背景
上一篇文章《[GPT大语言模型Alpaca-lora本地化部署实践]》介绍了斯坦福大学的Alpaca-lora模型的本地化部署,并验证了实际的推理效果。
总体感觉其实并不是特别理想,原始Alpaca-lora模型对中文支持并不好,用52k的中文指令集对模型进行fine-tuning之后,效果依然达不到网上说的媲美GPT-3.5的推理效果,验证了那句话:“事不目见耳闻,而臆断其有无,可乎?”
在具有3块Tesla P40显卡的服务器上,利用3块GPU显卡加载模型参数和计算,进行一次简单的推理(非数学运算和逻辑运算)也需要大概30s-1min的时间,效率简直慢的惊人。在京东云GPU云主机部署上,虽然推理效率提高了很多,用中文数据集对模型进行了fine-tuning,然而对中文的支持也并不是很好,经常会出现乱码、重复问题、词不达意等情况。
最近大模型也同雨后春笋般的层出不穷,各个大厂和科研机构都推出了自己的大模型,其中基于LLaMA(开源且好用)的最多,所以决定再看看其他模型,有没有推理效果好,中文支持好,同时推理效率高的模型。
经过筛选,Vicuna-13B的推理效果据说达到了ChatGPT的90%以上的能力,优于LLaMA-13B和Alpaca-13B的效果(具体如下图所示) 。评估方法是对各个模型Alpaca、LLaMA、ChatGPT和Bard输入同样的问题,然后通过GPT-4当裁判对推理结果进行打分,以ChatGPT的回答作为100分,回答越接近得分越高(虽然评估方法并不科学,但是目前看也没有更好的办法对模型推理结果进行更科学的评估)。
同时Vicuna的训练成本也很低,据说只需要$300左右,所以尝试本地化部署一下Vicuna-7B,看看效果如何,说干就干。

环境准备
由于之前本地化部署过Alpaca-lora模型了,本以为可以直接下载开源包,简单部署一下就可以看到效果了,结果发现我还是“too young,too simple”了,环境部署和解决包冲突的过程竟然比第一次部署Alpaca-lora模型还要费劲。
简单的复述一下部署流程,详细的可以参考上一篇内容《GPT大语言模型Alpaca-lora本地化部署实践》。
- 本地化部署或GPU云主机部署:GPU服务器具有4块独立的GPU,型号是P40,单个P40算力相当于60个同等主频CPU的算力;也可以使用京东云GPU云主机,要选购P40型号;
- 安装显卡驱动和CUDA驱动。
模型准备
由于Vicuna 是基于LLaMA模型的,为了符合LLaMA 模型license授权,仅发布了 delta 权重,所以我们需要将原始llama-7b模型与delta模型权重合并之后,才能得到vicuna权重。
首先是下载llama-7b模型,由于文件比较大,所以用lfs直接从文件服务器上下载,大小有26G,执行:
git lfsclonehttps://huggingface.co/decapoda-research/llama-7b-hf
然后是下载delta模型,执行:
git lfsclonehttps://huggingface.co/lmsys/vicuna-7b-delta-v1.1
下载完成后进行权重合并,执行:
python -m fastchat.model.apply_delta \ --base ./model/llama-7b-hf \ --delta ./model/vicuna-7b-delta-v1.1 \ --target ./model/vicuna-7b-all-v1.1
这个合并过程会很快,最终结果如下,合并之后参数大小变成了13G。


合并之后的目录下会有配置文件和数据文件。

安装依赖包
Vicuna主要用到3个依赖包,fschat、tensorboardX和flash-attn,前2个安装比较顺利,直接pip install fschat、tensorboardX即可安装完成。flash-attn安装遇到了问题,一直报以下错误:

经过一番检索,发现是gcc版本太低导致的,需要升级gcc,首先查看了一下本地的gcc版本,gcc -v和g++ -v发现是4.8.5的,确实是太低了,那么既然要升级,就升级到最新版,直接下载13.1版本,可以在
http://ftp.gnu.org/gnu/gcc/选择想要安装的版本,这里选择的是gcc-13.1.0.tar.gz。
执行:
tar -xzf gcc-13.1.0.tar.gz
cd gcc-13.1.0
./contrib/download_prerequisites
mkdir build
cd build/
…/configure -enable-checking=release -enable-languages=c,c++ -disable-multilib
然后执行make编译,注意这里make时间会非常长,可能会持续几个小时,可以使用 make -j 8让make最多运行8个编译命令同时运行,加快编译速度。
顺利完成后,我们再执行make install进行安装。
然后用gcc -v和g++ -v验证版本是否已经更新,如果提示如下,说明安装完成。
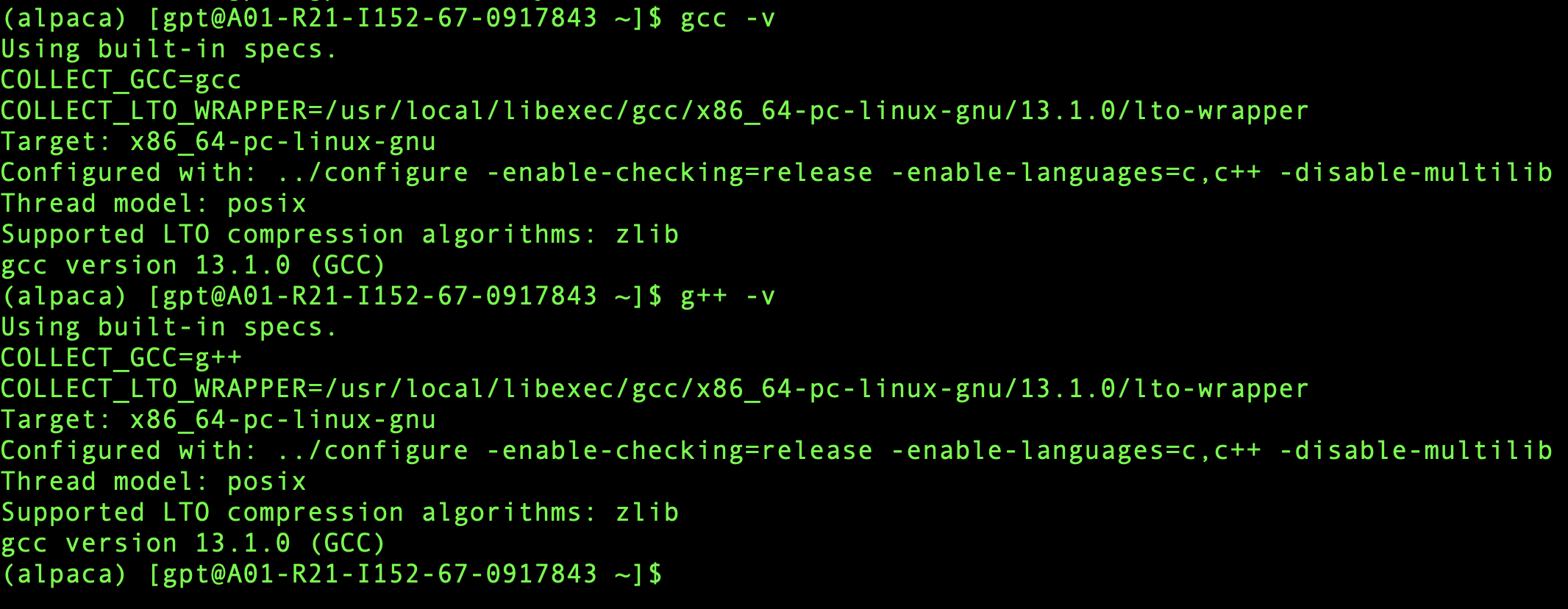
然后我们需要卸载原有的gcc和g++,切换到root权限,执行yum -y remove gcc g++。
配置新版本全局可用,执行ln -s /usr/local/bin/gcc /usr/bin/gcc。
更新链接库,执行:
查看原链接库:strings /usr/lib64/libstdc++.so.6 | grep CXXABI
删除原链接库:rm -f /usr/lib64/libstdc++.so.6
建立软连接:ln -s /usr/local/lib64/libstdc++.so.6.0.29 /usr/lib64/libstdc++.so.6
查看新链接库:strings /usr/lib64/libstdc++.so.6 | grep CXXABI
如果最新版本有变化,那么恭喜你,说明已经升级成功啦。

安装cuda
由于之前是用rpm包安装的cuda,有些文件是缺失的,运行时会报各种奇奇怪怪的错误,这里就不赘述了(只有经历过才会懂),直接介绍用二进制文件安装cuda过程。
下载地址:
https://developer.nvidia.com/cuda-11-7-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=CentOS&target_version=7&target_type=runfile_local
注意这里要选择runfile(local)。
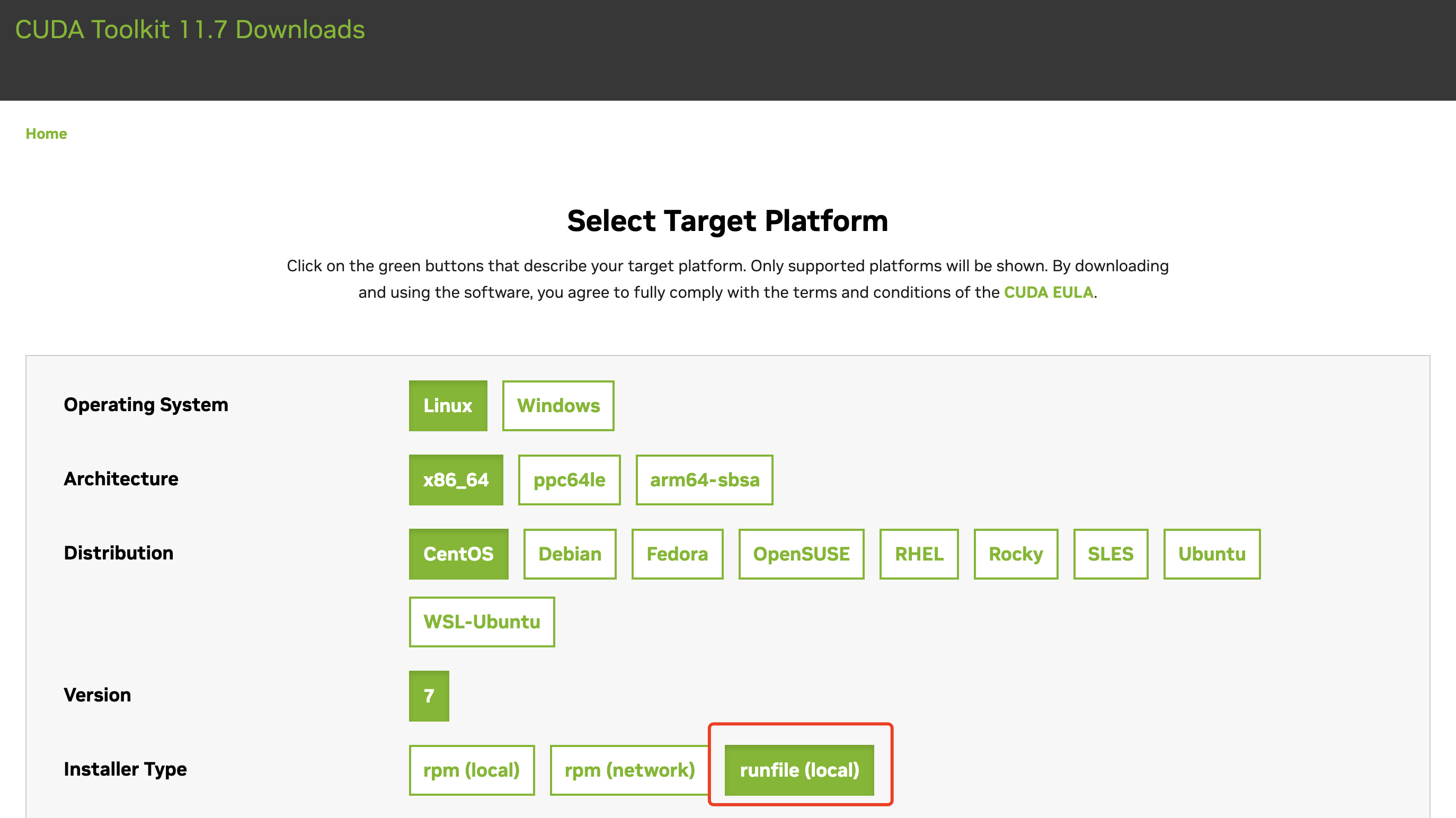
然后执行sh
cuda_11.7.0_515.43.04_linux.run。
安装完成后,需要配置环境变量,在本地.bash_profile中配置如下两项:
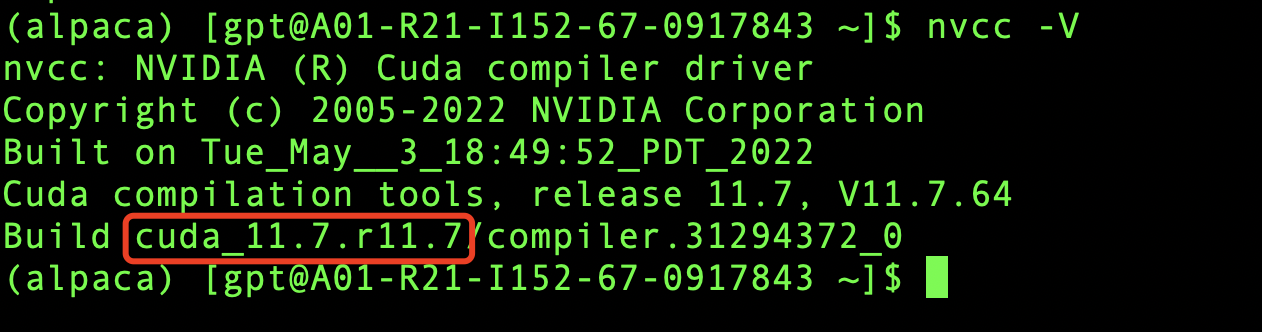
下面验证一下安装是否成功,执行nvcc -V,如下图所示,那么恭喜你,安装成功啦。
安装cudnn和nccl
安装cudnn和nccl需要先在nvidia注册账号,注册之后可以在以下两个地址下载相应的rpm包,然后rpm -ivh XXXXX.rpm包即可。
cudnn下载地址: https://developer.nvidia.com/cudnn
nccl下载地址: https://developer.nvidia.com/nccl/nccl-legacy-downloads
安装完成后,如下图所示说明已经安装成功rpm包。

模型推理
又到激动人心的时刻啦,让我们来测试一下看看模型的推理效果如何?首先我们先擦拭一下还没有干透辛勤的汗水,一切努力,都是为了最终能跟机器人程序对上话,理想情况是让我们感觉它并不是一个机器人。
在终端执行如下命令,然后输入问题即可。
python -m fastchat.serve.cli --model-path ./model/vicuna-7b-all-v1.1 --style rich
当然,还可以根据不同的需求场景,设置不用的运行参数,如下:
#压缩模型 预测效果会稍差一点,适合GPU显存不够的场景
python -m fastchat.serve.cli --model-path ./model/vicuna-7b-all-v1.1 --load-8bit --style rich
#使用cpu进行推理,速度会很慢,慎用
python -m fastchat.serve.cli --model-path ./model/vicuna-7b-all-v1.1 --device cpu --style rich
#使用多个GPU进行预测
python -m fastchat.serve.cli --model-path ./model/vicuna-7b-all-v1.1 --num-gpus 3 --style rich
1)推荐菜谱测试:


2)多语言测试:

3)代码能力测试:


4)数学计算测试

5)普通对话推荐

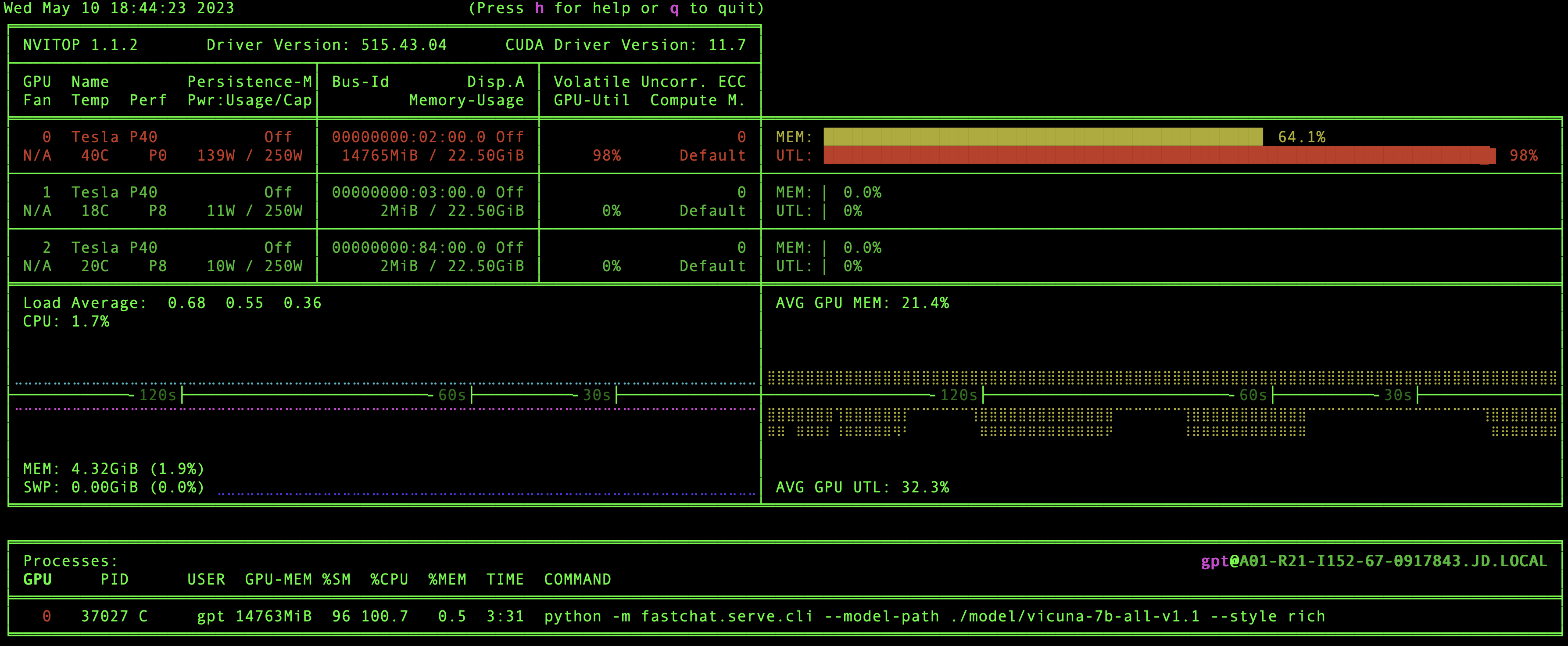
推理过程中GPU服务器资源使用情况,目前使用单GPU进行推理,都可以做到秒级响应,GPU内存空加载13G,推理时不到15G,推理时单GPU算力基本可以达到90%以上,甚至100%,如下图所示。
总结一下:
1)对精确的推理效果并不是很理想,比如推荐菜谱,感觉是在一本正经的胡说八道,按照推理的结果很难做出可口的饭菜️;
2)对多种自然语言的支持,这个真的是出乎预料,竟然日语和西班牙语完全都能够自如应对,可以说是相当的惊艳了;
3)编码能力还是可以的,能够大概给出基本需求,当然如果想直接编译执行可能还需要人工微调,但是作为辅助工具应该是没问题的;
4)数据计算能力目前看还是比较弱的,简单的乘法目前还不能够给出正确的答案;
5)普通的对话是完全没有问题的,对中文的理解也完全能否符合预期,解解闷排解一下孤独是能够cover住的。
由于模型目前还没有做fine-tuning,从目前的推理效果来看,已经是非常不错了,而且推理的效率也是非常不错的,即使使用单GPU进行推理也可以做到秒级响应,而且推理过程中显存占用也才只有60%多,跟空载时候的50%多没差多少,总之在没有经过fine-tuning的情况下,模型的推理表现和推理效率还是可以打7-8分(满分10分)的,如果假以时日,有足够的语料库和进行fine-tuning的话,效果还是可期的。
模型fine-tuning
要想使模型适合某一特定领域内的场景,获取特定领域的知识是必不可少的,基于原始模型就要做fine-tuning操作,那么我们尝试做一下fine-tuning,看看效果如何吧。
fine-tuning需要在终端执行一下命令:
torchrun --nproc_per_node=3 --master_port=40001 ./FastChat/fastchat/train/train_mem.py \
--model_name_or_path ./model/llama-7b-hf \
--data_path dummy.json \
--bf16 False \
--output_dir ./model/vicuna-dummy \
--num_train_epochs 2 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 300 \
--save_total_limit 10 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "tensorboard" \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--tf32 False \
--model_max_length 2048 \
--gradient_checkpointing True \
--lazy_preprocess True
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KabsdmH7-1684382280182)(null)]
最终./model/vicuna-dummy目录输出就是我们fine-tuning之后的模型权重文件目录。
很遗憾,本文fine-tuning没有成功,报错如下:
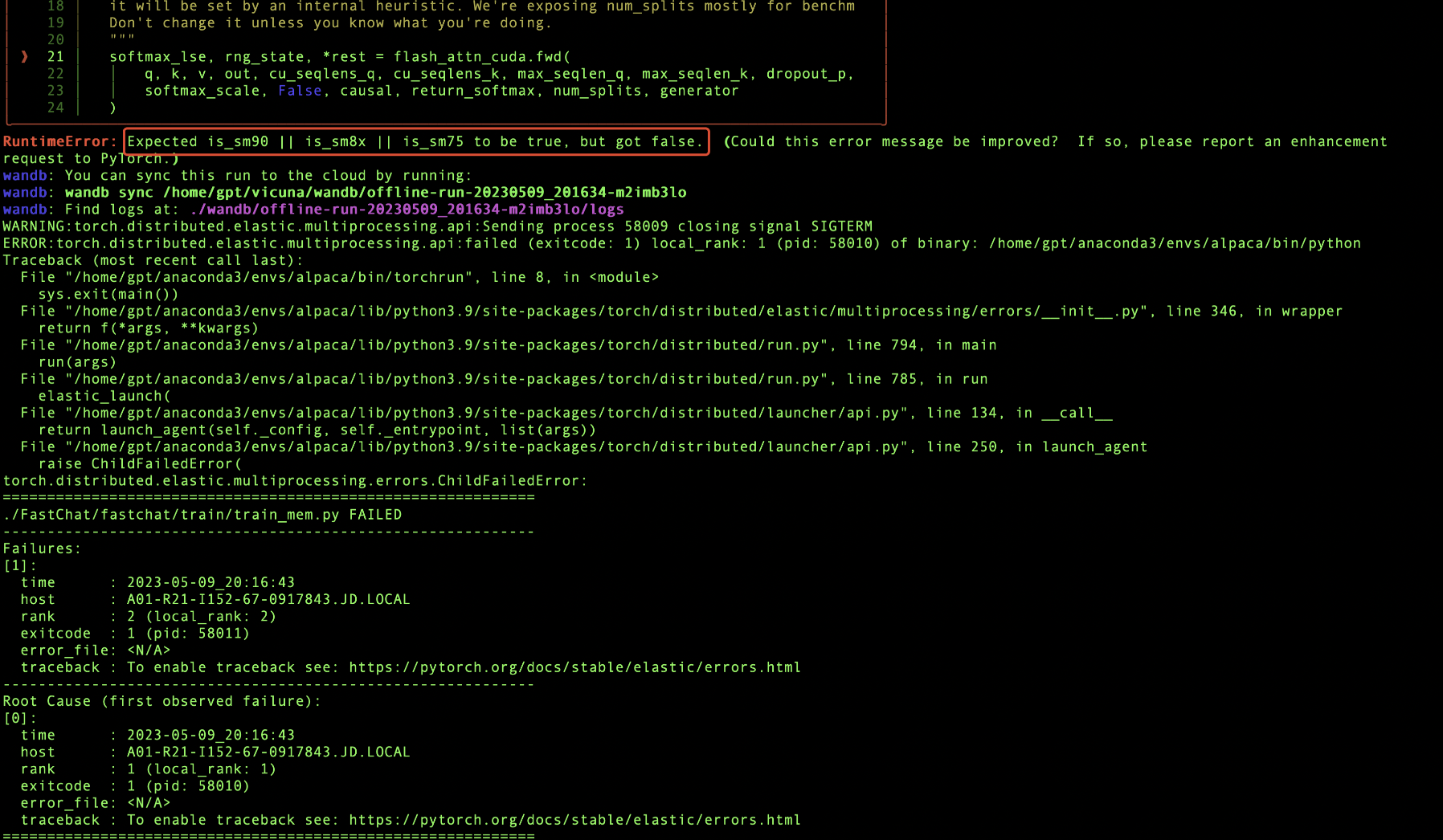
原因也很简单,由于我们使用的GPU型号是Tesla P40,此款显卡使用的SM_62架构,目前模型fine-tuning至少需要SM_75及以上架构,看社区有在4090、A100或者A80显卡上fine-tuning成功的,所以fine-tuning只能后续再更高架构的显卡上进行了。

后续工作
终上,Vicuna模型在整体表现和推理效率上可以说是秒杀Alpaca模型的,我们本文测试用的是Vicuna-7b,如果是Vicuna-13b效果会更好,而且对多种自然语言(包含中文)的支持也要远远好于Alpaca模型,确实像社区所说的,目前Vicuna模型可以说是开源大模型的天花板了,如果想基于开源大模型进行二次开发,是个不二的选择。
基于大模型的本地化部署工作目前就告一段落了,后续做的工作可能有以下几点:
1)如果有更好的显卡,可以对vicuna进行fine-tuinig,验证一下fine-tuning之后模型能不能学到特定领域的知识;后续准备使用公司内部提供的试用资源【京东云GPU云主机p.n3a100系列】,这个产品提供Nvidia® A100 GPU(80G显存),搭配使用Intel® Xeon® Platinum 8338C 处理器及DDR4内存,支持NVLink,单精度浮点运算峰值能达到156TFlops,可以说是最强算力了。
2)找到合适的与目前应用结合的场景,将大语言模型应用落地;
3)基于vicuna开源项目进行二次开发,封装成可用的服务;
4)基于大语言模型进行更多的探索和学习。
来源:京东云开发者社区
作者:Beyond_luo(未经授权请勿转载)