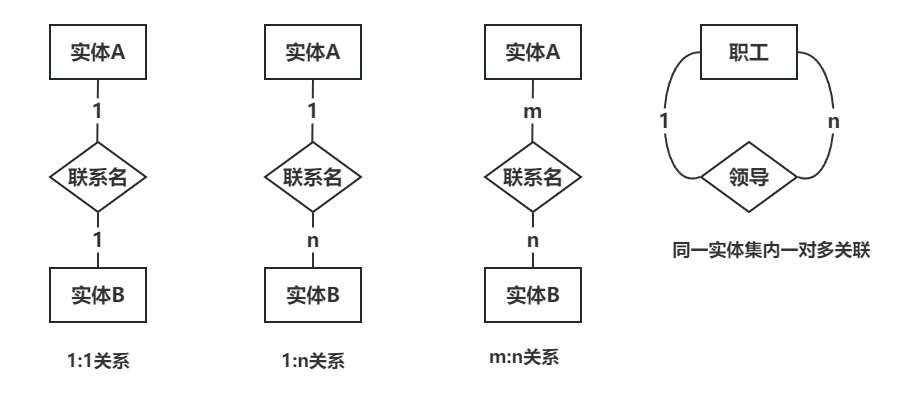
对于每种心率下给出的数据,我们需要进行合并才能方便后续处理,这里为大家展示利用python以及matlab分别实现合并的代码
import pandas as pd
import os
# 创建一个空的DataFrame对象
merged_data = pd.DataFrame()
# 设置数据文件所在的文件夹路径
folder_path = 'your_folder_path'
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
if filename.endswith('.csv'): # 假设文件是以.csv格式存储的
file_path = os.path.join(folder_path, filename)
# 读取文件数据
data = pd.read_csv(file_path, header=None)
# 将文件数据添加到合并的DataFrame中
merged_data = pd.concat([merged_data, data], axis=1)
# 保存合并后的数据到Excel文件
merged_data.to_excel('merged_data.xlsx', index=False)请将 'your_folder_path' 替换为实际数据文件所在的文件夹路径。假设所有数据文件都是以 .csv 格式存储的,如果不是,请根据实际情况修改代码中的文件格式条件判断部分。
这段代码将遍历指定文件夹中的所有数据文件,读取每个文件的数据,然后将它们按列合并到一个名为 merged_data 的DataFrame对象中。最后,将合并后的数据保存到一个名为 'merged_data.xlsx' 的Excel文件中,其中 index=False 参数用于不保存行索引。
MATLAB实现
% 设置数据文件所在的文件夹路径
folderPath = 'your_folder_path';
% 获取文件夹中所有的数据文件
fileList = dir(fullfile(folderPath, '*.csv')); % 假设文件是以.csv格式存储的
% 创建一个空矩阵用于存储合并后的数据
mergedData = [];
% 遍历所有数据文件
for i = 1:numel(fileList)
% 读取当前文件的数据
filePath = fullfile(folderPath, fileList(i).name);
data = csvread(filePath);
% 将数据添加到合并后的矩阵中
mergedData = [mergedData, data];
end
% 将合并后的数据保存到一个新的文件
outputFilePath = fullfile(folderPath, 'merged_data.csv');
csvwrite(outputFilePath, mergedData);请将 'your_folder_path' 替换为实际数据文件所在的文件夹路径,并确保所有数据文件的格式与代码中指定的一致(在示例中假设为 .csv 格式)。
这段MATLAB代码会遍历指定文件夹中的所有数据文件,逐个读取文件的数据,并将它们按列合并到一个名为 mergedData 的矩阵中。最后,它将合并后的数据保存到一个新的文件 'merged_data.csv' 中。
代码结果示意图,如下所示