文章目录
- 一、前言
- 二、object Detection VS object Recognition(Selective Search的提出)
- 2.1object recognition与object detection的关系
- 2.2滑动窗口方法的局限性
- 2.3Selective search算法的提出
- 三、Selective Search算法
- 3.1什么是Selective Search?
- 3.2图像相似性的计算
- 3.3.给生成的区域打分
- 四、算法评估
- 4.1单个策略评估
- 4.2.多个策略评估
- 五、代码实现
- 六、总结
- 参考博客与资料
一、前言
Selective Search 是两阶段目标检测R-CNN的第一步,在学习目标检测R-CNN之前,有必要了解学习一下SS算法。
二、object Detection VS object Recognition(Selective Search的提出)
2.1object recognition与object detection的关系
object Recognition算法识别图像中存在哪些目标。 它将整个图像作为输入并输出该图像中存在的目标的类标签和类概率。 例如,类标签可以是“狗”,相关的类概率可以是 97%。
而object Detection算法会识别出图像中的目标以及他们的bounding box边界框,来指示目标在图像中的位置。
因此object Detection的核心是object recognition算法。假设我们训练了一个object Recognition模型,它只能检测这张图片里面的是什么类别,但是不能够输出这个目标在在图片中位置。
因此为了定位目标在图像中位置,选择图像的子区域来输入object recognition模型,检测的目标的位置由输入的子区域来确定。
2.2滑动窗口方法的局限性
为了得到子区域,滑动窗口的方法被提出,本质是穷举法,但是会存在很多的局限性:
1)由于object recognition模型一般都是在特定大小的图像上预测,滑动窗口的方法不仅需要考虑子区域的位置,还要考虑子区域的大小,因此这会产生上万个子区域,产生冗余,这大大降低了检测的效率。
2)滑动窗口的方法适合固定宽高比的目标,例如人脸或者行人,因为图像都是三维物体的二维成像,不同的拍摄角度会带来不同的宽高比,使用多种宽高比这会极大的增加运算的复杂性。
2.3Selective search算法的提出
为了解决滑动窗口的限制,提出了很多方法,他们被称为“Region Proposal”,本文要介绍的Selective search是其中最流行的一种。
Region Proposal提出的方法是将图像中最有可能是对象的子区域先检测出来,然后作为子区域输入object recognition模型中。这些子区域可能含有噪声、重叠、目标没有完整在子区域内,但是他们是最接近真实对象的子区域。
由于穷举法只是单纯的滑动窗口,没有好好的利用图像的特征,因此作者在想能不能利用图像本身的特征来减少窗口的数量,提升检测效率。
我们可以先看一张图

假设我们现在不知道需要检测的目标是什么,在a图中,桌子,瓶子、餐具都是我们的候选目标,餐具包含在桌子这个目标内,勺子又在碗中,体现了目标检测的层级关系和尺度关系,那么如何去获取这些可能目标的位置呢,因此作者这时想到了根据图片本身的特征来减少候选框的数量并提高精确度。
在b中很明显颜色是这两只猫最大的不同的,因此颜色可以作为特征来得到候选框,但在图C中,变色龙和树叶都是绿色,颜色就不能作为特征了,但纹理这时候就可以作为特征了,而在图d中,汽车车身和轮胎颜色和纹理尽管都不同,但是它们确实是一个整体,这时候又该用什么特征呢?
Selective search的策略是:
既然是不知道尺度是怎样的,那我们就尽可能遍历所有的尺度好了,但是不同于暴力穷举,我们可以先利用基于图的图像分割的方法得到小尺度的区域,然后一次次合并得到大的尺寸就好了,这样也符合人类的视觉认知。既然特征很多,那就把我们知道的特征都用上,但是同时也要照顾下计算复杂度,不然和穷举法也没啥区别了。最后还要做的是能够对每个区域进行排序,这样你想要多少个候选我就产生多少个,不然总是产生那么多你也用不完不是吗?
在介绍Selective search算法之前,我们有几个需要注意到的点:
适应不同尺度(Capture All Scales):穷举搜索(Exhaustive Selective)通过改变窗口大小来适应物体的不同尺度,选择搜索(Selective Search)同样无法避免这个问题。算法采用了图像分割(Image Segmentation)以及使用一种层次算法(Hierarchical Algorithm)有效地解决了这个问题。
多样化(Diversification):单一的策略无法应对多种类别的图像。使用颜色(color)、纹理(texture)、大小(size)等多种策略对分割好的区域(region)进行合并。
速度快(Fast to Compute):算法,就像功夫一样,唯快不破!
接下来正式介绍Selective Search
三、Selective Search算法
3.1什么是Selective Search?
它是一种用于目标检测的Region Proposal算法,根据颜色、纹理、大小、形状来计算相似区域的层次分组。
它根据像素的强度使用图的方法来进行过度分割。

过度分割方法论文地址:Efficient Graph-Based Image Segmentation
代码地址:seg-ijcv.pdf (brown.edu)
继续回到Selective Search算法,显然我们并不能直接使用上面的分割图来获取子区域,一个原因是原图中的大部分目标都包含2个或者多个分割部分,另一个原因是目标相互包含,例如在图中杯子挡住了盘,且杯子里装满了咖啡。
对于第一个原因,我们可以尝试合并相似的区域来使每个分割部分只包含一个或者两个目标。完美的分割并不是我们的目的,我们使用相似性的方法来融合只是为了可以生成的子区域与目标有更大的重叠。Selective search使用 Felzenszwalb 和 Huttenlocher 方法过度分割作为初始。

过度分割得到的结果如上图所示,将它作为初始,执行下面的步骤:
1)将所有与分段部分对应的边界框添加到Region Proposal列表中
2)基于相似性合并相似的区域
3)回到第一步
这个过程不够详细,具体来看有以下步骤:

具体解释:

举例:下面图展示了这个过程
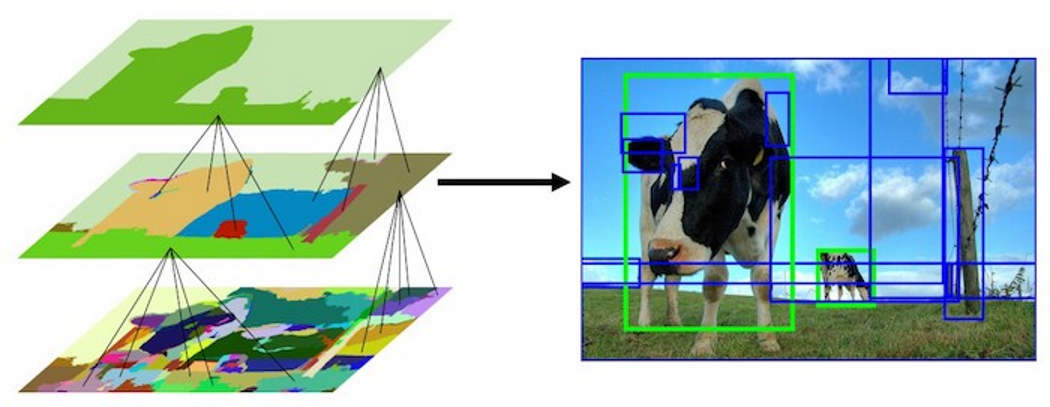
3.2图像相似性的计算
在进行相似度的比较之前,作者对图像进行了一些处理来提高召回率增加候选区域:
主要有三种策略:
- 多种颜色空间,考虑RGB、灰度、HSV及其变种等
- 多种相似度度量标准,既考虑颜色相似度,又考虑纹理、大小、重叠情况等。
- 通过改变阈值初始化原始区域,阈值越大,分割的区域越少。
那么如何比较图像的相似性,主要基于四种相似度:
颜色
s
c
o
l
o
u
r
、纹理
s
t
e
x
t
u
r
e
、大小
s
s
i
z
e
、形状
s
f
i
l
l
颜色s_{colour}、纹理s_{texture}、大小s_{size}、形状s_{fill}
颜色scolour、纹理stexture、大小ssize、形状sfill、

对于Scolour(ri,rj)个人是这样理解的,由于Ci是归一化的向量,那么对于Ci本来是有三个通道的25维向量组成的,每个25维的向量使用L1归一化后和为1,三个通道的累加即为3,假设两个区域完全一模一样,那么他们的相似性将为3,若两个区域差别很大,我们可以设为Ci,Cj,因为有差别,那么这两个75维向量我们可以把每个向量拆为3个25维向量,由于Ci,Cj有差别,那么至少有一个25维向量在两个区域是不一样的,我们可以假设这两个25维下向量分别为Di,Dj,每个向量和为1,又由于取两者中的更小的求和,那么最终的结果会小于1,那么两个不同的Ci,Cj求相似度会小于3,它们越不相似,求和越小。
对于直方图不了解的可以去看我的另一篇博客(博客地址)。
Ct为新的合并区域的直方图向量

这里使用到了SIFT-Like特征,Scale-invariant feature transform,中文含义就是尺度不变特征变换。SIFT算法是一个经典的特征描述算法,在传统的目标检测很受欢迎,不同于以往的传统目标检测算法对图片的大小、旋转非常敏感,SIFT算法不仅对图片大小和旋转不敏感,而且对光照、噪声等影响的抗击能力也非常优秀。区域之间纹理相似度的计算方式与颜色相似度一样,合并后的区域计算方式也一样。

优先合并小的区域,如果仅仅是通过颜色和纹理特征合并的话,很容易使得合并后的区域不断吞并周围的区域,后果就是多尺度只应用在了那个局部,而不是全局的多尺度。因此我们给小的区域更多的权重,这样保证在图像每个位置都是多尺度的在合并。
上面公式表明合并的区域越小,相似性越大。

这个主要用来限制区域的空间位置,如果某个区域包含在另一个区域内部,我们应该首先合并,如果两个区域不相邻,则会形成“断崖”,它们不该合并在一起,当BBij越小,空间交叠相似性越接近1。
总的相似度为四种相似度线性叠加:
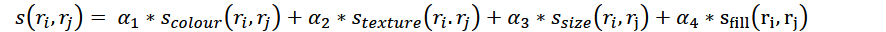
其中参数α为0或者1
3.3.给生成的区域打分
通过上述的步骤我们能够得到很多很多的区域,但是显然不是每个区域作为目标的可能性都是相同的,因此我们需要衡量这个可能性,这样就可以根据我们的需要筛选区域建议个数。
这篇文章做法是,给予最先合并的图片块较大的权重,比如最后一块完整图像权重为1,倒数第二次合并的区域权重为2以此类推。但是当我们策略很多,多样性很多的时候呢,这个权重就会有太多的重合了,排序不好搞啊。文章做法是给他们乘以一个随机数,毕竟3分看运气嘛,然后对于相同的区域多次出现的也叠加下权重,毕竟多个方法都说你是目标,也是有理由的嘛。这样我就得到了所有区域的目标分数,也就可以根据自己的需要选择需要多少个区域了。
四、算法评估
对于预测的bounding box与真实的框的重叠面积越大,则算法性能越高,这里使用的是平均最高重叠率ABO(Average best overlap),对于单个类别C,假设每个真实框
G^c,对于预测的L中每一个l
如下公式:
A
B
O
=
1
∣
G
c
∣
Σ
g
i
c
∈
G
c
max
l
i
∈
L
O
v
e
r
l
a
p
(
g
i
c
,
l
j
)
ABO = \frac{1}{|G^c|} \Sigma_{g_{i}^c \in G^c}\max_{l_i\in L}Overlap(g_{i}^c,l_j)
ABO=∣Gc∣1Σgic∈Gcli∈LmaxOverlap(gic,lj)
o
v
e
r
l
a
p
(
g
i
c
,
l
j
)
=
a
r
e
a
(
g
i
c
)
∩
a
r
e
a
(
l
j
)
a
r
e
a
(
g
i
c
)
∪
a
r
e
a
(
l
j
)
overlap(g_{i}^c,l_j) = \frac{area(g_{i}^c)\cap area(l_j)} {area(g_{i}^c)\cup area(l_j)}
overlap(gic,lj)=area(gic)∪area(lj)area(gic)∩area(lj)
以上为单独一个类别的ABO,要评估还要加上所有类别也即得到MABO(Mean Average Best Overalp).
4.1单个策略评估
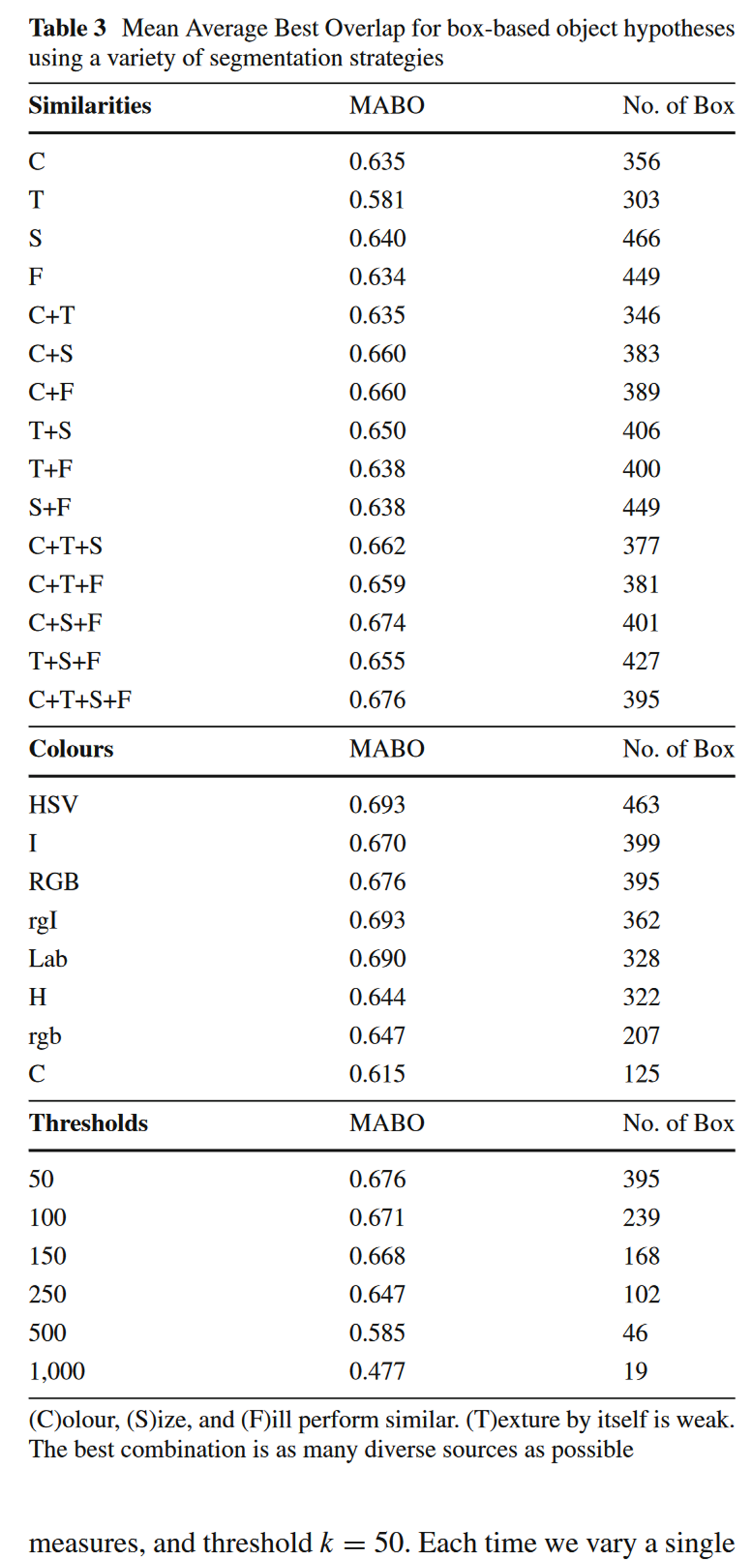
我们可以通过改变多样性策略中的任何一种,评估选择性搜索的MABO性能指标。论文中采取的策略如下:
使用RGB色彩空间(基于图的图像分割会利用不同的色彩进行图像区域分割)
采用四种相似度计算的组合方式
设置图像分割的阈值k=50
然后通过改变其中一个策略参数,获取MABO性能指标如下表(第一列为改变的参数,第二列为MABO值,第三列为获取的候选区的个数):
基础设置:颜色模式为RGB,相似度为四种相似性的结合,thresholds为50
表中Similarities为不同的相似度组合,单独的,我们可以看到纹理相似度表现最差,MABO为0.581,其他的MABO值介于0.63和0.64之间。当使用多种相似度组合时MABO性能优于单种相似度。colour使用HSV颜色空间,有463个候选区域,而且MABO值最大为0.693。threshoids使用较小的阈值,会得到更多的候选区和较高的MABO值。
4.2.多个策略评估
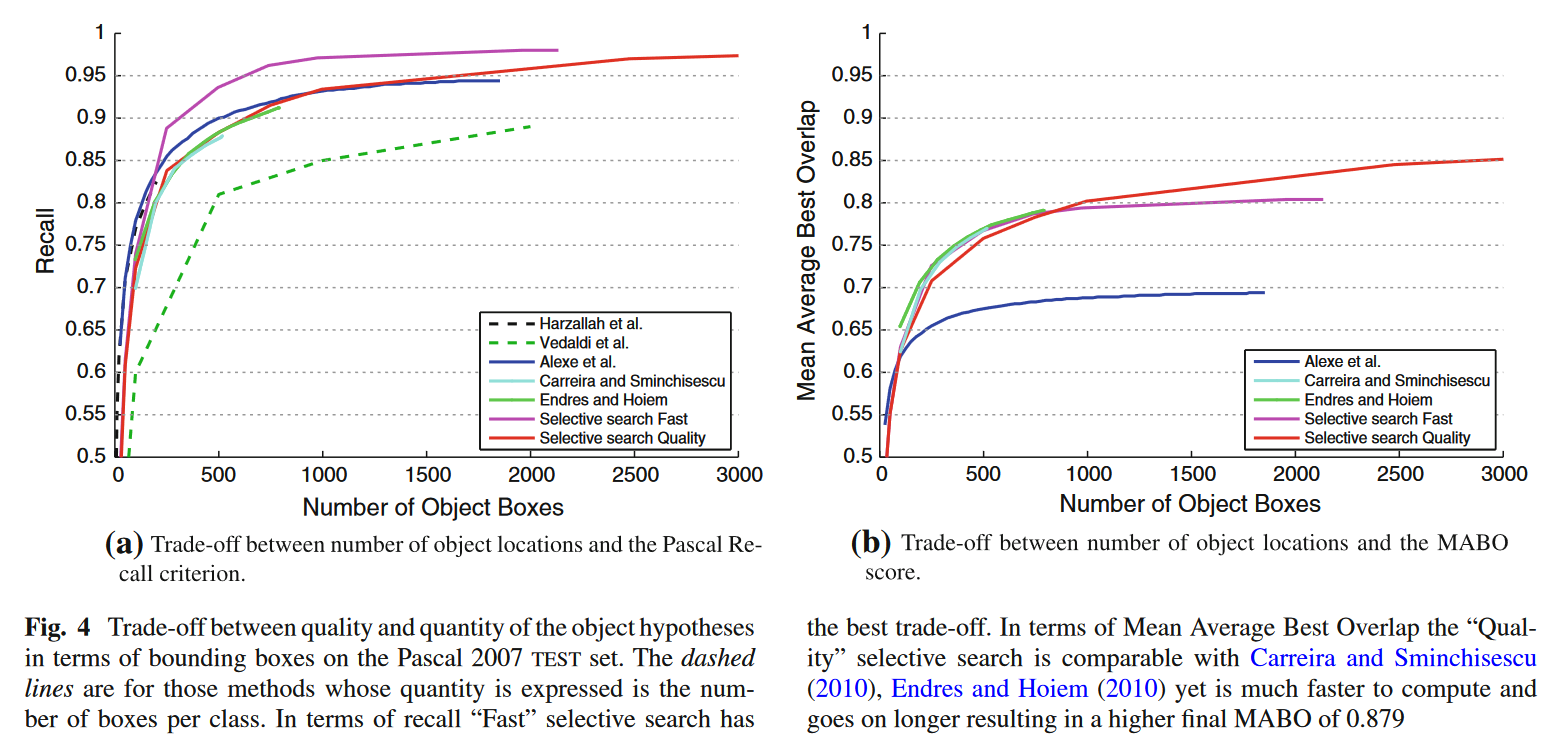
这三种策略不同组合的结果如下:
采取贪婪的策略,无疑会提升效果,但也需要付出一些代价,计算成本的增加,时间的延长,需要我们做一个平衡。

作者做了很多实验,更多的实验分析可以去看原文
至于为什么Selective search得到大约2000个预测框,主要还是由于这个时候的性价比是最高的,有着基本上最好的效果,计算成本也不是很大。
五、代码实现
我们可以直接下载Selective Search包
# -*- coding: utf-8 -*-
from __future__ import (
division,
print_function,
)
import skimage.data
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import selectivesearch
def main():
# loading astronaut image
img = skimage.data.astronaut()
# perform selective search
img_lbl, regions = selectivesearch.selective_search(
img, scale=500, sigma=0.9, min_size=10)
candidates = set()
for r in regions:
# excluding same rectangle (with different segments)
if r['rect'] in candidates:
continue
# excluding regions smaller than 2000 pixels
if r['size'] < 2000:
continue
# distorted rects
x, y, w, h = r['rect']
if w / h > 1.2 or h / w > 1.2:
continue
candidates.add(r['rect'])
# draw rectangles on the original image
fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))
ax.imshow(img)
for x, y, w, h in candidates:
print(x, y, w, h)
rect = mpatches.Rectangle(
(x, y), w, h, fill=False, edgecolor='red', linewidth=1)
ax.add_patch(rect)
plt.show()
if __name__ == "__main__":
main()
运行后结果

六、总结
本文拙劣的花了很多时间来写,参考了很多博客,下面参考博客的第一篇,是目前看到写的最好的一篇博客,借鉴了很多,通过学习这个selective search的过程,我发现自己的基础很薄弱,好多算法,好多术语都不了解,本人水平有限.
关于直方图的知识和SIFT的原理暂时没有写,主要还是很费时间,写这篇博客已经花了很多时间了。
基于图的图像分割算法:暂时没有写笔记,留待后续继续写,可以去看这篇博客
Efficient Graph-Based Image Segmentation_surgewong的博客-CSDN博客
参考博客与资料
[1]第三十三节,目标检测之选择性搜索-Selective Search - 大奥特曼打小怪兽 - 博客园 (cnblogs.com)
[2]Selective Search for Object Detection (C++ / Python) | LearnOpenCV
[3]代码地址:AlpacaTechJP/selectivesearch: Selective Search Implementation for Python (github.com)
[4]原论文地址:www.eecs.qmul.ac.uk/~sgg/ECS795P/papers/WK09_SelectiveSearch_Uijlings_IJCV2013.pdf