目录
前言:
一:大体思路
二:分割成有序的小文件
(1)先给代码
(2)解析
三:进行文件归并
(1)主逻辑
(2)归并两个有序文件
四:全部代码
前言:
如果要排序的数据量非常大,内存无法容纳,我们就需要借助磁盘来进行排序了。
在之前的文章中我们介绍了归并排序,外排序就是利用了归并排序来进行排序。
注意:本文排序时生成的文件默认在项目目录下,为了方便观察,分割出的子文件放在sub目录下(使用前请检查是否有sub文件夹),大文件存储的数据格式统一为数据+换行。
归并排序链接(有兴趣可以看,不看也没影响):https://blog.csdn.net/2301_76269963/article/details/130542554?spm=1001.2014.3001.5502
一:大体思路
(1)进行文件分割
我们可以把大文件分割成很多有序的小份,一小份的数据量依据实际情况来决定。
(2)进行文件归并
将一个个有序的小文件进行归并,最后合成一个有序的大文件。
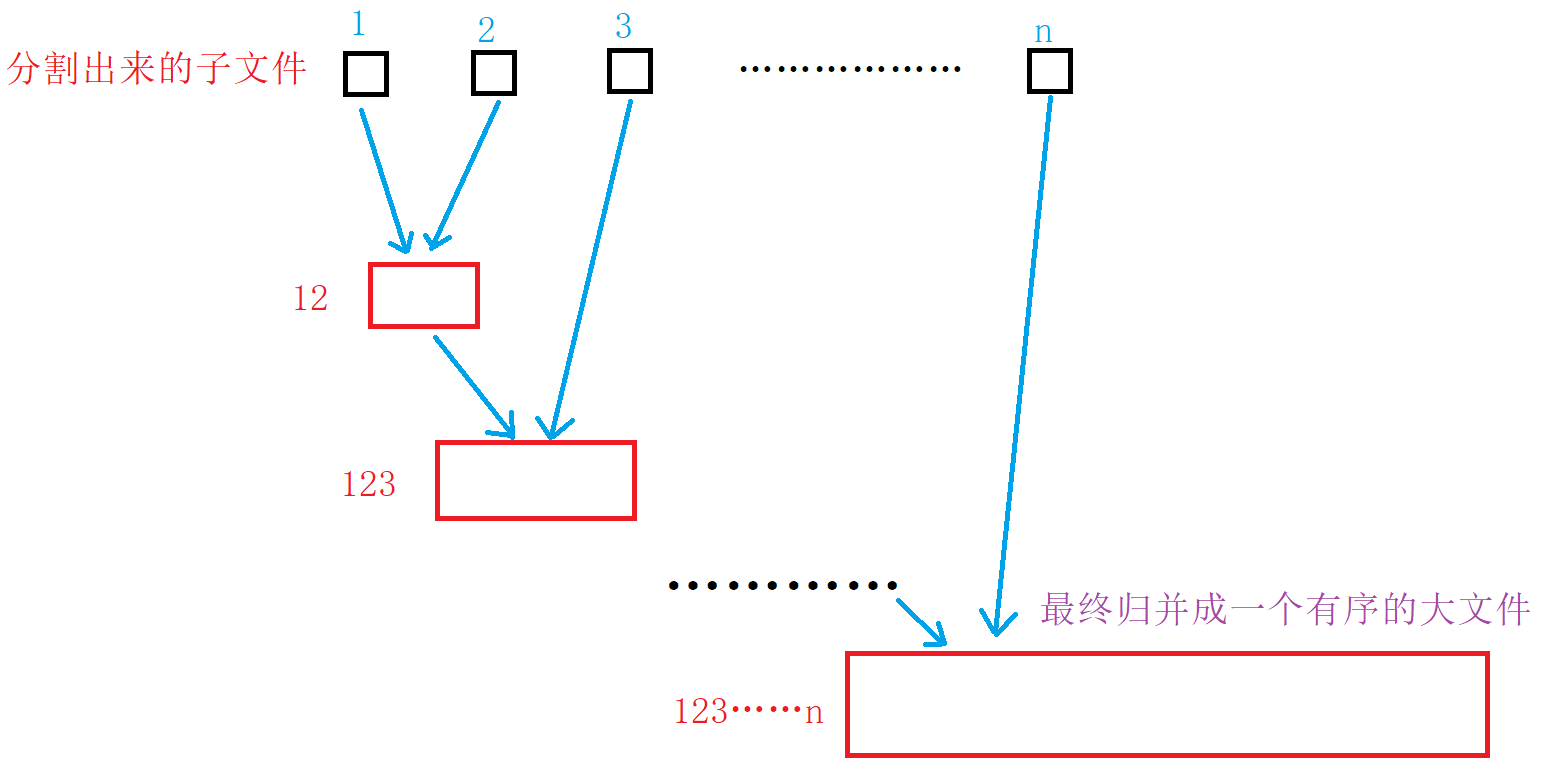
二:分割成有序的小文件
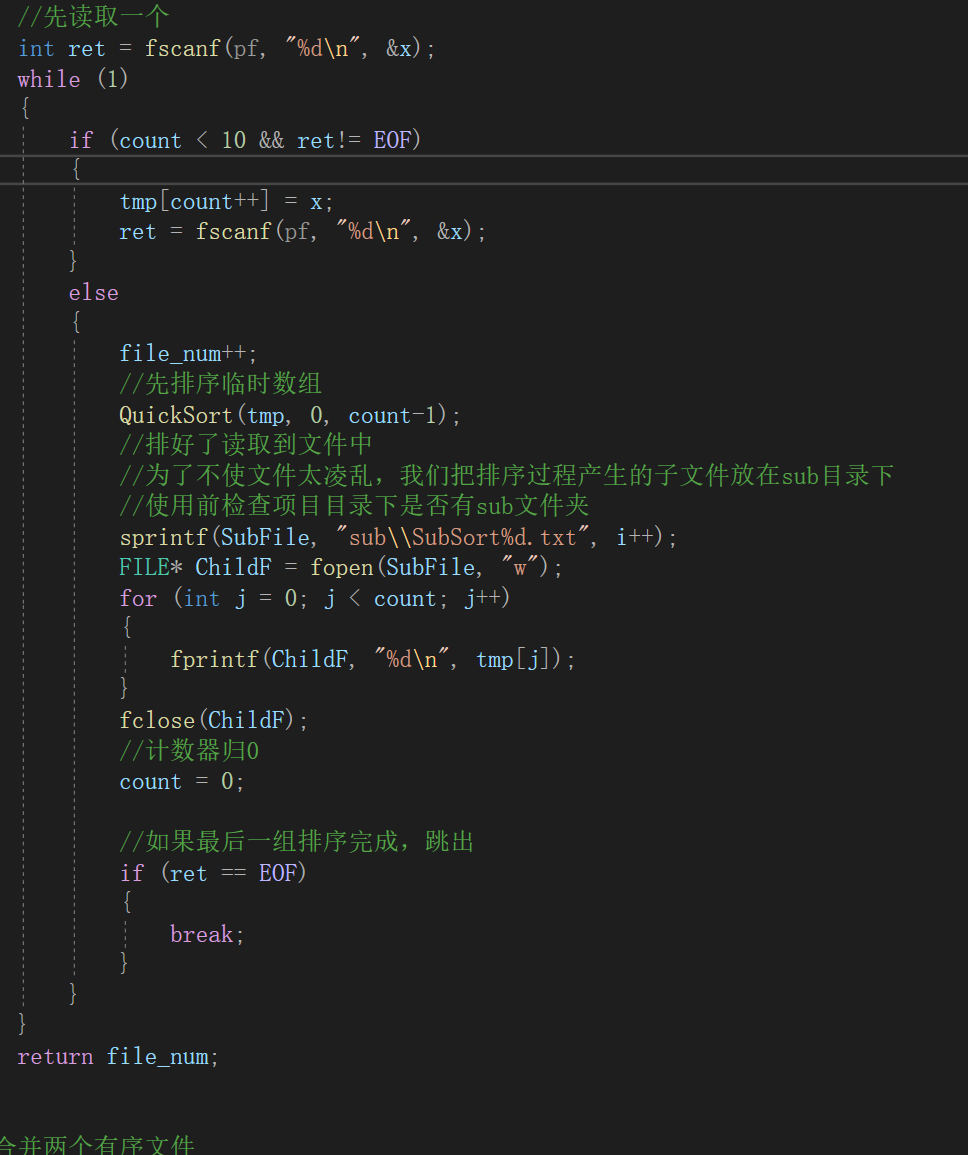
(1)先给代码
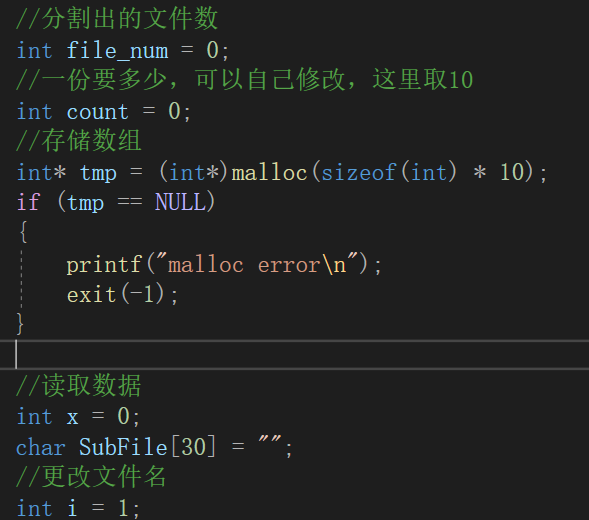
//文件分割 int FSplit(FILE* pf) { //分割出的文件数 int file_num = 0; //一份要多少,可以自己修改,这里取10 int count = 0; //存储数组 int* tmp = (int*)malloc(sizeof(int) * 10); if (tmp == NULL) { printf("malloc error\n"); exit(-1); } //读取数据 int x = 0; char SubFile[30] = ""; int i = 1; //先读取一个 int ret = fscanf(pf, "%d\n", &x); while (1) { if (count < 10 && ret!= EOF) { tmp[count++] = x; ret = fscanf(pf, "%d\n", &x); } else { file_num++; //先排序临时数组 QuickSort(tmp, 0, count-1); //排好了读取到文件中 //为了不使文件太凌乱,我们把排序过程产生的子文件放在sub目录下 //使用前检查项目目录下是否有sub文件夹 sprintf(SubFile, "sub\\SubSort%d.txt", i++); FILE* ChildF = fopen(SubFile, "w"); for (int j = 0; j < count; j++) { fprintf(ChildF, "%d\n", tmp[j]); } fclose(ChildF); //计数器归0 count = 0; //如果最后一组排序完成,跳出 if (ret == EOF) { break; } } } return file_num; }
(2)解析
①要使分割出的小文件有序,我们先用临时数组来保存读取的数据,把数组进行排序后再进行数据读入。
②file_num用来记录分割出的子文件数,x用来记录读取数据,count用来记录一份子文件的数据量。
③循环的过程中我们需要不断改变文件名来进行区分,i用来更改文件名,每次生成一个子文件就加1,SubFile用来保存子文件名。
①ret用来接收fscanf的返回值,用来判断文件是否读取到结尾
②如果文件未读取到结尾并且一份没有达到10,就把数据放在tmp数组中,然后再进行一次读取。
③如果文件读取到了结尾或者一份到达10,file_num加1,排序临时数组。
利用sprintf生成子文件名,打开子文件,将数组元素读入到子文件中,关闭文件后count置0,如果这个时候文件已经读取到结尾,就结束循环。
三:进行文件归并
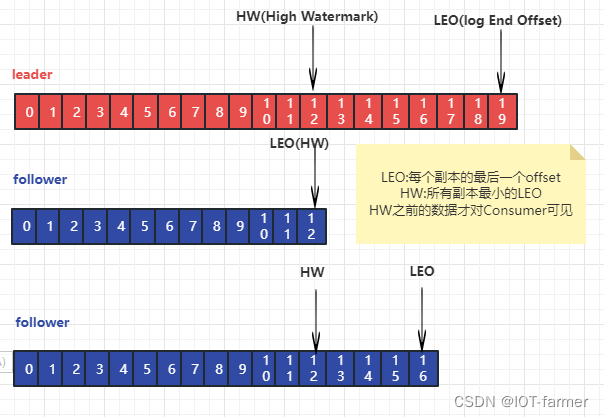
(1)主逻辑
图解:
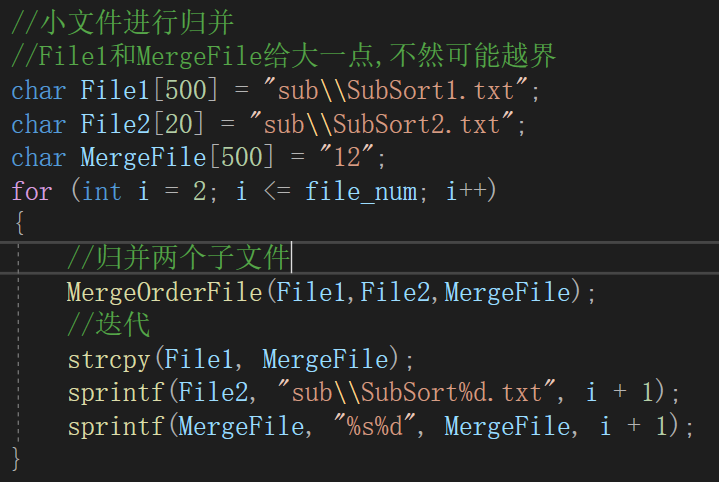

(2)归并两个有序文件
代码:
//合并两个有序文件 void MergeOrderFile(const char* f1, const char* f2, const char* m1) { //先打开文件 FILE* pf1 = fopen(f1, "r"); if (pf1 == NULL) { printf("打开文件失败\n"); exit(-1); } FILE* pf2 = fopen(f2, "r"); if (pf2 == NULL) { printf("打开文件失败\n"); exit(-1); } FILE* pm1 = fopen(m1, "w"); if (pm1 == NULL) { printf("打开文件失败\n"); exit(-1); } //归并 //记录两个文件数据 int num1 = 0; int num2 = 0; //记录两个文件读取状态 int ret1 = fscanf(pf1, "%d\n", &num1); int ret2 = fscanf(pf2, "%d\n", &num2); while (ret1 != EOF && ret2 != EOF) { if (num1 < num2) { fprintf(pm1, "%d\n", num1); ret1 = fscanf(pf1, "%d\n", &num1); } else { fprintf(pm1, "%d\n", num2); ret2 = fscanf(pf2, "%d\n", &num2); } } //把没结束的一方写入文件 while (ret1 != EOF) { fprintf(pm1, "%d\n", num1); ret1 = fscanf(pf1, "%d\n", &num1); } while (ret2 != EOF) { fprintf(pm1, "%d\n", num2); ret2 = fscanf(pf2, "%d\n", &num2); } //关闭文件 fclose(pf1); fclose(pf2); fclose(pm1); }图解:
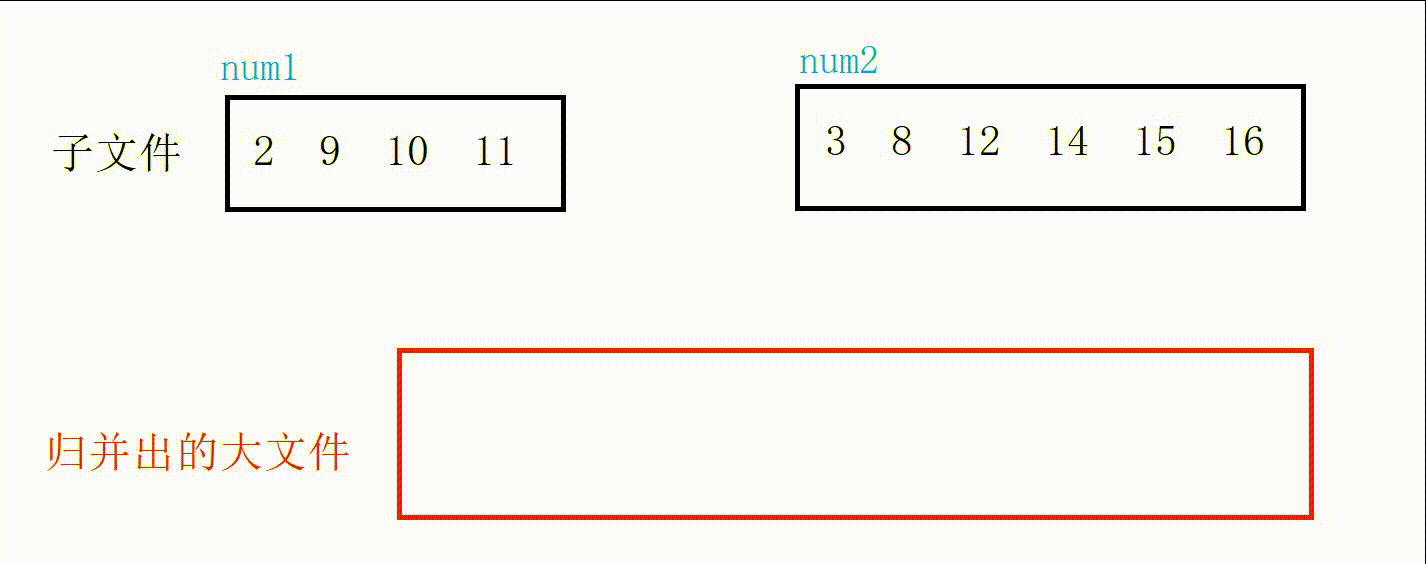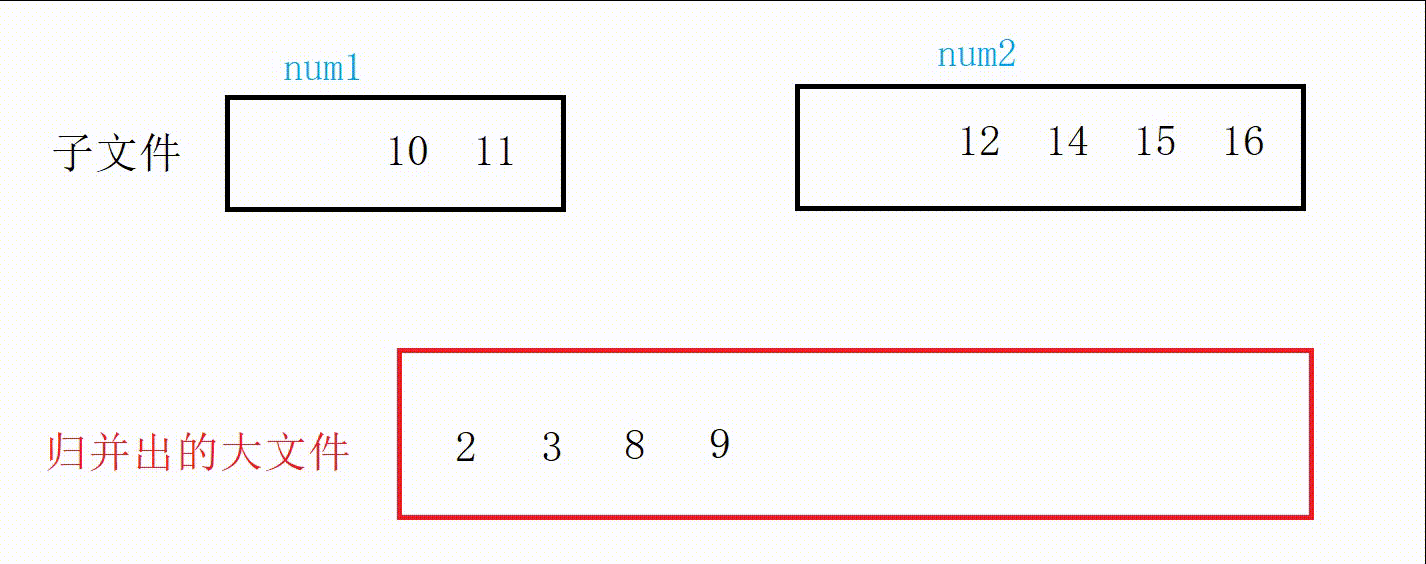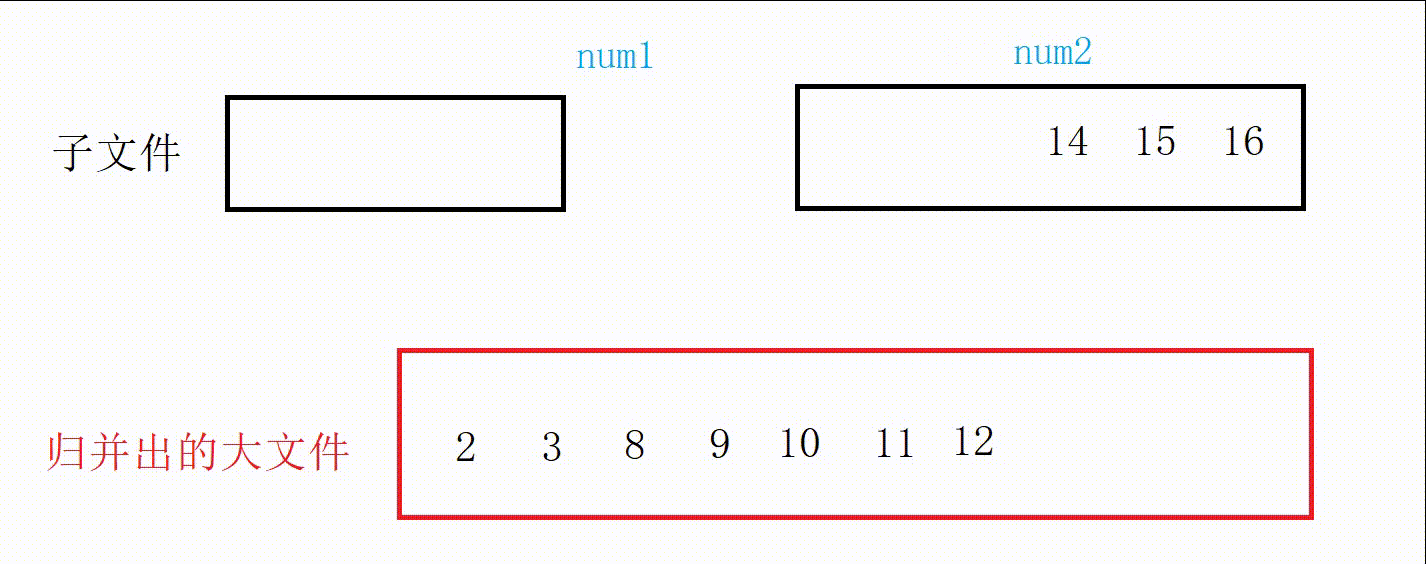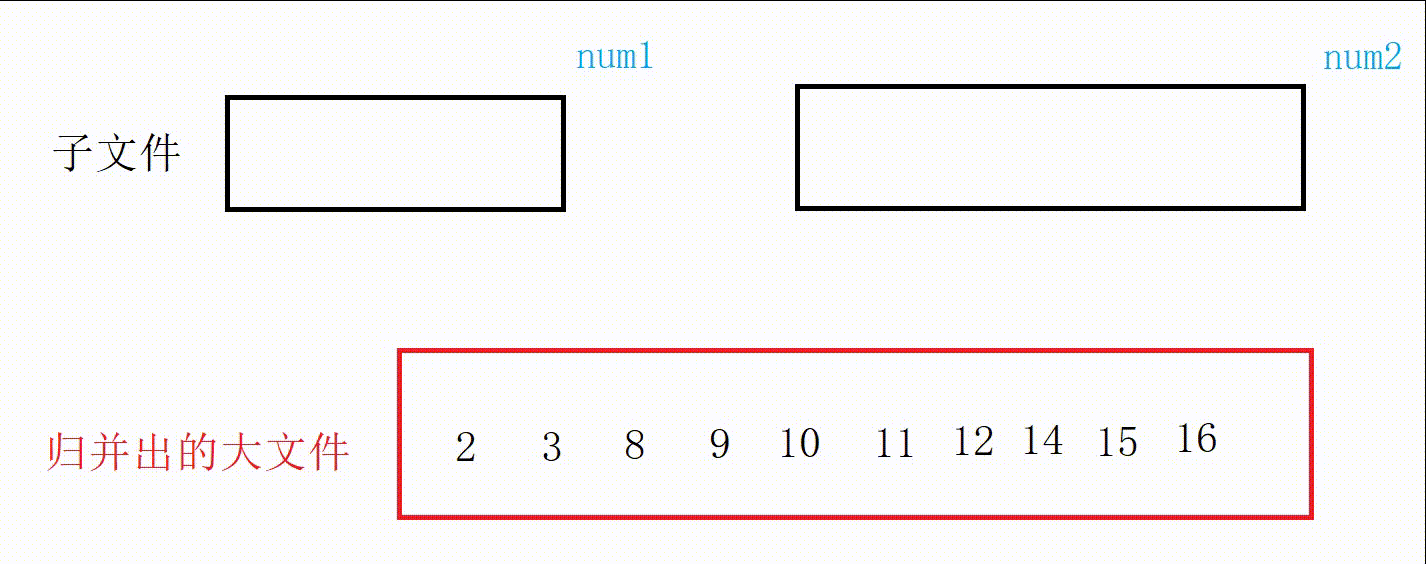
四:全部代码
// 三数取中 int GetMidIndex(int* a, int left, int right) { int midi = left + (right - left) / 2; if (a[midi] > a[right]) { if (a[midi] < a[left]) return midi; else if (a[right] > a[left]) return right; else return left; } else // a[right] > a[mid] { if (a[midi] > a[left]) return midi; else if (a[left] < a[right]) return left; else return right; } } //前后指针法 int partion3(int* a, int left, int right) { int midi = GetMidIndex(a, left, right); swap(&a[midi], &a[left]); int keyi = left; int prev = left; int cur = left + 1; while (cur <= right) { //++prev和cur相等,无效交换,不换 if (a[cur] < a[keyi] && ++prev!= cur) { swap(&a[prev], &a[cur]); } cur++; } swap(&a[keyi], &a[prev]); return prev; } //快速排序 void QuickSort(int* a, int left, int right) { //如果left>right,区间不存在 //left==right,只有一个元素,可以看成是有序的 if (left >= right) { return; } //单次排序 int keyi = partion3(a, left, right); //分成左右区间,排序左右区间 QuickSort(a, left, keyi - 1); QuickSort(a, keyi + 1, right); } //文件分割 int FSplit(FILE* pf) { //分割出的文件数 int file_num = 0; //一份要多少,可以自己修改,这里取10 int count = 0; //存储数组 int* tmp = (int*)malloc(sizeof(int) * 10); if (tmp == NULL) { printf("malloc error\n"); exit(-1); } //读取数据 int x = 0; char SubFile[30] = ""; //更改文件名 int i = 1; //先读取一个 int ret = fscanf(pf, "%d\n", &x); while (1) { if (count < 10 && ret!= EOF) { tmp[count++] = x; ret = fscanf(pf, "%d\n", &x); } else { file_num++; //先排序临时数组,这里使用快排 QuickSort(tmp, 0, count-1); //排好了读取到文件中 //为了不使文件太凌乱,我们把排序过程产生的子文件放在sub目录下 //使用前检查项目目录下是否有sub文件夹 sprintf(SubFile, "sub\\SubSort%d.txt", i++); FILE* ChildF = fopen(SubFile, "w"); for (int j = 0; j < count; j++) { fprintf(ChildF, "%d\n", tmp[j]); } fclose(ChildF); //计数器归0 count = 0; //如果最后一组排序完成,跳出 if (ret == EOF) { break; } } } return file_num; } //合并两个有序文件 void MergeOrderFile(const char* f1, const char* f2, const char* m1) { //先打开文件 FILE* pf1 = fopen(f1, "r"); if (pf1 == NULL) { printf("打开文件失败\n"); exit(-1); } FILE* pf2 = fopen(f2, "r"); if (pf2 == NULL) { printf("打开文件失败\n"); exit(-1); } FILE* pm1 = fopen(m1, "w"); if (pm1 == NULL) { printf("打开文件失败\n"); exit(-1); } //归并 //记录两个文件数据 int num1 = 0; int num2 = 0; //记录两个文件读取状态 int ret1 = fscanf(pf1, "%d\n", &num1); int ret2 = fscanf(pf2, "%d\n", &num2); while (ret1 != EOF && ret2 != EOF) { if (num1 < num2) { fprintf(pm1, "%d\n", num1); ret1 = fscanf(pf1, "%d\n", &num1); } else { fprintf(pm1, "%d\n", num2); ret2 = fscanf(pf2, "%d\n", &num2); } } //把没结束的一方写入文件 while (ret1 != EOF) { fprintf(pm1, "%d\n", num1); ret1 = fscanf(pf1, "%d\n", &num1); } while (ret2 != EOF) { fprintf(pm1, "%d\n", num2); ret2 = fscanf(pf2, "%d\n", &num2); } //关闭文件 fclose(pf1); fclose(pf2); fclose(pm1); } //文件排序 void MergeSortFile(const char* ParentFile) { //先打开父文件 FILE* pf = fopen(ParentFile, "r"); if (pf == NULL) { printf("打开文件失败\n"); return; } //分割成小文件 int file_num = FSplit(pf); fclose(pf); //小文件进行归并 //File1和MergeFile给大一点,不然可能越界 char File1[500] = "sub\\SubSort1.txt"; char File2[20] = "sub\\SubSort2.txt"; char MergeFile[500] = "12"; for (int i = 2; i <= file_num; i++) { //归并两个子文件 MergeOrderFile(File1,File2,MergeFile); //迭代 strcpy(File1, MergeFile); sprintf(File2, "sub\\SubSort%d.txt", i + 1); sprintf(MergeFile, "%s%d", MergeFile, i + 1); } }实际演示
待排序文件为sort.txt,sub文件夹放子文件