开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共790人左右 1 + 2)
最近遇到一个难题,关于POSTGRESQL 的Tigger问题,实际上我是十分不愿意在数据库中使用tigger, 管理的问题,性能的问题,以及可能在你不清晰你部署了tigger 的情况下,触发到底会发生什么的问题。但实际的问题中,还是会被逼无奈的使用TIGGER ,所以本期的说说TIGGER 我们怎么用。
我们先熟悉一下TRIGGER 的工作范围和触发场景,实际上在使用TRIGGER 上还是有一些门道的
1 before or after 这是一个针对事件触发次序的设置,触发分为,事前触发和事后触发,事前触发为在实际操作数据行或表时,需先对触发器的操作进行相应,相应后才能进行触发触发器的操作。
这个对于系统的性能消耗较大,但对于一些情况下是必须的,如你想捕捉触发某条删除操作的语句是什么那么你需要在操作DELETE的操作前,就对pg_stat_activity 的操作进行一个捕捉,而不是放到AFTER 操作,否则大概率你将一无所获。
而 after 相对于事务commit了,或在事务中的这个DML操作完成了,那么就可以触发这个操作了,相对于before ,after 会对于系统的性能消耗相对小一些,当然这也根据你的触发TIGGER 后的操作的工作有关。

2 FOR EACH ROW or FOR EACH STATEMENT
这个部分是第二个针对触发器性能影响的关键,FOR EACH ROW 在触发后,会对于语句操作的每一行都进行触发器的操作,这样的性能消耗要大,而反过来如果使用FOR EACH STATEMENT 的操作,将对于系统的影响相对小,语句只触发一次触发器的操作。
所以在建立TRIGGER 时,正确选择是for each row , or for each statement 是重要的。
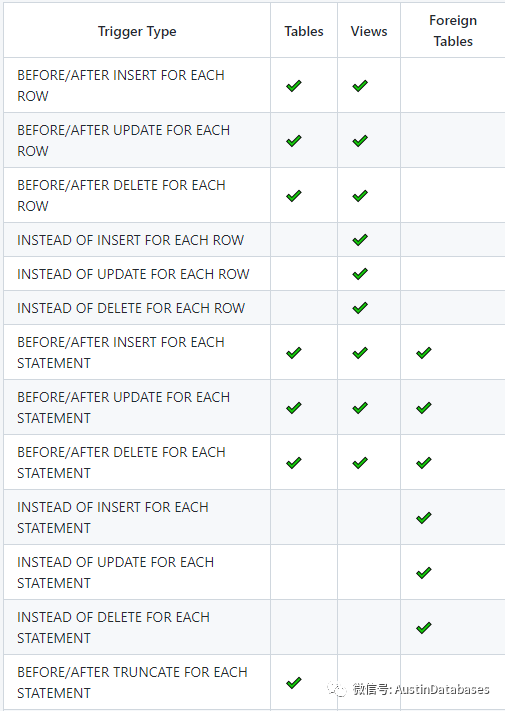
同时需要注意的是在表上建立的约束,也是属于触发器,约束也是after row 类型的触发器。
下面我们建立一个关于删除表中数据时就触发对于当前数据库运行时的语句进行snapshot的trigger.
SELECT
tgname as "Trigger Name",
tgenabled as "Status",
tgisinternal as "Is Internal",
proname as "Function Name",
n.nspname as "Schema",
pg_get_triggerdef(t.oid) as "Trigger Definition"
FROM pg_trigger t
JOIN pg_class c ON t.tgrelid = c.oid
JOIN pg_namespace n ON c.relnamespace = n.oid
JOIN pg_proc p ON t.tgfoid = p.oid
where tgisinternal = 'f';

SELECT proname, pg_get_function_arguments(oid) as args, pg_get_function_result(oid) as result_type,pg_get_functiondef(oid) as "Source Code"FROM pg_catalog.pg_proc
WHERE pronamespace = (SELECT oid FROM pg_namespace WHERE nspname = 'public') and proname like 'delete%';
通过定义函数,并且将函数在trigger 中进行调用,这里需要说明如果是trigger 调用的函数如何去写。
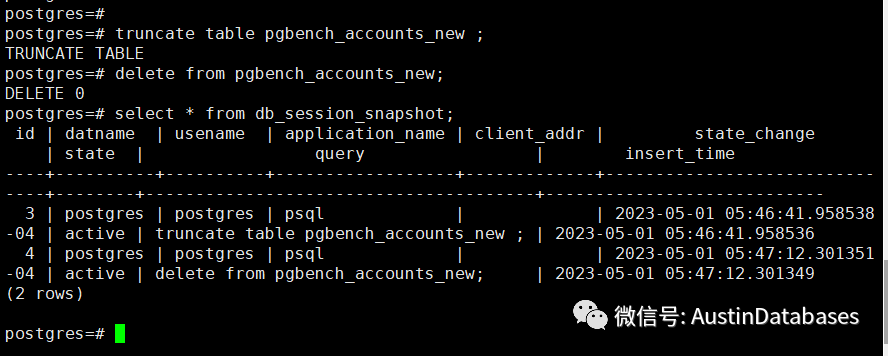
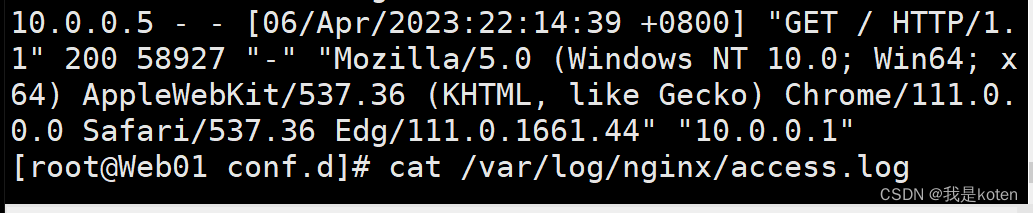
上图为尝试对这个表进行delete 操作或truncate 操作等等,我们均可以通过触发器进行后续操作的记录session的表进行,可以发现操作的语句。
目前看这个方案是可以捕捉到对于特定表进行delete ,truncate 触发记录的工作。
这里需要注意的是触发器函数,虽然都是函数,但是在使用触发器时是需要定义触发器函数的。首先在trigger 中使用的函数是不需要返回参数的,
所以在函数中的return 返回的变量是特殊的指定的
NEW
数据类型是RECORD;该变量为行级触发器中的INSERT/UPDATE操作保持新数据行。在语句级别的触发器以及DELETE操作,这个变量是null。
OLD
数据类型是RECORD;该变量为行级触发器中的UPDATE/DELETE操作保持新数据行。在语句级别的触发器以及INSERT操作,这个变量是null。
所以这里我们选择的return 是 NEW ,这里还有一个问题是采用的触发方式是before ,before 引发的触发操作,可以返回空,来让触发器跳过对于剩下行的操作,在DELETE中的常用方法是返回OLD.
说到这里,可能还有同学不明白 NEW 和 OLD 的用法,我们用下面的一个例子来讲明白,在什么时间用NEW 在什么时间用OLD
CREATE TRIGGER insert_user_trigger
BEFORE INSERT ON users
FOR EACH ROW
EXECUTE FUNCTION set_created_at();
CREATE OR REPLACE FUNCTION set_created_at()
RETURNS TRIGGER AS $$
BEGIN
NEW.created_at = NOW();
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
上面的这个例子的意思是,建立一个插入数据的trigger ,在插入数据的时候,针对这一行数据的字段 created_at 插入时间
所以这里使用了 new 的方式来进行相关引用插入的新行,所以以这个例子为目标,则如果是删除数据,则一般是适应old ,对原有的行进行一些处理,或根本不处理等。