Chinese-LangChain 是 yanqiangmiffy 同学的开源项目https://hf.co/spaces/ChallengeHub/Chinese-LangChainhttps://github.com/yanqiangmiffy/Chinese-LangChain
中文 langchain 项目,基于 ChatGLM-6b + langchain 实现本地化知识库检索与智能答案生成。
LangChain 的资料准备
海量的知识库,知识库是由一段一段的文本构成的。
LangChain 中用到的功能性语言模型
基于问题搜索知识库中的文本的问题搜索知识文本功能性语言模型
基于问题与问题相关的知识库文本进行问答的对话式语言模型
对话式大参数量语言模型有:
chatglm
LLama
Bloom
基于中文预训练、问答训练、文档问答训练、多轮问答训练、人工强化反馈学习的对话式大参数语言模型有:
chatglm
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考 ChatGLM-6B 的 博客。
ChatGLM-6B:https://github.com/THUDM/ChatGLM-6BChatGLM 博客:https://chatglm.cn/blog
为了方便下游开发者针对自己的应用场景定制模型,THUDM 同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南),INT4 量化级别下最低只需 7GB 显存即可启动微调。
THUDM:https://github.com/THUDMP-Tuning v2:https://github.com/THUDM/P-tuning-v2使用指南:https://github.com/THUDM/ChatGLM-6B/blob/main/ptuning/README.md
LLama
Huatuo-Llama-Med-Chinese:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
SCIR-HI 训练的医疗领域 Llama 对话式大参数语言模型
开源了经过中文医学指令精调/指令微调 (Instruct-tuning) 的 LLaMA-7B 模型。SCIR-HI 通过医学知识图谱和 GPT3.5 API 构建了中文医学指令数据集,并在此基础上对 LLaMA 进行了指令微调,提高了 LLaMA 在医疗领域的问答效果。
SCIR-HI:https://github.com/SCIR-HIChinese-LLaMA-Alpaca 开源仓库:https://github.com/ymcui/Chinese-LLaMA-Alpaca
为了促进大模型在中文 NLP 社区的开放研究,Chinese-LLaMA-Alpaca 开源了中文 LLaMA 模型和指令精调的 Alpaca 大模型。这些模型在原版 LLaMA 的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文 Alpaca 模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。详细内容请参考技术报告 (Cui, Yang, and Yao, 2023)。
报告地址:https://arxiv.org/abs/2304.08177
Chinese-LLaMA-Alpaca 主要内容:
🚀 针对原版 LLaMA 模型扩充了中文词表,提升了中文编解码效率
🚀 Chinese-LLaMA-Alpaca 开源了使用中文文本数据预训练的中文 LLaMA 以及经过指令精调的中文 Alpaca(7B、13B)
🚀 快速使用笔记本电脑(个人 PC)的 CPU/GPU 本地量化和部署体验大模型
| 对比项 | 中文 LLaMA | 中文 Alpaca |
|---|---|---|
| 训练方式 | 传统 CLM (在通用语料上训练) | 指令精调 (在指令数据上训练) |
| 输入模板 | 不需要 | 需要符合模板要求(llama.cpp/LlamaChat/HF 推理代码等已内嵌) |
| 适用场景 ✔️ | 文本续写:给定上文内容,让模型继续写下去,生成下文 | 1、指令理解(问答、写作、建议等)2、多轮上下文理解(聊天等) |
| 不适用场景 ❌ | 指令理解 、多轮聊天等 | 文本无限制自由生成 |
| llama.cpp | 使用 -p 参数指定上文 | 使用 -ins 参数启动指令理解+聊天模式 |
| text-generation-webui | 不适合 chat 模式 | 使用 --cpu 可在无显卡形式下运行,若生成内容不满意,建议修改 prompt |
| LlamaChat | 加载模型时选择"LLaMA" | 加载模型时选择"Alpaca" |
| HF推理代码 | 无需添加额外启动参数 | 启动时添加参数 --with_prompt |
| 已知问题 | 如果不控制终止,则会一直写下去,直到达到输出长度上限。 | 目前版本模型生成的文本长度相对短一些,比较惜字如金。 |
HF 推理代码https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/scripts/inference_hf.py
| 对比项 | 中文 LLaMA | 中文 Alpaca |
|---|---|---|
| 训练方式 | 传统 CLM (在通用语料上训练) | 指令精调 (在指令数据上训练) |
| 输入模板 | 不需要 | 需要符合模板要求(llama.cpp/LlamaChat/HF 推理代码等已内嵌) |
| 适用场景 ✔️ | 文本续写:给定上文内容,让模型继续写下去,生成下文 | 1、指令理解(问答、写作、建议等)2、多轮上下文理解(聊天等) |
| 不适用场景 ❌ | 指令理解 、多轮聊天等 | 文本无限制自由生成 |
| llama.cpp | 使用 -p 参数指定上文 | 使用 -ins 参数启动指令理解+聊天模式 |
| text-generation-webui | 不适合 chat 模式 | 使用 --cpu 可在无显卡形式下运行,若生成内容不满意,建议修改 prompt |
| LlamaChat | 加载模型时选择"LLaMA" | 加载模型时选择"Alpaca" |
| HF推理代码 | 无需添加额外启动参数 | 启动时添加参数 --with_prompt |
| 已知问题 | 如果不控制终止,则会一直写下去,直到达到输出长度上限。 | 目前版本模型生成的文本长度相对短一些,比较惜字如金。 |
HF 推理代码https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/scripts/inference_hf.py
| 对比项 | 中文 LLaMA | 中文 Alpaca |
|---|---|---|
| 训练方式 | 传统 CLM (在通用语料上训练) | 指令精调 (在指令数据上训练) |
| 输入模板 | 不需要 | 需要符合模板要求(llama.cpp/LlamaChat/HF 推理代码等已内嵌) |
| 适用场景 ✔️ | 文本续写:给定上文内容,让模型继续写下去,生成下文 | 1、指令理解(问答、写作、建议等)2、多轮上下文理解(聊天等) |
| 不适用场景 ❌ | 指令理解 、多轮聊天等 | 文本无限制自由生成 |
| llama.cpp | 使用 -p 参数指定上文 | 使用 -ins 参数启动指令理解+聊天模式 |
| text-generation-webui | 不适合 chat 模式 | 使用 --cpu 可在无显卡形式下运行,若生成内容不满意,建议修改prompt |
| LlamaChat | 加载模型时选择"LLaMA" | 加载模型时选择"Alpaca" |
| HF推理代码 | 无需添加额外启动参数 | 启动时添加参数 --with_prompt |
| 已知问题 | 如果不控制终止,则会一直写下去,直到达到输出长度上限。 | 目前版本模型生成的文本长度相对短一些,比较惜字如金。 |
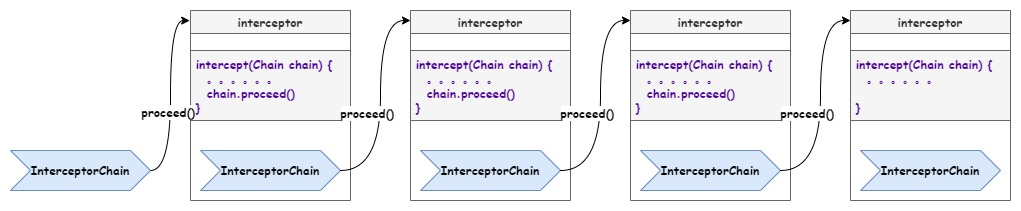
LangChain 的工作流程
在没有知识库的情况下:直接将问题输入对话式大语言模型作为当前问题的答案。
在有知识库的情况下:首先用输入的问题,基于文本相似度表征模型获取到输入的表征。依靠表征寻找到相似的知识段落文本。第二将相似知识段落文本拼接上问题输入对话式语言模型获取当前问题的文档问答结果。
LangChain 的问答实现路径
基于纯粹的大语言模型的对话能力
基于相似度检索相关文档以及基于对话大参数预训练语言模型的阅读理解能力
LangChain 的资料库向量化
如何提升 LangChain 的性能:
训练垂直领域问题与文档相似度模型,提升问题寻找知识文档的精度。
训练垂直领域问题+知识文档的对话式大语言模型,优化返回结果。
在不同的环境中安装 LangChain 环境
安装 pytorch 1.13.1
# ROCM 5.2 (Linux only)
pip3 install torch torchvision torchaudio --extra-index-url
pip install torch==1.13.1+rocm5.2 torchvision==0.14.1+rocm5.2 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/rocm5.2
# CUDA 11.6
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
# CUDA 11.7
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
# CPU only
pip install torch==1.13.1+cpu torchvision==0.14.1+cpu torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cpu安装 pytorch 2.0.0、cuda 11.7
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117安装 pytorch 2.0.0、cuda 11.8
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118LangChain 项目地址:https://github.com/hwchase17/langchain
很多中文的 LangChain 都是基于这个项目进行二次开发的。
安装 LangChain 的两次尝试
LangChain 可在 PyPi 上使用,因此可以轻松安装:
pip install langchain这将安装 LangChain 的最低要求。当 LangChain 与各种模型提供程序、数据存储等集成时,它的很多价值就来了。默认情况下,不安装执行此操作所需的依赖项。然而,还有另外两种安装 LangChain 的方法确实引入了这些依赖关系。
要安装通用 LLM 提供程序所需的模块,请运行:
pip install langchain[llms]要安装所有集成所需的所有模块,请运行:
pip install langchain[all]请注意,如果您使用的是 zsh,则在将方括号作为参数传递给命令时需要引用方括号,例如:
pip install 'langchain[all]'基于源码安装 LangChain
git clone https://github.com/hwchase17/langchain.git
cd langchain
pip install -e .Chinese-LangChain 安装部署过程
24 pip install -r requirements.txt
26 pip install 'httpx[socks]'
27 python main.py
44 发现导入pdf失败,提示缺失一下的包 以下异常并没有引起程序中断。
45* pip install 'unstructured[local-inference]'Chinese-LangChain 构建自己知识库的文档与问题相似度表征,这一步一定要准备好足够的内存。
import os
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.schema import Document
from langchain.vectorstores import FAISS
from tqdm import tqdm
# 中文 Wikipedia 数据导入示例:
embedding_model_name = 'GanymedeNil/text2vec-large-chinese'
docs_path = '/root/work/Chinese-LangChain/docs'
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name)
docs = []
d = []
doc_files = os.listdir("./docs")
for doc_one in doc_files:
if not "txt" in doc_one:
continue
with open(os.path.join("./docs",doc_one), 'r', encoding='utf-8') as f:
for idx, line in tqdm(enumerate(f.read().split("。"))):
d.append(line)
d = list(set(d))
for idx, d_one in tqdm(enumerate(d)):
metadata = {"source": f'doc_id_{idx}'}
docs.append(Document(page_content=line.strip()+"。", metadata=metadata))
vector_store = FAISS.from_documents(docs, embeddings)
vector_store.save_local('cache/annoy/')相对有限的内存资源来说,可以尝试把知识库文本段向量化做成一个批式处理流程:
import os
import pandas as pd
from langchain.schema import Document
from langchain.document_loaders import UnstructuredFileLoader
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from tqdm import tqdm
# 中文 Wikipedia 数据导入示例:
embedding_model_name = 'GanymedeNil/text2vec-large-chinese'
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name)
d = []
doc_files = os.listdir("./2012")
for doc_one in doc_files:
if not "txt" in doc_one:
continue
with open(os.path.join("./2012",doc_one), 'r', encoding='utf-8') as f:
for idx, line in tqdm(enumerate(f.read().split("。"))):
d.append(line)
d = list(set(d))
for i in range(len(d)//100000):
docs = []
for idx, d_one in tqdm(enumerate(d[100000*i:100000*(i+1)])):
metadata = {"source": f'doc_id_{idx}'}
docs.append(Document(page_content=line.strip()+"。", metadata=metadata))
vector_store = FAISS.from_documents(docs, embeddings)
vector_store.save_local('cache/annoy'+str(i)+'/')100 万句子分成了 10 批次 10 万次句子生成了 10 个 faiss 向量数据文件。获取向量的过程也是需要显卡参与计算的。
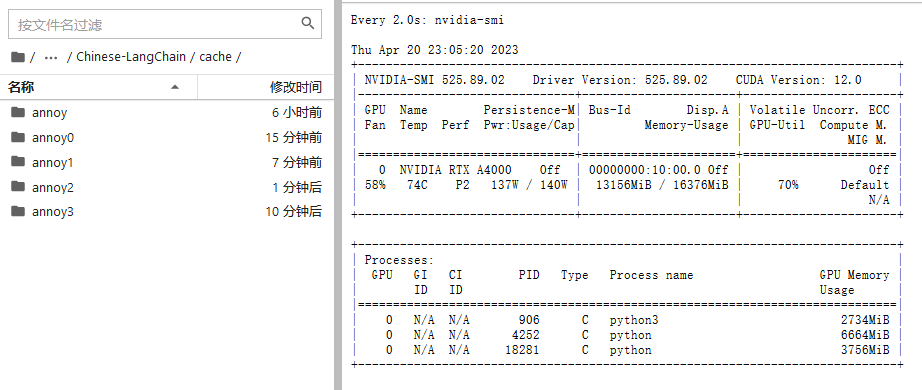
从 0 到 3 是我生成的 faiss 向量数据文件。据说还可以合并成一个大的向量文件。
在 Chinese-LangChain 中加入自己的知识库的文档与问题相似度表征
class LangChainCFG:
llm_model_name = 'THUDM/chatglm-6b-int4-qe' # 本地模型文件 or huggingface远程仓库
embedding_model_name = 'GanymedeNil/text2vec-large-chinese' # 检索模型文件 or huggingface远程仓库
vector_store_path = './cache'
docs_path = './docs'
kg_vector_stores = {
'2010年企业年报': './cache/annoy/',
} # 可以替换成自己的知识库,如果没有需要设置为None
# kg_vector_stores=None
patterns = ['模型问答', '知识库问答'] #训练垂直领域问题 + 知识文档的对话式大语言模型的几种方式,(按照资源由小到大的排序方式)
ptuning v2 & finetune chatglm 的官方支持了对下游文本生成任务进行 ptuning 和全参数量 finetune 的实现 chatglm ptuning & finetune:https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
lora 开源社区的志愿者小伙伴,为了提升多卡的并行训练方法,实现了一套基于 lora 训练策略的多卡并行训练实现。
pretrain 根据 ymcui 的实现的 Chinese-LLaMA-Alpaca 项目,可以知道通过 transformers 的原生代码进行 clm 的 pretrain 可以提升 LLaMA 语言模型的生成效果。在 LLaMA 的预训练过程中采用的是先扩充词表,再进行中文数据集预训练的过程。
相关工作
transformers language-modeling:https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling
全参数量 finetune 目前看起来效果是非常不错的。效果提升非常明显。
如果你有好的文章希望通过我们的平台分享给更多人,请通过这个链接与我们联系:
https://bit.ly/hf-tougao

![[网络安全]XSS之Cookie外带攻击姿势及例题详析](https://img-blog.csdnimg.cn/28d08355ff51401395c801da7b06fda3.png#pic_center)