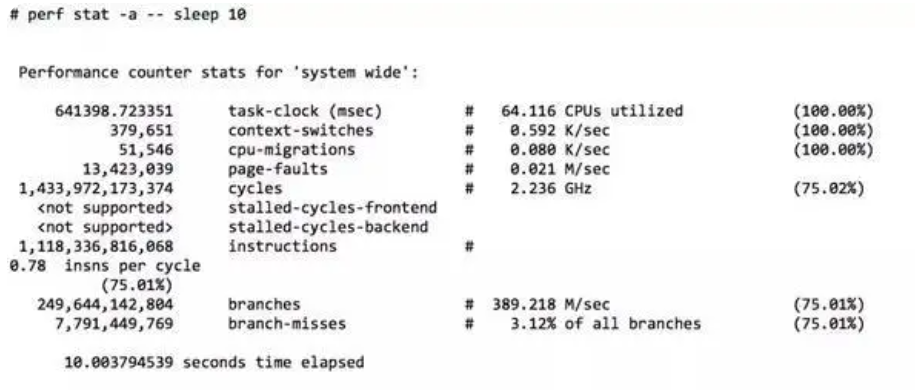
一、什么是哨兵
Redis Sentinel(哨兵)是一个分布式系统,你可以在一个架构中运行多个哨兵(sentinel) 进程, 这些进程使用 gossip协议(基于流行病传播方式的节点或者进程之间信息交换的协议,在分布式系统中被广泛使用) 来接收关于Master是否下线的信息,并使用投票协议(agreement protocols) 来决定是否执行自动故障迁移,以及选择哪个 Slave 作为新的 Master (raft算法);
二、作用
1、监控:Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
2、提醒:当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
3、自动故障迁移: 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
总结:Sentinel (哨兵)进程是用于 监控 Redis 集群中 Master主服务器工作的状态,在 Master 主服务器发生故障的时候,可以实现 Master 和 Slave 服务器的切换,保证系统的高可用( HA );

三、栗子:
一般中小公司redis的架构使用一主两从三哨兵就已经够用了。
哨兵集群:自动监控和维护集群,不存放数据,这里用哨兵集群主要是为了防止一个哨兵挂了,还有其他哨兵可用。
一主两从:用于数据读取和存放
一、配置
参考官网
二、master宕机了出现问题
1、当master宕机了之后,两台从机的数据时没有问题的。哨兵会从两台从机选出一台作为master继续为程序服务。但是第一次访问得时候会出现异常。

原因:原master跪了,选举出新的master,需要重新发送心跳包。

2、当旧master恢复了之后,旧的会变成slave,而不会出现两台master或者新的master又变回slave。
3、哨兵以及新旧master配置文件内容,在运行期间会被哨兵动态进行更改。master--slave切换后,对应的master、slave以及哨兵配置文件的内容都会发生改变。即,master配置文件会多一行slave的配置,哨兵的监控目标也随之改变。
四、哨兵运行流程和选举原理
一、前置知识
一、主观下线(sdown)
1、sdown(主观不可用)是单个哨兵自己主观上检测到的关于master的状态,从哨兵的角度来看,如果发送PING心跳后,在一定的时间内没有得到合法的回复,就达到了sdown的条件。
2、哨兵配置文件中down-after-milliseconds设置了判断主观下线的回复时间。

二、客观下线 (odown)
客观下线需要一定数量的哨兵,多个哨兵达成一致意见才能认为一个master客观上已经宕机了。

三、哨兵的本质:
哨兵其实也是一台 Redis 服务器,只是不对外提供任何服务。稍后我们在配置时,你会看到实际上哨兵只是一个运行在特殊模式下的 Redis 服务器,你可以在启动一个普通 Redis 服务器时通过给定
--sentinel选项来启动哨兵。
二、哨兵监控工作流程
1、哨兵启动后根据配置向master发送info指令,获取并保存所有哨兵状态,主节点和从节点信息。
2、主节点master会记录所有从节点和与它连接的哨兵实例的信息。
3、哨兵会根据在主节点拿到的从节点信息,给对应的从节点建立连接后发送info指令
4、之后哨兵2来了也是给master发送info指令,同时拿到了从节点和哨兵的实例信息
5、此时哨兵2也会保存跟哨兵1一样的信息,只不过它保存的哨兵信息是2个
6、这个时候为了每个哨兵的信息都一致它们之间建立了一个发布订阅,互相发送 ping 命令 保证信息长期对称
7、当再来一个哨兵3时,也会做同样的事情,给主节点和从节点发送info,并且跟哨兵1和哨兵2建立连接
注意:从服务器是如何与主服务器同步数据的?
从服务器默认以每秒一次的频率,向主服务器发送命令:
REPLCONF ACK <replication_offset> // replication_offset 指从服务器当前的复制偏移量。
如果因为网络故障,主服务器传播给从服务器的写命令在半路丢失,那么当从服务器向主服务器发送命令:
REPLCONF ACK <replication_offset>时,主服务器将发觉从服务器当前的复制偏移量少于自己的复制偏移量,然后主服务器就会根据从服务器提交的复制偏移量,在复制积压缓冲区里面找到从服务器缺少的数据,并将这些数据重新发送给从服务器。所以从服务器宕机后,从新起来还是会把主服务器的数据同步过来的。
三、 故障转移原理
一、过程
1、哨兵会一直给主节点发送
publish sentinel :hello,直到哨兵收不到响应而报出 sdown。哨兵报出主节点 sdown 后还没有完,哨兵还会往内网里发布消息给其它哨兵说明这个主节点挂了。发送的指令是sentinel is-master-down-by-address-port。2、其余的哨兵接收到指令后,心想,主节点挂了吗?让我去看看到底挂没挂。发送的信息也是 hello,如果发现确实收不到响应而报出 sdown,这些哨兵也发送指令
sentinel is-master-down-by-address-port到自己的内网,就这样大家都收到了哨兵内部群发的这个 master 已经挂了的消息,然后汇总计票,超过一半就认为这个家伙确实挂了,然后就会修改其状态为odown。当一个哨兵认为主节点挂了标记的是sdown,当过半数哨兵都认为挂了其标记的状态是odown,这也就是配置哨兵为什么配置单数的原因。3、对于一个哨兵认为主节点挂了称之为主观下线,超半数哨兵认为主节点挂了称之为客观下线。
4、一旦被认为主节点客观下线后,哨兵就会进行下一步操作选举新master。
5、这个时候呢!几个sentinel就在一起开会了,所有的哨兵都在一个内网中,然后他们会做一件事情就是几个sentinel会同时发送指令
sentinel is-master-down-by-address-port并且携带上自己竞选次数和runid。每个 sentinel 既是参选者也是投票者,每个sentinel都有一票,信封就代表自己的投票权。选择规则:当sentinel1和sentinel3同时把指令发送到哨兵内部群里准备竞选时,sentinel2这个时候就说我先接到谁的指令就把票投给谁。假如sentinel1发的早,那么sentinel2的票就会投给sentinel1。
按照这样的规则一直发起投票直到某一个时间点有一个sentinel的票数为总sentinel数量的一半之多。假设说是sentinel1的票数满足总哨兵数量的一半之多后,sentinel1就会当选。这个时候就进行到了下一个阶段。
6、选举新的master,由指定的哨兵进行选举。选举条件
- 响应慢的干掉,sentinel会给所有的redis发送信息,响应速度慢的就会被干掉;
- 判断 offset 偏移量,判断数据同步性,假如说 slave2 的 offset 为90, slave1偏移量为100 那么哨兵就会认为slave2的网络是不是有问题啊!于是就会选slave1为新的主节点。那如果说是slave1和slave2的offset相同呢!那就看下一个判断;
- 最后一步就是判断runid了,也就是职场中的论资排辈了,时间早的上位。
- 选出新的主节点后就要对所有的节点发送指令了,召集所有兄弟,告知新老大的上位。然后 slave 从新老大master上同步数据,广播告知所有客户端新老大的身份,至此切换完成。
二、总结
当主节点被判断为客观下线后,各个哨兵节点会进行协商,先选举出一个哨兵节点(Raft实算法),并由该哨兵节点推送故障迁移,选出新的master。
注意:
- 当启动哨兵模式之后,如果你的master服务器宕机之后,哨兵自动会在从redis服务器里面 投票选举一个master主服务器出来;这个主服务器也可以进行读写操作!
- 如果之前宕机的主服务器已经修好,可以正式运行了。那么这个服务器只能进行读的操作,也就说前大哥现在变为小弟了。
三、日志查看
 四、Raft算法
四、Raft算法