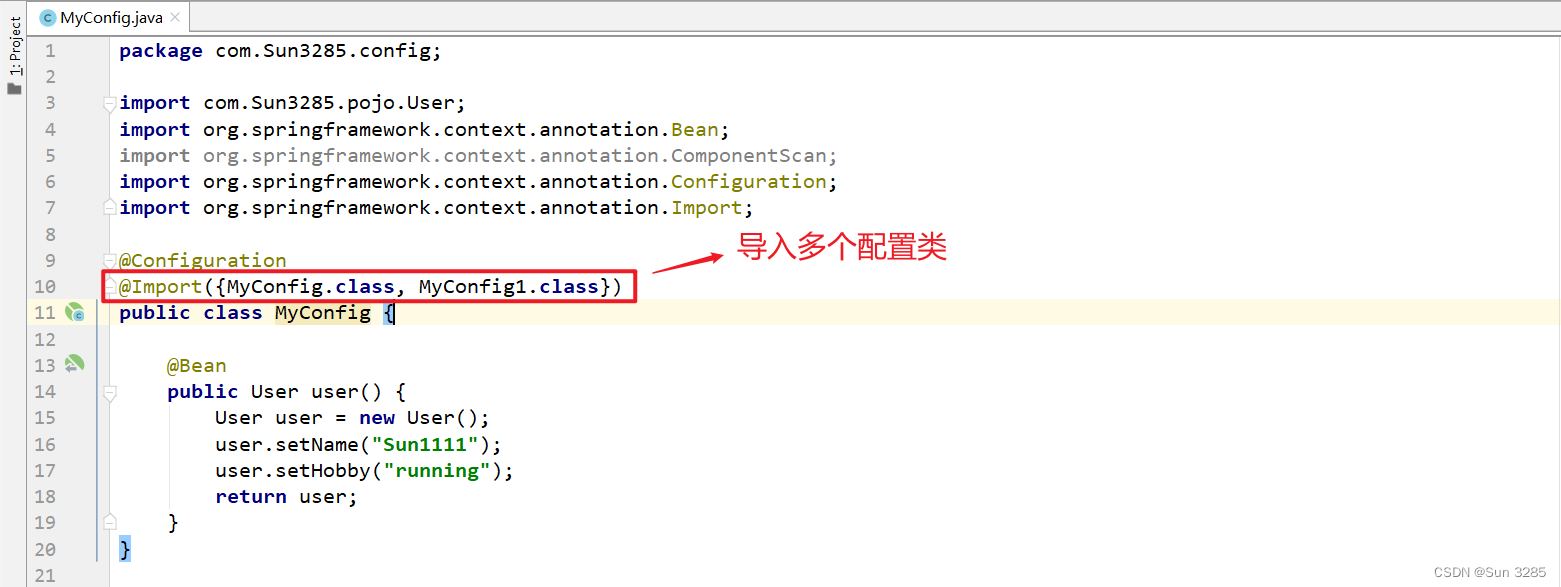
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共800人左右 1 + 2)
以下数据库虽然方法和能力各不相同,但所有这些数据库都允许您在数据所在的地方构建机器学习模型。

对于机器学习将代码保持在数据附近是保持低延迟的必要条件,因为光速限制了传输速度。毕竟,机器学习——尤其是深度学习——往往需要多次遍历所有数据(每次遍历称为一个epoch)。
对于非常大的数据集来说,理想的情况是在数据已经存在的地方构建模型,这样就不需要进行大量数据传输。有几个数据库在一定程度上支持这种功能。那么自然接下来的问题是,哪些数据库支持内部机器学习,它们是如何实现的呢?我将按字母顺序讨论这些数据库。
亚马逊Redshift 亚马逊Redshift是一种托管的、可达到PB级别的数据仓库服务,旨在使您使用现有的商业智能工具分析所有数据变得简单且具有成本效益。它针对从几百GB到PB或更大的数据集进行了优化,每年每TB的成本不到1000美元。
亚马逊Redshift ML旨在让SQL用户能够通过使用SQL命令轻松创建、训练和部署机器学习模型。Redshift SQL中的CREATE MODEL命令定义了用于训练的数据和目标列,然后通过同一区域的加密Amazon S3存储桶将数据传递给Amazon SageMaker Autopilot进行训练。
Amazon Redshift ML 旨在让 SQL 用户能够轻松地使用 SQL 命令创建、训练和部署机器学习模型。Redshift SQL 中的 CREATE MODEL 命令定义了用于训练的数据和目标列,然后通过位于同一区域的加密 Amazon S3 存储桶将数据传输给 Amazon SageMaker Autopilot 进行训练。
在 AutoML 训练之后,Redshift ML 会编译最优模型并将其注册为 Redshift 集群中的预测 SQL 函数。接下来,您可以通过在 SELECT 语句中调用预测函数来使用该模型进行推断。
BlazingSQL 是一个基于 RAPIDS 生态系统构建的 GPU 加速 SQL 引擎;它既存在于开源项目中,也提供付费服务。RAPIDS 是一个开源软件库和 API 套件,由 Nvidia 孵化,使用 CUDA 并基于 Apache Arrow 列式内存格式。RAPIDS 的一部分,CuDF 是一个类 Pandas 的 GPU DataFrame 库,用于加载、连接、聚合、过滤和其他数据操作。
Dask 是一个开源工具,可以将 Python 包扩展到多台机器上。Dask 能够将数据和计算分布在多个 GPU 上,无论是在同一系统中还是在多节点集群中。Dask 可与 RAPIDS cuDF、XGBoost 和 RAPIDS cuML 集成,实现 GPU 加速的数据分析和机器学习。
摘要:BlazingSQL 可以在 Amazon S3 的数据湖上运行 GPU 加速查询,将得到的 DataFrames 传递给 cuDF 进行数据操作,最后使用 RAPIDS XGBoost 和 cuML 进行机器学习,以及与 PyTorch 和 TensorFlow 进行深度学习。
Brytlyt 是一个基于浏览器的平台,具备在数据库内进行 AI 和深度学习能力。Brytlyt 将 PostgreSQL 数据库、PyTorch、Jupyter Notebooks、Scikit-learn、NumPy、Pandas 和 MLflow 集成到一个无服务器平台中,作为三个 GPU 加速产品:数据库、数据可视化工具和使用笔记本的数据科学工具。
Brytlyt 可以与任何具有 PostgreSQL 连接器的产品连接,包括诸如 Tableau 的 BI 工具和 Python。它支持从外部数据文件(如 CSV)以及由 PostgreSQL 外部数据包装器(FDWs)支持的外部 SQL 数据源加载和获取数据。后者包括 Snowflake、Microsoft SQL Server、Google Cloud BigQuery、Databricks、Amazon Redshift 和 Amazon Athena 等。
作为具有并行处理连接功能的 GPU 数据库,Brytlyt 可以在几秒钟内处理数十亿行数据。Brytlyt 在电信、零售、石油和天然气、金融、物流以及 DNA 和基因组等领域都有应用。
总结:通过集成 PyTorch 和 Scikit-learn,Brytlyt 可以支持针对其数据内部运行的深度学习和简单机器学习模型。GPU 支持和并行处理意味着所有操作相对较快,尽管针对数十亿行数据训练复杂的深度学习模型当然需要一些时间。
Google Cloud BigQuery BigQuery 是 Google Cloud 的托管、PB 级数据仓库,可让您在近乎实时的情况下对大量数据进行分析。BigQuery ML 允许您使用 SQL 查询在 BigQuery 中创建和执行机器学习模型。
BigQuery ML 支持用于预测的线性回归;用于分类的二元及多类逻辑回归;用于数据分割的 K-均值聚类;用于创建产品推荐系统的矩阵分解;用于执行时间序列预测(包括异常、季度和节假日)的时间序列;XGBoost 分类和回归模型;基于 TensorFlow 的深度神经网络分类和回归模型;AutoML 表格;以及 TensorFlow 模型导入。您可以将模型与来自多个 BigQuery 数据集的数据一起用于训练和预测。BigQuery ML 不会从数据仓库中提取数据。您可以在 CREATE MODEL 语句中使用 TRANSFORM 子句,通过 BigQuery ML 进行特征工程。
总结:BigQuery ML 将许多 Google Cloud 机器学习功能引入 BigQuery 数据仓库,并采用 SQL 语法,无需从数据仓库中提取数据。
IBM Db2 WarehouseIBM Db2 Warehouse on Cloud 是一个托管的公共云服务。您还可以在自己的硬件上或私有云中部署 IBM Db2 Warehouse。作为一个数据仓库,它包括诸如内存数据处理和列式表格等用于在线分析处理的功能。其 Netezza 技术提供了一套强大的分析工具,旨在有效地将查询带入数据。一系列库和函数可以帮助您获得所需的精确洞察。
Db2 Warehouse 支持 Python、R 和 SQL 的数据库内机器学习。IDAX 模块包含分析存储过程,包括方差分析、关联规则、数据转换、决策树、诊断度量、离散化和矩、K-均值聚类、k-最近邻、线性回归、元数据管理、朴素贝叶斯分类、主成分分析、概率分布、随机抽样、回归树、顺序模式和规则,以及参数和非参数统计。
IBM Db2 Warehouse 包括一整套数据库内 SQL 分析工具,包括一些基本的机器学习功能,以及对 R 和 Python 的数据库内支持。
Kinetica Kinetica 流式数据仓库将历史和流式数据分析与地理位置智能和 AI 结合在一个平台中,可通过 API 和 SQL 访问。Kinetica 是一个非常快速的、分布式的、列式的、内存优先的 GPU 加速数据库,具有过滤、可视化和聚合功能。
Kinetica 将机器学习模型和算法与您的数据集成,以实现大规模实时预测分析。它允许您简化数据管道以及分析、机器学习模型和数据工程的生命周期,并通过流计算特征。Kinetica 提供了一个基于 GPU 加速的完整机器学习生命周期解决方案:托管的 Jupyter 笔记本、通过 RAPIDS 进行模型训练,以及在 Kinetica 平台中进行自动模型部署和推理。
总结:Kinetica 提供了一个基于 GPU 加速的完整数据库内机器学习生命周期解决方案,并可以从流式数据中计算特征。
Microsoft SQL Server Microsoft SQL Server 机器学习服务支持在 SQL Server RDBMS 中的 R、Python、Java、PREDICT T-SQL 命令以及 rx_Predict 存储过程,以及在 SQL Server 大数据集群中的 SparkML。在 R 和 Python 语言中,Microsoft 包含了多个用于机器学习的软件包和库。您可以将训练好的模型存储在数据库中或外部。Azure SQL 托管实例支持预览版的 Python 和 R 的机器学习服务。
Microsoft R 具有扩展功能,允许它处理来自磁盘以及内存中的数据。SQL Server 提供了一个扩展框架,使得 R、Python 和 Java 代码可以使用 SQL Server 数据和函数。SQL Server 大数据集群在 Kubernetes 中运行 SQL Server、Spark 和 HDFS。当 SQL Server 调用 Python 代码时,它可以反过来调用 Azure 机器学习,并将生成的模型保存在数据库中以用于预测。
总结:目前版本的 SQL Server 能够在多种编程语言中训练和推断机器学习模型。
Oracle 数据库 Oracle Cloud Infrastructure(OCI)Data Science 是一个托管的、无服务器的平台,供数据科学团队使用 Oracle Cloud Infrastructure(包括 Oracle Autonomous Database 和 Oracle Autonomous Data Warehouse)构建、训练和管理机器学习模型。它包括由开源社区开发的以 Python 为中心的工具、库和包,以及支持预测模型端到端生命周期的 Oracle Accelerated Data Science(ADS)库:
数据获取、分析、准备和可视化 特征工程 模型训练(包括 Oracle AutoML) 模型评估、解释和解读(包括 Oracle MLX) 将模型部署到 Oracle Functions OCI Data Science 与 Oracle Cloud Infrastructure 栈的其他部分集成,包括 Functions、Data Flow、Autonomous Data Warehouse 和 Object Storage
VerticaVertica Analytics Platform 是一个可扩展的列式存储数据仓库。它有两种运行模式:企业版,将数据本地存储在组成数据库的节点的文件系统中;EON 版,为所有计算节点共同存储数据。
Vertica 使用大规模并行处理来处理 PB 级数据,并使用数据并行进行内部机器学习。它包括八个用于数据准备的内置算法、三个回归算法、四个分类算法、两个聚类算法、几个模型管理功能,以及导入在其他地方训练的 TensorFlow 和 PMML 模型的能力。一旦您拟合或导入了一个模型,就可以将其用于预测。Vertica 还允许用户使用 C++、Java、Python 或 R 编程定义扩展。训练和推理都使用 SQL 语法。
总结:Vertica 内置了一整套不错的机器学习算法,并且可以导入 TensorFlow 和 PMML 模型。它不仅可以从导入的模型进行预测,还可以使用自己的模型进行预测。
MindsDB 如果您的数据库尚未支持内部机器学习,您可能可以使用 MindsDB 来添加该功能,因为它可以与半打数据库和五个 BI 工具集成。支持的数据库包括 MariaDB、MySQL、PostgreSQL、ClickHouse、Microsoft SQL Server 和 Snowflake,MongoDB 集成正在进行中,而且在 2021 年底之前承诺会集成流式数据库。目前支持的 BI 工具包括 SAS、Qlik Sense、Microsoft Power BI、Looker 和 Domo。
MindsDB 具有 AutoML、AI 表和可解释 AI(XAI)功能。您可以从 MindsDB Studio、SQL INSERT 语句或 Python API 调用中启动 AutoML 训练。训练可以选择使用 GPU,并可以选择创建时间序列模型。
您可以将模型保存为数据库表,并从 SQL SELECT 语句、MindsDB Studio 或 Python API 调用针对已保存模型进行调用。您可以从 MindsDB Studio 评估、解释和可视化模型质量。
您还可以将MindsDB Studio和Python API连接到本地和远程数据源。此外,MindsDB还提供了一个简化的深度学习框架——Lightwood,它基于PyTorch运行。
摘要:MindsDB为许多缺乏内置机器学习支持的数据库带来了有用的机器学习功能。
越来越多的数据库支持在内部进行机器学习。具体的机制各有不同,有些比其他更强大。然而,如果您拥有大量数据,以至于您可能必须在抽样的子集上进行拟合模型,那么上面列出的八个数据库中的任何一个——以及其他借助MindsDB的数据库——都可能帮助您在不产生严重数据导出开销的情况下从完整数据集构建模型。