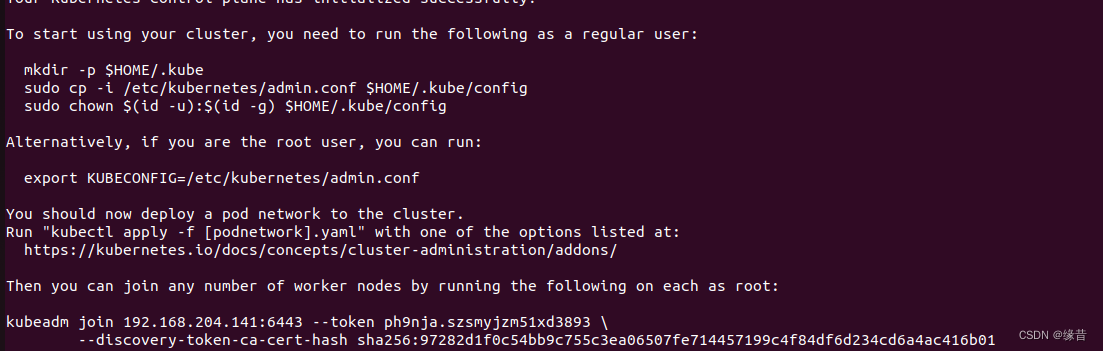
笔记整理:邹铭辉,天津大学硕士,研究方向为知识图谱
链接:https://aclanthology.org/2022.emnlp-main.743
动机
知识图谱通常被用作常识问答的信息来源,同时也可以用来解释模型对答案的选择。纳入图谱中事实信息的一个常见方式是:将图谱信息与问题分别编码,然后将两种表示结合起来用于答案选择。在本文中,作者认为不能从此类模型中提取基于图的、高度忠诚的解释。因为这样的解释将不包括编码器在编码问题时所做的推理,是不完整的。本文用一种新的忠诚度代理测量方法证实了这一理论,并提出了两个架构变化来解决这一问题。本文的发现为开发基于图的忠诚的解释架构指出了一条前进的道路。
亮点
本文的亮点主要包括:
(1) 从理论和实验上分析验证了现有的基于图的解释在忠诚度上存在缺陷,其主要原因在于现有模型在推理过程中主要依赖于文本编码器而非图编码器。
(2) 提出了两个架构变化尝试验证并解决基于图的解释不完整的问题,实验结果表明了这种架构变化的有效性。
模型结构
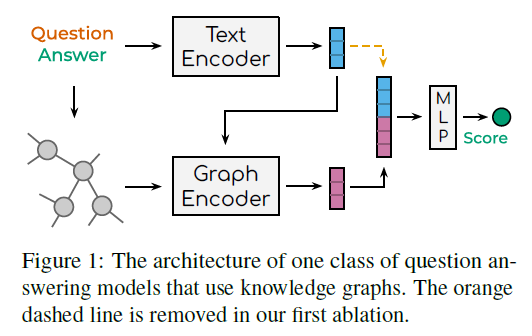
本文关注于一类结合了文本编码器和图编码器的模型(如图1所示)。在这类模型中,解释可以自然的表示成输入图中一些边的集合(如图2所示),并且可以用来理解模型在选择答案时使用了哪些事实。具体来说,本文选择了两个模型进行测试:MHGRN和QA-GNN。这两个模型的高层操作是可比较的,并且能够代表其他具有相同结构的模型。

在上述两个模型中,文本编码器基于RoBERTa-Large进行构建,它以问题和候选答案作为问题上下文进行语义编码,此外问题上下文还会被用于从大规模知识图中抽取出一个至多包含200个节点的子图(有时称为模式图)。图编码器基于GNN进行构建,它针对抽取出的子图进行语义编码。这两个模型的一个关键区别是GNN的结构。在MHGRN的每一层,通过子图找到以每个节点为终点的多条路径,对其进行编码,然后汇集起来形成新的节点嵌入。QA-GNN则通过聚合直接邻居的信息来更新每一层的节点。此外,这两个模型还以不同的方式使用每层的文本嵌入,在MHGRN中,当为每个节点创建新的嵌入时,它被用来计算每条路径的相关性;在QA-GNN中,一个用这个文本嵌入初始化的伪节点会被添加到图中,从而允许文本嵌入参与与其他节点的信息传递。
最后,为了给每个候选答案打分,问题上下文表示和子图表示首先被拼接到一起,然后利用MLP网络进行打分。
解释的忠诚度问题
本文认为此类模型生成的解释的忠实度低是因为模型使用文本和图嵌入来选择候选答案,但解释仅从图编码器中提取。因此,这些解释无法完全描述用于回答问题的事实,因为文本编码器可能也提供了相关信息,而图结构的解释必然是不完整的。
为了增强解释的忠诚度,本文从以下三个方面进行改变:
(1)使用文本嵌入
在模型最后的MLP网络中,文本嵌入直接用于预测候选答案的得分(即图1中橙色虚线)。这是绕过图编码器最明显的方式,本文认为如果要用基于图的解释来理解模型,就必须去除文本嵌入。
(2)冻结文本编码器
另一种最小化文本编码器影响的方法是在训练期间将其冻结。在这种情况下,模型仍然可以生成问题上下文的有意义的表示,同时只需要最少的任务特定信息。使用这些表示而不经过微调必然会增加忠实性,因为此时图编码器在推理过程中占据了更高的地位。
(3)可解释性技术
尽管不是本文的研究重点,评估解释抽取技术的忠诚度同样是十分重要的。MHGRN和QA-GNN模型都是利用注意力值来选择子图中的一些边作为解释,但是目前尚不清楚这种注意力是否能够忠诚的反应模型推理的过程。因此,可以考虑使用一些专门为忠诚度设计的方法进行替代,例如GraphMask。
除了理论上的分析,本文还提出了一种代理测量方法用于评价本文提出改进方法的影响。首先,本文提出了一个假设:如果能够从图编码器中抽取出忠诚的解释,那么在输入上的巨大修改将会对模型行为产生巨大影响。如果这一假设不成立,则表明推理过程是在模型不同的部分上进行的,此时,基于图的解释将不忠诚于整个模型的工作过程。具体来说,本文中对图编码器输入所作的修改是在问题之间对模式图进行打乱,使得模式图变得无关紧要。如果推理过程主要是在图编码器上进行的话,经过上述打乱操作,模型的性能将会急剧下降。
实验结果
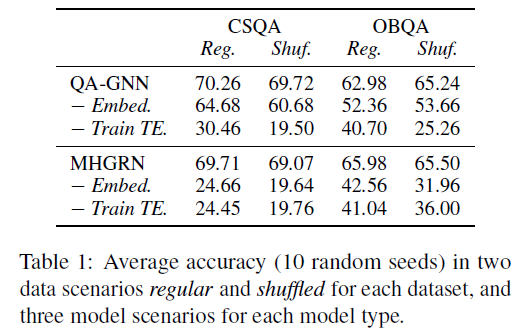
本文将常规图数据和打乱图数据与三种不同的模型进行结合:(1)原始MHGRN和QA-GAN;(2)去除最后MLP网络中的文本嵌入(-Embed);(3)去除文本嵌入的同时冻结文本编码器的参数(-Train TE)。实验结果如表1所示。
(1)原始模型
在所有四种情况下,模型在打乱图数据上准确率都很高,且与常规图数据情况没有显著差异。这与上文中的假设相矛盾,因此这个结果表明此类模型架构几乎在文本编码器上进行了所有的推理。即使在常规场景中,很大一部分推理也可能是在图编码器之外完成。可以得出结论:从图编码器中提取的解释不能反映整个模型的工作原理。
(2)去除文本嵌入
可以看到,除了MHGRN在OBQA数据集上的结果外,其余三组实验设置都在常规与打乱场景下表现出了显著差异,即将图编码器的输入替换成无意义的输入时,模型性能会显著下降。这一实验结果表明,在去除文本嵌入之后,模型在推理过程中更加依赖于图编码器,从而基于图的解释能够增加忠诚于模型的整体行为。
(3)冻结文本编码器
当在去除文本嵌入的同时冻结文本编码器时,可以看到所有四种情况下,模型在常规与打乱场景下都表现出了显著差异。这些结果表明了此时图编码器是对性能影响最大的模型组件,这是检索忠诚解释的理想情况。
总结
本文试验证明了,在MHGRN和QAGNN中,限制预训练文本编码器学习任务的能力会导致模型准确性显著降低。这一结果表明,在此类模型中对性能贡献最大的是文本编码器。此外,本文的发现还有另外一个事实支持:在问题之间重排子图对性能没有显著影响。因此,从图编码器中提取的解释将不忠于模型的整体操作,因为它们不会捕获在文本编码器中完成的实质性推理。更进一步的,本文通过两个变种实验验证了“去除文本嵌入”和“冻结文本编码器”在增强解释忠诚度上的有效性。未来关于忠实解释模型的工作可能会以类似于MHGRN的方式构建他们对文本编码器的使用,因为这种方式更容易生成忠实的解释。此类工作可能会研究如何更好地训练文本编码器来权衡事实的关联性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。