对于基于视频分析的问题,2D卷积(卷积核为二维)不能很好得捕获时序上的信息,因此《3D convolutional neural networks for human action recognition》 这片论文提出了3D卷积并用于行为识别的,论文中将其用于行为识别,场景识别,视频相似度分析等领域。
3D卷积与2D卷积的区别
首先看一下二维卷积,一个3*3的卷积核,在单通道图像上进行卷积,得到输出。
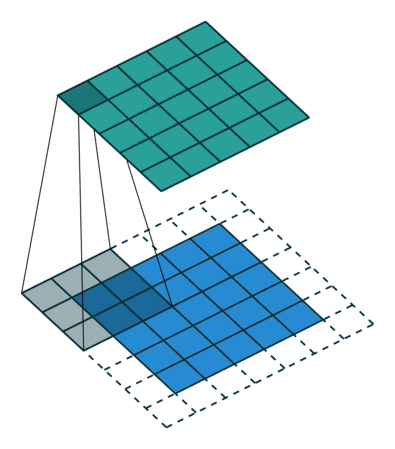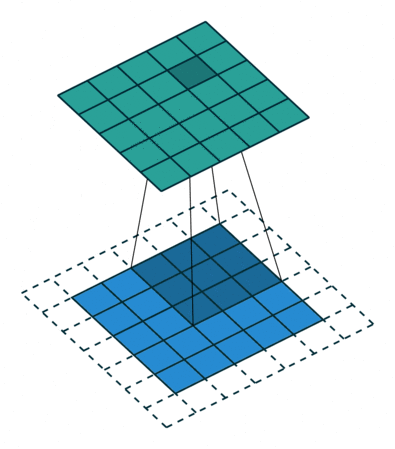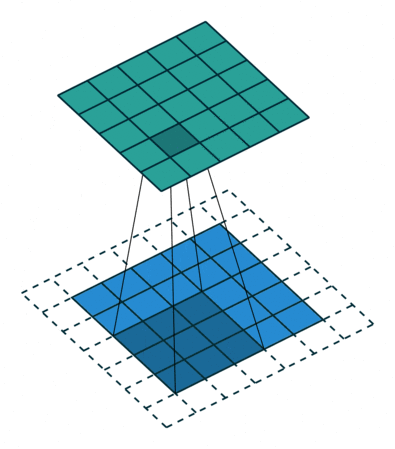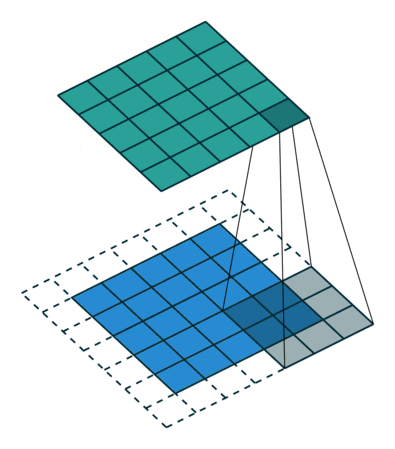
然后我们再看一下3维卷积,一个3*3*3的卷积核在立方体上进行卷积,得到输出:
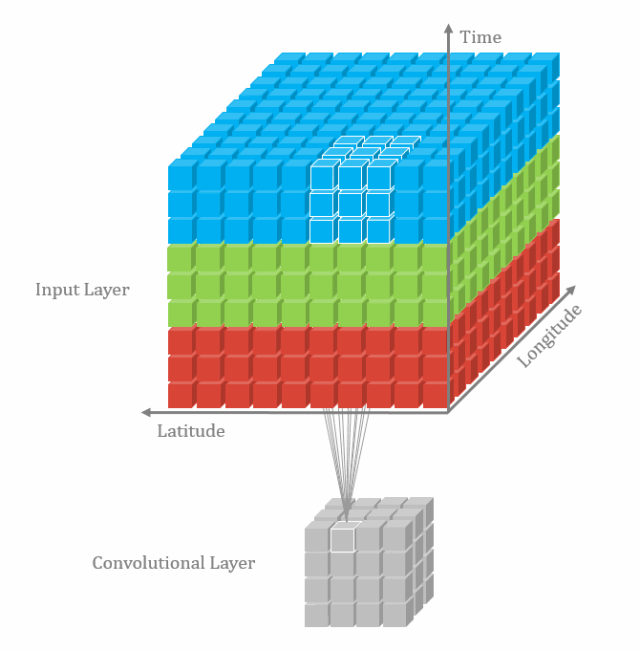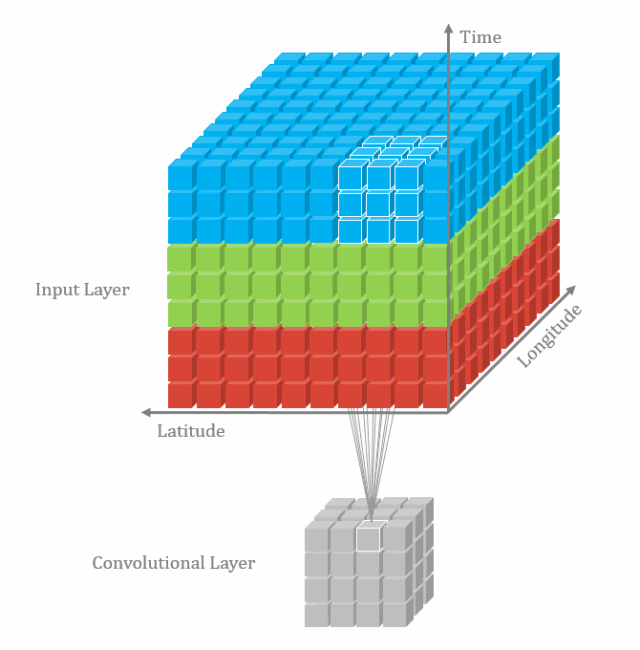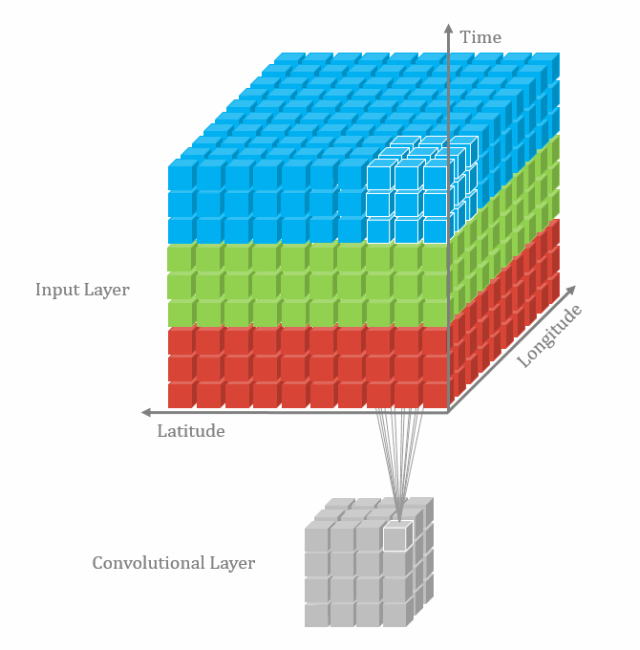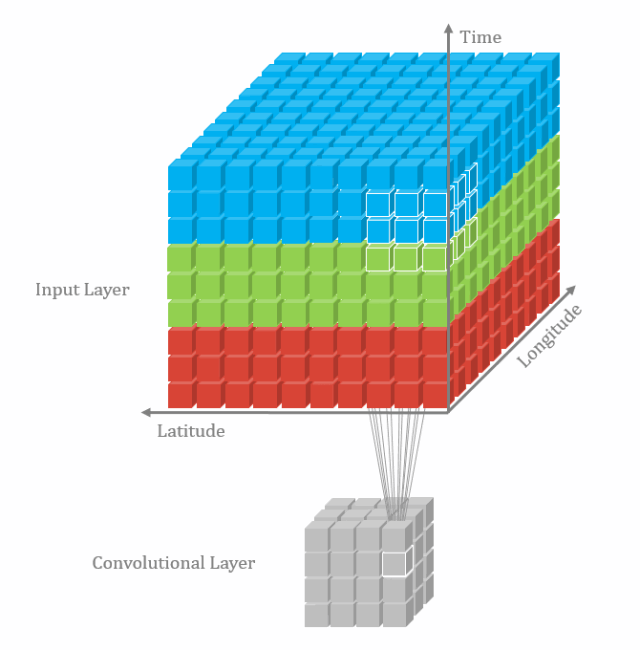
多通道卷积不同的通道上的卷积核的参数是不同的,而3D卷积则由于卷积核本身是3D的,所以这个由于“深度”造成的看似不同通道上用的就是同一个卷积,权重共享。
总之,多了一个深度通道,这个深度可能是视频上的连续帧,也可能是立体图像中的不同切片。
基于C3D网络视频动作分析
C3D模型
视频分析中,时间序列维度上通过一次输入连续帧到C3D网络中进行分析,注意和图像分析中的batch进行区分,C3D网络输入的维度多了一个时间维度,一次会传入前后多张图像。
论文链接
该论文发现:
1、3D ConvNets比2D ConvNets更适用于时空特征的学习;
2、对于3D ConvNet而言,在所有层使用3×3×3的小卷积核效果最好;
3、我们通过简单的线性分类器学到的特征名为C3D(Convolutional 3D),在4个不同的基准上优于现有的方法,并在其他2个基准上与目前最好的方法相当。
class C3D(nn.Module):
"""
The C3D network.
"""
def __init__(self, num_classes):
super(C3D, self).__init__()
self.conv1 = nn.Conv3d(3, 64, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool1 = nn.MaxPool3d(kernel_size=(1, 2, 2), stride=(1, 2, 2))
self.conv2 = nn.Conv3d(64, 128, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool2 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2))
self.conv3a = nn.Conv3d(128, 256, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.conv3b = nn.Conv3d(256, 256, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool3 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2))
self.conv4a = nn.Conv3d(256, 512, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.conv4b = nn.Conv3d(512, 512, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool4 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2))
self.conv5a = nn.Conv3d(512, 512, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.conv5b = nn.Conv3d(512, 512, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool5 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2), padding=(0, 1, 1))
self.fc6 = nn.Linear(8192, 4096)
self.fc7 = nn.Linear(4096, 4096)
self.fc8 = nn.Linear(4096, num_classes)
self.dropout = nn.Dropout(p=0.5)
self.relu = nn.ReLU()
self.__init_weight()
def forward(self, x):
#print ('1:',x.size())
x = self.relu(self.conv1(x))
#print ('2:',x.size())
x = self.pool1(x)
#print ('3:',x.size())
x = self.relu(self.conv2(x))
#print ('4:',x.size())
x = self.pool2(x)
#print ('5:',x.size())
x = self.relu(self.conv3a(x))
#print ('6:',x.size())
x = self.relu(self.conv3b(x))
#print ('7:',x.size())
x = self.pool3(x)
#print ('8:',x.size())
x = self.relu(self.conv4a(x))
#print ('9:',x.size())
x = self.relu(self.conv4b(x))
#print ('10:',x.size())
x = self.pool4(x)
#print ('11:',x.size())
x = self.relu(self.conv5a(x))
#print ('12:',x.size())
x = self.relu(self.conv5b(x))
#print ('13:',x.size())
x = self.pool5(x)
#print ('14:',x.size())
x = x.view(-1, 8192)
#print ('15:',x.size())
x = self.relu(self.fc6(x))
#print ('16:',x.size())
x = self.dropout(x)
x = self.relu(self.fc7(x))
x = self.dropout(x)
logits = self.fc8(x)
#print ('17:',logits.size())
return logits
- C3D网络架构跟2D网络架构的区别,就是多了一个时间维度。它的kernel_size和pading、stride都是对应的三维的,如kernel_size=(3,3,3) 和 padding=(1,2,2),stride=(2,2,2)。其中kernel_size中第一个3表示3帧卷积一次提取特征。
- 第一次Maxpool3d对应的kernel_size=(1,2,2)和stride_size(1,2,2),其中时间维度对应kernel值为1,w,h对应2,说明经过该Maxpool3d时间维度大小不变,图片宽高的特征变为一半。原作者解释,在做3D卷积时,不希望一开始就压缩时间维度上的特征。
- 第二次Maxpool3d对应的kernel_size=(2,2,2)和stride_size(2,2,2)都变为2,进行时间维度、w,h方向的特征压缩,同时channel越来越大。
- 最后通过连接3个连接层,输出最终的结果。
UCF-101 数据集
UCF101是一个现实动作视频的动作识别数据集,收集自YouTube,提供了来自101个动作类别的13320个视频。
总视频数:13,320个视频
总时长:27个小时
视频来源:YouTube采集
视频类别:101 种
主要包括5大类动作 :人与物体交互,单纯的肢体动作,人与人交互,演奏乐器,体育运动
每个类别(文件夹)分为25组,每组4~7个短视频,每个视频时长不等
具体类别:涂抹眼妆,涂抹口红,射箭,婴儿爬行,平衡木,乐队游行,棒球场,篮球投篮,篮球扣篮,卧推,骑自行车,台球射击,吹干头发,吹蜡烛,体重蹲,保龄球,拳击沙袋,拳击速度袋,蛙泳,刷牙,清洁和挺举,悬崖跳水,板球保龄球,板球射击,在厨房切割,潜水,打鼓,击剑,曲棍球罚款,地板体操,飞盘接球,前爬网,高尔夫挥杆,理发,链球掷,锤击,倒立俯卧撑,倒立行走,头部按摩,跳高,跑马,骑马,呼啦圈,冰舞,标枪掷,杂耍球,跳绳,跳跃杰克,皮划艇,针织,跳远,刺,阅兵,混合击球手,拖地板,修女夹头,双杠,披萨折腾,弹吉他,弹钢琴,弹塔布拉琴,弹小提琴,弹大提琴,弹Daf,弹Dhol,弹长笛,弹奏锡塔琴,撑竿跳高,鞍马,引体向上,拳打,俯卧撑,漂流,室内攀岩,爬绳,划船,莎莎旋转,剃胡子,铅球,滑板溜冰,滑雪,Skijet,跳伞,足球杂耍,足球罚球,静环,相扑摔跤,冲浪,秋千,乒乓球拍,太极拳,网球秋千,投掷铁饼,蹦床跳跃,打字,高低杠,排球突刺,与狗同行,墙上俯卧撑,在船上写字,溜溜球。剃胡须,铅球,滑冰登机,滑雪,Skijet,跳伞,足球杂耍,足球罚款,静物环,相扑,冲浪,秋千,乒乓球射击,太极拳,网球秋千,掷铁饼,蹦床跳跃,打字,不均匀酒吧,排球突刺,与狗同行,壁式俯卧撑,船上写字,溜溜球。剃胡须,铅球,滑冰登机,滑雪,Skijet,跳伞,足球杂耍,足球罚款,静物环,相扑,冲浪,秋千,乒乓球射击,太极拳,网球秋千,掷铁饼,蹦床跳跃,打字,不均匀酒吧,排球突刺,与狗同行,壁式俯卧撑,船上写字,溜溜球
每种视频类型,包括一系列的视频片段:

数据集下载
UCF101数据下载
官方数据划分下载
数据处理
有了视频之后需要干什么呢?实际在网络输入的时候真能输入一个视频吗?,答案肯定不是的。大家想想我们构造C3D模型进行动作分析,输入3D的卷积中,除了第一个维度batch之外,第二个维度代表是序列的长度,假设序列的长度是16,那么在视频处理时我们需要从中提取出16帧的图像。因此我们需要先对视频数据集做预处理,从每个视频中抽取16帧,16帧组成输入的16个序列。
大家可能会觉得做模型训练过程中,把视频读进来,边抽取数据会比较好,答案是可以的,但相对会比较麻烦,这样会导致每次训练过程,都需要从视频中抽取数据,而且训练过程还需要调参,需要消耗大量的算力。
所以在拿到视频数据后,第一步都需要对视频数据做预处理,把视频数据转换为后续需要用的一帧帧图像数据,并且保存到文件中,这样后续建模中会更加方便。
将UCF-101视频数据按每类动作视频抽取的图像,并划分训练集、验证集、测试集。提取后的图片数据单独存放在data_process文件夹,data_process下面新建test,train,val文件

如果不想从视频中提取划分图片,可以直接下载官方划分好的数据集
- 对视频每隔EXTRACT_FREQUENCY提取一帧图像,·EXTRACT_FREQUENCY·初始化为4(每隔4帧区一张图像),但由于各个视频长短不一样,为了保证每个视频至少能够提取16张图像,所以针对不同视频调整EXTRACT_FREQUENCY的值。
- 根据论文,需要将图像的宽高调整到:(171,128),其中代码中self.resize_width=171,self.resize_height=128,另外还需要将得到的图片随机裁剪crop_size=112大小。
- 提取每个视频16张图片序列,输入到C3D模型中
def preprocess(self):
if not os.path.exists(self.output_dir):
os.mkdir(self.output_dir)
os.mkdir(os.path.join(self.output_dir, 'train'))
os.mkdir(os.path.join(self.output_dir, 'val'))
os.mkdir(os.path.join(self.output_dir, 'test'))
# Split train/val/test sets
for file in os.listdir(self.root_dir):
file_path = os.path.join(self.root_dir, file)
video_files = [name for name in os.listdir(file_path)]
train_and_valid, test = train_test_split(video_files, test_size=0.2, random_state=42)
train, val = train_test_split(train_and_valid, test_size=0.2, random_state=42)
train_dir = os.path.join(self.output_dir, 'train', file)
val_dir = os.path.join(self.output_dir, 'val', file)
test_dir = os.path.join(self.output_dir, 'test', file)
if not os.path.exists(train_dir):
os.mkdir(train_dir)
if not os.path.exists(val_dir):
os.mkdir(val_dir)
if not os.path.exists(test_dir):
os.mkdir(test_dir)
for video in train:
self.process_video(video, file, train_dir)
for video in val:
self.process_video(video, file, val_dir)
for video in test:
self.process_video(video, file, test_dir)
print('Preprocessing finished.')
def process_video(self, video, action_name, save_dir):
# Initialize a VideoCapture object to read video data into a numpy array
video_filename = video.split('.')[0]
if not os.path.exists(os.path.join(save_dir, video_filename)):
os.mkdir(os.path.join(save_dir, video_filename))
capture = cv2.VideoCapture(os.path.join(self.root_dir, action_name, video))
frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))
frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
# Make sure splited video has at least 16 frames
EXTRACT_FREQUENCY = 4
if frame_count // EXTRACT_FREQUENCY <= 16:
EXTRACT_FREQUENCY -= 1
if frame_count // EXTRACT_FREQUENCY <= 16:
EXTRACT_FREQUENCY -= 1
if frame_count // EXTRACT_FREQUENCY <= 16:
EXTRACT_FREQUENCY -= 1
count = 0
i = 0
retaining = True
while (count < frame_count and retaining):
retaining, frame = capture.read()
if frame is None:
continue
if count % EXTRACT_FREQUENCY == 0:
if (frame_height != self.resize_height) or (frame_width != self.resize_width):
frame = cv2.resize(frame, (self.resize_width, self.resize_height))
cv2.imwrite(filename=os.path.join(save_dir, video_filename, '0000{}.jpg'.format(str(i))), img=frame)
i += 1
count += 1
# Release the VideoCapture once it is no longer needed
capture.release()
def load_frames(self, file_dir):
frames = sorted([os.path.join(file_dir, img) for img in os.listdir(file_dir)])
frame_count = len(frames)
buffer = np.empty((frame_count, self.resize_height, self.resize_width, 3), np.dtype('float32'))
for i, frame_name in enumerate(frames):
frame = np.array(cv2.imread(frame_name)).astype(np.float64)
buffer[i] = frame
return buffer
def crop(self, buffer, clip_len, crop_size):
# randomly select time index for temporal jittering
time_index = np.random.randint(buffer.shape[0] - clip_len)
# Randomly select start indices in order to crop the video
height_index = np.random.randint(buffer.shape[1] - crop_size)
width_index = np.random.randint(buffer.shape[2] - crop_size)
# Crop and jitter the video using indexing. The spatial crop is performed on
# the entire array, so each frame is cropped in the same location. The temporal
# jitter takes place via the selection of consecutive frames
buffer = buffer[time_index:time_index + clip_len,
height_index:height_index + crop_size,
width_index:width_index + crop_size, :]
return buffer
自定义Dataset
有时候,在处理大数据集时,一次将整个数据加载到内存中变得非常难。因此,唯一的方法是将数据分批加载到内存中进行处理,这需要编写额外的代码来执行此操作。对此,PyTorch 已经提供了 Dataloader 功能。
下面显示了 PyTorch 库中DataLoader函数的语法及其参数信息。
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False)
参见pytorch官方文档,
主要参数:
- dataset (dataset)—从其中加载数据的数据集。
- Batch_size (int,可选)-每批加载多少个样本(默认值:1)。
- shuffle (bool,可选)-设置为True在每个时期重新洗牌数据(默认:False)。
- sampler (sampler或Iterable,可选)-定义从数据集中抽取样本的策略。可以是任何实现了__len__的可迭代对象。如果指定了,则不能指定shuffle。
- batch_sampler (Sampler或Iterable,可选)-类似于Sampler,但每次返回一批索引。与batch_size、shuffle、sampler和dro函数互斥
- num_workers (int,可选)——用于数据加载的子进程数。0表示数据将在主进程中加载。(默认值:0)
- collate_fn(可调用,可选)-合并一个样本列表,形成一个张量的小批。当从映射风格的数据集使用批处理加载时使用。
- pin_memory (bool,可选)-如果为True,数据加载器将在返回张量之前将张量复制到CUDA固定内存中。
- drop_last (bool,可选)-如果数据集大小不能被批处理大小整除,则设置为True将删除最后一个未完成的批处理。如果为False且数据集的大小不能被批处理大小整除,则最后一批将更小。(默认值:False)
- Timeout(数值,可选)-如果为正值,则为从workers中收集批处理的超时值。应该总是非负的。(默认值:0)
- worker_init_fn(可调用,可选)-如果不是None,将在每个worker子进程上调用这个- worker id (int in [0, num_workers - 1])作为输入,在播种之后和数据加载之前。
- generator(torch.Generator,Generator,可选)-如果不是None,则RandomSampler将使用该RNG生成随机索引,并使用multiprocessing为worker生成base_seed。(默认值:无)
- prefetch_factor (int,可选,仅关键字arg) -每个worker预先加载的样本数量。2表示在所有workers中总共会预取2 * num_workers样本。(默认值:2)
- persistent_workers (bool,可选)-如果为True,数据加载器将不会在一个数据集被使用一次后关闭工作进程。这允许保持workers Dataset实例是活的。(默认值:False)
DataLoader支持map-style和可iterable-style数据集,可以单进程或多进程加载、自定义加载顺序和可选的自动批处理(排序)和内存固定。其中map-style类的数据集需要继承Dataset类,通过继承Dataset类自定义数据集。
pytorch自定义数据集,需要继承Dataset类,并改写__init__, len,__getitme__函数。具体结构如下:
class ReadDataset(Dataset):
def __init__(self, 参数...):
def __len__(self, 参数...):
...
return 数据长度
def __getitem__(self, 参数...):
...
return 字典
自定义Dataset的代码如下:
class VideoDataset(Dataset):
r"""A Dataset for a folder of videos. Expects the directory structure to be
directory->[train/val/test]->[class labels]->[videos]. Initializes with a list
of all file names, along with an array of labels, with label being automatically
inferred from the respective folder names.
Args:
dataset (str): Name of dataset. Defaults to 'ucf101'.
split (str): Determines which folder of the directory the dataset will read from. Defaults to 'train'.
clip_len (int): Determines how many frames are there in each clip. Defaults to 16.
preprocess (bool): Determines whether to preprocess dataset. Default is False.
"""
# 注意第一次要预处理数据的
def __init__(self, dataset='ucf101', split='train', clip_len=16, preprocess=False):
self.root_dir, self.output_dir = Path.db_dir(dataset)
folder = os.path.join(self.output_dir, split)
self.clip_len = clip_len
self.split = split
# The following three parameters are chosen as described in the paper section 4.1
self.resize_height = 128
self.resize_width = 171
self.crop_size = 112
if not self.check_integrity():
raise RuntimeError('Dataset not found or corrupted.' +
' You need to download it from official website.')
if (not self.check_preprocess()) or preprocess:
print('Preprocessing of {} dataset, this will take long, but it will be done only once.'.format(dataset))
self.preprocess()
# Obtain all the filenames of files inside all the class folders
# Going through each class folder one at a time
self.fnames, labels = [], []
for label in sorted(os.listdir(folder)):
for fname in os.listdir(os.path.join(folder, label)):
self.fnames.append(os.path.join(folder, label, fname))
labels.append(label)
assert len(labels) == len(self.fnames)
print('Number of {} videos: {:d}'.format(split, len(self.fnames)))
# Prepare a mapping between the label names (strings) and indices (ints)
self.label2index = {label: index for index, label in enumerate(sorted(set(labels)))}
# Convert the list of label names into an array of label indices
self.label_array = np.array([self.label2index[label] for label in labels], dtype=int)
if dataset == "ucf101":
if not os.path.exists('dataloaders/ucf_labels.txt'):
with open('dataloaders/ucf_labels.txt', 'w') as f:
for id, label in enumerate(sorted(self.label2index)):
f.writelines(str(id+1) + ' ' + label + '\n')
elif dataset == 'hmdb51':
if not os.path.exists('dataloaders/hmdb_labels.txt'):
with open('dataloaders/hmdb_labels.txt', 'w') as f:
for id, label in enumerate(sorted(self.label2index)):
f.writelines(str(id+1) + ' ' + label + '\n')
def __len__(self):
return len(self.fnames)
#需要重写__getitem__方法
def __getitem__(self, index):
# Loading and preprocessing.
buffer = self.load_frames(self.fnames[index]) #一共有8460个文件夹
buffer = self.crop(buffer, self.clip_len, self.crop_size)
labels = np.array(self.label_array[index])
if self.split == 'test':
# Perform data augmentation
buffer = self.randomflip(buffer)
buffer = self.normalize(buffer)
buffer = self.to_tensor(buffer)
return torch.from_numpy(buffer), torch.from_numpy(labels)
- self.load_frames(),将每个视频提取后的图片,保存在一个buffer中。
- self.crop() , 对self.load_frames()保存的buffer数据中,截取clip_len=16张时序图片,并对每张图片在w,h维度上随机裁取crop_size=112大小。
- 对test数据通过self.randomflip(),水平随机翻转进行数据增强
- self.normalize() 对图片数据沿着RGB3通道进行去均值的操作,3通道的均值为:np.array([[[90.0,98.0,102.0]]]) ,训练集进行去均值处理,同理测试集也需要去均值处理。
- torch.from_numpy 将nd.array格式的数据,不满足pytorch tensor的数据格式要求,因此通过torch.from_numpy将数据转换为tensor格式
- __getitem__(self, index)返回对应index索引下的buffer数据和标签labels
创建GPU训练环境
- 虚拟环境创建
conda create -n C3D_env python=3.8 -y
conda activate C3D_env
- 安装pytorch_gpu环境
训练脚本介绍
代码结构如下,其中train.py为训练的脚本
设置训练参数:
# Use GPU if available else revert to CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("Device being used:", device)
nEpochs = 101 # Number of epochs for training
resume_epoch = 0 # Default is 0, change if want to resume
useTest = True # See evolution of the test set when training
nTestInterval = 20 # Run on test set every nTestInterval epochs
snapshot = 25 # Store a model every snapshot epochs
lr = 1e-5 # Learning rate
- resume_epoch当训练中断时,可以不需要重新开始训练,可以从设置resume_epoch处开始训练,如resume_epoch=30,表示从之前epoch=30的训练结果中开始训练。
- snapshot=25表示每隔25个epoch保存一次模型
- lr = 1e-5 ,指定了一个非常小的学习率
准备用于训练、验证、测试的dataloader数据
train_dataloader = DataLoader(VideoDataset(dataset=dataset, split='train',clip_len=16), batch_size=6, shuffle=True, num_workers=0)
val_dataloader = DataLoader(VideoDataset(dataset=dataset, split='val', clip_len=16), batch_size=6, num_workers=0)
test_dataloader = DataLoader(VideoDataset(dataset=dataset, split='test', clip_len=16), batch_size=6, num_workers=0)
- 其中clip_len=16表示时间序列长度,一次性处理16帧的数据,时间序列维度正是3D卷积相比2D卷积新增加的特性,具有时间特性。
- batch_size表示批处理的数据。输入网络数据的维度为(batch_size,channel,clip_len,w,h) 。batch_sizebatch_size越大,一个epoch迭代的次数就越少,因此训练速度就越快。如果你显卡是12G以上,可以尝试设置为24,如果显卡的内存不足可以减少batch_size
训练过程说明
训练过程,每个epoch,通过sceduler.step()更新学习率lr,验证阶段不需要,代码上设置如下:
if phase == 'train':
# scheduler.step() is to be called once every epoch during training
scheduler.step()
model.train()
else:
model.eval()
- 然后通过dataloader加载数据和标签,将数据带入模型,在训练阶段更新梯度,验证阶段不更新。通过Softmax计算输出的分类概率,去概率最大的索引作为预测的类别索引。
- 每个epoch结束时计算一次平均损失,以及精度,并将结果保存到tensorboard,方便查看训练过程的损失和精度变化。
for epoch in range(resume_epoch, num_epochs):
# each epoch has a training and validation step
for phase in ['train', 'val']:
start_time = timeit.default_timer()
# reset the running loss and corrects
running_loss = 0.0
running_corrects = 0.0
# set model to train() or eval() mode depending on whether it is trained
# or being validated. Primarily affects layers such as BatchNorm or Dropout.
if phase == 'train':
# scheduler.step() is to be called once every epoch during training
scheduler.step()
model.train()
else:
model.eval()
for inputs, labels in tqdm(trainval_loaders[phase]):
# move inputs and labels to the device the training is taking place on
inputs = Variable(inputs, requires_grad=True).to(device)
labels = Variable(labels).to(device)
optimizer.zero_grad()
if phase == 'train':
outputs = model(inputs)
else:
with torch.no_grad():
outputs = model(inputs)
probs = nn.Softmax(dim=1)(outputs)
preds = torch.max(probs, 1)[1]
loss = criterion(outputs, labels.long())
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / trainval_sizes[phase]
epoch_acc = running_corrects.double() / trainval_sizes[phase]
if phase == 'train':
writer.add_scalar('data/train_loss_epoch', epoch_loss, epoch)
writer.add_scalar('data/train_acc_epoch', epoch_acc, epoch)
else:
writer.add_scalar('data/val_loss_epoch', epoch_loss, epoch)
writer.add_scalar('data/val_acc_epoch', epoch_acc, epoch)
保存模型
if epoch % save_epoch == (save_epoch - 1):
torch.save({
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'opt_dict': optimizer.state_dict(),
}, os.path.join(save_dir, 'models', saveName + '_epoch-' + str(epoch) + '.pth.tar'))
print("Save model at {}\n".format(os.path.join(save_dir, 'models', saveName + '_epoch-' + str(epoch) + '.pth.tar')))
- 每隔 save_epoch保存一次模型,模型保存了当前的epoch,权重state_dict以及 优化器参数opt_dict
tensorboard 查看训练效果
- 安装tensorboardX包
pip install tensorboardX
- 导入
from tensorboardX import SummaryWriter
- 创建writer对象,并指定logdir路径
log_dir = 'logdir_path_to_define' # path to define
writer = SummaryWriter(log_dir=log_dir)- 将数据写入tensorboard
比如保存训练和验证过程中的,各个epoch对应的 acc和loss
if phase == 'train':
writer.add_scalar('data/train_loss_epoch', epoch_loss, epoch)
writer.add_scalar('data/train_acc_epoch', epoch_acc, epoch)
else:
writer.add_scalar('data/val_loss_epoch', epoch_loss, epoch)
writer.add_scalar('data/val_acc_epoch', epoch_acc, epoch)- 训练完成后,终端利用tensorboard查看结果
tensorboard --logdir='logdir_path_to_define' --host=localhost
这里的路径与SummaryWriter初始化,设置的logdir路经一样
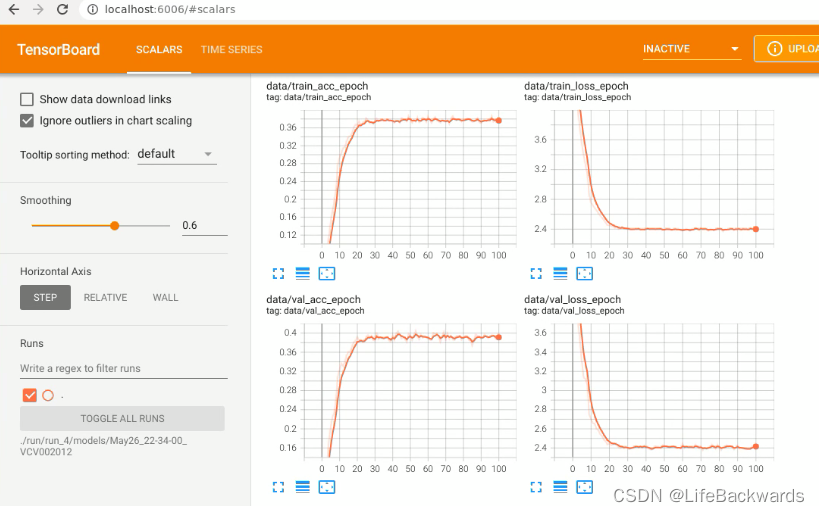
可以设置更大的epoch,提升训练效果
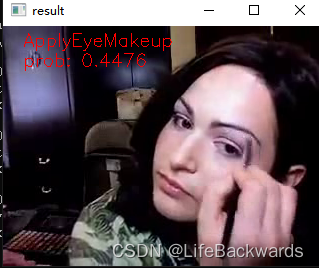
识别效果





![[学习笔记]解决因C#8.0的语言特性导致EFCore实体类型映射的错误](https://img-blog.csdnimg.cn/091446b0bf6e427992498c4b6b605b40.png)