目录
- 简介
- 1、字节缓冲流
- 1.1构造方法
- 1.2缓冲流的高效
- 1.3为什么字节缓冲流会这么快?
- 1.4byte & 0xFF
- 2、字符缓冲流
- 2.1构造方法
- 2.2字符缓冲流特有方法
- 3、练习
简介
Java 的缓冲流是对字节流和字符流的一种封装,通过在内存中开辟缓冲区来提高 I/O 操作的效率。Java 通过 BufferedInputStream 和 BufferedOutputStream 来实现字节流的缓冲,通过 BufferedReader 和 BufferedWriter 来实现字符流的缓冲。
缓冲流的工作原理是将数据先写入缓冲区中,当缓冲区满时再一次性写入文件或输出流,或者当缓冲区为空时一次性从文件或输入流中读取一定量的数据。这样可以减少系统的 I/O 操作次数,提高系统的 I/O 效率,从而提高程序的运行效率。
1、字节缓冲流
BufferedInputStream 和 BufferedOutputStream 属于字节缓冲流,强化了字节流 InputStream 和 OutputStream,关于字节流。
1.1构造方法
- BufferedInputStream(InputStream in) :创建一个新的缓冲输入流,注意参数类型为InputStream。
- BufferedOutputStream(OutputStream out): 创建一个新的缓冲输出流,注意参数类型为OutputStream。
代码示例如下:
// 创建字节缓冲输入流,先声明字节流
FileInputStream fps = new FileInputStream(b.txt);
BufferedInputStream bis = new BufferedInputStream(fps)
// 创建字节缓冲输入流(一步到位)
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("b.txt"));
// 创建字节缓冲输出流(一步到位)
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("b.txt"));
1.2缓冲流的高效
我们通过复制一个 370M+ 的大文件,来测试缓冲流的效率。为了做对比,我们先用基本流来实现一下,代码如下:
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (FileInputStream fis = new FileInputStream("py.mp4");//exe文件够大
FileOutputStream fos = new FileOutputStream("copyPy.mp4")){
// 读写数据
int b;
while ((b = fis.read()) != -1) {
fos.write(b);
}
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("普通流复制时间:"+(end - start)+" 毫秒");
不好意思,我本机比较菜,10 分钟还在复制中。切换到缓冲流试一下,代码如下:
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("py.mp4"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copyPy.mp4"));){
// 读写数据
int b;
while ((b = bis.read()) != -1) {
bos.write(b);
}
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流复制时间:"+(end - start)+" 毫秒");
只需要 8016 毫秒,如何更快呢?
可以换数组的方式来读写,这个我们前面也有讲到,代码如下:
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("py.mp4"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copyPy.mp4"));){
// 读写数据
int len;
byte[] bytes = new byte[8*1024];
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0 , len);
}
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流使用数组复制时间:"+(end - start)+" 毫秒");
这下就更快了,只需要 521 毫秒。
1.3为什么字节缓冲流会这么快?
传统的 Java IO 是阻塞模式的,它的工作状态就是“读/写,等待,读/写,等待。。。。。。”
字节缓冲流解决的就是这个问题:一次多读点多写点,减少读写的频率,用空间换时间。
- 减少系统调用次数:在使用字节缓冲流时,数据不是立即写入磁盘或输出流,而是先写入缓冲区,当缓冲区满时再一次性写入磁盘或输出流。这样可以减少系统调用的次数,从而提高 I/O 操作的效率。
- 减少磁盘读写次数:在使用字节缓冲流时,当需要读取数据时,缓冲流会先从缓冲区中读取数据,如果缓冲区中没有足够的数据,则会一次性从磁盘或输入流中读取一定量的数据。同样地,当需要写入数据时,缓冲流会先将数据写入缓冲区,如果缓冲区满了,则会一次性将缓冲区中的数据写入磁盘或输出流。这样可以减少磁盘读写的次数,从而提高 I/O 操作的效率。
- 提高数据传输效率:在使用字节缓冲流时,由于数据是以块的形式进行传输,因此可以减少数据传输的次数,从而提高数据传输的效率。
我们来看 BufferedInputStream 的 read 方法:
public synchronized int read() throws IOException {
if (pos >= count) { // 如果当前位置已经到达缓冲区末尾
fill(); // 填充缓冲区
if (pos >= count) // 如果填充后仍然到达缓冲区末尾,说明已经读取完毕
return -1; // 返回 -1 表示已经读取完毕
}
return getBufIfOpen()[pos++] & 0xff; // 返回当前位置的字节,并将位置加 1
}
我们来看 BufferedInputStream 的 read 方法:
public synchronized int read() throws IOException {
if (pos >= count) { // 如果当前位置已经到达缓冲区末尾
fill(); // 填充缓冲区
if (pos >= count) // 如果填充后仍然到达缓冲区末尾,说明已经读取完毕
return -1; // 返回 -1 表示已经读取完毕
}
return getBufIfOpen()[pos++] & 0xff; // 返回当前位置的字节,并将位置加 1
}
这段代码主要有两部分:
- fill():该方法会将缓冲 buf 填满。
- getBufIfOpen()[pos++] & 0xff:返回当前读取位置 pos 处的字节(getBufIfOpen()返回的是 buffer 数组,是 byte 类型),并将其与 0xff 进行位与运算。这里的目的是将读取到的字节 b 当做无符号的字节处理,因为 Java 的 byte 类型是有符号的,而将 b 与 0xff 进行位与运算,就可以将其转换为无符号的字节,其范围为 0 到 255。
byte & 0xFF 我们一会再细讲。
再来看 FileInputStream 的 read 方法:
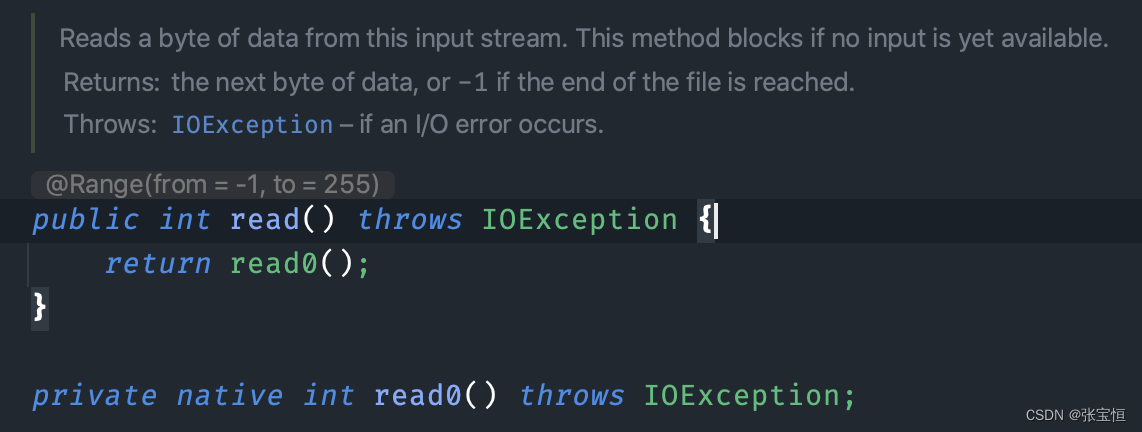
在这段代码中,read0() 方法是一个本地方法,它的实现是由底层操作系统提供的,并不是 Java 语言实现的。在不同的操作系统上,read0() 方法的实现可能会有所不同,但是它们的功能都是相同的,都是用于读取一个字节。
再来看一下 BufferedOutputStream 的 write(byte b[], int off, int len) 方法:
public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) { // 如果写入的字节数大于等于缓冲区长度
/* 如果请求的长度超过了输出缓冲区的大小,
先刷新缓冲区,然后直接将数据写入。
这样可以避免缓冲流级联时的问题。*/
flushBuffer(); // 先刷新缓冲区
out.write(b, off, len); // 直接将数据写入输出流
return;
}
if (len > buf.length - count) { // 如果写入的字节数大于空余空间
flushBuffer(); // 先刷新缓冲区
}
System.arraycopy(b, off, buf, count, len); // 将数据拷贝到缓冲区中
count += len; // 更新计数器
}
-
首先,该方法会检查写入的字节数是否大于等于缓冲区长度,如果是,则先将缓冲区中的数据刷新到磁盘中,然后直接将数据写入输出流。这样做是为了避免缓冲流级联时的问题,即缓冲区的大小不足以容纳写入的数据时,可能会引发级联刷新,导致效率降低。
-
级联问题(Cascade Problem)是指在一组缓冲流(Buffered Stream)中,由于缓冲区的大小不足以容纳要写入的数据,导致数据被分割成多个部分,并分别写入到不同的缓冲区中,最终需要逐个刷新缓冲区,从而导致性能下降的问题。
-
其次,如果写入的字节数小于缓冲区长度,则检查缓冲区中剩余的空间是否足够容纳要写入的字节数,如果不够,则先将缓冲区中的数据刷新到磁盘中。然后,使用 System.arraycopy() 方法将要写入的数据拷贝到缓冲区中,并更新计数器 count。
-
最后,如果写入的字节数小于缓冲区长度且缓冲区中还有剩余空间,则直接将要写入的数据拷贝到缓冲区中,并更新计数器 count。
也就是说,只有当 buf 写满了,才会 flush,将数据刷到磁盘,默认一次刷 8192 个字节。
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
如果 buf 没有写满,会继续写 buf。
对比一下 FileOutputStream 的 write 方法,同样是本地方法,一次只能写入一个字节。
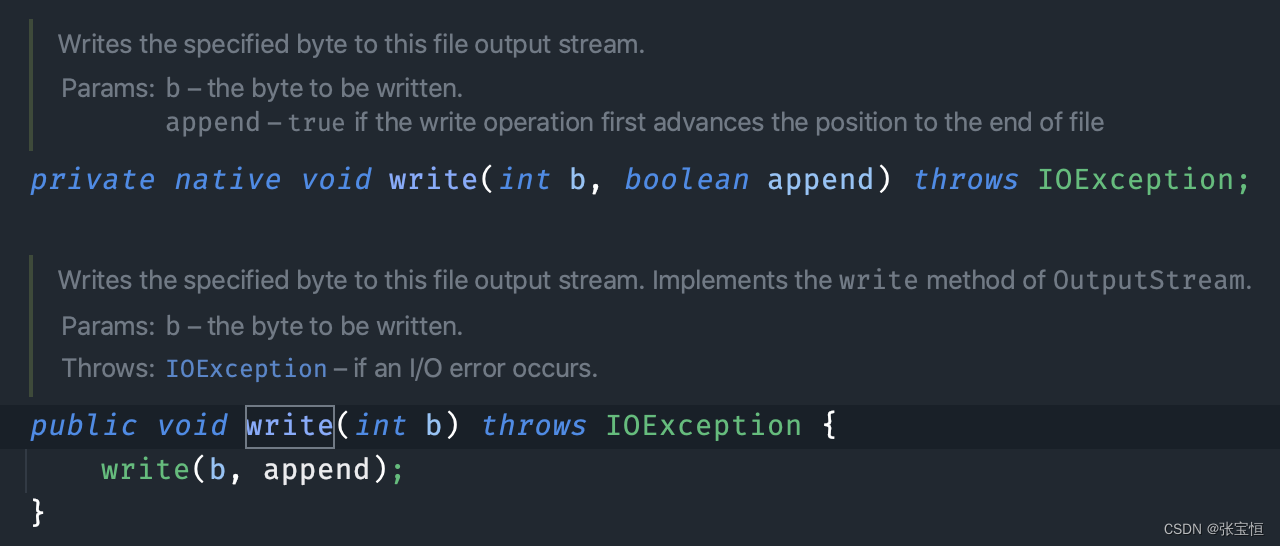 当把 BufferedOutputStream 和 BufferedInputStream 配合起来使用后,就减少了大量的读写次数,尤其是 byte[] bytes = new byte[8*1024],就相当于缓冲区的空间有 8 个 1024 字节,那读写效率就会大大提高。
当把 BufferedOutputStream 和 BufferedInputStream 配合起来使用后,就减少了大量的读写次数,尤其是 byte[] bytes = new byte[8*1024],就相当于缓冲区的空间有 8 个 1024 字节,那读写效率就会大大提高。
1.4byte & 0xFF
byte 类型通常被用于存储二进制数据,例如读取和写入文件、网络传输等场景。在这些场景下,byte 类型的变量可以用来存储数据流中的每个字节,从而进行读取和写入操作。
byte 类型是有符号的,即其取值范围为 -128 到 127。如果我们希望得到的是一个无符号的 byte 值,就需要使用 byte & 0xFF 来进行转换。
这是因为 0xFF 是一个无符号的整数,它的二进制表示为 11111111。当一个 byte 类型的值与 0xFF 进行位与运算时,会将 byte 类型的值转换为一个无符号的整数,其范围为 0 到 255。
0xff 是一个十六进制的数,相当于二进制的 11111111,& 运算符的意思是:如果两个操作数的对应位为 1,则输出 1,否则为 0;由于 0xff 有 8 个 1,单个 byte 转成 int 其实就是将 byte 和 int 类型的 255 进行(&)与运算。
例如,如果我们有一个 byte 类型的变量 b,其值为 -1,那么 b & 0xFF 的结果就是 255。这样就可以将一个有符号的 byte 类型的值转换为一个无符号的整数。
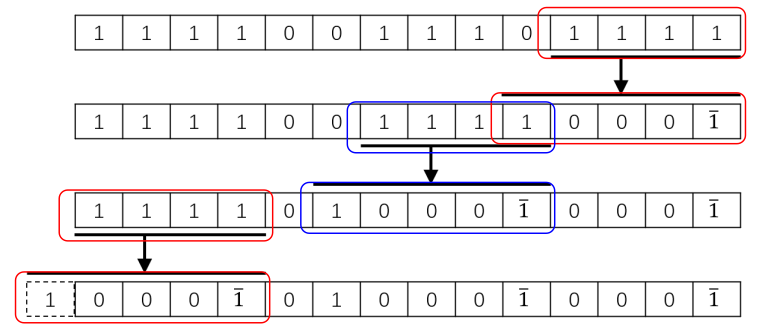
& 运算是一种二进制数据的计算方式, 两个操作位都为1,结果才为1,否则结果为0. 在上面的 getBufIfOpen()[pos++] & 0xff 计算过程中, byte 有 8bit, OXFF 是16进制的255, 表示的是 int 类型, int 有 32bit.
如果 getBufIfOpen()[pos++] 为 -118, 那么其原码表示为
00000000 00000000 00000000 10001010
反码为
11111111 11111111 11111111 11110101
补码为
11111111 11111111 11111111 11110110
0XFF 表示16进制的数据255, 原码, 反码, 补码都是一样的, 其二进制数据为
00000000 00000000 00000000 11111111
0XFF 和 -118 进行&运算后结果为
00000000 00000000 00000000 11110110
还原为原码后为
00000000 00000000 00000000 10001010
其表示的 int 值为 138,可见将 byte 类型的 -118 与 0XFF 进行与运算后值由 -118 变成了 int 类型的 138,其中低8位和byte的-118完全一致。
顺带聊一下 原码、反码和补码。
①、原码
原码就是符号位加上真值的绝对值,即用第一位表示符号,其余位表示值。比如如果是8位二进制:
[+1]原 = 0000 0001
[-1]原 = 1000 0001
第一位是符号位。因为第一位是符号位,所以8位二进制数的取值范围就是:
[1111 1111 , 0111 1111]
即
[-127 , 127]
②、反码
反码的表示方法是:
正数的反码是其本身
负数的反码是在其原码的基础上,符号位不变,其余各个位取反。
例如:
[+1] = [00000001]原 = [00000001]反
[-1] = [10000001]原 = [11111110]反
可见如果一个反码表示的是负数,人脑无法直观的看出来它的数值。通常要将其转换成原码再计算。
③、补码
补码的表示方法是:
正数的补码就是其本身
负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1。(即在反码的基础上+1)
[+1] = [00000001]原 = [00000001]反 = [00000001]补
[-1] = [10000001]原 = [11111110]反 = [11111111]补
对于负数,补码表示方式也是人脑无法直观看出其数值的。通常也需要转换成原码在计算其数值。
从上面可以看到:
对于正数:原码,反码,补码都是一样的
对于负数:原码,反码,补码都是不一样的
2、字符缓冲流
BufferedReader 类继承自 Reader 类,提供了一些便捷的方法,例如 readLine() 方法可以一次读取一行数据,而不是一个字符一个字符地读取。
BufferedWriter 类继承自 Writer 类,提供了一些便捷的方法,例如 newLine() 方法可以写入一个系统特定的行分隔符。
2.1构造方法
BufferedReader(Reader in) :创建一个新的缓冲输入流,注意参数类型为Reader。
BufferedWriter(Writer out): 创建一个新的缓冲输出流,注意参数类型为Writer。
代码示例如下:
// 创建字符缓冲输入流
BufferedReader br = new BufferedReader(new FileReader("b.txt"));
// 创建字符缓冲输出流
BufferedWriter bw = new BufferedWriter(new FileWriter("b.txt"));
2.2字符缓冲流特有方法
字符缓冲流的基本方法与普通字符流调用方式一致,这里不再赘述,我们来看字符缓冲流特有的方法。
BufferedReader:String readLine(): 读一行数据,读取到最后返回 null
BufferedWriter:newLine(): 换行,由系统定义换行符。
来看 readLine()方法的代码示例:
// 创建流对象
BufferedReader br = new BufferedReader(new FileReader("a.txt"));
// 定义字符串,保存读取的一行文字
String line = null;
// 循环读取,读取到最后返回null
while ((line = br.readLine())!=null) {
System.out.print(line);
System.out.println("------");
}
// 释放资源
br.close();
再来看 newLine() 方法的代码示例:
// 创建流对象
BfferedWriter bw = new BufferedWriter(new FileWriter("b.txt"));
// 写出数据
bw.write("追");
// 写出换行
bw.newLine();
bw.write("风");
bw.newLine();
bw.write("少");
bw.newLine();
bw.write("年");
bw.newLine();
// 释放资源
bw.close();
3、练习
来欣赏一下我写的这篇诗:
6.岑夫子,丹丘生,将进酒,杯莫停。
1.君不见黄河之水天上来,奔流到海不复回。
8.钟鼓馔玉不足贵,但愿长醉不愿醒。
3.人生得意须尽欢,莫使金樽空对月。
5.烹羊宰牛且为乐,会须一饮三百杯。
2.君不见高堂明镜悲白发,朝如青丝暮成雪。
7.与君歌一曲,请君为我倾耳听。
4.天生我材必有用,千金散尽还复来。
欣赏完了没?
估计你也看出来了,这是李白写的《将进酒》,不是我写的。😝
不过,顺序是乱的,还好,我都编了号。那如何才能按照正确的顺序来呢?
来看代码实现:
// 创建map集合,保存文本数据,键为序号,值为文字
HashMap<String, String> lineMap = new HashMap<>();
// 创建流对象 源
BufferedReader br = new BufferedReader(new FileReader("logs/test.log"));
//目标
BufferedWriter bw = new BufferedWriter(new FileWriter("logs/test1.txt"));
// 读取数据
String line;
while ((line = br.readLine())!=null) {
// 解析文本
if (line.isEmpty()) {
continue;
}
String[] split = line.split(Pattern.quote("."));
// 保存到集合
lineMap.put(split[0], split[1]);
}
// 释放资源
br.close();
// 遍历map集合
for (int i = 1; i <= lineMap.size(); i++) {
String key = String.valueOf(i);
// 获取map中文本
String value = lineMap.get(key);
// 写出拼接文本
bw.write(key+"."+value);
// 写出换行
bw.newLine();
}
// 释放资源
bw.close();
来看输出结果:
1.君不见黄河之水天上来,奔流到海不复回。
2.君不见高堂明镜悲白发,朝如青丝暮成雪。
3.人生得意须尽欢,莫使金樽空对月。
4.天生我材必有用,千金散尽还复来。
5.烹羊宰牛且为乐,会须一饮三百杯。
6.岑夫子,丹丘生,将进酒,杯莫停。
7.与君歌一曲,请君为我倾耳听。
8.钟鼓馔玉不足贵,但愿长醉不愿醒。
吾之荣耀,离别已久。如果觉得有用,点个赞吧~~~~