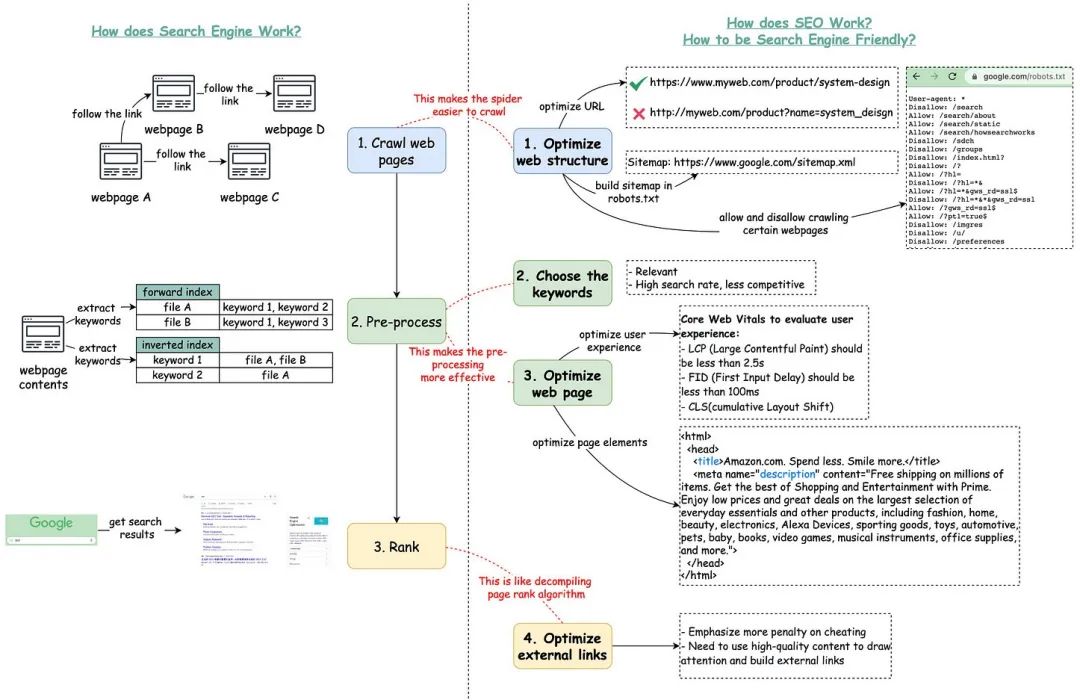
大家好,最近突然发现了一篇在专门应用于医学领域的LLaMA,名为Dr.LLaMA(太卷了太卷了),就此来分享下该语言模型的构建方法和最终的性能情况。
论文:Dr. LLaMA: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation
地址:https://arxiv.org/pdf/2305.07804.pdf
代码:https://github.com/zguo0525/Dr.llama进NLP群—>加入NLP交流群
总体说一下
最近的大语言模型(LLM)发展的太快了,大家也都知道,每周好几个语言模型,羊驼的名字都用不过来了(LLaMA、Alpaca、Vicana、华驼等),哈哈。
由于现有的模型很大(GPT4、ChatGPT),性能表现非常好,但是很多特定小方向性能还是不是那么的好,所以就有想构建特定领域小语言模型的想法。
但是在特定领域中会有 1.计算费用和效率低下的问题;2.训练数据较少 的问题,很多小语言模型(SLM)经常会卡在上述情况中不能自拔。
在本文中,介绍了Dr.LLaMA,这是一种通过LLM生成数据增强来改进SLM,同时重点关注医学问答任务和PubMedQA数据集。
本文探索了 1.有效在小模型上finetune的方法对比(Prefix-tuning vs LoRA); 2.LLM数据增强的有效性。
该研究旨在弥合 LLM 令人印象深刻的功能与 SLM 的计算效率之间的差距,从而为特定领域的应用程序开发更有效和高效的模型。
方法介绍
有效的fine-tuning
在特定任务fine-tuning大语言模型会有计算量和时间成本,为了解决这样的问题,前人提出了2种方法:Prefix Tuning 和 Low-rank Adaptaion(LoRA)。
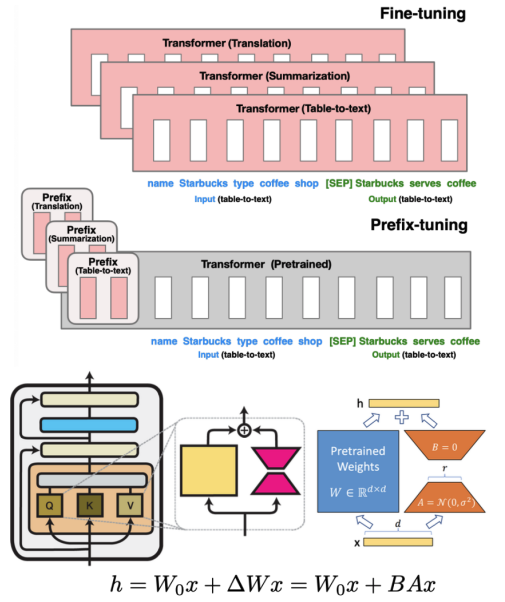
Prefix-tuning:prefix tuning就是训练一个小的、任务特定的网络,可称之为前置网络(prefix network),来生成特定任务的输入前置信息。这些信息和原始的输入信息concat起来,一起送入LLM中,只需要训练前者即可,不用动LLM的权重。该方法可大幅度减少可训练的参数和计算资源,具有高效多任务学习能力。
Low-rank adaptation(LoRA):低秩自适应使用低秩分解将模型的权重矩阵分解为两个较小的矩阵,然后对其进行微调。这种方法捕获基本信息,同时减少计算负担,保持模型适应具有较低计算要求的特定领域任务的能力。
这里使用的对比模型为:
BioGPTLarge
LLaMA-7b
Alpaca-7b
其中,prefix tuning这里使用32-256的token范围, Low-rank adaptation使用32-256的alpha范围和一个固定的rank为4的值。
生成式数据增强
生成式数据增强在扩充和使得数据多样性方面一直有着很重要的作用。大语言模型是个很厉害的工具,比如GPT3和4作为强有力的可根据已有数据生成具有真实性、可信赖的新数据,可扩充训练数据。

具体来说,在本实验中,通过扩充医学问答对,生成新的具有相同意义但不同文本的新的问答对。
但是,确保生成样本的质量和相关性是一个严肃的问题,如低质量或者不相关的生成样本对最终的性能会带来负面的影响。控制生成样本的多样性对于防止冗余或过于相似的数据点至关重要。
其中,为了保证质量和多样性,使用了两项技术:
Repetition Penalty Logits Processor,惩罚值为2。这种技术不鼓励生成文本中的重复词,促进更多的多样性并避免单调。
Temperature Logits Warper,温度为0.8。这种技术能够控制生成输出的随机性。使用较低的温度值,模型会产生更集中和确定性的结果,从而降低产生意外或不相关文本的可能性。
实验结果
Prefix Tuning和Low-rank Adaptation
在这个分析中,针对 BioGPT-Large 比较了两种技术的性能,Prefix Tuning和 Low-rank adaptation。结果如图所示,发现了一个有趣的现象,即这些技术对超参数选择的敏感性。
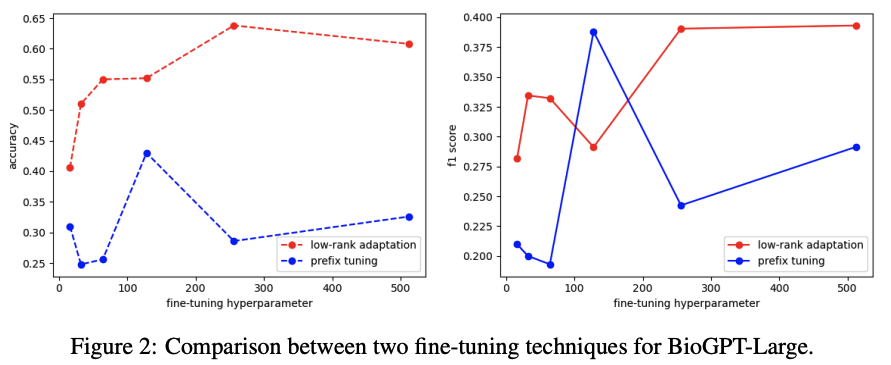
这一观察结果表明,与Prefix Tuning相比, Low-rank adaptation对超参数选择更稳健且更不敏感。这表明 Low-rank adaptation在不同的超参数值之间提供更一致和可靠的性能,以实现有效的微调。
指令微调限制语言模型的领域适应性
Alpaca-7b 源自 LLaMA-7b,是一种指令微调的大型语言模型 (LLM),可增强其遵循指令和有效响应特定任务的能力。然而,与普通的预训练模型相比,这种方法限制了它对特定领域任务的适应性。

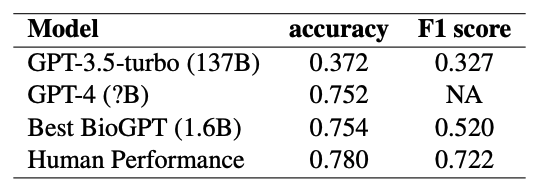
实验表明,与 BioGPT-Large 相比,LLaMA-7b 表现出更好的泛化能力,准确率和 F1 分数之间的差异更小。这一观察表明,对特定领域的数据集进行预训练可能不是必需的,因为经过微调的模型可以获得令人满意的性能。此外,尽管 LLaMA-7b 比 BioGPT-Large 大大约 4.3 倍,但它仍然与单个 V100 GPU 兼容,这也是其具有优异的性能的原因。
最佳生成数据增强方法
实验使用大语言模型进行数据扩充,比如ChatGPT。然而,发现指示缺乏领域知识的 LLM 生成全新的问答对并没有带来改进,反而导致微调 SLM 的下游任务性能下降。这一观察结果表明,虽然 LLM 可以有效地改进和多样化现有的问答对,但它们为特定领域的任务创建新颖、高质量的对的能力仍然有限。
另一方面,LLM 的最新进展(例如 GPT-4)具有针对 PubMedQA 的特定领域知识和问答能力,可以生成有用的新训练数据。通过将这些数据纳入训练过程,可以显着提高微调模型的性能。这些发现强调了具有特定领域知识的 LLM 在增强特定领域 QA 数据集和提高下游任务性能方面的重要性。
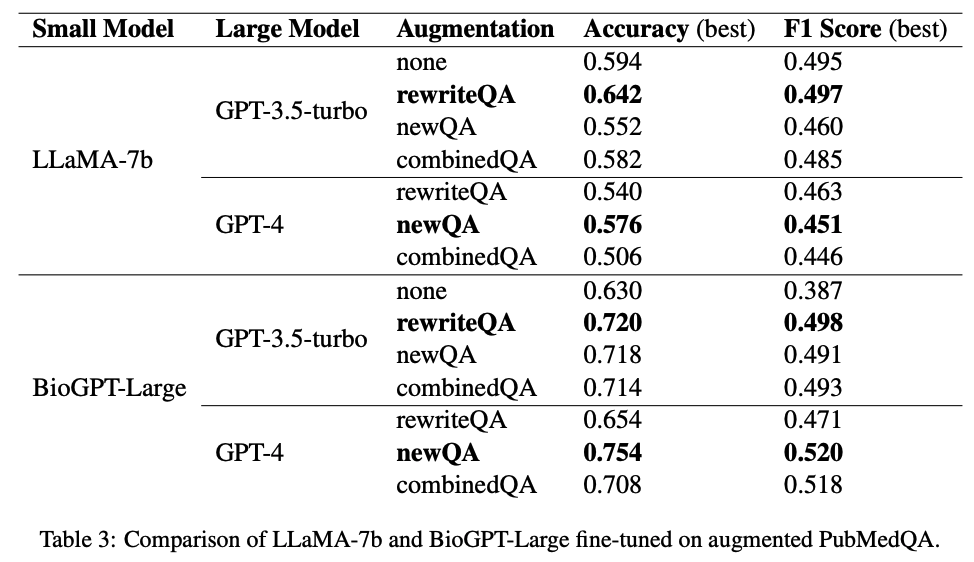
最后,毫不奇怪,当 BioGPT 在增强数据集上进行微调时,它的性能优于 LLaMA-7B。这与之前的发现一致,并强调了使用领域特定数据进行预训练的有效性,使 BioGPT 能够更好地理解领域特定任务并在其中表现出色。在微调期间利用特定领域的知识可以提高模型的准确性和上下文相关性,从而在特定领域的问题或任务中表现出色。
结论
根据实验结果得出结论,生成式数据增强是提高小型语言模型 (SLM) 在医学问答 (QA) 任务中性能的有效技术。Prefix Tuning 和 Low-rank Adaptation 被证明是有前途的 SLM 微调方法,Low-rank Adaptation 展示了对超参数选择的更大鲁棒性。此外,实验表明,对具有领域知识的 LLM 进行微调可以显着提高领域特定任务的性能。
更多细节,请阅读原文获取哈~
进NLP群—>加入NLP交流群