假设你想建立一个垃圾邮件分类器,通过监督学习来构造一个分类器来区分垃圾邮件和非垃圾邮件。为了应用监督学习,首先要想的就是:如何来表示邮件的特征向量x,通过特征向量x和分类标签y,我们就能训练一个分类器,比如使用逻辑回归的方法。这里有一种选择邮件的特征向量的方法:我们可以提出一个可能包含100个单词的列表,通过这些单词来区分垃圾邮件或非垃圾邮件。
7.1 误差分析
误差分析能帮助你更系统地在众多方法中做出选择。
如果你准备从事研发机器学习产品或开发机器学习应用。
- 通常来说,最好的方法不是建立一个很复杂的有许多复杂特征的系统,而是通过一个简单的算法来快速地实现它。
- 在1结束之后,就可以画出相应学习曲线,通过学习曲线以及检验误差来找出你的算法是否存在高偏差或者高方差的问题或者一些其他问题。在这些分析之后,再来决定是否使用更多的数据或者特征等等。
- 误差分析:当实现比如一个垃圾邮件分类器的时候,可以经常观察交叉验证集的情况,然后看一看那些被算法错误分类的文件,通过查看这些被错误分类的垃圾邮件和非垃圾邮件,看看这些经常被错误分类的邮件有什么共同特征和规律。经常做这个过程就会启发你应该设计怎样的新特征或是告诉你现在的系统有什么优点和缺点。
假设你在做一个垃圾邮件分类器,然后在你的交叉验证集中有500个样本,假如该例子中算法有很高的错误率,它错误分类了100个交叉验证样本。于是现在需要做的就是,手动核查这100个错误,然后手工为他们分类。同时要考虑清楚这些邮件是什么类型的邮件,有什么线索或者特征你觉得能帮助算法正确地进行分类。最后在改进学习算法时,另一个技巧是保证自己对学习算法有一种数值估计的方法。当改进算法的时候,如果你的算法能够返回一个数值评价指标来估计算法执行的效果,将会很有帮助。
例子:假如我们正在决定是否应该将discount disounts discounter discounting视为同一个单词,这样做的一种方法就是只看单词中的前几个英文字母。如果只看这些单词,就会发现这些单词大体上有着相似的意思。在自然语言处理中,就有这种方法叫做词干提取软件,porter stemmer,但这种方法有利也有弊,要看自己怎么选择。如果选择了这种方法,那么数值估计对这种方法的误差分析很有用。
7.2 不对称性分类的误差评估
有一个问题:使用一个合适的误差度量值,有时会对于你的学习算法造成非常微妙的影响,这就是偏斜类的问题。
假如说你有一个算法,它的精确度是99.2%,因此它只有0.8%的误差。然后你对你的算法做出了一点改动,现在是99.5%的精确度,0.5%误差。那我们的改动是有效的还是一个只输出y=1的函数都比你的模型准确?这里就引入了查准率和召回率。
假设我们正在用测试集来评估一个分类模型,对于每个测试中的样本都会等于0或1,我们的学习算法要做的就是做出值的预测并且学习算法会为每一个测试集中的实例做出预测,预测值也是等于0或1。

- 查准率:预测得所有正例中实际是正例得比重
- 召回率(查全率):实际真正例中预测正确的正例的比重
(Precision(查准率):预测为1中真正为1的概率;Recall(召回率):真正为1中预测为1的概率)
在有些时候,我们需要保证查准率和召回率的相对平衡,并且学习它们作为算法评估度量值的更有效的方式。(为什么逻辑回归有个0.5, 原来是先逻辑回归有个hx概率结果,再进行人为划分类。)

7.3 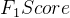
通常如果阈值设置的比较高,那么对应的查准率高、召回率低;相反如果阈值设置的低,那么查准率低、召回率高。这么看来threshold也就是临界值比较重要,那有没有办法自动选取临界值?或者更广泛地说,如果我们有不同的算法或者不同的想法,我们如何比较不同的查准率和召回率?
这里使用的,即调和平均数(倒数的平均数)来衡量。

会比较照顾数值小的一方,如果PR都为0,
=0;如果PR都为1,
=1。
7.4 机器学习数据
这节讲的重点是数据和特征的关系,例如,你就算找一个房地产经纪人,只给他房子有多大,他也无法准确给出价格,所以学习算法也没有办法给出准确的价格。
- 对数据的要求:要包含足够多的特征,不然白搭;
- 对算法的要求:要包含足够的参数。