你好,我是zhenguo(郭震)
很久没有更新文章,从现在开始我将逐步恢复更新。在接下来的日子,我将系统更新强化学习文章,在期间,也会插播一些读博做科研的一些日常总结。如果你感兴趣,欢迎关注学习。
写公众号文章,是沉淀技术非常好的一种方法,希望更多朋友参与进来。精进技术,脚踏实地,永远不过时。
下面是强化学习的初步更新大纲,我将大概按照此大纲,每几天总结发布一篇文章。感兴趣的朋友讨论学习起来。
文字版:
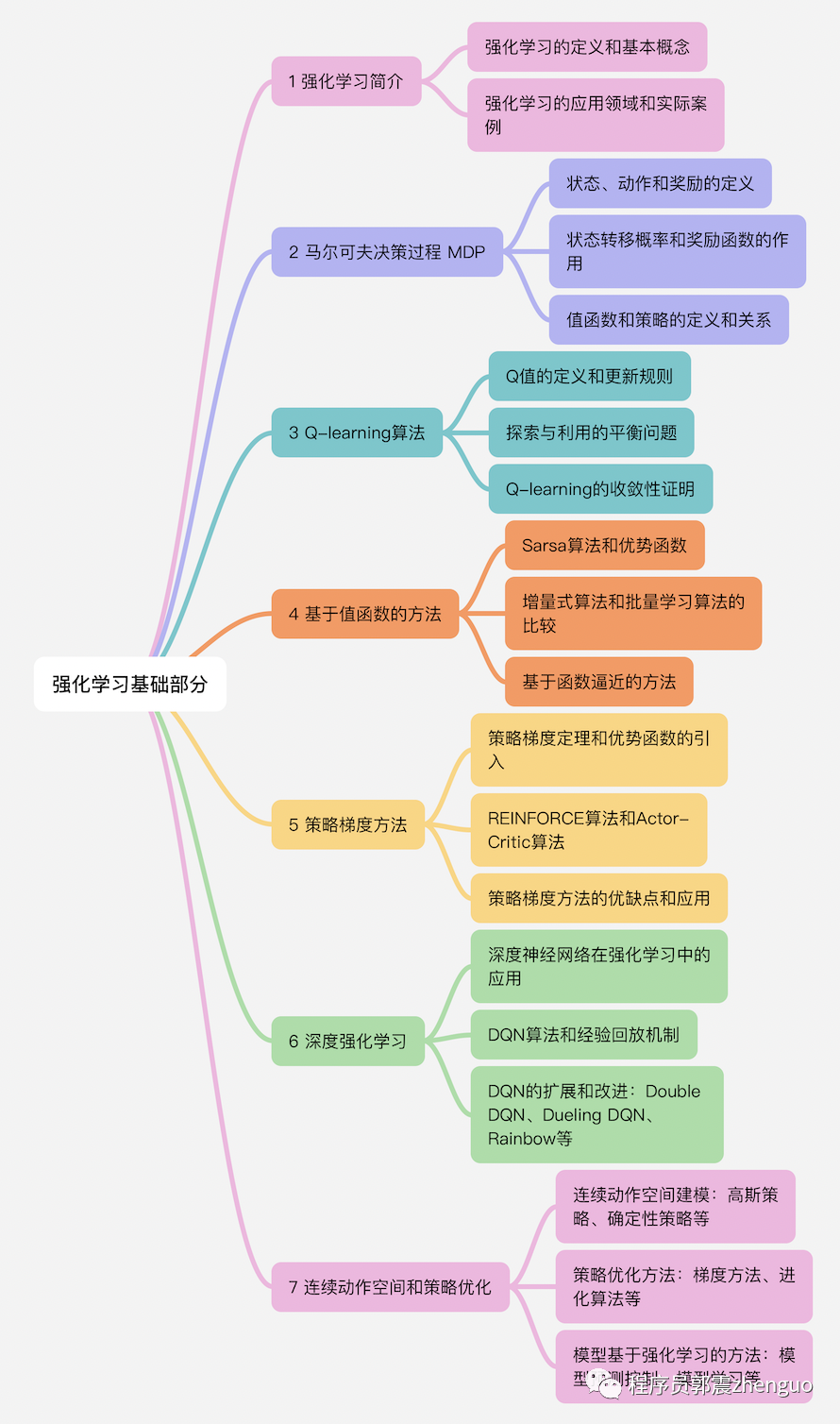
强化学习基础部分
1 强化学习简介
强化学习的定义和基本概念
强化学习的应用领域和实际案例
2 马尔可夫决策过程 MDP
状态、动作和奖励的定义
状态转移概率和奖励函数的作用
值函数和策略的定义和关系
3 Q-learning算法
Q值的定义和更新规则
探索与利用的平衡问题
Q-learning的收敛性证明
4 基于值函数的方法
Sarsa算法和优势函数
增量式算法和批量学习算法的比较
基于函数逼近的方法
5 策略梯度方法
策略梯度定理和优势函数的引入
REINFORCE算法和Actor-Critic算法
策略梯度方法的优缺点和应用
6 深度强化学习
深度神经网络在强化学习中的应用
DQN算法和经验回放机制
DQN的扩展和改进:Double DQN、Dueling DQN、Rainbow等
7 连续动作空间和策略优化
连续动作空间建模:高斯策略、确定性策略等
策略优化方法:梯度方法、进化算法等
模型基于强化学习的方法:模型预测控制、模型学习等
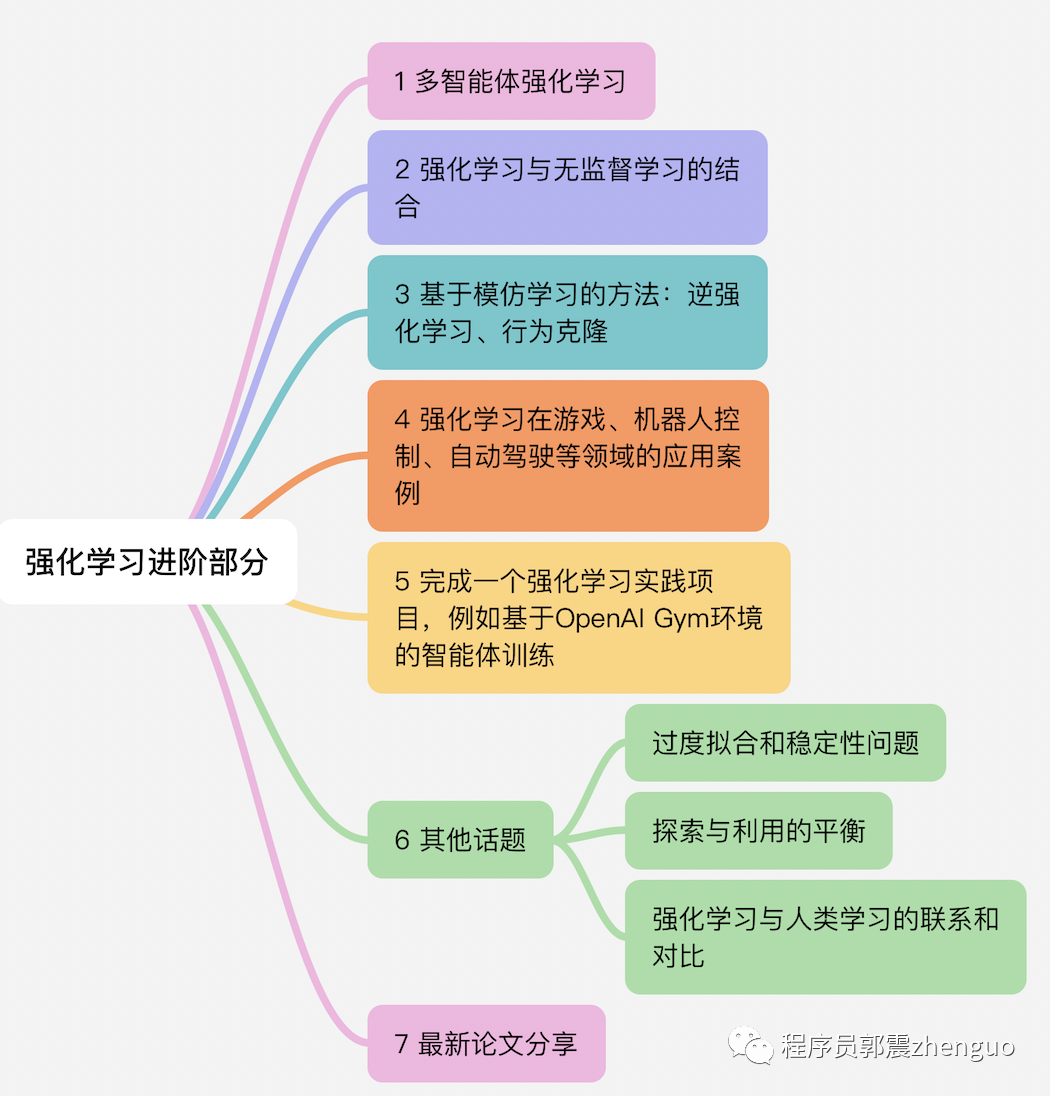
强化学习进阶部分
1 多智能体强化学习
2 强化学习与无监督学习的结合
3 基于模仿学习的方法:逆强化学习、行为克隆
4 强化学习在游戏、机器人控制、自动驾驶等领域的应用案例
5 完成一个强化学习实践项目,例如基于OpenAI Gym环境的智能体训练
6 其他话题
过度拟合和稳定性问题
探索与利用的平衡
强化学习与人类学习的联系和对比
7 最新论文分享
你的点赞和转发,给我更新增加更大动力,感谢你的支持。