分析方法只讲了amuda定理
Hello的一生
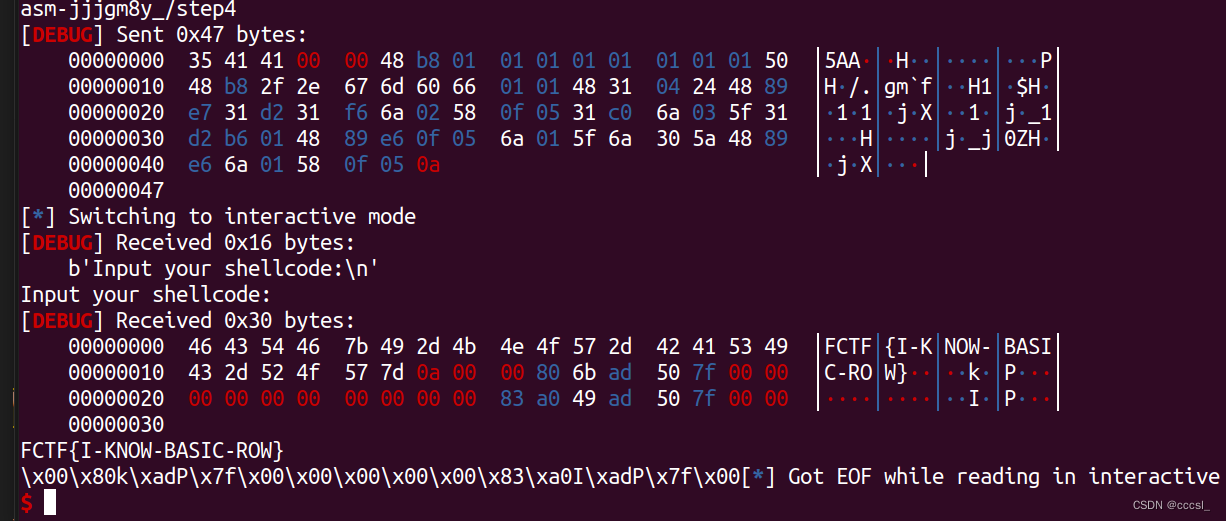
hello的执行过程
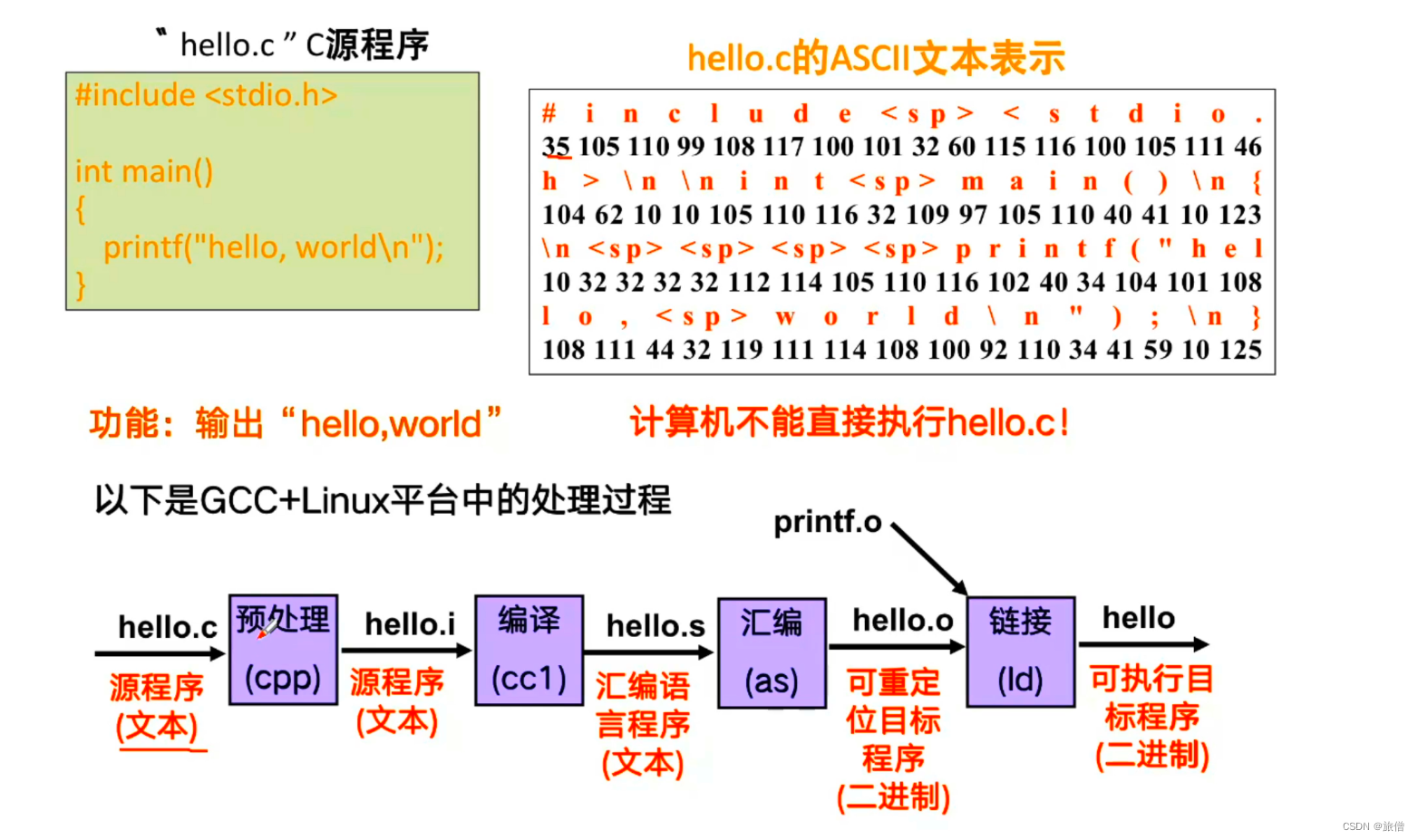
- 了解hello的执行过程 和响应的汇编器
- 生成的可执行文件是.out不是.exe

gcc -E hello.c -o hello.i//预处理 cpp hello.c>hello.i
gcc -S hello.i -o hello.s//编译
gcc -C hello.s -o hello.o//汇编 二进制文件看不到
objdump -S -d >hello.txt//反汇编
抽象
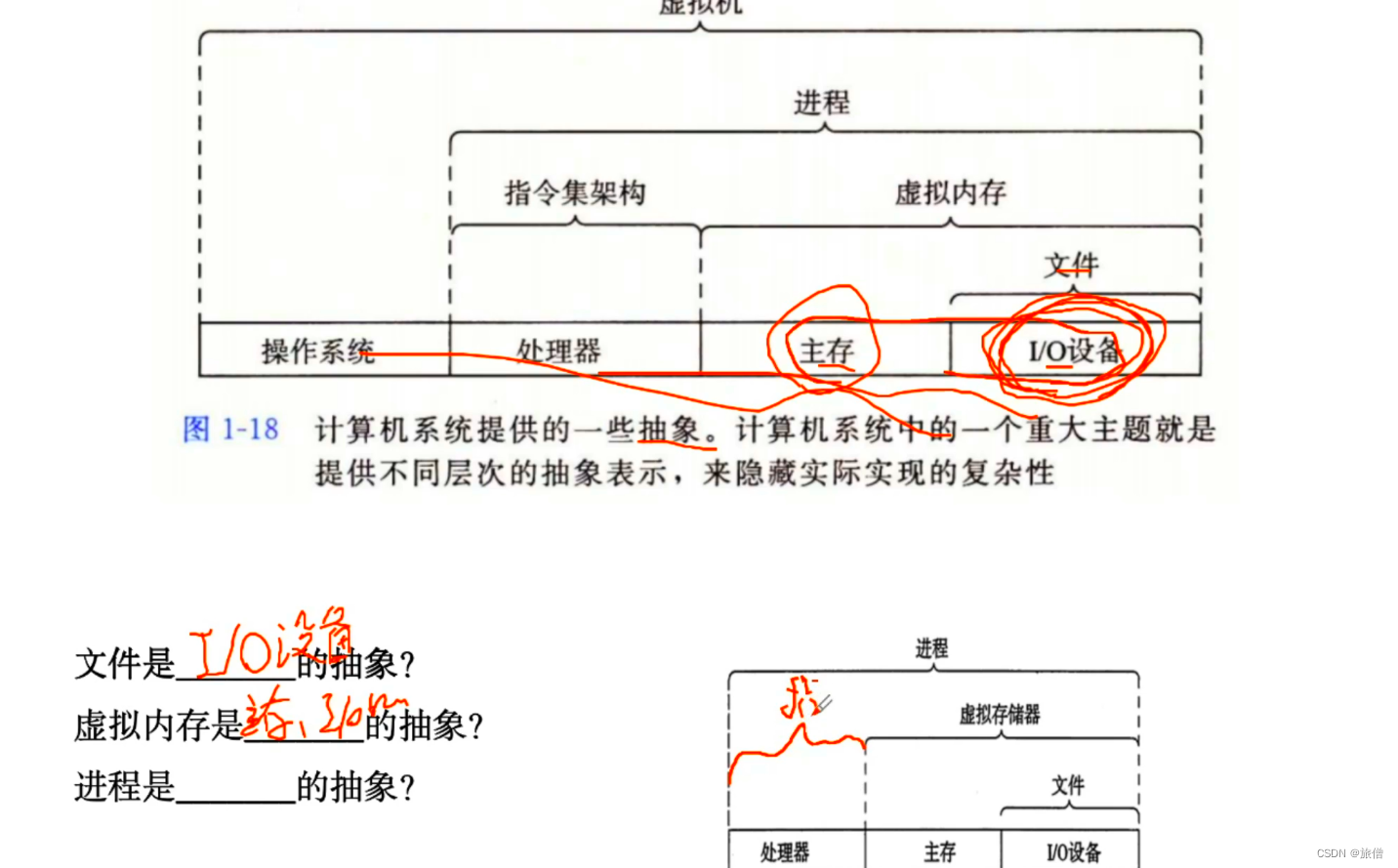
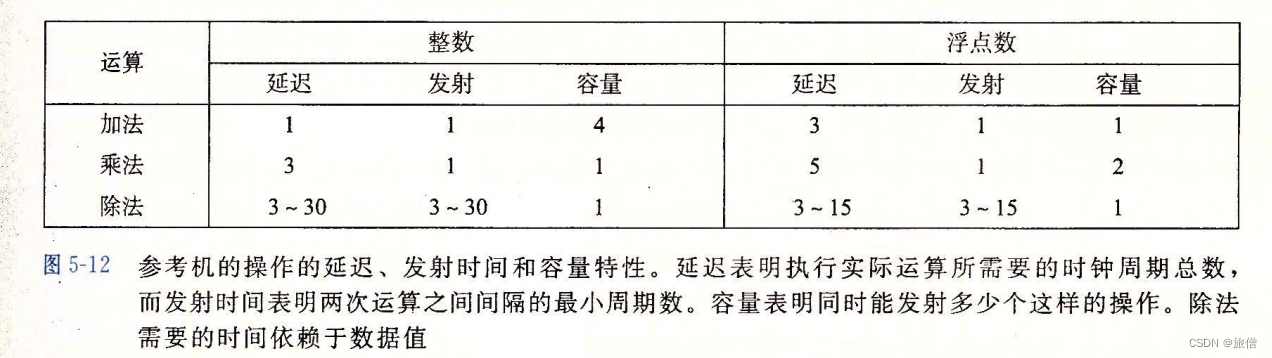
评价系统的性能和方法
几种常见的运算:
一元和二元运算

不同的浮点数 规格化的方式不同:


单精度浮点数的分类:
exclusive or手动置0

CH3
常见的寄存器

补充 RIP/pc/ip是一个意思
程序员可见状态 PC 条件码寄存器 通用寄存器
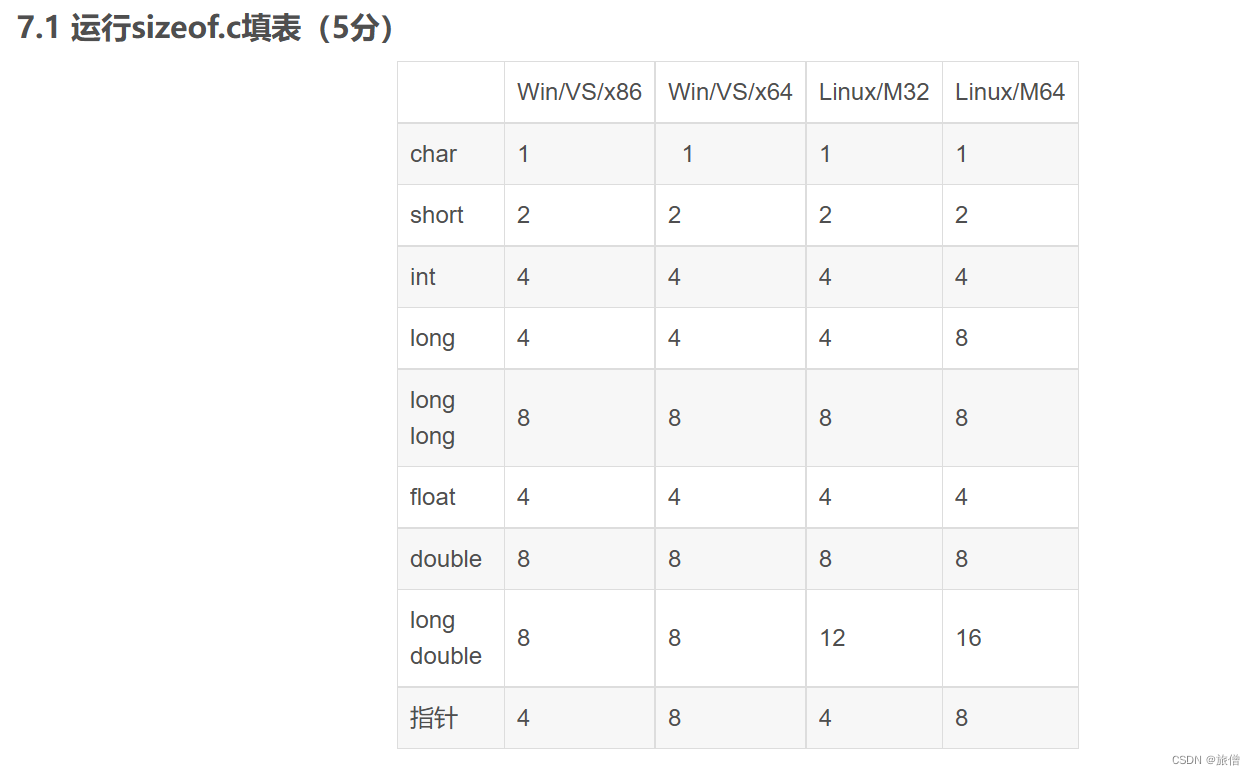
教材120页 64位是寄存器传参 32位是栈来传参
函数参数是保存在寄存器中(64位) 局部变量是保存在栈中 函数的全局变量是保存在ELF中 对于函数的局部变量如果寄存器不够的话 可以将他存放在堆栈中,

常见的汇编指令。
有的时候会直接考察汇编指令的格式 因为32位系统不能用寄存器寻址 第三个是错误的。第二个例4是错误的因为两个操作数都不能是内存。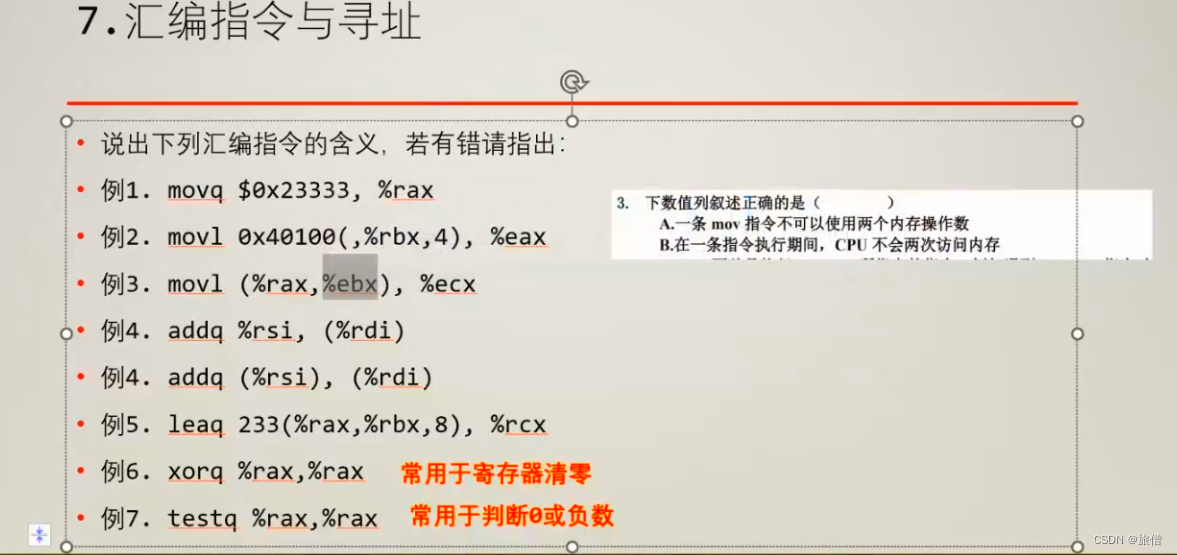
只有在寄存器中参加运算的才能修改标志位。
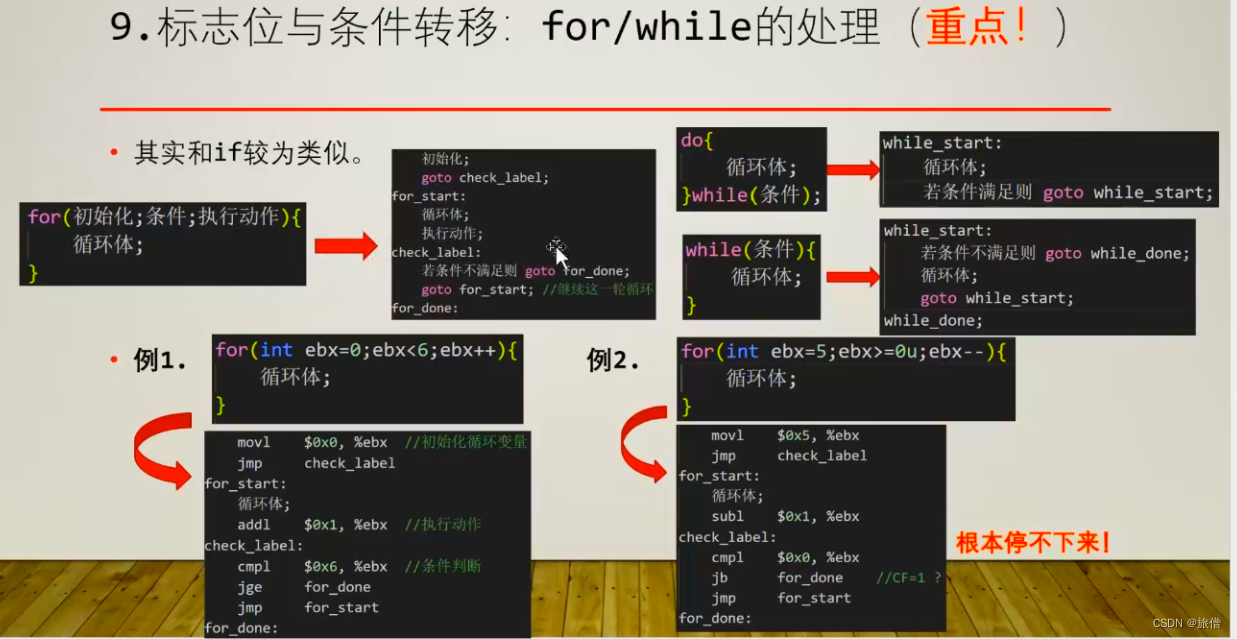
通过标志位进行程序的跳转。

对于无符号意义上的整数也可以采用借位的方式来进行。
 CPU只是机械的做二进制 减法 机器对是否是二进制没有察觉 取决于编译器选择正确的指令 编译器 会将数据转换成二进制编码 如果操作类型不一致 都转换成无符号数再操作,数组操作完成之后 编译器会根据不同的操作数类型选择不同的判断条件 然后进行跳转。
CPU只是机械的做二进制 减法 机器对是否是二进制没有察觉 取决于编译器选择正确的指令 编译器 会将数据转换成二进制编码 如果操作类型不一致 都转换成无符号数再操作,数组操作完成之后 编译器会根据不同的操作数类型选择不同的判断条件 然后进行跳转。

if的条件判断: 如果是写汇编代码的话 先要判断是有符号数还是无符号数。

考试的时候会画栈帧:

近几年没看到有switch的题 练一下手:

五、系统分析题(20分)
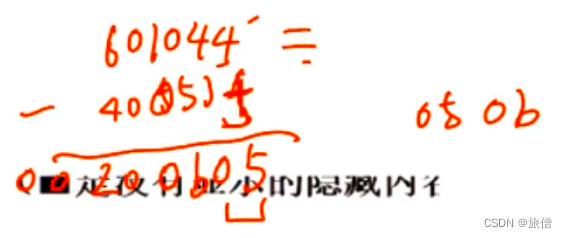
学会结果是负数的减法。

PC存放的是下条指令 PC+X = 40004E7根据下条指令显示 还要注意 补码在机器中表示是大端存储。第二个空考察数组寻址 第一个#后边的东西表示数组寻址 [rip]+偏移

但是这个减法不是下一个的减法 而是40053f

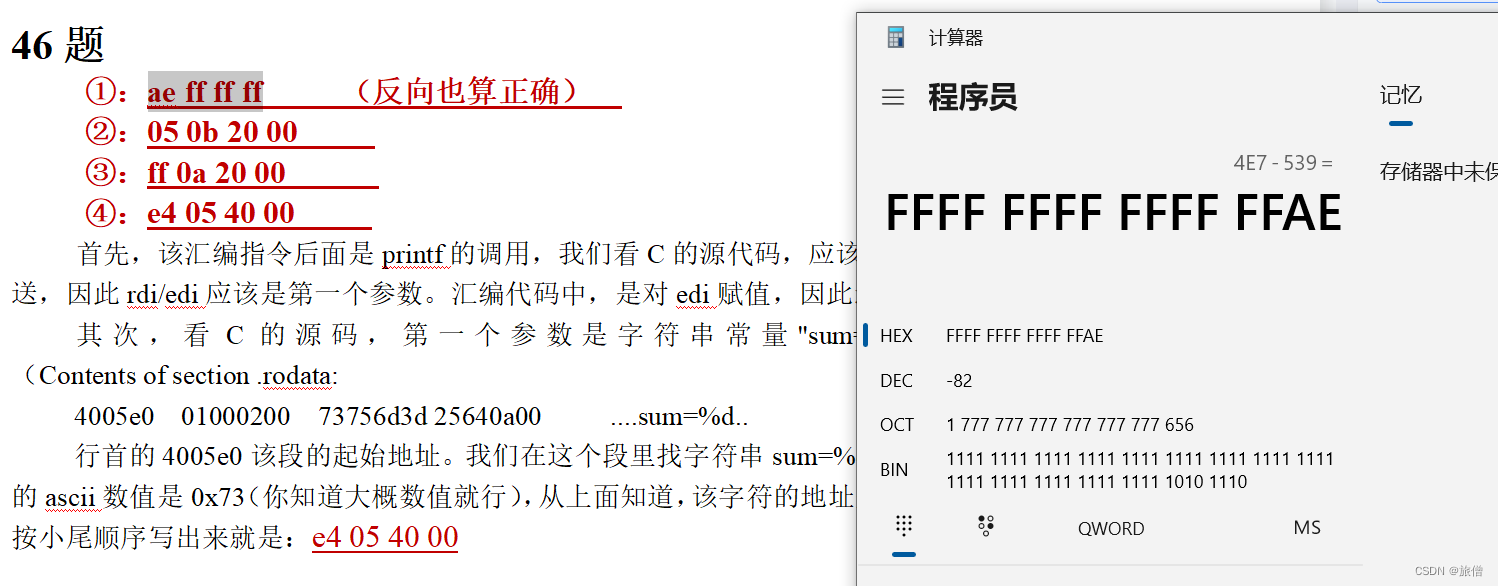 同理 第五个
同理 第五个

(1条消息) 数组指针和指针数组_mick_hu的博客-CSDN博客

argv存储的是一个指针 所以前面那个3143就是argv0 指向的空间 首先了解指针数组和数组指针 argv[0] 存储的是可执行目标文件名。char 一般是0结尾 0的acii是30那么1就是0x31同理...所以 是1C 同理可以得出其他两个参数的地址。

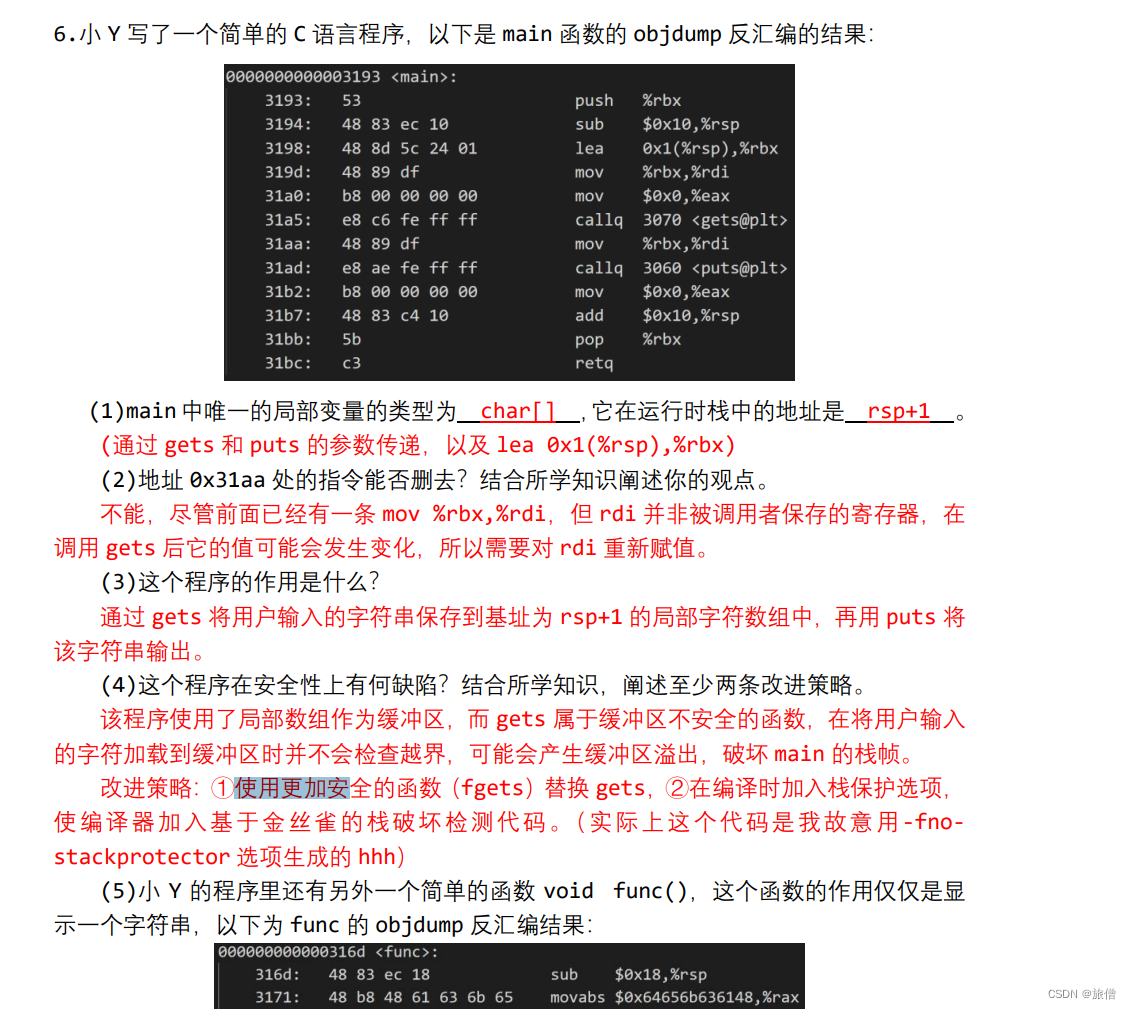

两个C语言程序main.c、test.c如下所示:
| /* main.c */ #include <stdio.h> int a[4]={-1,-2,2, 3}; extern int val; int sum(); int main(int argc, char * argv[] ) { val=sum(); printf("sum=%d\n",val); } | /* test.c */ extern int a[]; int val=0; int sum() { int i; for (i=0; i<4; i++) val += a[i]; return val; } |
CH5程序的优化
四种有用的优化:


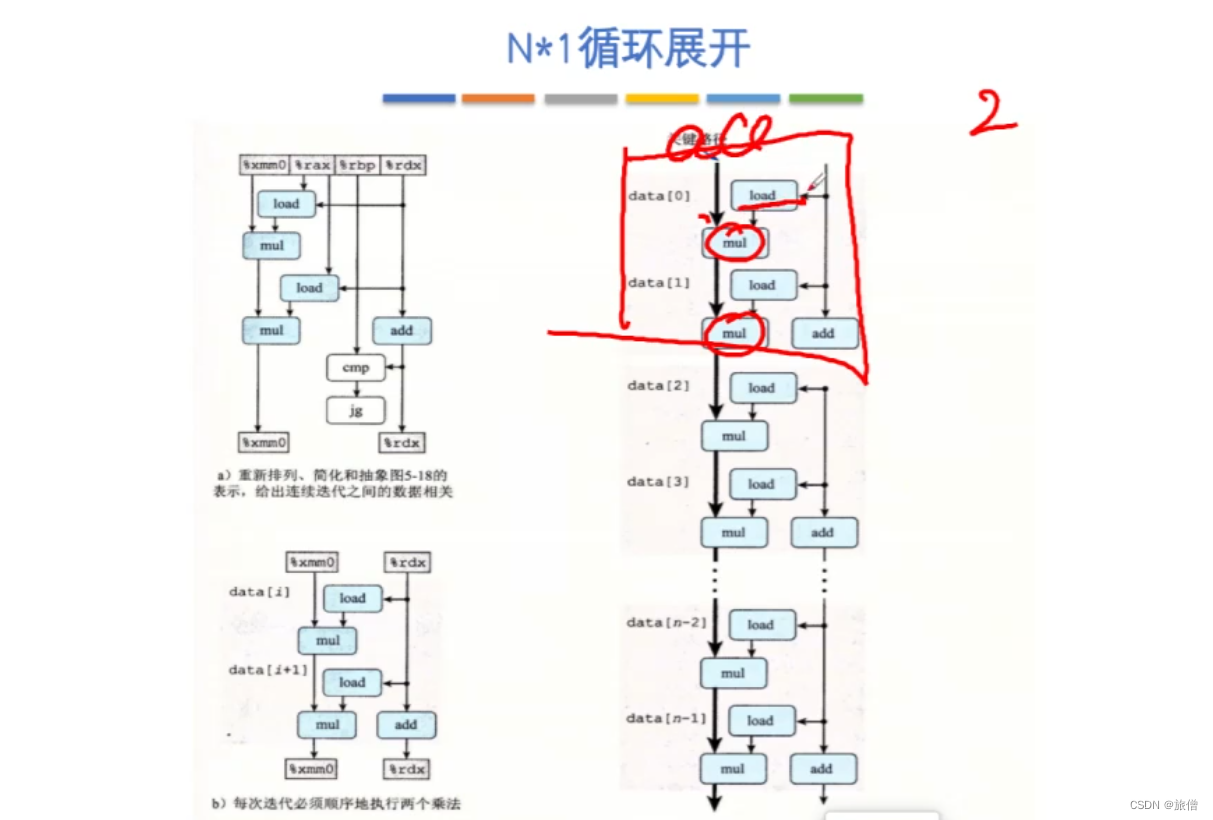
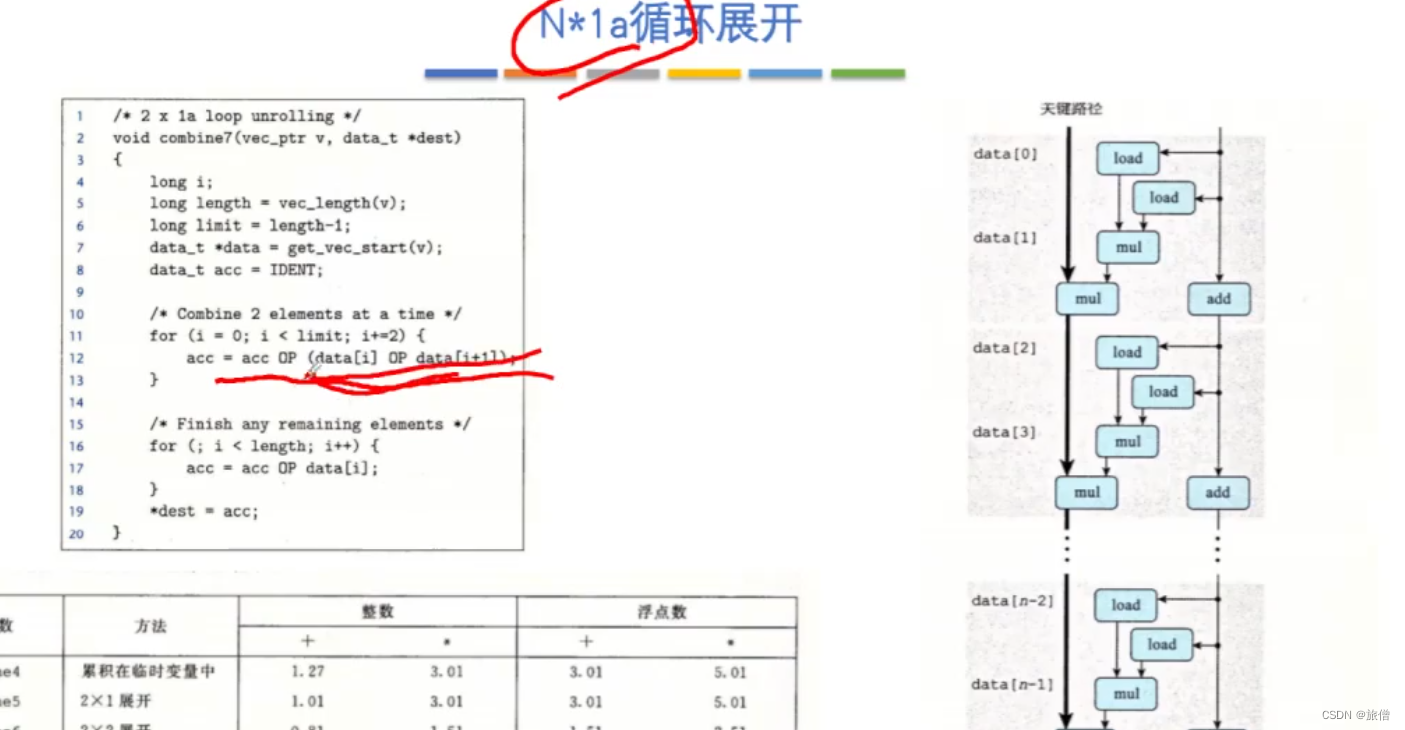
N*1展开不能从根本上改变程序运行速度的原因:数据相关性太大,虽然循环的次数减少了一半但是循环的时间每次增加了一倍。
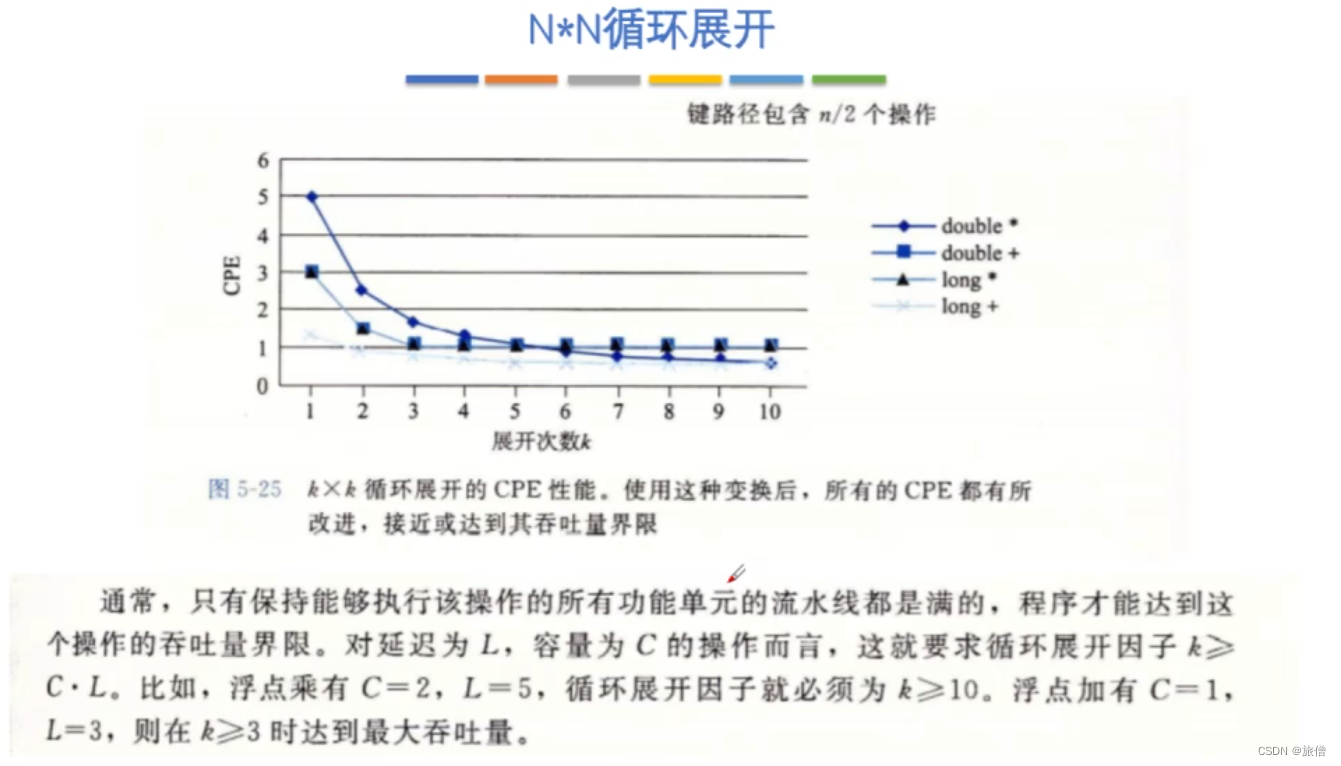
N*N循环展开 ,
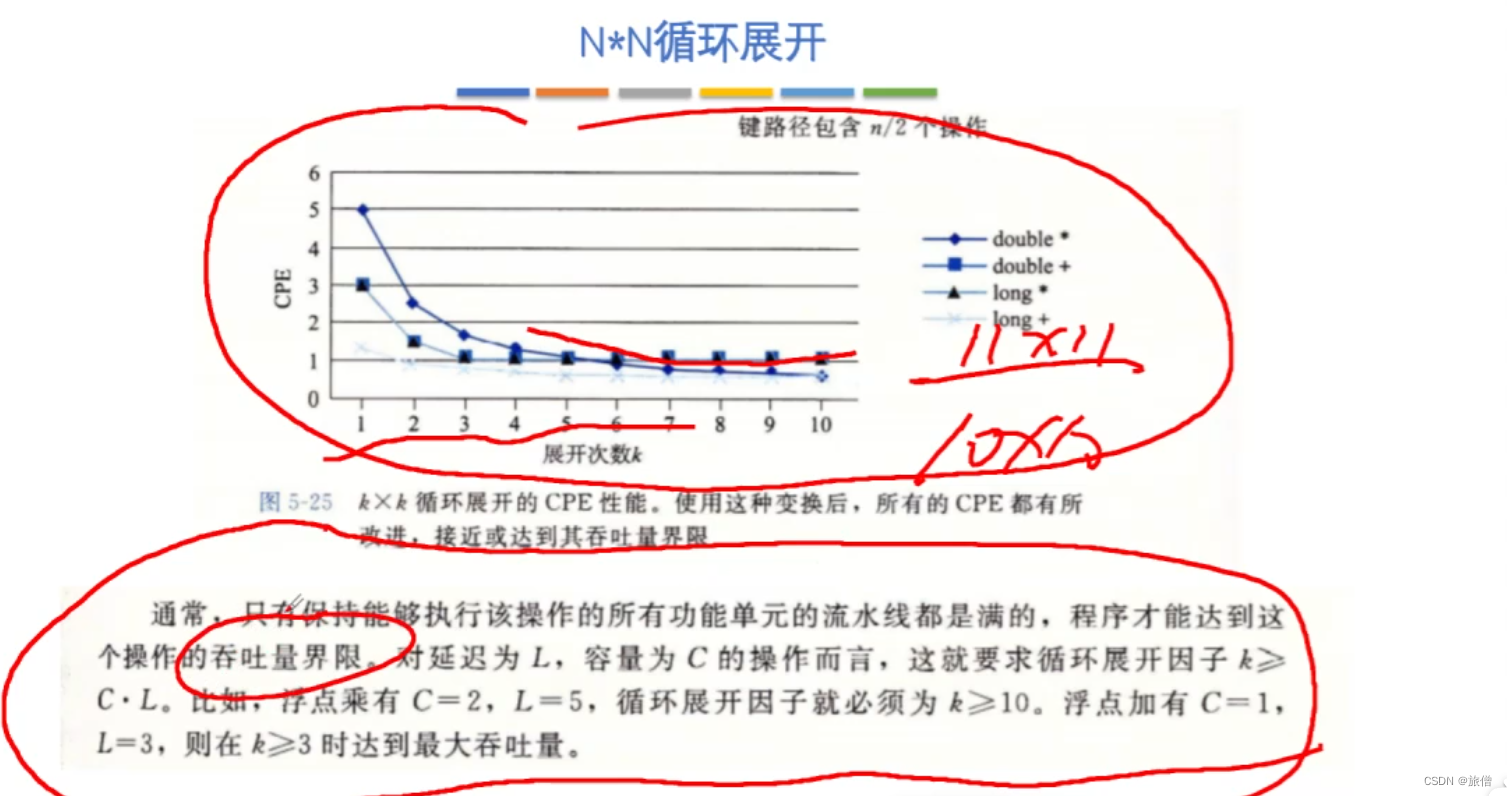
如何让功能达到最优 达到吞吐量界限 思考怎么计算机吞吐量界限


 A n 2n
A n 2n
B必须等到上次乘法结束完之后 才能进行一个乘法 效率很低
优化方法:减少函数调用 减少内存引用 消除不必要的循环

面向CPU的优化
衡量参数:

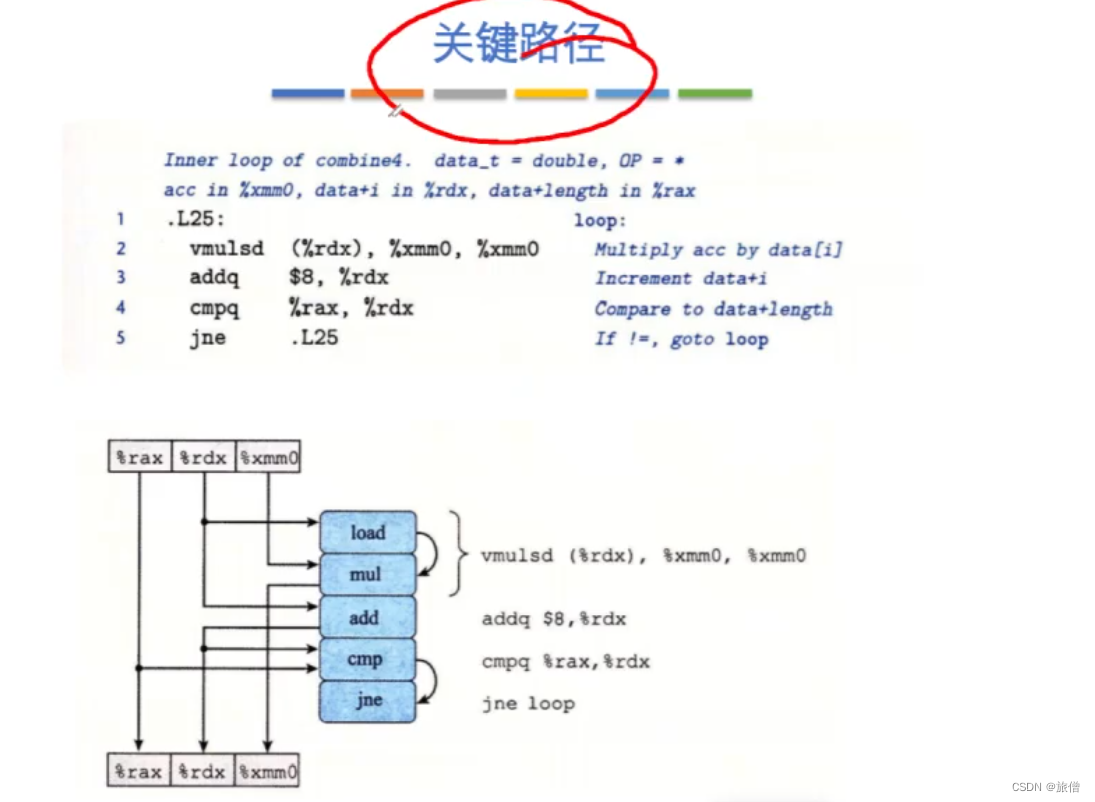
理解关键路径:


 循环展开的顺序也是一个考点:
循环展开的顺序也是一个考点:

找出关键路径:


- 一般有用的优化 复杂指令集的简化 共享公共子表达式

- 面向编译器的优化:用局部变量
- 面向标量CPU优化:带分离的累加器的循环展开。通过比较不同展开因子L时的最小CPE,从而确定最优的L展开因子。
- 面向向量CPU优化:采用vaddpd及YMMi寄存器编程
- 面向Cache优化:
空间局部性:重新排列(局部变量、循环变量顺序重排)提高空间局部性
时间局部性:分块,考虑到Cache 32K。
CH6
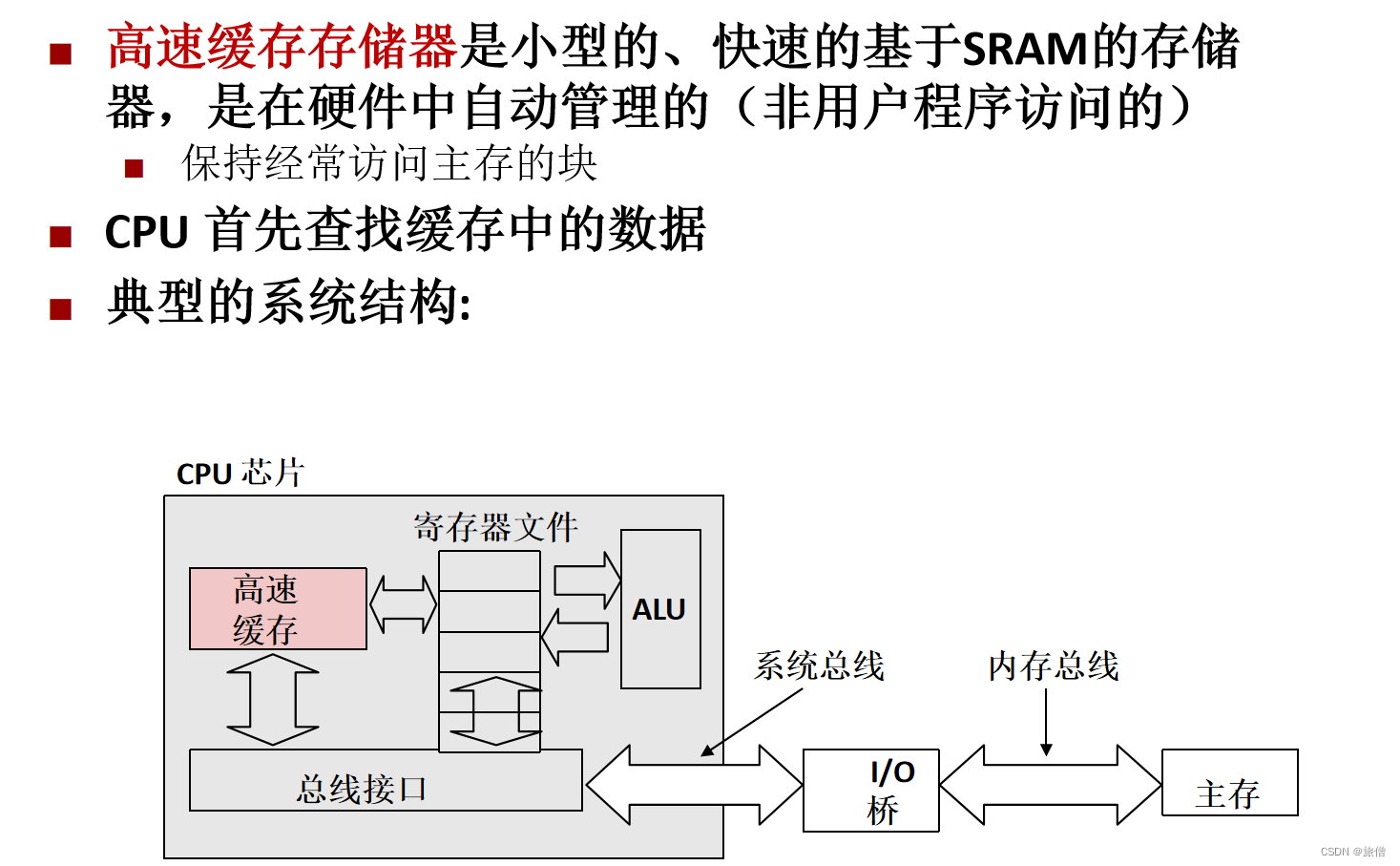
源程序 执行程序 空间代码都要存在外存上,程序运行的时候操作系统要把外存的东西加载到内存里,CPU要从内存一行一行的读、译码和分析
我们来看一个例子:

指令位于内存中的代码段中,必须从内存中读出来进行译码分析之后才能运行
指令必须从内存中读出经过CPU的译码器 才能翻译成机器语言
关于存储器的一些基本术语:

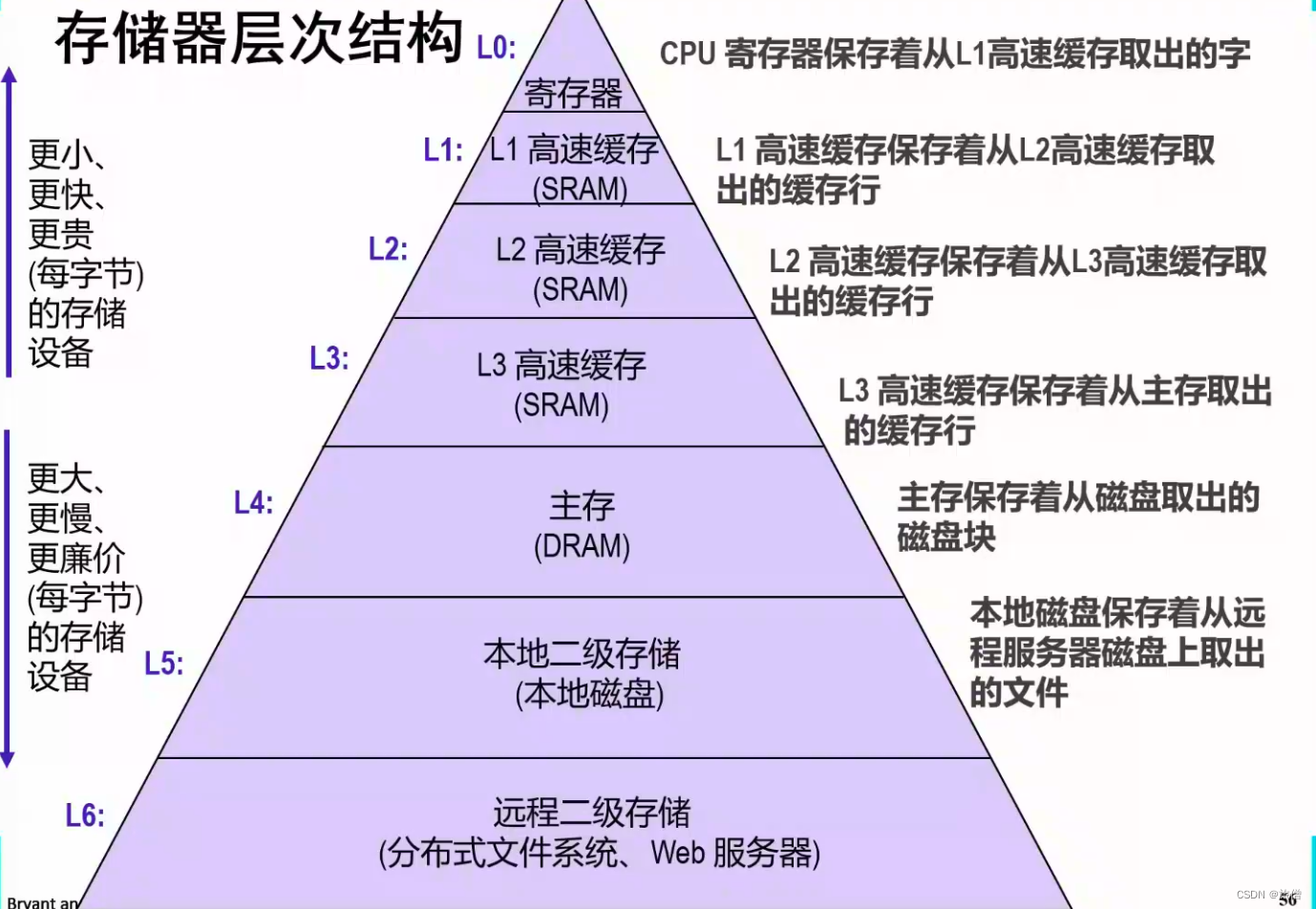
如果上一级不命中回到下一级来寻找:
不命中的分类:

首先要理解局部性原理 为啥层次结构行得通 因为局部性原理访问第K层的数据要比访问第K+1层的数据要频繁。cache是由硬件自动完成的。
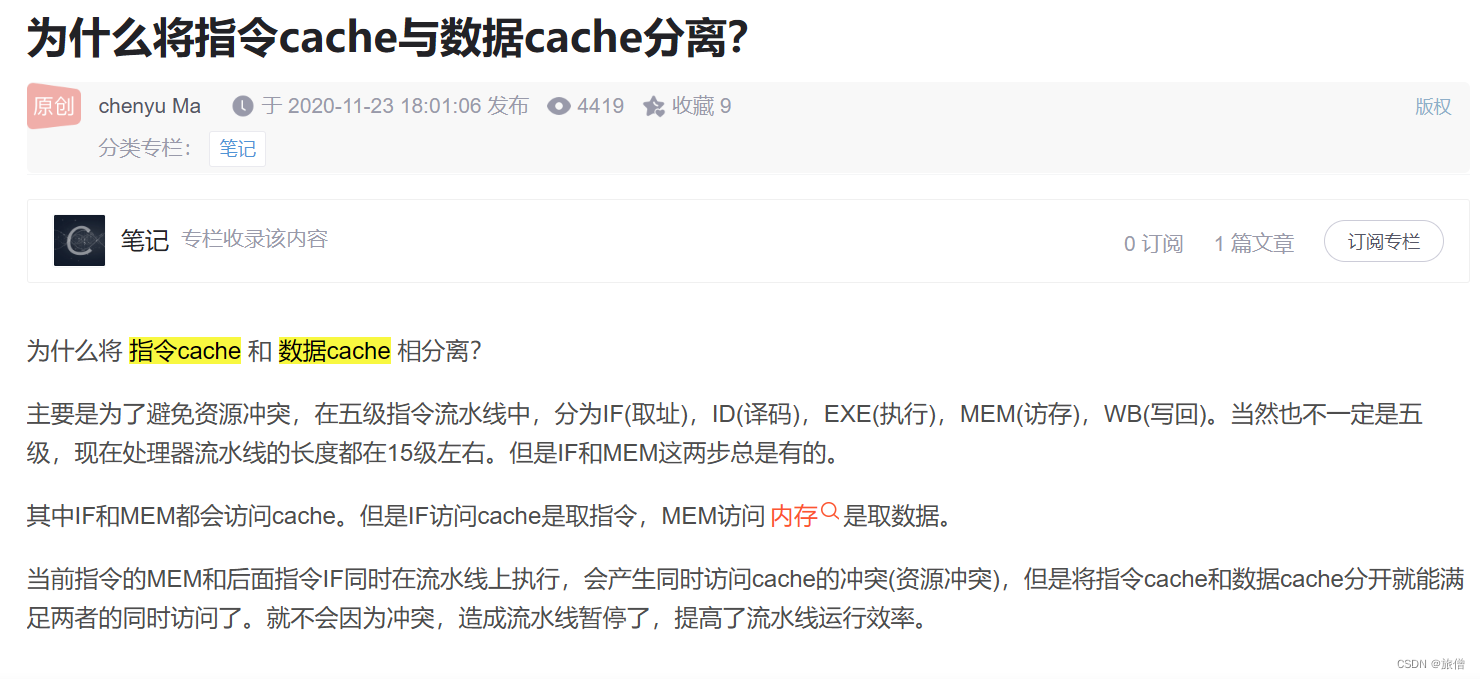
为啥要把指令和数据cache分开 为了避免资源的冲突 这个是一个很重要的东西 计组也考了(但是我错了)
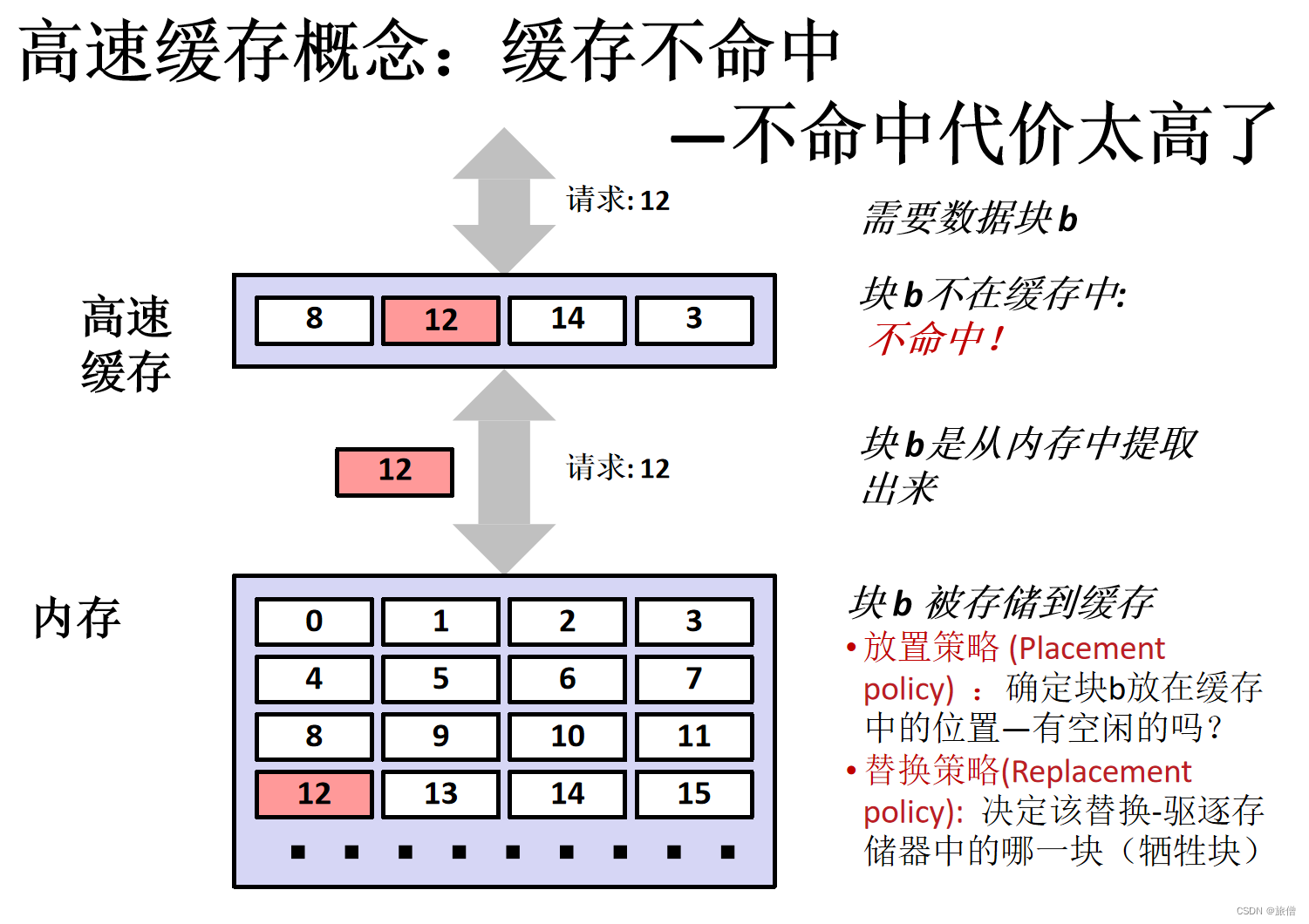
一位不命中的代价太高了 所以cache采用按块求取的方式,读取8不命中 然后就到下方的内存中找数据。
查找方式:
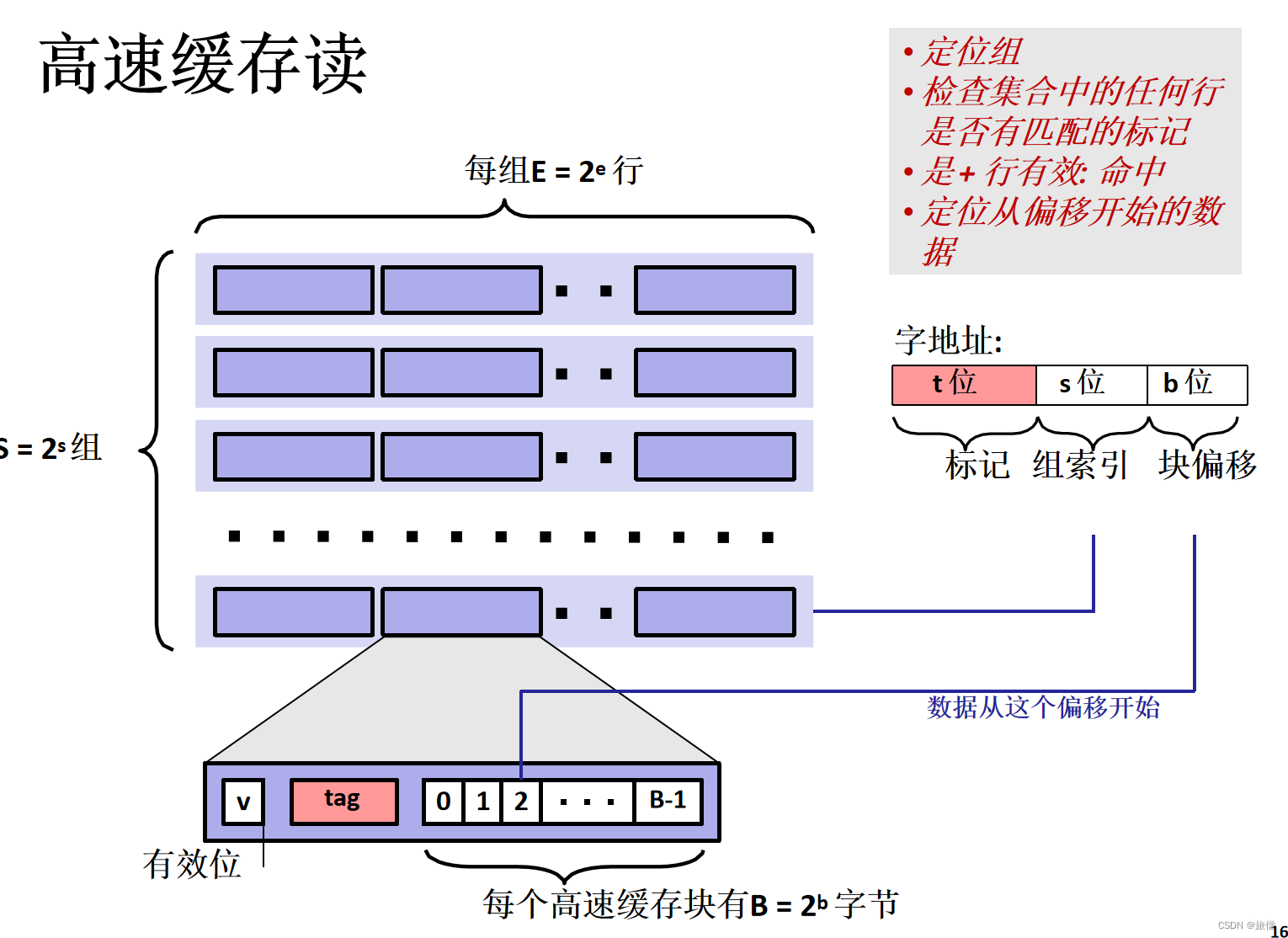
比如这一条语句:
movl n(rip), %eax传地址 然后由硬件自动将地址进行切割,找到组 然后逐路进行查找 先看有效位valid是不是1,然后再看 再比较字地址的标记位和块的tag位是不是相等。b决定从第几个字节开始读 movl决定读几个字节。
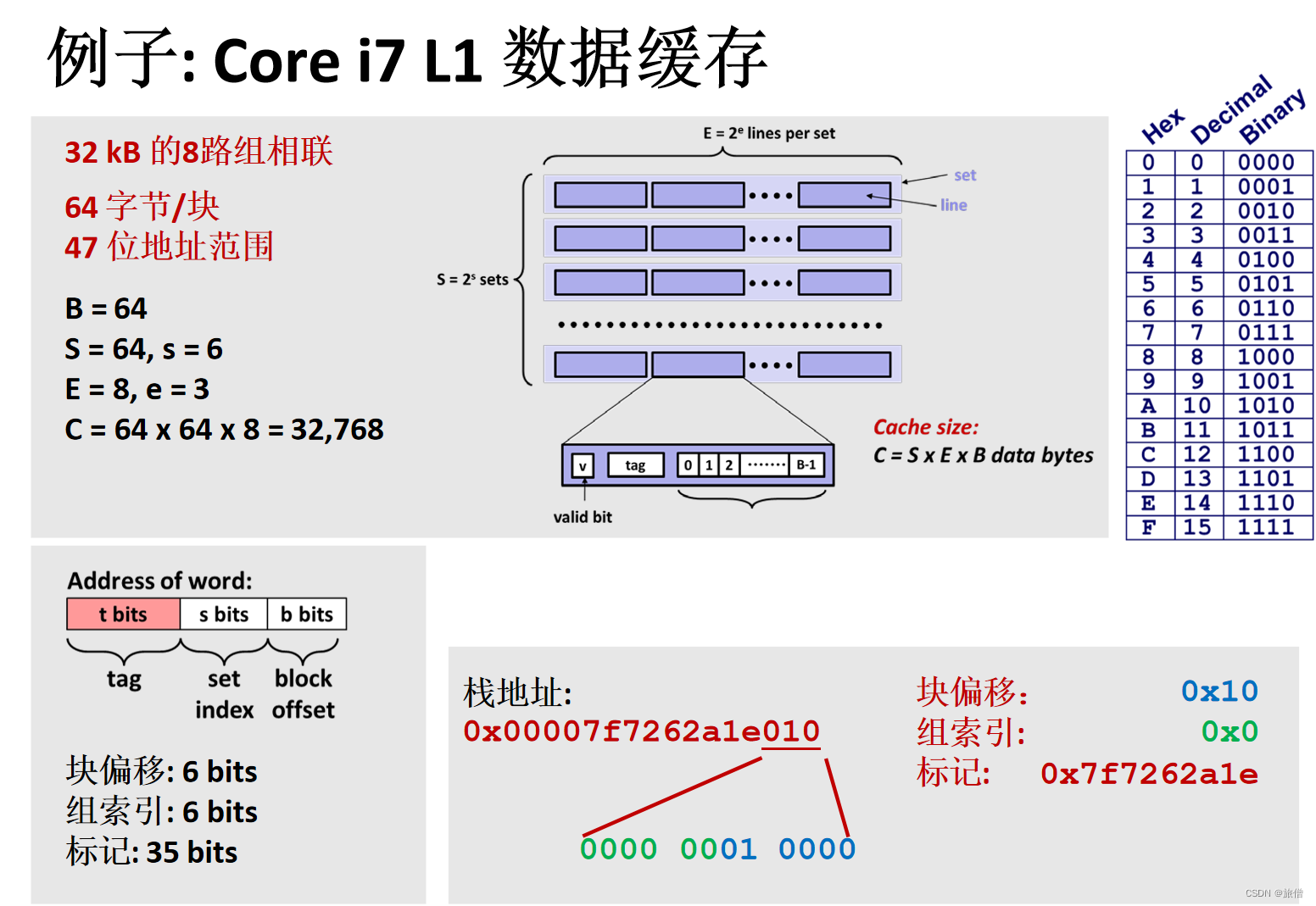
B = 64块 S = 32kB/64B每块/8路=64 E = 8 C=SEB
35 6 6机器数在计算机中是小端存储
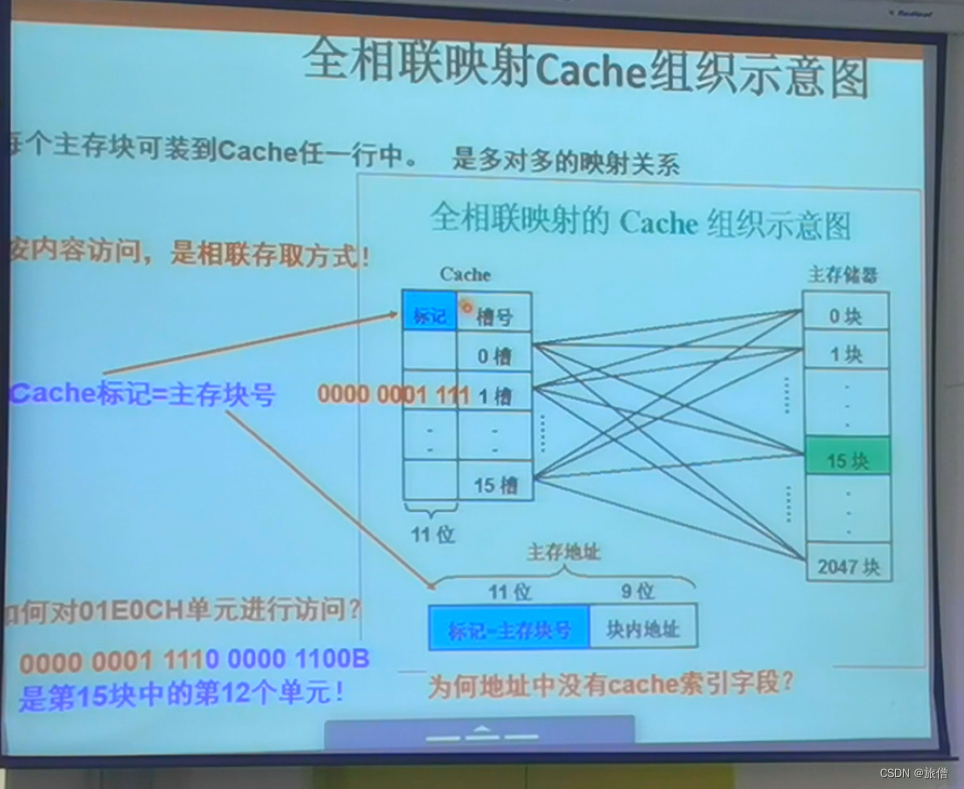 全相联映射示意图
全相联映射示意图
ACD 没有路索引
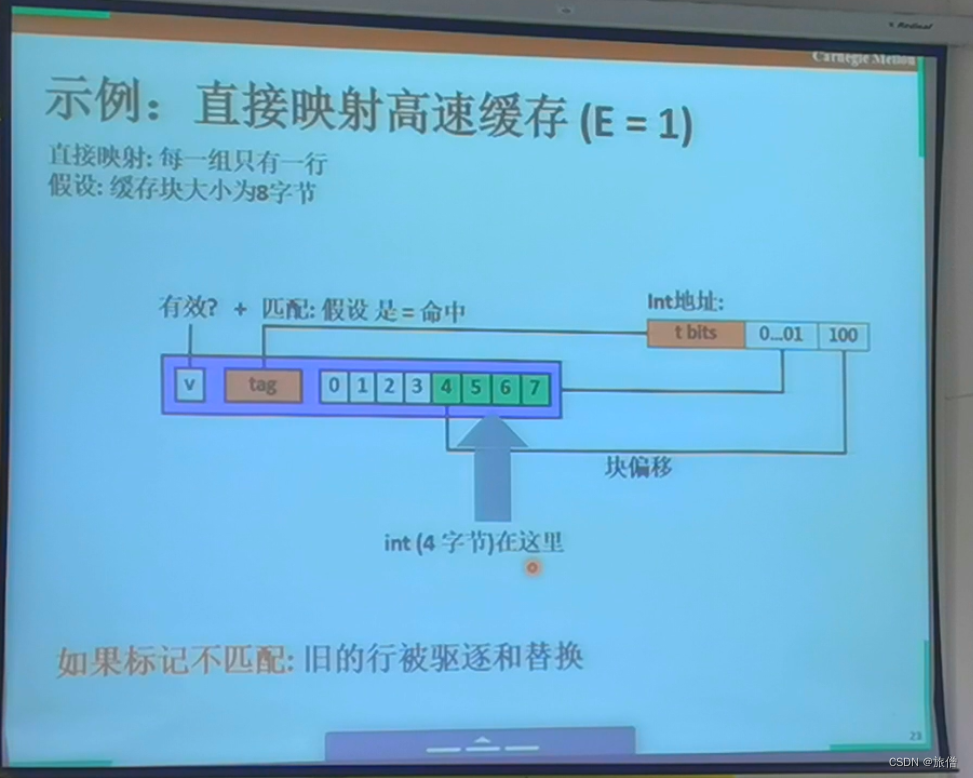
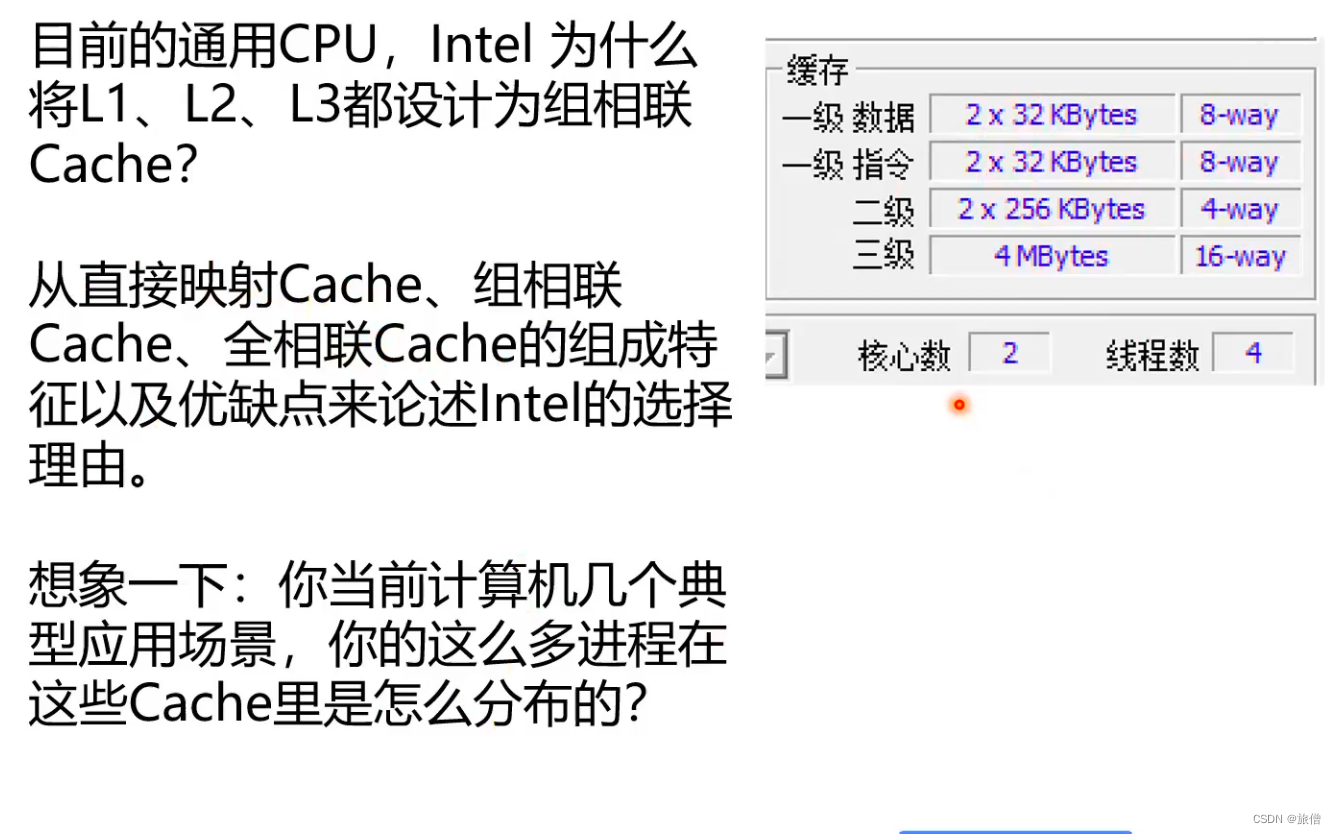 直接映射会发生窗口抖动的现象 全相联映射会出现比较器比较多而产生电路设计复杂的问题。
直接映射会发生窗口抖动的现象 全相联映射会出现比较器比较多而产生电路设计复杂的问题。
抖动指的是多次冲突不命中。
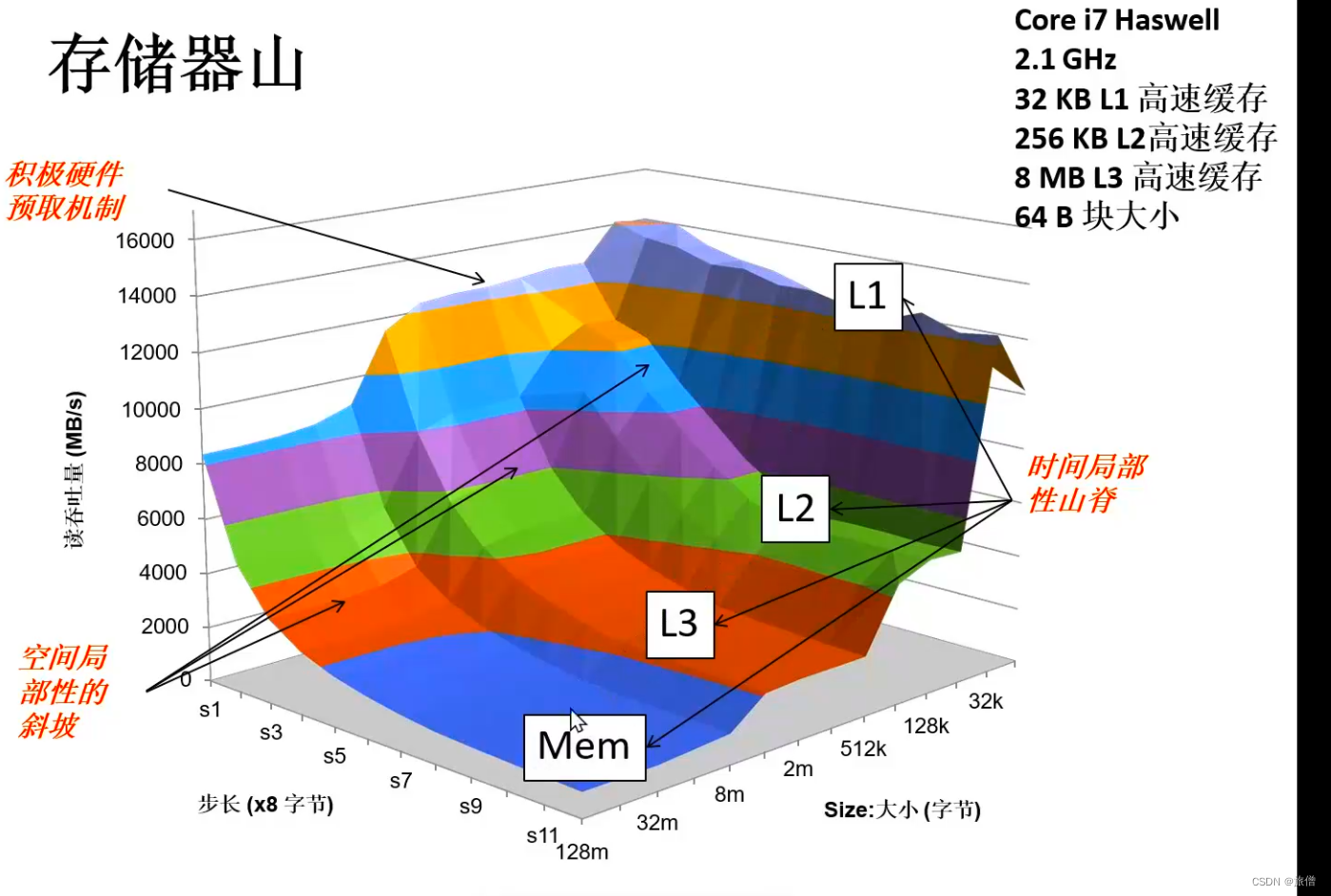
存储器山


编写面向cache友好的程序:




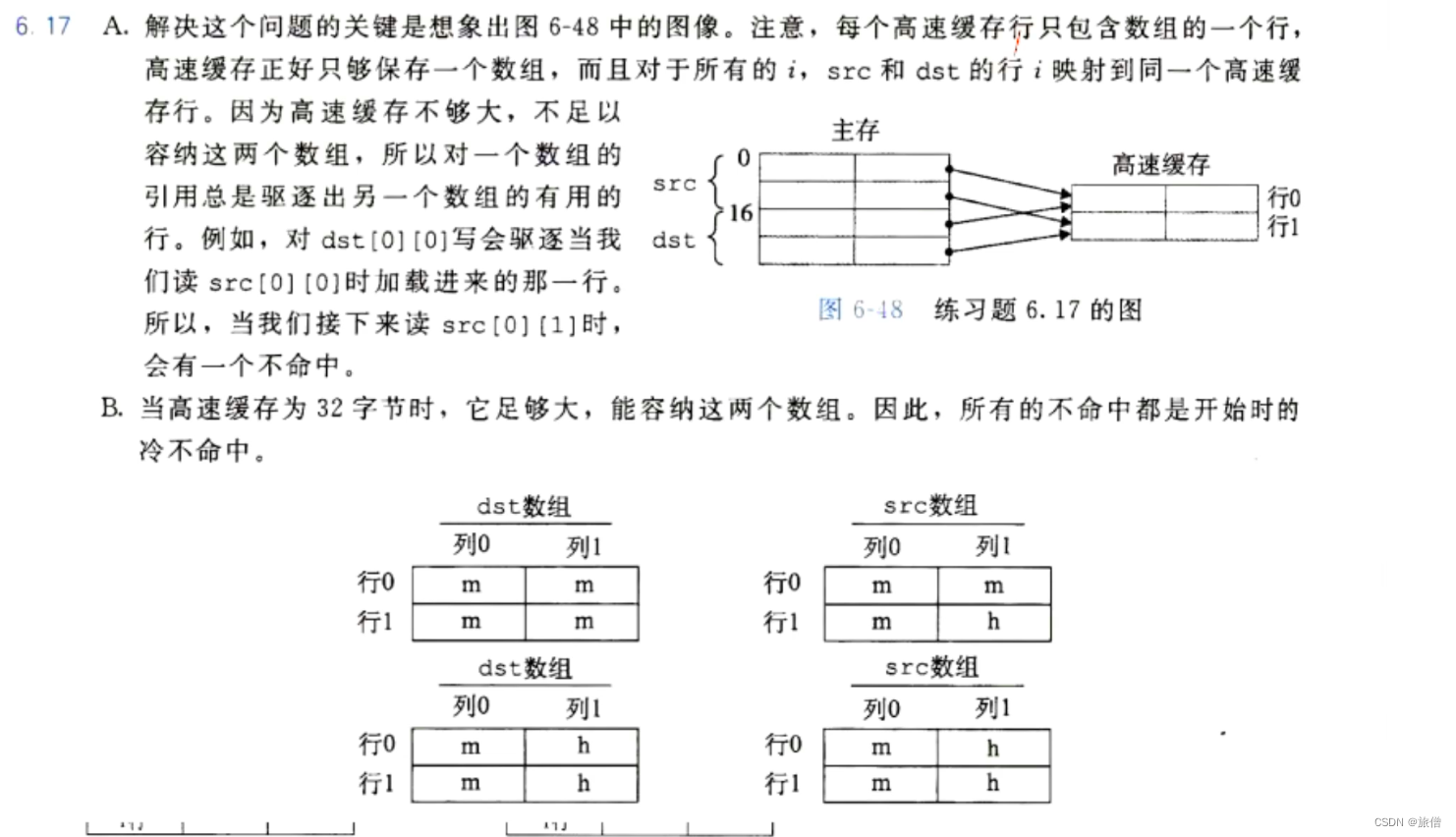
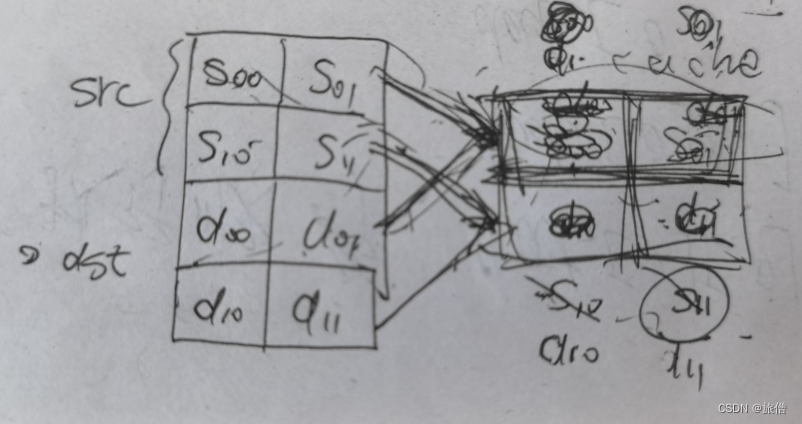
第一次 读00 调入cache 读disc调入cache

第二部访问source 01命中 但是dst 10不在cache里 调入 10 11
第三次访问source 10 m调入 11 访问dis01 命中
第四次访问source 11 命中 访问 11命中
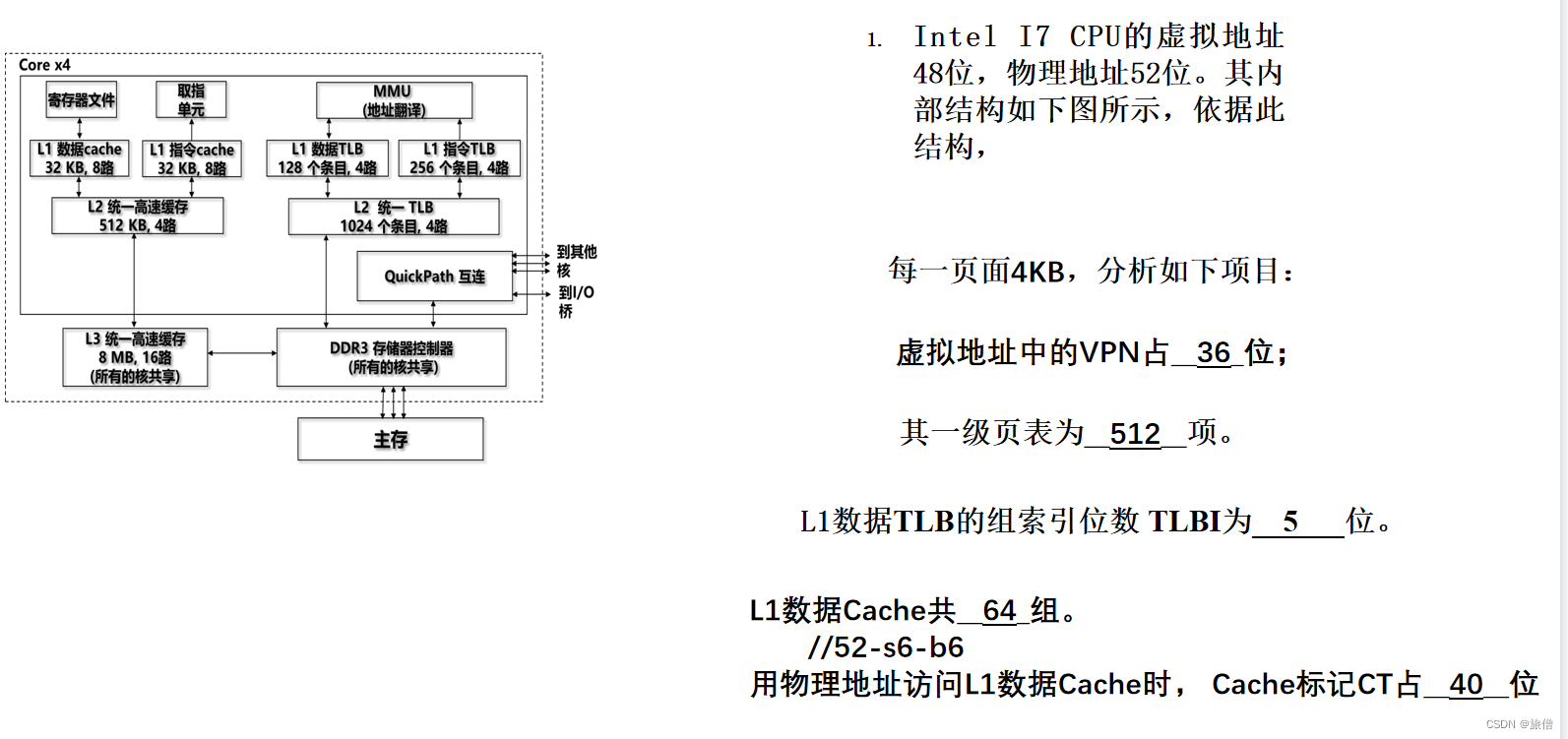
组号八位 组内地址八位 所以标记是40位。
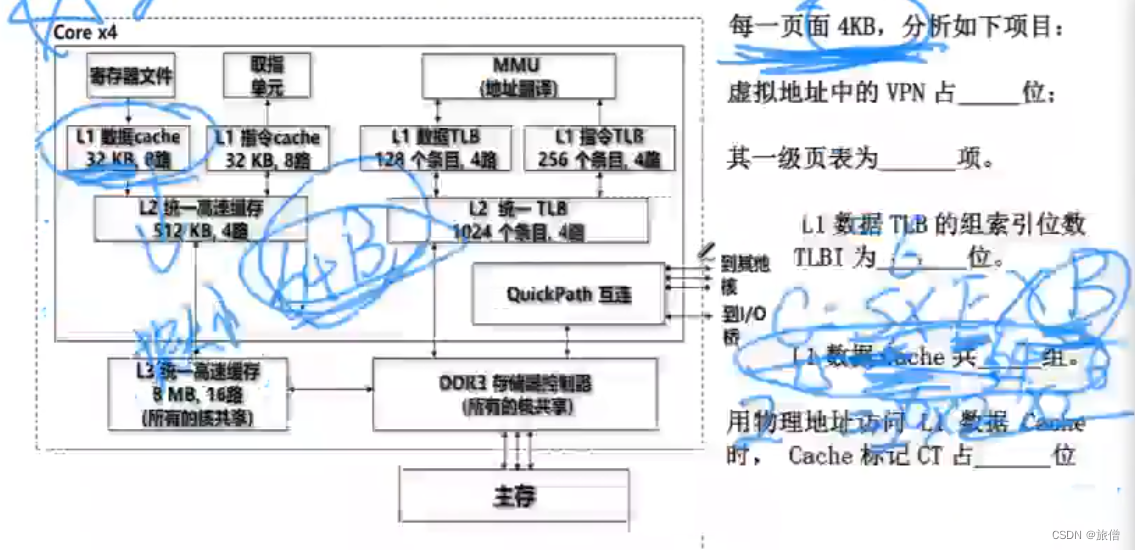



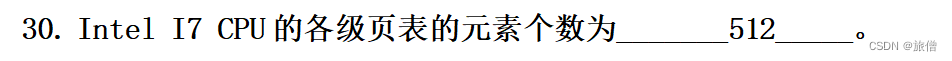
 一个块是32KB
一个块是32KB
CH7



函数定义是强符号 函数调用是弱符号 函数没有赋初值是强符号 函数没有赋初值是弱符号
只要是局部变量他就和强弱符号没有关系了

DS SS数据段寄存器 SS代码段寄存器
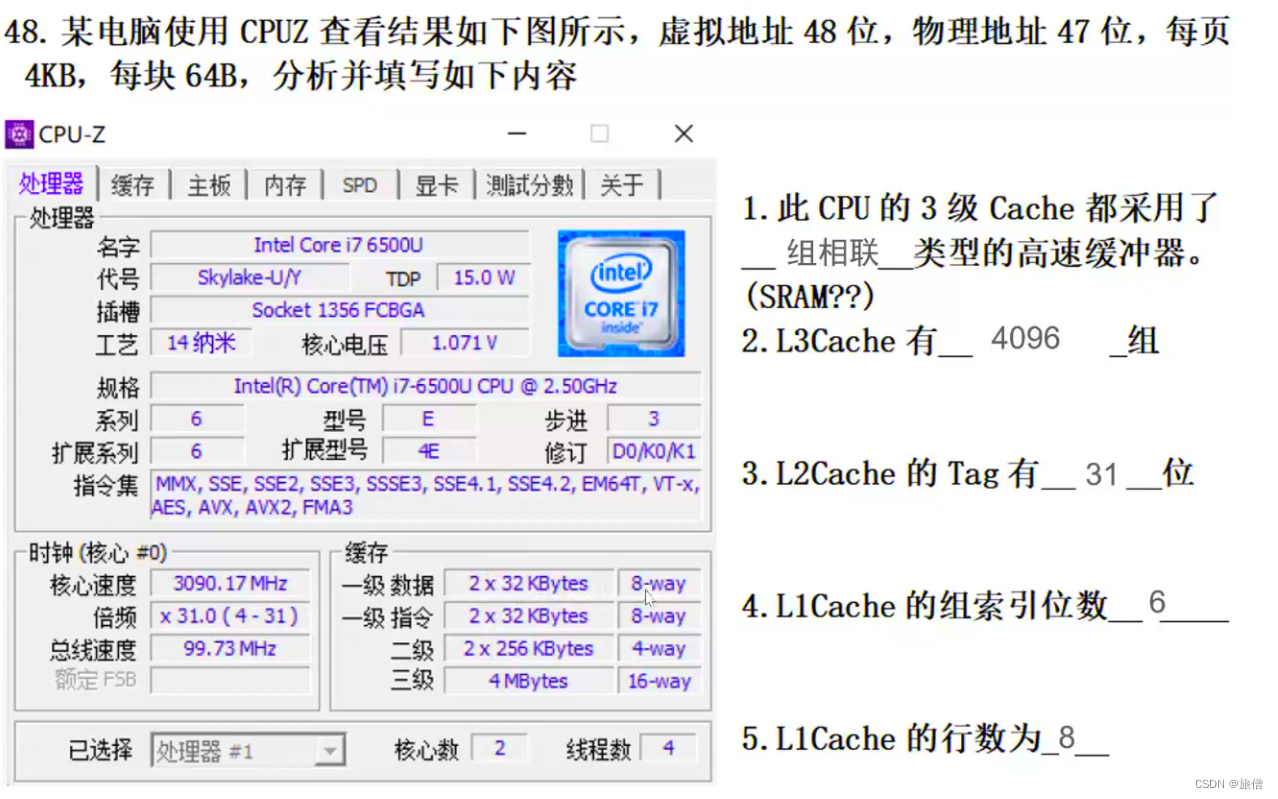
GOT表和PLB表

动态库的出现就是
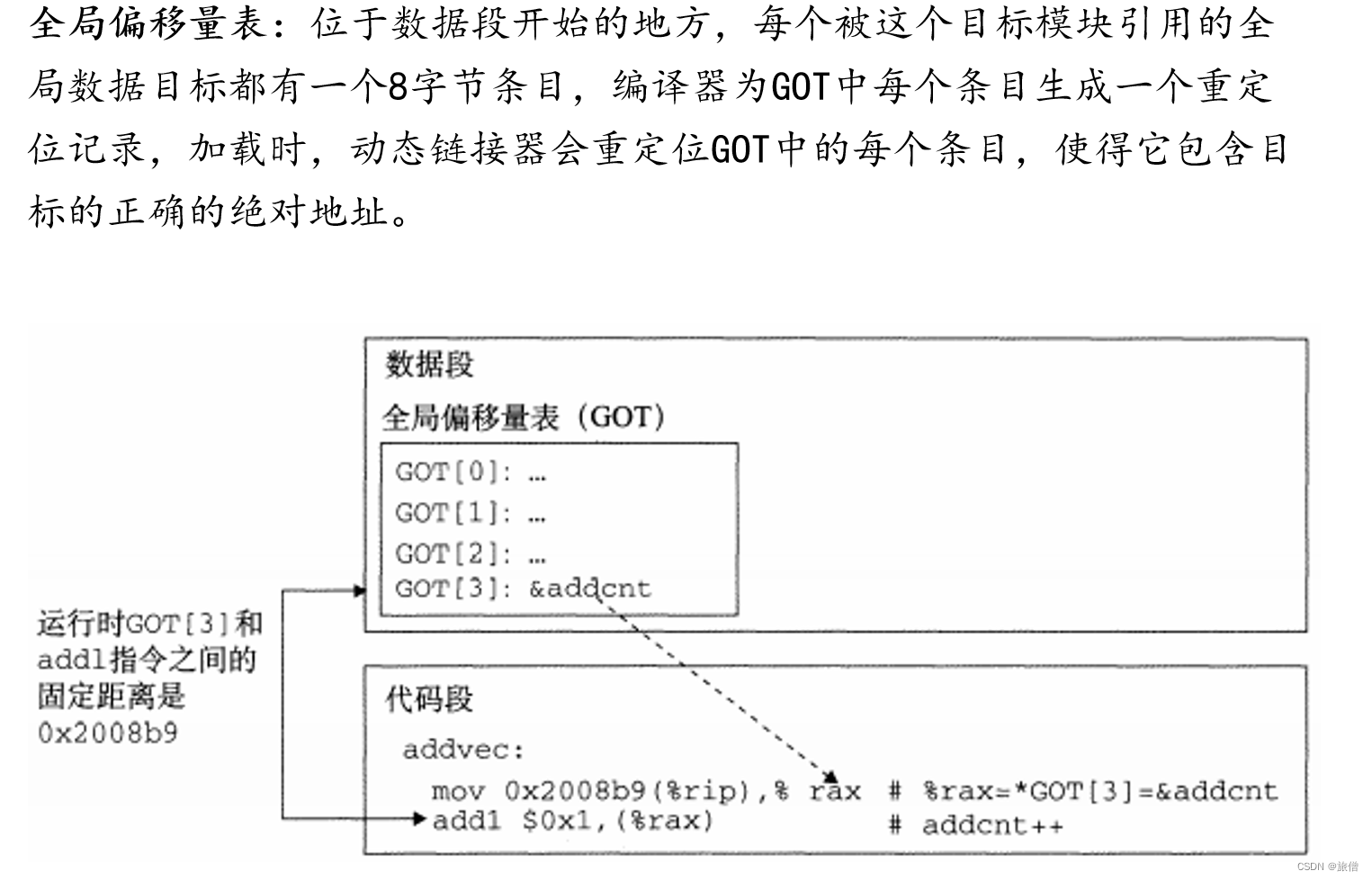
符号解析的全过程

Linux下的三种目标文件 可重定位目标文件 .so文件 .o文件是经过编译器和汇编器生成的可重定位目标文件
如何解决文件过多 查找困难问题:



链接器的解析外部引用的算法:
- 按照在命令行的顺序扫描.o与 .a文件
- 在扫描期间,保持一个当前未解析的引用列表. 扫到每一个新的.o或 .a文件, 遇到目标 obj,尝试解析列表中每个未解析的符号引用,而不是在obj中定义的符号。
- 如果在扫描结束时,在未解析符号列表中仍存在任一条目,那么就报错!
没有被解析的外部符号 就进入未解析的列表里:
关于lib的解析算法:
CH8


属不属于系统调用

内核调用函数:
8.6

总结 setjump和long jump都是非本地跳转 long jump被调用一次但不返回 setjump调用一次但返回多次。


进程和信号:
信号的原则:

CH9
主要讲了三个问题
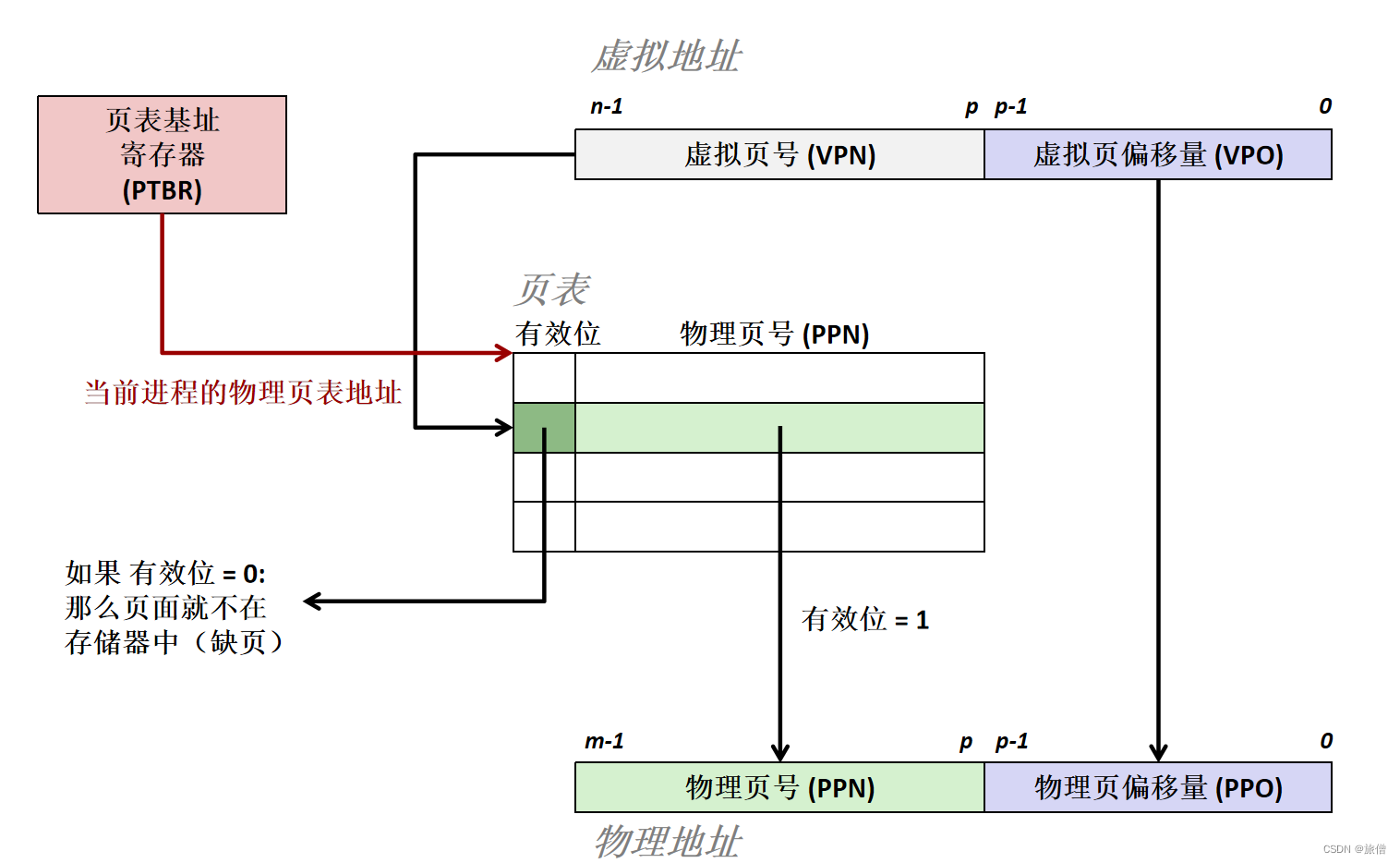
- 什么是虚拟内存
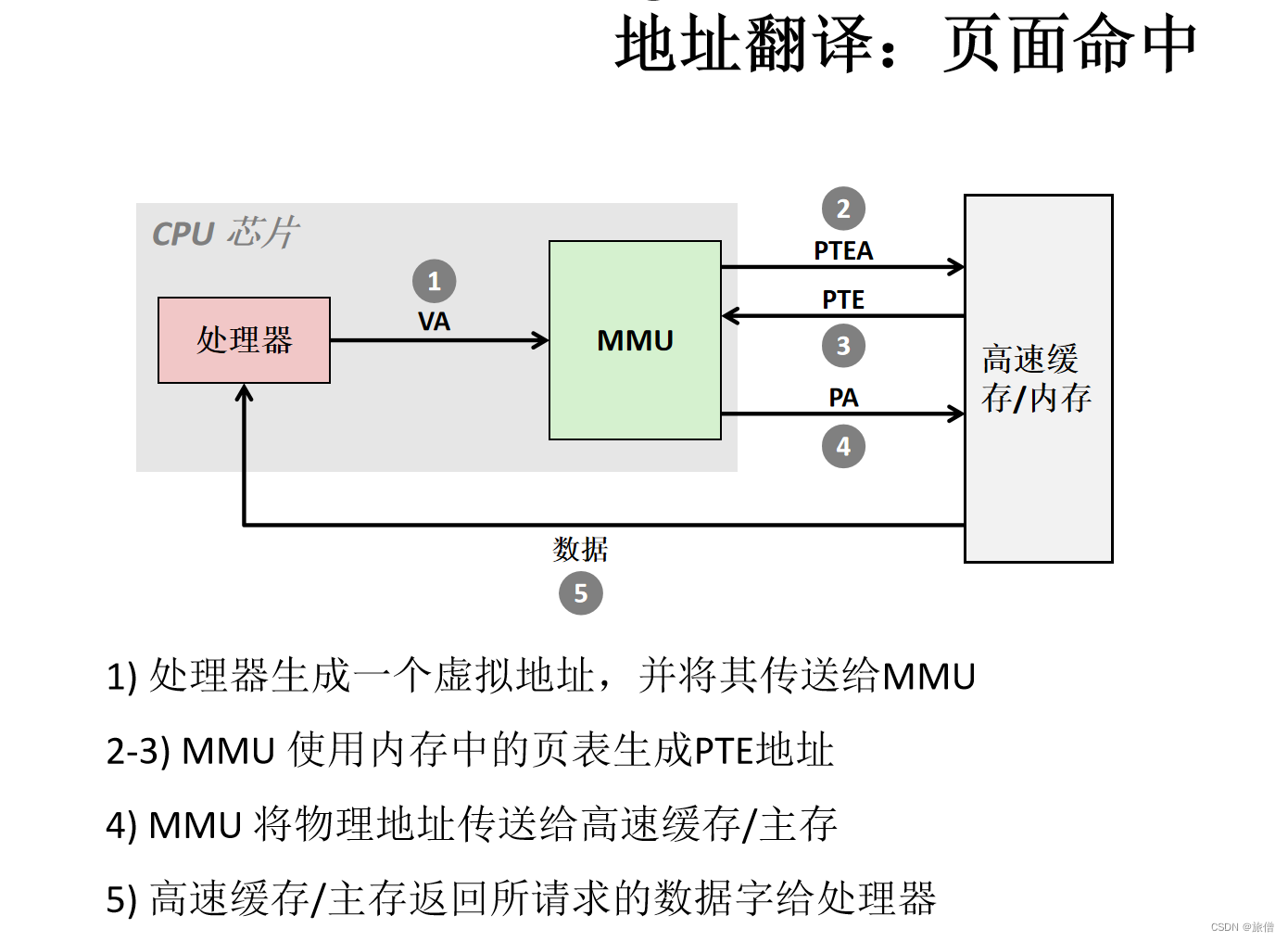
- 地址翻译过程
- IA32地址翻译过程
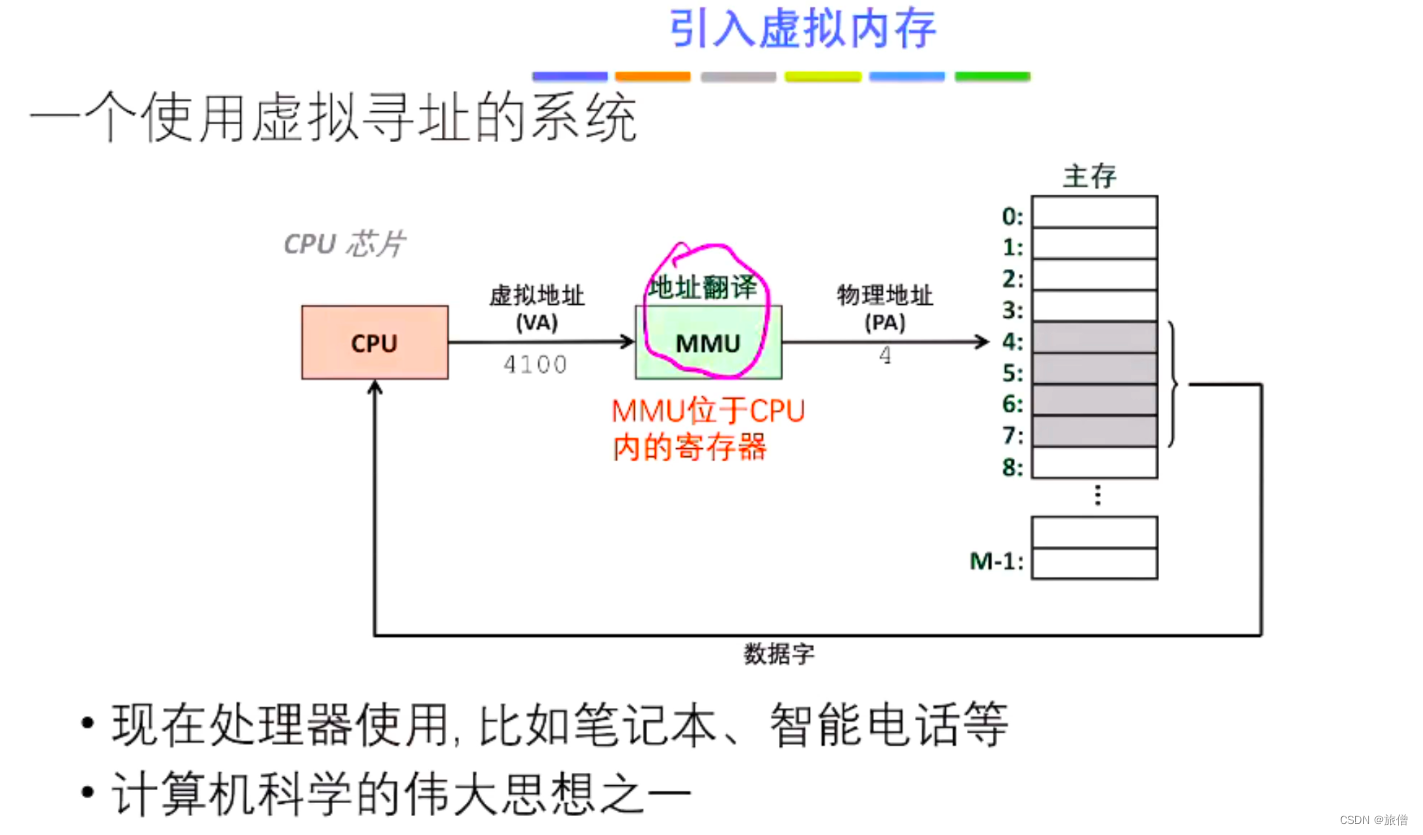
MMU是一个寄存器:
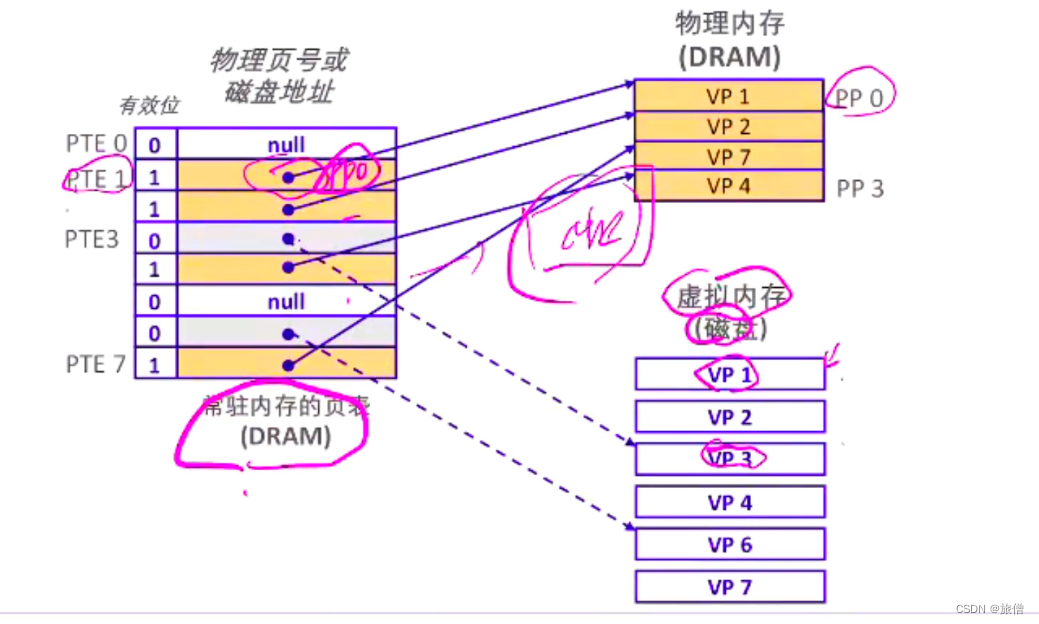 给内存里的页表加速:为缓存 磁盘号和truck号
给内存里的页表加速:为缓存 磁盘号和truck号

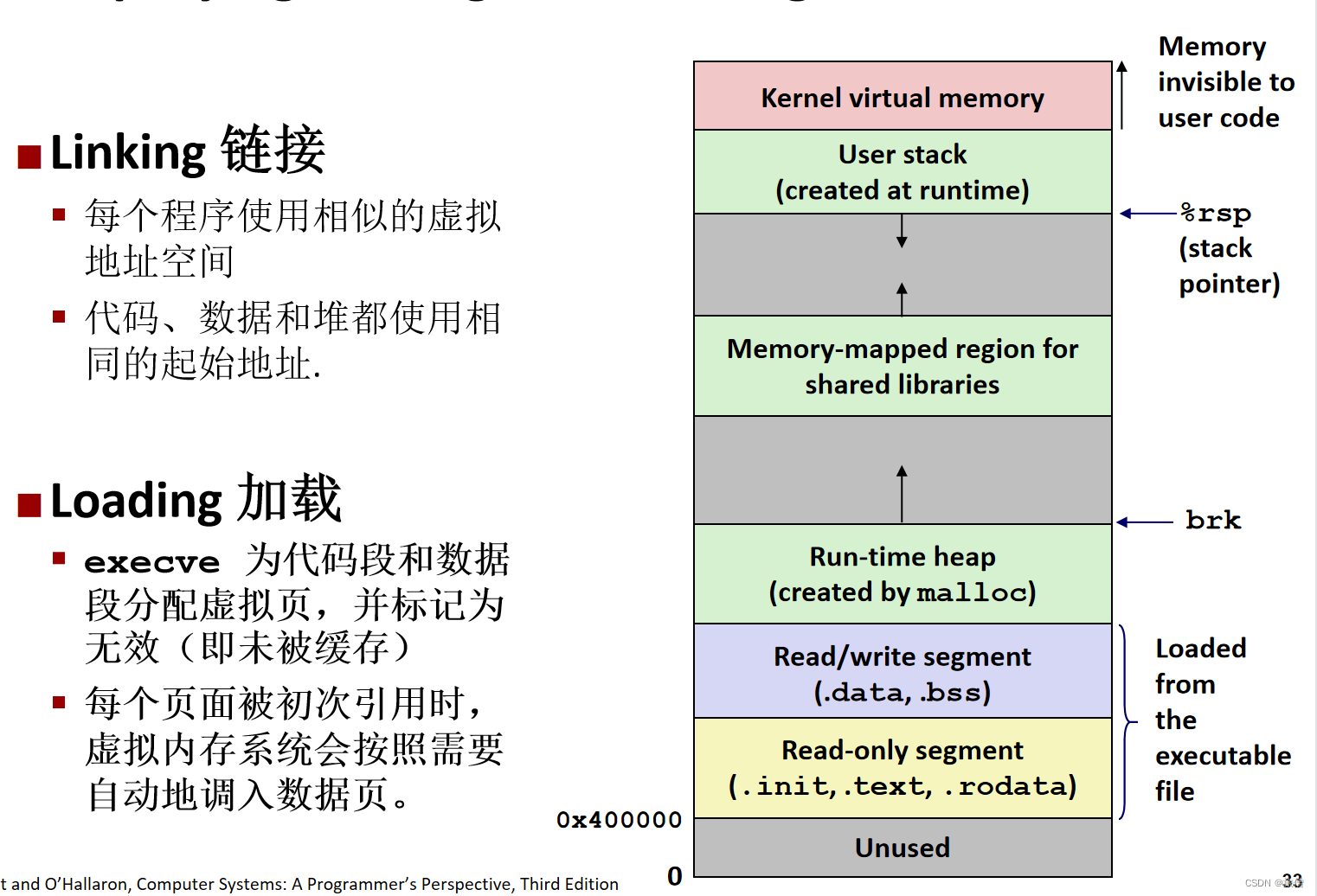
简化链接 使用execve函数
其他使用execve的函数:


可执行文件的反汇编格式
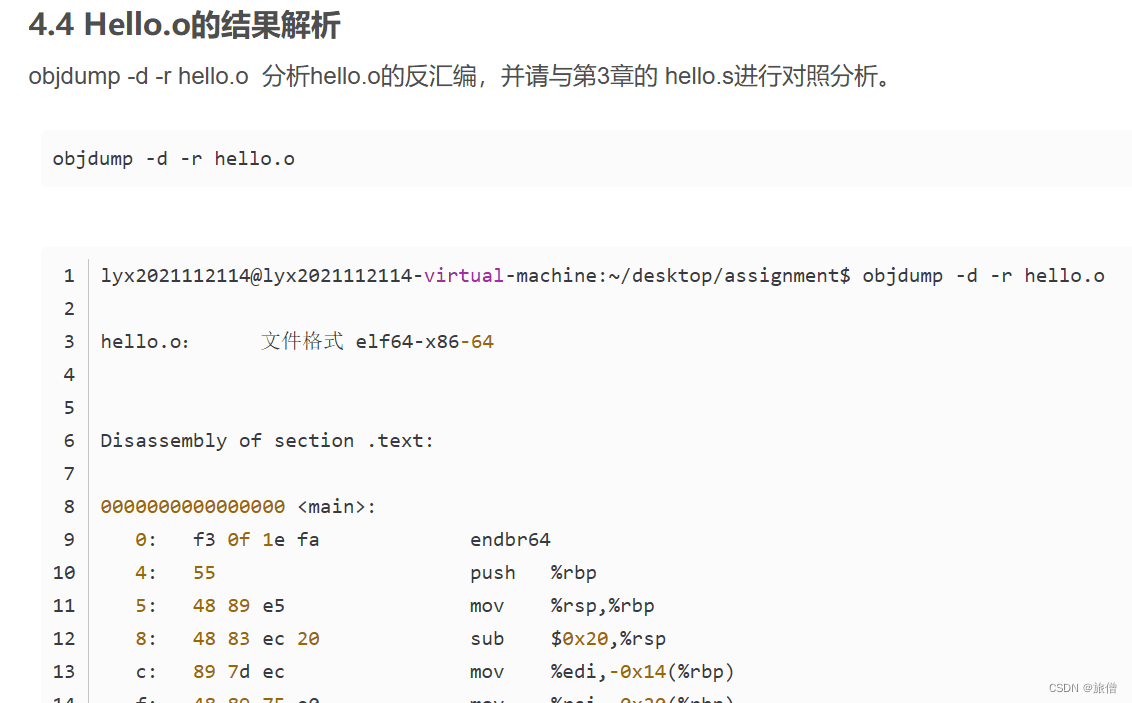
可重定位目标文件的反汇编格式:
ISA地址计算是由段式管理来完成的

段式管理机构 将地址进行分段 页式管理机构MMU