“降本增效”是最近企业常被提及的关键字,作为新时代企业发展的数据大脑,企业大数据团队需要持续探索如何在有限资源下创造更多价值。本文将以场景为"引",技术为"核",介绍如何基于 StarRocks 全新的存算分离架构实现数据分析的“降本”和“增效”。
降本
在冷热数据混合分析场景下,采用存算分离架构能够显著降低存储成本。
以日志分析场景为例,用户的 APP 和业务系统都会生成大量的埋点日志或应用日志。网站的运营和优化不仅需要对实时流量和用户行为等数据进行实时日志分析,还需要分析离线日志,对网站历史数据进行深入分析,以挖掘潜在的业务价值。
因此,我们可以看出日志数据分析有以下两个特点:
-
日志数据需要实时接入并且需要长期保存。这会对存储产生较大压力。通常,一个互联网企业会有上百 TB 甚至是 PB 级别的日志数据存储需求。
-
日志数据分析主要关注近期的数据,尤其是当天的热数据需要实时分析,响应时间通常在分钟级或秒级。对于全量数据或已经归档的冷数据,分析频率较低,且时效性要求一般较低。
为了让大家更好地了解 StarRocks 存算分离架构所带来的成本节约,我们举一个具体的例子:
客户 A 的网站每天会产生 1TB 的增量日志数据,数据保存周期为 2 年。日常分析主要集中在近 7 天内的日志数据,但偶尔也需要查询超过 7 天的数据。 在传统的存算一体的架构下,如果每台服务器配置 20TB 的存储容量、16 vcore 和 64GB 内存,且数据副本为 3,压缩率为 50%。那么为了存储 700TB 的数据,总计需要 (700TB * 3 * 0.5)/20TB ≈ 52 台服务器。但是按照 28 定律, 实际上 80% 的场景下只分析近 7 天的数据,因此大约只需要(7TB * 3 * 0.5)/20TB ≈ 0.52 台服务器就可以满足大多数查询需求。这意味着超过 95% 的服务器成本都被浪费在了存储低频查询所需的冷数据上。 假设极端情况下,有 20% 的查询需要对全量的冷数据进行分析,而有 80% 的查询只需要分析近期的热数据。那么在采用弹性扩缩容的方案下,用户能节省多少成本? 答案:(0.2*52+0.8*1)/52 ≈ 0.22。 理想状态下,用户日常相同的查询性能只需要付出(52*0.22)≈ 11 台服务器的成本(对象存储的成本忽略不计)。硬件成本节约 78% 。
增效
针对流量存在明显波峰波谷的场景,存算分离架构的快速弹性能力可以带来显著的计算效率提升。
以电商 SaaS 服务场景为例,通过对订单数据进行时间序列分析,企业可以了解销售趋势和季节性变化,以优化产品库存和销售策略。通常,销售趋势分析的查询场景包括实时报表、天报表、月报表和年度报表,而每天的查询高峰和月末、季度末的数据汇总都有明显的规律。
在存算一体的架构下,为了确保用户在不同的查询场景下都能获得良好的用户体验,通常会以最大资源消耗场景来预估整个集群的规模。
因此,销售报表的查询存在以下特点:
-
整体数据量不大,但是计算复杂。由于数据需要经常更新,因此难以进行预计算以提升计算效率。
-
查询的规律明显,流量有明显的波峰和波谷,因此大部分时间集群的资源利用率不高。
为了让大家更好地了解 StarRocks 存算分离架构所带来的计算效率提升,我们举一个具体的例子:
某 SaaS 服务提供商为用户的商品销售情况提供了基于不同时间维度的销售统计报表。日常的报表访问 QPS 峰值在 100 左右,为每个用户单独部署一套 3 个节点(32 vcores,128 GB)的集群,日报表和周报表的查询 P99 稳定维持在 3s 以内,集群负载在 30%左右。然而,到了月末,由于要计算整个月度的销售情况,数据计算范围扩大了 4 倍以上,查询的 QPS 峰值也会有显著的上升。此时集群的负载会飙升到 100% ,且查询 P99 会超过 10s,甚至更久。为了在月底提供和日常一致的查询性能,服务商就需要把集群规模扩大到原先的 (30/7) * (10/3) *(1/3) ≈ 4.76 倍如果使用存算分离的架构,计算资源可以按需扩缩容,计算效率可以提升多少呢?基于 StarRocks 存算一体的架构下,如果要给用户在日常与月末为用户提供一致的查询体验,那就需要部署 3 * 4.76 ≈ 14 台服务器。 以每个月最后一周为月度报表的查询高峰为例,只需要在这一周部署 14 个节点。在其他时间,只需要部署 3 个节点即可。因此。总体成本 (3/4 * 3) + (1/4 * 14) = 5.75 节点,使用存算分离架构后,整体计算效率将提高 14/5.75 ≈ 2.43倍。
核心技术揭秘
作为 MPP 数据库的典型代表,StarRocks 3.0 之前一直使用存算一体架构。存算一体架构的优势在于性能,直接访问本地数据,速度非常快。但也存在一些局限性,主要表现为:
-
成本:随着用户存储数据量的增加,需要不断扩容存储和计算资源,导致计算资源浪费
-
架构复杂:存算一体架构维护数据副本一致性增加了系统的复杂度,系统越复杂,风险越大
-
弹性:在存算一体模式下,用户扩缩容会引发数据重平衡,弹性体验不佳
为了解决上述问题,最根本的途径是对架构进行升级,这也是 StarRocks 3.0 版本带来的最大变化。接下来,我们将从技术设计的角度揭秘 StarRocks 是如何在存算分离架构下实现与存算一体架构一致的性能,并探讨存算分离架构如实现成本的节约和效率的提升。
01 存算分离新范式
在深入思考存算分离的发展方向后,我们提出并构建了一个统一的存算分离平台——StarOS。区别于传统存算分离架构,StarRocks 只是构建在 StarOS 上的一个存算分离应用。基于 StarOS,未来我们可以轻松构建各种类型的存算分离应用。
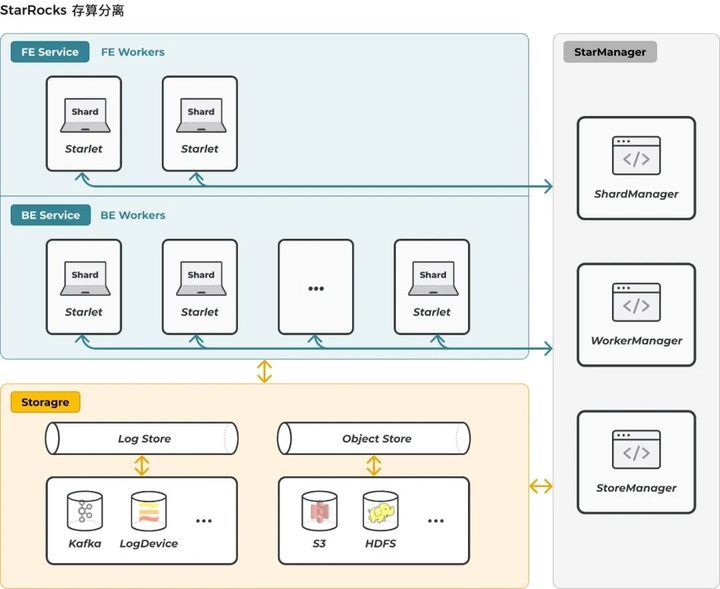
在新平台中,我们构建了一个统一的存储访问层,屏蔽了后端不同存储系统的差异。基于该统一存储访问层,StarRocks 可以在轻松地支持新的存储系统的同时保持对上层应用的透明。StarRocks 3.0 版本支持多种主流存储系统,包括 S3 兼容的对象存储系统(如 OSS、MinIO)以及 HDFS 等。
另外,StarOS 的调度中枢负责计算任务调度,并支持丰富的调度能力,如打散调度、亲和调度等,以支持复杂的业务需求。
为了真正实现存算分离架构,我们还对内核进行了诸多改进。
1.1 存储
StarRocks 存算分离的核心在于将存储与计算解耦,计算节点无状态,实现快速扩缩容。而且,对象存储通常具备更好的数据可靠性和更低的成本。
目前,StarRocks 存算分离技术支持两种后端存储方式:兼容 AWS S3 协议的对象存储系统(主流对象存储均支持)以及传统数据中心部署的 HDFS。该技术将表数据统一存储至对象存储指定的 bucket 或 HDFS 目录中,按根据类型的不同被存储在data/、meta/ 等子目录下。
StarRocks 存算分离数据文件格式与存算一体相同,数据按照 Segment 文件组织,StarRocks 各种索引技术在存算分离表中也同样复用。
1.2 缓存
StarRocks 的存算分离架构解耦了数据存储和计算,实现了它们各自的弹性,从而节约成本并提升弹性能力。但是这种架构也会影响系统性能,尤其是对于追求极速的 StarRocks 而言更为明显。
为了解决存算分离对性能的影响,我们使用磁盘(Local Disk) 来缓存热点数据。用户可以选择在建表时打开热数据缓存并同时指定热数据的生命周期,从数据写入开始到生命周期结束,热数据会一直缓存在本地磁盘中,以提升查询效率。
用户可在建表时指定如下参数来控制数据缓存行为:
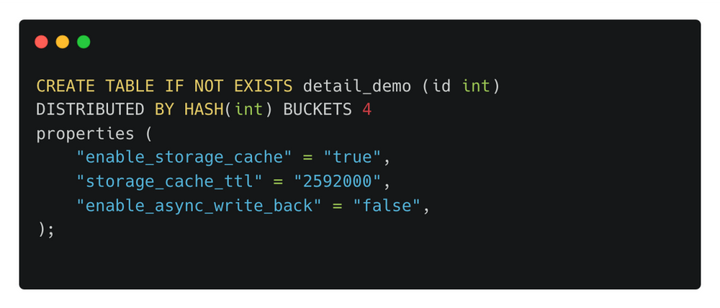
其中:
-
enable_storage_cache:控制是否开启热数据磁盘缓存
-
storage_cache_ttl:热数据缓存生命周期,超过该时间后,热数据会被自动从缓存中淘汰
-
enable_async_write_back:是否开启异步写入
如果开启计算节点磁盘缓存,数据被写入时,会同时写入本地磁盘以及后端存储系统,当两者都成功后才返回。同时,storage_cache_ttl 控制了数据在磁盘上的生存周期。
如果开启 enable_async_write_back,数据写入本地磁盘后便返回,由后台任务负责将其写入对象存储。这种模式适用于追求高吞吐、低延迟的业务场景,但存在一定的数据可靠性风险。
在查询时,热数据通常会直接从缓存中命中,而冷数据则需要从对象存储中读取并填充至本地缓存,以加速后续访问。Profile 也能够清晰地观察到数据读取的冷热分布:
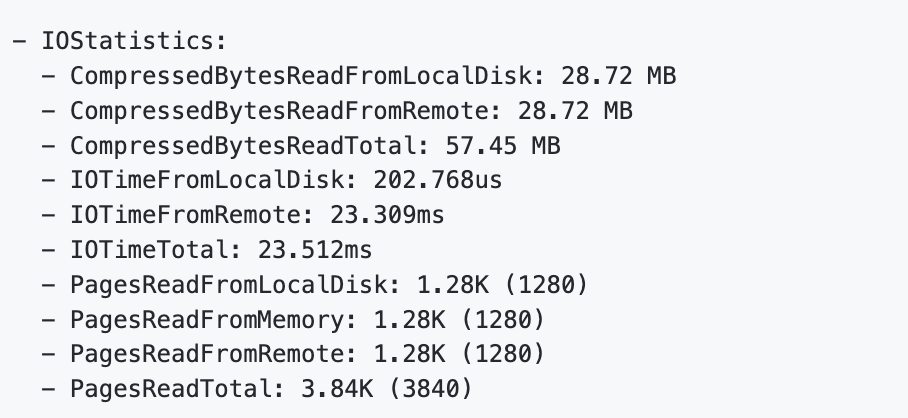
上图显示了某次查询所访问的数据部分来自后端对象存储(PagesReadFromRemote),部分来自本地磁盘缓存(PagesReadFromLocalDisk),部分来自计算节点内存缓存(PagesReadFromMemory)及各自的耗时。
然而,在实际的业务场景中,会存在某些查询涉及历史数据访问量比较大,如果这些极低频访问的冷数据被缓存,那么可能会将热数据挤出,造成性能抖动。针对该问题,我们会在接下来的版本中允许用户在建表时指定策略,避免在访问这些冷数据时将其放入缓存从而淘汰那些真正的热点数据。
同时,针对未在上述任何缓存中命中的冷数据,StarRocks 也进行了优化,可根据应用访问模式,利用数据预读技术从后端读取接下来可能会访问的数据。此举可有效减少对于后端对象存储的访问频次,提升查询性能。我们在实际测试效果中也验证了该优化的有效性,细节可参考文章后面的“性能评估”。
通过内存、本地磁盘、远端存储,StarRocks 存算分离构建了一个多层次的数据访问体系,用户可以指定数据冷热规则以更好地满足业务需求,让热数据靠近计算,真正实现高性能计算和低成本存储。同时,对冷数据访问也进行了预读等针对性优化,有效提升了查询性能下限。
1.3 数据多版本
StarRocks 存算分离中引入了数据多版本技术。用户的每次导入都会在 StarRocks 中生成一个唯一版本号,数据版本一旦产生便不会再更改, Compaction 也只会产生新的数据版本。
StarRocks 存算分离中,每个数据版本包含 Tablet Meta 和 Tablet Data 文件,并且都写入后端对象存储。
TabletMeta 文件内记录了该版本所有的数据文件索引。而 Tablet Data 文件仍然按照 Segment 文件格式组织。一旦 BE 节点需要访问某个Tablet 时,会先根据版本号从后端存储加载对应的 Tablet Meta 文件,然后再根据索引访问相应的数据文件。
StarRocks 存算分离中引入了数据多版本技术,为未来实现 Time Travel 等高级功能打下了基础。
1.4 Compaction
Compaction 是 StarRocks 中最重要的后台任务,它负责将用户的历史版本合并为一个更大的版本以提高查询性能。在存算一体中,BE 节点根据自身负载情况来调度 Compaction 任务。
在存算分离版本中,Compaction 任务调度被上移至 FE 节点。得益于存算分离的数据共享能力,FE 可以选择将 Compaction 任务发往任意 BE 节点执行,甚至未来 FE 可以将 Compaction 任务调度至专用集群,实现对业务的零干扰。同时,根据实际需要,执行 Compaction 任务的资源池也可以动态地进行扩缩容。这样,Compaction 不再成为困扰用户的头疼问题,真正实现了性能和成本的和谐统一。
02 性能评估
存算分离架构能够极大地降低用户的成本,同时提供极致的弹性体验。然而,由于对象存储的高延迟特点,用户仍然担心可能出现的性能问题。为此,我们在存算分离中引入了多项性能优化技术,以应对各种场景。下面的测试结果表明了其所能达到的性能水平,测试主要包含数据导入、冷热数据查询等场景,并与 StarRocks 存算一体架构进行了对比。
2.1 数据导入
我们使用 Clickbench 测试评估了 StarRocks 存算分离 stream load 性能表现,测试中使用 1FE + 3BE 的硬件配置。测试数据格式为 CSV,总量 160 GB,单文件大小为 1GB。
测试主要关注在不同客户端并发下的数据导入吞吐,以下是测试结果:
| 客户端并发数 | 存算一体耗时 / 存算分离耗时 (s) | 存算一体吞吐 / 存算分离吞吐 (MB/s) |
| 1 | 1007/1024 | 162/160 |
| 4 | 377/379 | 434/432 |
| 16 | 363/183 | 451/895 |
随着并发提升,存算分离表的写入吞吐仍在不断提升,直到最终达到了 BE 节点的网络带宽瓶颈。
2.2 数据查询
我们创建了存算一体和存算分离两个同规格集群,并使用 TPC-DS 1TB 数据集来评估性能表现,下图展示了性能对比情况:

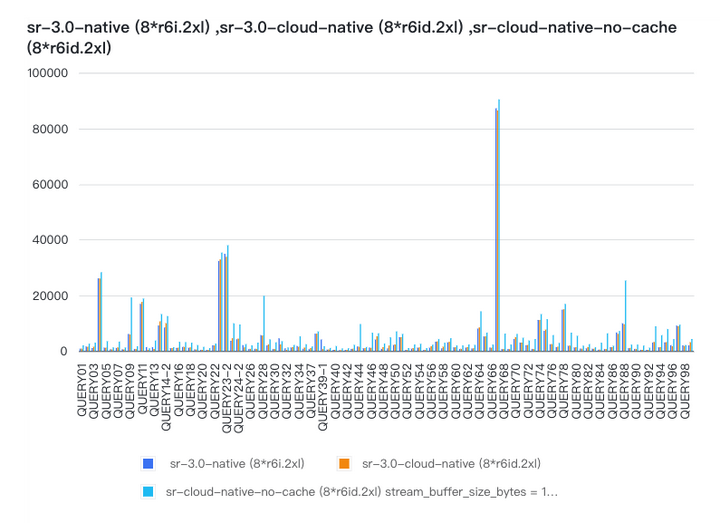
sr-3.0-native 代表存算一体模式的性能,sr-3.0-cloud-native 代表存算分离在数据完全命中缓存情况下性能,而 sr-3.0-cloud-native-no-cache 则是关闭所有缓存(包括内存 page cache 以及 local disk cache)情况下的性能表现。
存算分离版本在缓存完全命中情况下,其总体性能已经追平存算一体(428s VS 423s)。即使在完全访问冷数据情况下,通过预读等优化手段,也很好地将冷数据查询性能衰退控制在一个合理范围内(668s VS 428s)。
总结与展望
从 3.0 版本开始,StarRocks 已经升级为全新的存储计算分离架构。在新架构下,用户不仅可以享受到原有的StarRocks 强大的极速分析能力,还能够受益于存算分离带来的低成本和极致弹性能力。更重要的是,这些能力都是开放共享的,每个 StarRocks 用户都可以受益于 StarRocks 的卓越性能。
接下来,我们将继续发扬 3.0 版本的优势,进一步依托 StarOS,充分利用存算分离的数据共享能力,实现更为灵活的数据分享、资源弹性伸缩和资源隔离能力。我们将构建多计算集群来彻底解决不同业务互相干扰的问题,同时,我们将探索基于 StarOS 构建 WAL 存储等高级能力,进一步提升实时分析处理能力。
最后,正所谓“众人拾柴火焰高”,我们诚挚邀请广大的 StarRocks 社区伙伴们共同携手,共建极速统一的湖仓分析新范式!