文章目录
- 图
- 1.图的基本概念
- 2.图的存储结构
- 3.邻接矩阵
- 3.1邻接矩阵的优缺点
- 3.2邻接矩阵的实现
- 4.邻接表
- 4.1邻接表的实现
- 5.图的遍历
- 5.1广度优先遍历
- 5.2深度优先遍历
- 5.3如何遍历不连通的图?
图
1.图的基本概念
图是由顶点集合及顶点间的关系组成的一种数据结构:G = (V, E),其中:
- 顶点集合V = {x|x属于某个数据对象集}是有穷非空集合;
- E = {(x,y)|x,y属于V}或者E = {<x, y>|x,y属于V && Path(x, y)}是顶点间关系的有穷集合,也叫
做边的集合。 - (x, y)表示x到y的一条双向通路,即(x, y)是无方向的;Path(x, y)表示从x到y的一条单向通路,即Path(x, y)是有方向的。
图相关的概念
- 顶点和边:图中结点称为顶点,第i个顶点记作vi。两个顶点vi和vj相关联称作顶点vi和顶点vj之间有一条边,图中的第k条边记作ek,ek = (vi,vj)或<vi,vj>。
- 有向图和无向图:在有向图中,顶点对<x, y>是有序的,顶点对<x,y>称为顶点x到顶点y的一条边(弧),<x, y>和<y, x>是两条不同的边,比如下图G3和G4为有向图;在无向图中,顶点对(x, y)是无序的,顶点对(x,y)称为顶点x和顶点y相关联的一条边,这条边没有特定方向,(x, y)和(y,x)是同一条边,比如下图G1和G2为无向图。注意:无向边(x, y)等于有向边<x, y>和<y, x>。
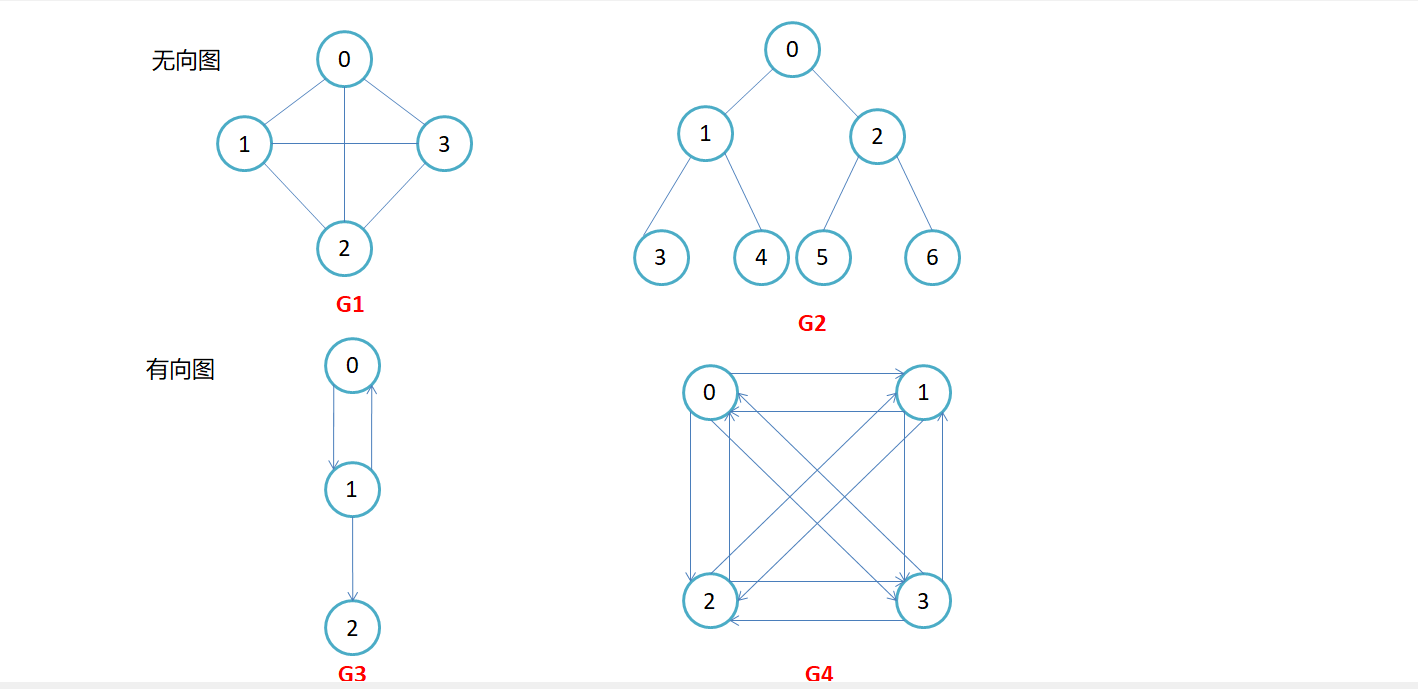
完全图
- 无向完全图:即图中每两个顶点都有边。在有n个顶点的无向图中,若有n * (n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图 。
- 有向完全图:在n个顶点的有向图中,若有n * (n-1)条边,即任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图。
顶点的度
- 顶点的度:顶点v的度是指与它相关联的边的条数,记作deg(v)。在有向图中,顶点的度等于该顶点的入度与出度之和。在无向图中顶点的度等于该顶点的入度和出度,即dev(v)=indev(v) = outdev(v)。
路径
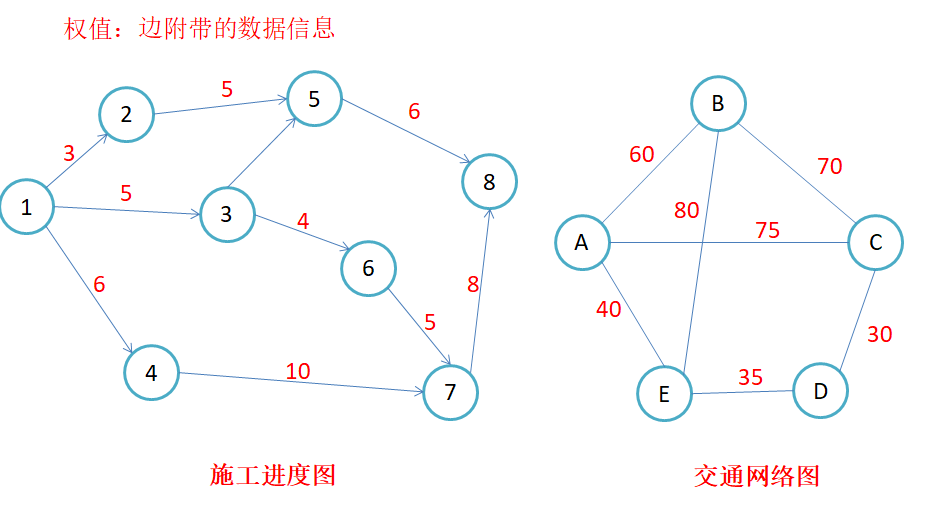
- 路径:在图G = (V, E)中,若从顶点vi出发有一组边使其可到达顶点vj,则称顶点vi到顶点vj的顶点序列为从顶点vi到顶点vj的路径
- 路径长度:对于不带权的图,一条路径的路径长度是指该路径上的边的条数;**对于带权的图,一条路径的路径长度是指该路径上各个边权值的总和。 **
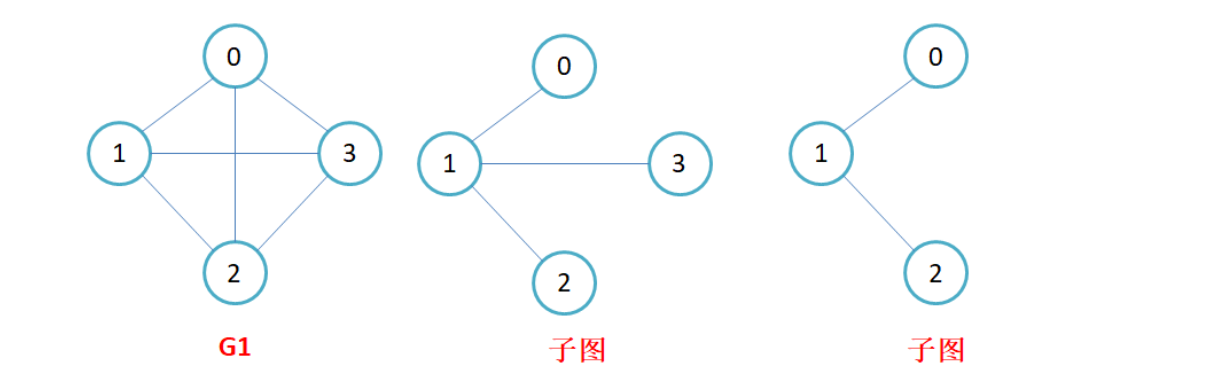
子图
子图:设图G = {V, E}和图G1 = {V1,E1},若V1属于V且E1属于E,则称G1是G的子图。
**连通图:**在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任
意一对顶点都是连通的,则称此图为连通图。
**强连通图:**在有向图中,若在每一对顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条从vj
到vi的路径,则称此图是强连通图
生成树:一个连通图的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点
和n-1条边。
2.图的存储结构
图的存储方式主要有两种,一种叫邻接矩阵,一种叫做邻接表。
3.邻接矩阵
因为节点与节点之间的关系就是连通与否,即为0或者1,因此邻接矩阵(二维数组)即是:先用一
个数组将定点保存,然后采用矩阵来表示节点与节点之间的关系。
无向图

有向图

注意:
无向图的邻接矩阵是一个对称图;第i行(列)元素之和,就是顶点i的度。有向图的邻接矩阵则不一
定是对称的,第i行(列)元素之后就是顶点i 的出(入)度。
带权图
对于有权值的图:边的关系就用权值代替,如果两个顶点不通,则使用无穷大代替。
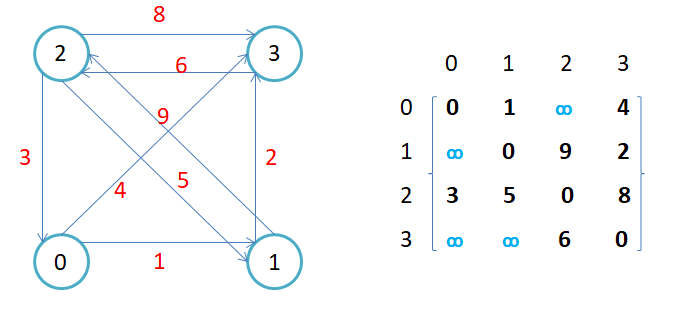
3.1邻接矩阵的优缺点
优点:
- 能够快速知道两个顶点是否连通。
缺点:
- 顶点比较多,边比较少时,矩阵中存储了大量的0成为系数矩阵,比较浪费空间,并且要求两个节点之间的路径不是很好求。
3.2邻接矩阵的实现
基本接口框架:包括构造函数,边的添加函数,返回下标等
namespace matrix
{
template <class V, class W, W MAX_W = INT64_MAX, bool Direction = false>
class Graph
{
struct edge
{
size_t _srci; //起点下标
size_t _dsti; //指向下标
W _w; //权值
edge(size_t srci, size_t dsti, W w) : _srci(srci), _dsti(dsti), _w(w)
{
}
bool operator>(const edge &e) const
{
return _w > e._w;
}
};
typedef Graph<V, W, MAX_W, Direction> self;
public:
Graph() = default;
//构造函数
Graph(const V *v, size_t n)
{
_vertexs.reserve(n);
for (size_t i = 0; i < n; i++)
{
_vertexs.push_back(v[i]);
_indexmap[v[i]] = i;
}
//为存储边的矩阵开辟空间
_matrix.resize(n);
for (size_t i = 0; i < _matrix.size(); i++)
{
_matrix[i].resize(n, MAX_W);
}
}
//返回顶点的下标
size_t GetVertexIndex(const V &v);
//边的添加函数
void addedge(const V &src, const V &dst, const W &w);
//打印邻接矩阵函数
void Print();
private:
unordered_map<V, int> _indexmap; //记录顶点和下标的映射关系
vector<V> _vertexs; // 顶点集合的集合
vector<vector<W>> _matrix; // 存储边集合的矩阵
};
}
返回顶点的下标
顶点和顶点下标的映射关系,由一个Hash表存储。可以直接访问Hash表得到顶点的下标
//获取顶点的下标API
size_t GetVertexIndex(const V &v)
{
auto it = _indexmap.find(v);
if (it != _indexmap.end())
{
return _indexmap[v];
}
else
{
std::cout << "不存在这样的节点" << std::endl;
return -1;
}
}
添加边API
添加边时,需要判断图是否为有向图。如果是一个无向图,那么天需要添加两次。
void _addedge(size_t srci, size_t dsti, const W &w)
{
_matrix[srci][dsti] = w;
if (Direction == false)
{
_matrix[dsti][srci] = w;
}
}
void addedge(const V &src, const V &dst, const W &w)
{
size_t srci = GetVertexIndex(src);
size_t dsti = GetVertexIndex(dst);
assert(srci != -1);
assert(dsti != -1);
_addedge(srci, dsti, w);
}
打印临界矩阵
如果两个顶点直接没有边,就使用*表示
void Print()
{
//先打印顶点
for (int i = 0; i < _vertexs.size(); i++)
{
cout << "[" << i << "]"
<< "->" << _vertexs[i]<<endl;
}
cout << endl;
// 横下标
cout << " ";
for (size_t i = 0; i < _vertexs.size(); ++i)
{
// cout << i << " ";
printf("%4d", i);
}
cout << endl;
for (size_t i = 0; i < _matrix.size(); ++i)
{
cout << i << " "; // 竖下标
for (size_t j = 0; j < _matrix[i].size(); ++j)
{
// cout << _matrix[i][j] << " ";
if (_matrix[i][j] == MAX_W)
{
// cout << "* ";
printf("%4c", '*');
}
else
{
// cout << _matrix[i][j] << " ";
printf("%4d", _matrix[i][j]);
}
}
cout << endl;
}
cout << endl;
}
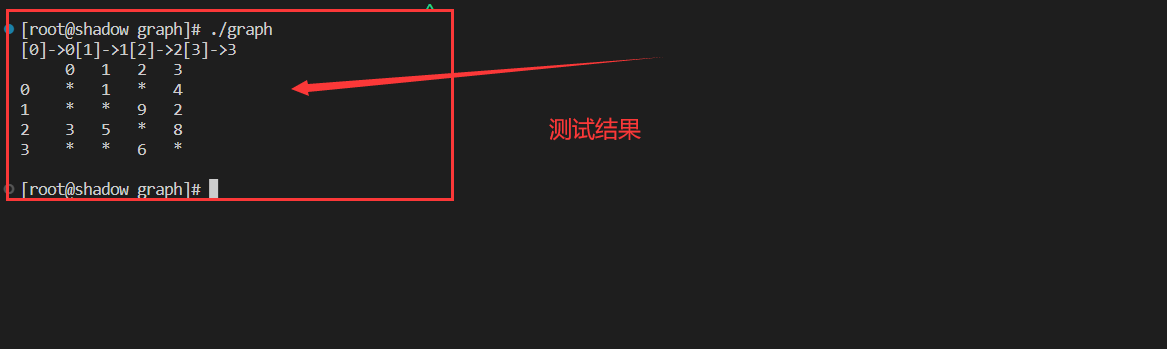
接口测试结果
void test_matrix(){
matrix::Graph<char, int, INT64_MAX, true> g("0123", 4);
g.addedge('0', '1', 1);
g.addedge('0', '3', 4);
g.addedge('1', '3', 2);
g.addedge('1', '2', 9);
g.addedge('2', '3', 8);
g.addedge('2', '1', 5);
g.addedge('2', '0', 3);
g.addedge('3', '2', 6);
g.Print();
}
int main()
{
test_matrix();
return 0;
}
4.邻接表
邻接表:使用数组表示顶点的集合,使用链表表示边的关系。
无向图邻接表
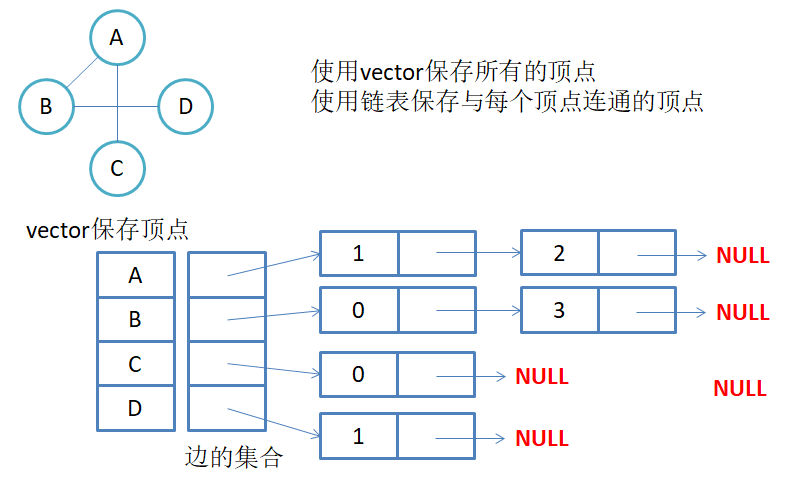
**注意:**无向图中同一条边在邻接表中出现了两次。如果想知道顶点vi的度,只需要知道顶点vi边链表集合中结点的数目即可。
有向图邻接表
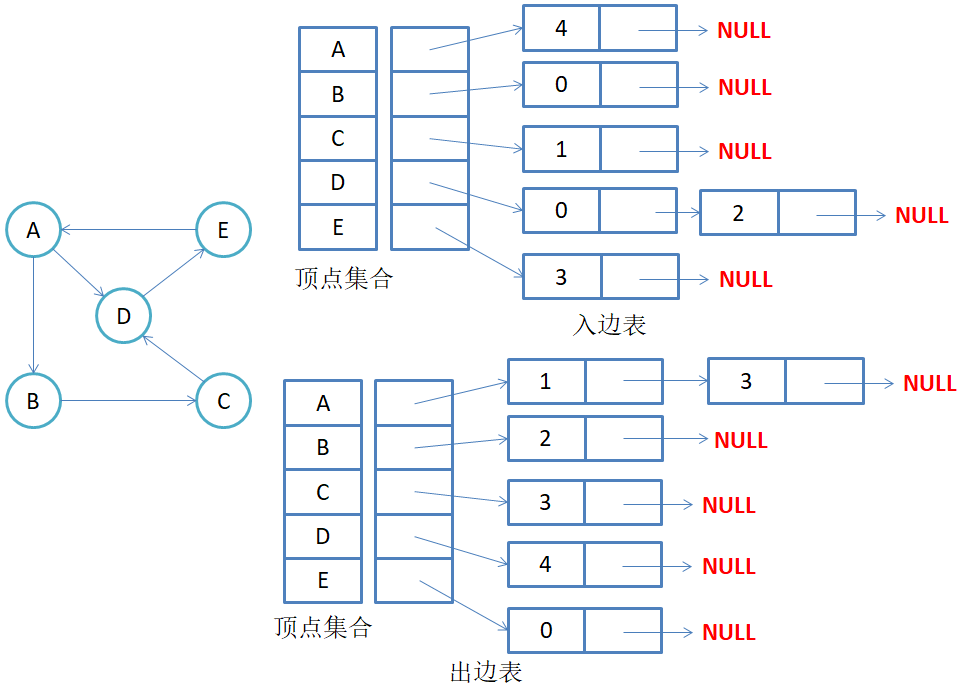
**注意:**有向图中每条边在邻接表中只出现一次,与顶点vi对应的邻接表所含结点的个数,就是该顶点的出度,也称出度表,要得到vi顶点的入度,必须检测其他所有顶点对应的边链表,看有多少边顶点的dst取值是i。
4.1邻接表的实现
基本接口框架:包括构造函数,边的添加函数,返回下标等;
namespace link_table
{
template <class V, class W, W MAX_W = INT64_MAX, bool Direction = false>
class Graph
{
typedef Graph<V, W, MAX_W, Direction> self;
struct edge
{
//由于是链表,起点就是当前点,所以一般都省略
// int _srci;
size_t _dsti; //目标点
W _w; //权值
//用一个链表将于该顶点相连的顶点连接起来
edge *_next;
edge(size_t dsti, const W& w)
: _dsti(dsti), _w(w), _next(nullptr)
{
}
};
public:
//构造函数
Graph() = default;
Graph(const V *a, size_t n)
{
_vertexs.reserve(n);
//添加顶点
for (size_t i = 0; i < n; i++)
{
_vertexs.push_back(a[i]);
_indexmap[a[i]] = i;
}
_tables.resize(n, nullptr);
}
//获取顶点的下标
size_t GetVertexIndex(const V &v);
//添加边的API
void addedge(const V &src, const V &dst, const W &w);
//打印接口API
void Print();
private:
unordered_map<V, int> _indexmap; //记录顶点和下标的映射关系
vector<V> _vertexs; // 顶点集合的集合
vector<edge *> _tables; //邻接表
};
};
获取顶点的下标
顶点和顶点下标的映射关系,由一个Hash表存储。可以直接访问Hash表得到顶点的下标。
//获取顶点的下标
size_t GetVertexIndex(const V &v)
{
auto it = _indexmap.find(v);
if (it != _indexmap.end())
{
return _indexmap[v];
}
else
{
std::cout << "不存在这样的节点" << std::endl;
return -1;
}
}
添加边
//添加边
void addedge(const V &src, const V &dst, const W &w)
{
size_t srci = GetVertexIndex(src);
size_t dsti = GetVertexIndex(dst);
//头插的方式
edge *head = _tables[srci];
edge *eg = new edge(dsti, w);
eg->_next = head;
_tables[srci] = eg;
//如果是无向图
if (Direction == false)
{
edge *eg = new edge(srci, w);
eg->_next = _tables[dsti];
_tables[dsti] = eg;
}
}
打印邻接表
void Print()
{
//打印顶点
for (size_t i = 0; i < _vertexs.size(); i++)
{
cout << "[" << i << "]"
<< "->" << _vertexs[i] << endl;
}
//打印边
for (size_t i = 0; i < _tables.size(); i++)
{
cout << _vertexs[i] << "[ " << i << "]->";
edge *cur = _tables[i];
while (cur)
{
cout << "[" << _vertexs[cur->_dsti] << ":" << cur->_dsti << ":" << cur->_w << "]->";
cur = cur->_next;
}
cout << "nullptr" << endl;
}
}
测试邻接表的实现
void test_table()
{
string a[] = {"张三", "李四", "王五", "赵六"};
link_table::Graph<string, int> g1(a, 4);
g1.addedge("张三", "李四", 100);
g1.addedge("张三", "王五", 200);
g1.addedge("王五", "赵六", 30);
g1.Print();
}
int main()
{
test_table();
return 0;
}

5.图的遍历
图的遍历有两种方式,一种是广度优先遍历(BFS),另一种是深度优先遍历(DFS)。下面以邻接矩阵为例,实现图的广度优先遍历和深度优先遍历。
5.1广度优先遍历
比如现在你需要找你的钥匙,有三个抽屉,东西在哪个抽屉不清楚,现在要将其找到,广度优先遍历的做法是:
- 先将三个抽屉打开,在三个抽屉的最外层找一遍
- 依次打开三个抽屉的第二层,再找一遍。
- 如果没有找到,依次打开第三个抽屉的第三层,再找一边…
- 重复上面的操作,直到找到钥匙…
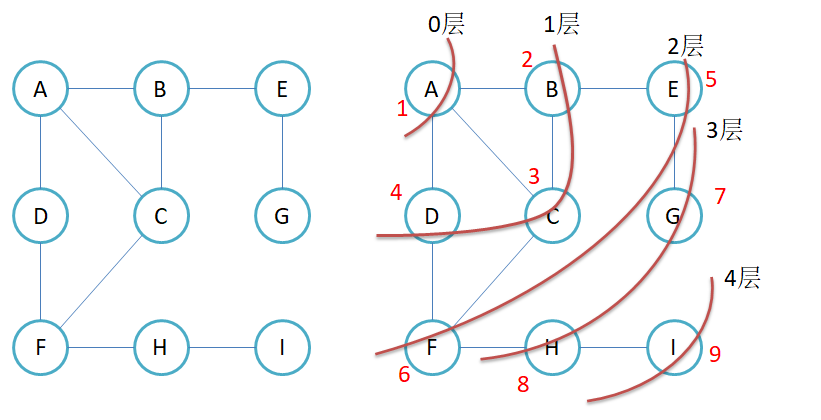
邻接矩阵的广度优先遍历实现
思路:像树的层序遍历一样,借助一个队列实现广度遍历。
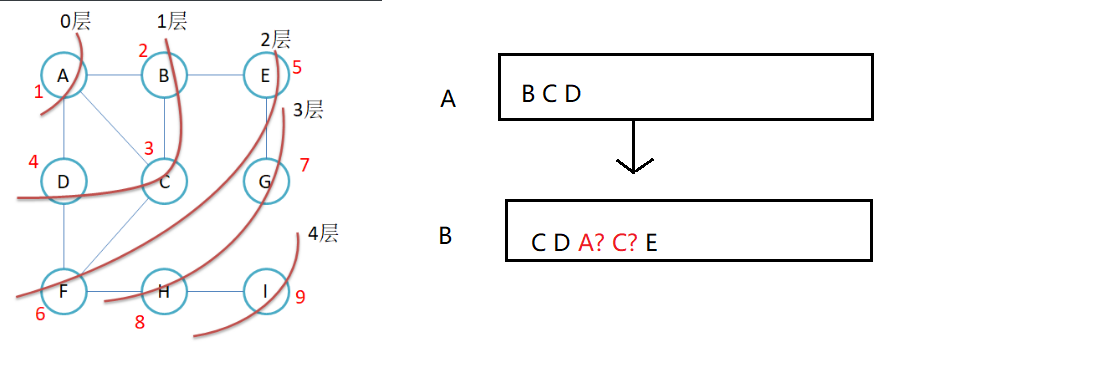
但是可能会出现重复遍历的问题,造成死循环。
解决办法:使用一个标记数组,记录顶点是否已经被遍历。如果顶点已经被遍历,则不再入队列。
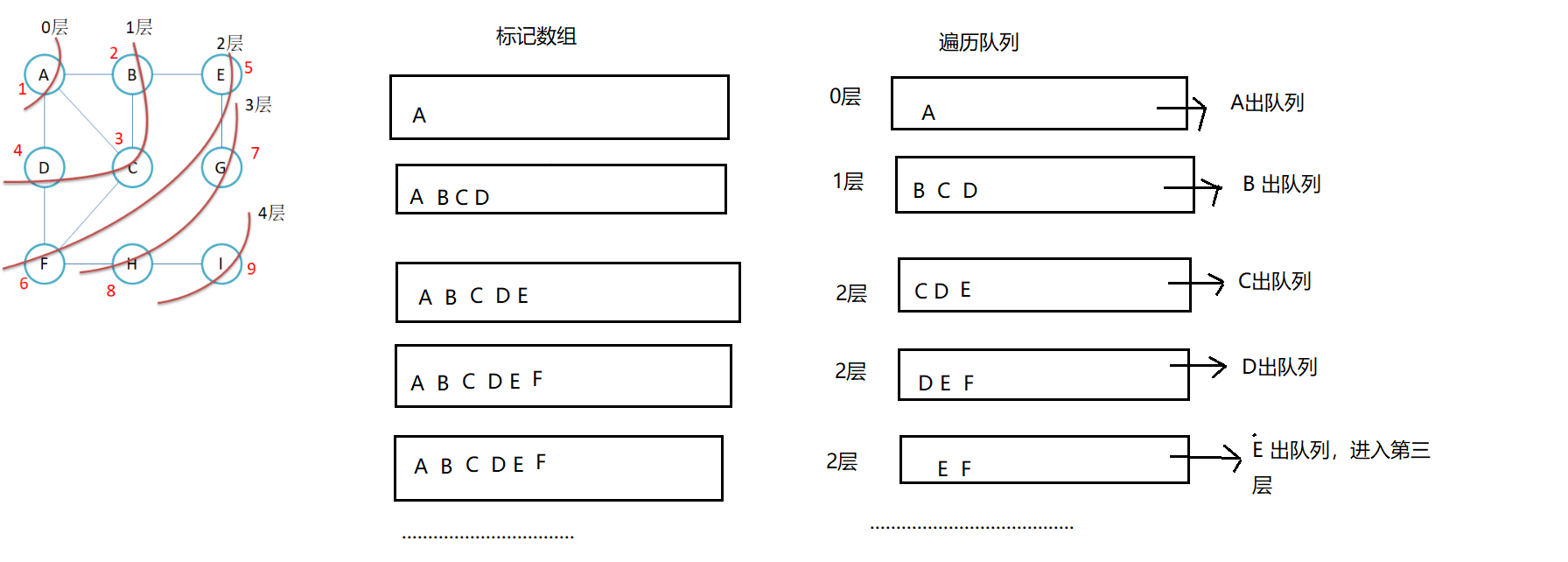
void BFS(const V &src)
{
size_t srci = GetVertexIndex(src);
//遍历队列
queue<int> q;
//标记数组
vector<bool> visited(_vertexs.size(), false);
q.push(srci);
visited[srci] = true;
int n = _vertexs.size();
int num = 0;
int size = 1;
while (!q.empty())
{
cout << "第" << num << "层:" << endl;
for (int i = 0; i < size; i++)
{
int front = q.front();
q.pop();
cout << front << ":" << _vertexs[front] << " ";
for (int i = 0; i < n; i++)
{
if (_matrix[front][i] != MAX_W && !visited[i])
{
q.push(i);
visited[i] = true;
}
}
cout << endl;
}
num++;
size = q.size();
}
cout << endl;
}
测试程序
void test_matrix()
{
matrix::Graph<char, int, INT64_MAX, false> g("ABCDEFGHI", 9);
g.addedge('A','B',1);
g.addedge('A','C',1);
g.addedge('A','D',1);
g.addedge('B','E',1);
g.addedge('B','C',1);
g.addedge('C','F',1);
g.addedge('D','F',1);
g.addedge('E','G',1);
g.addedge('F','H',1);
g.addedge('H','I',1);
g.Print();
g.BFS('A');
}

美团的面试题:六度人脉理论
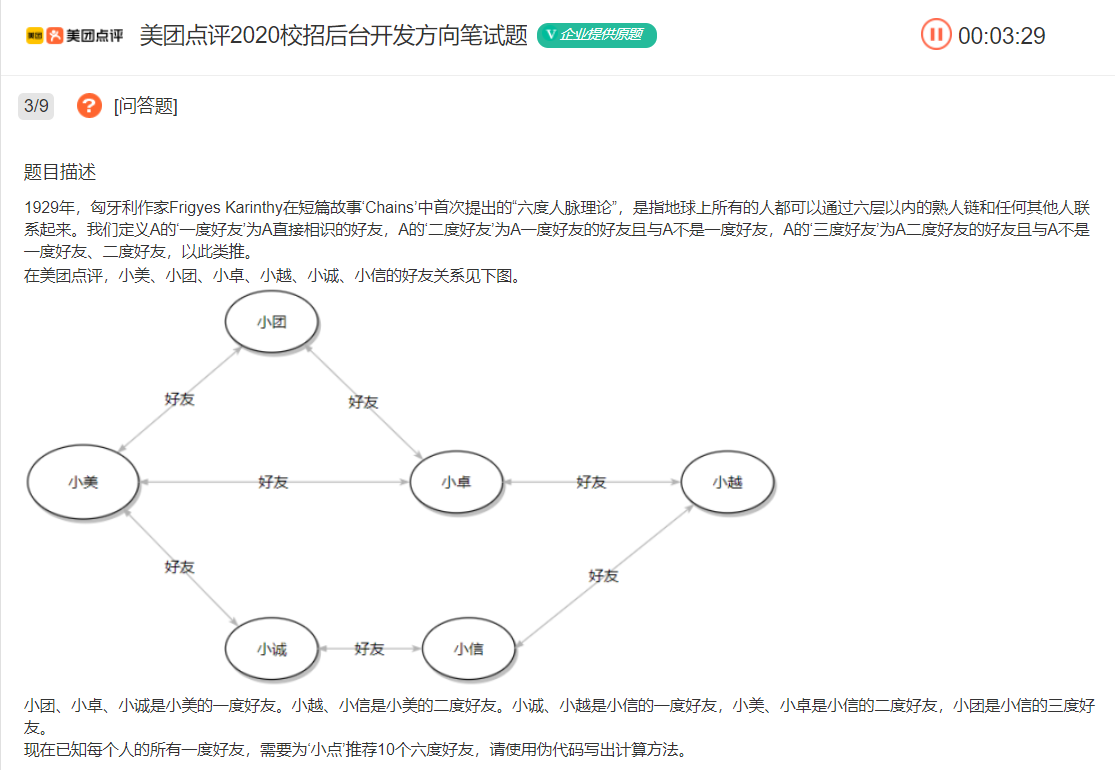
这个题的思路需要用到广度优先遍历,每一层就是小点的一度人脉。
void test_matrix()
{
string name[]={"小美","小团","小卓","小越","小诚","小信"};
matrix::Graph<string, int> g(name, 6);
g.addedge("小美","小团",1);
g.addedge("小美","小卓",1);
g.addedge("小美","小诚",1);
g.addedge("小团","小诚",1);
g.addedge("小卓","小越",1);
g.addedge("小卓","小信",1);
g.addedge("小信","小越",1);
g.BFS("小美");
}

5.2深度优先遍历

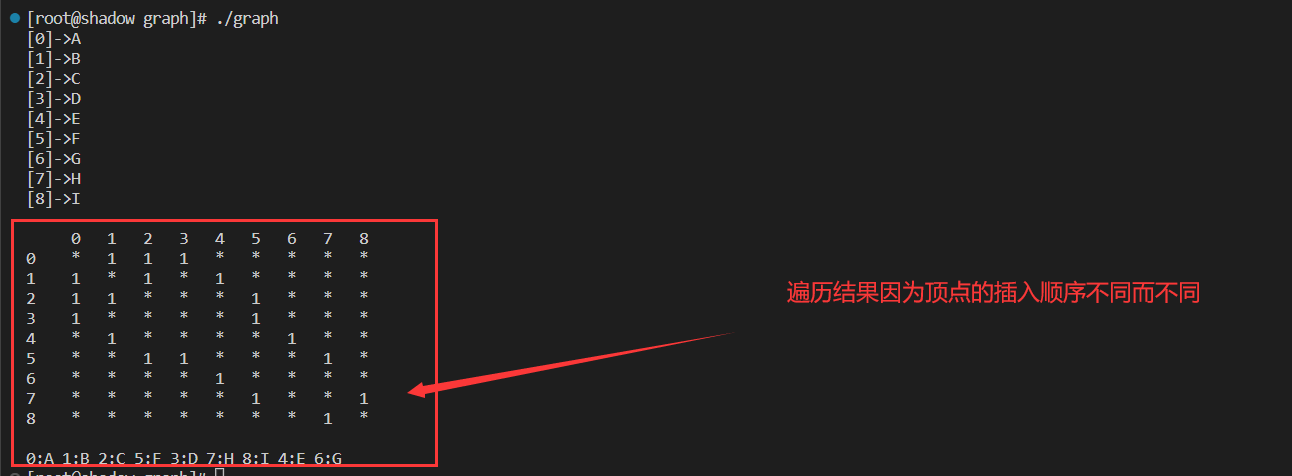
深度优先遍历的遍历顺序与顶点插入顺序有关,不同的插入顺序可能有不同的遍历结果。
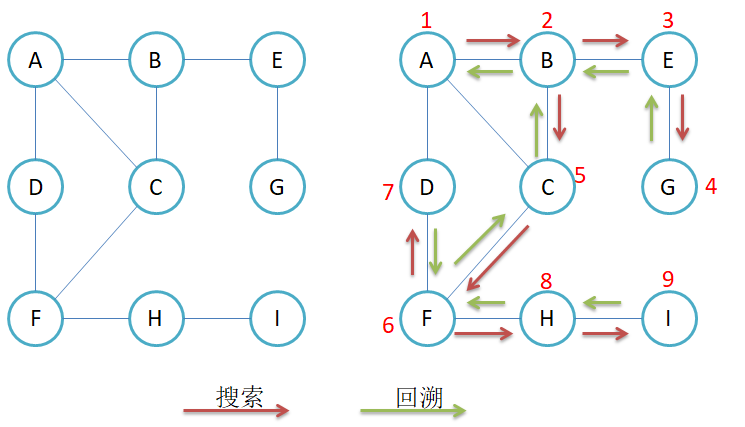
void _DFS(size_t srci, vector<bool> &visited)
{
cout << srci << ":" << _vertexs[srci] << " ";
visited[srci] = true;
for (int i = 0; i < _vertexs.size(); i++)
{
if (_matrix[srci][i] != MAX_W && !visited[i])
{
_DFS(i, visited);
}
}
}
void DFS(const V &src)
{
size_t srci = GetVertexIndex(src);
vector<bool> visited(_vertexs.size(), false);
_DFS(srci, visited);
cout << endl;
}
测试结果
void test_matrix()
{
matrix::Graph<char, int, INT64_MAX, false> g("ABCDEFGHI", 9);
g.addedge('A','B',1);
g.addedge('A','C',1);
g.addedge('A','D',1);
g.addedge('B','E',1);
g.addedge('B','C',1);
g.addedge('C','F',1);
g.addedge('D','F',1);
g.addedge('E','G',1);
g.addedge('F','H',1);
g.addedge('H','I',1);
g.Print();
g.DFS('A');
}
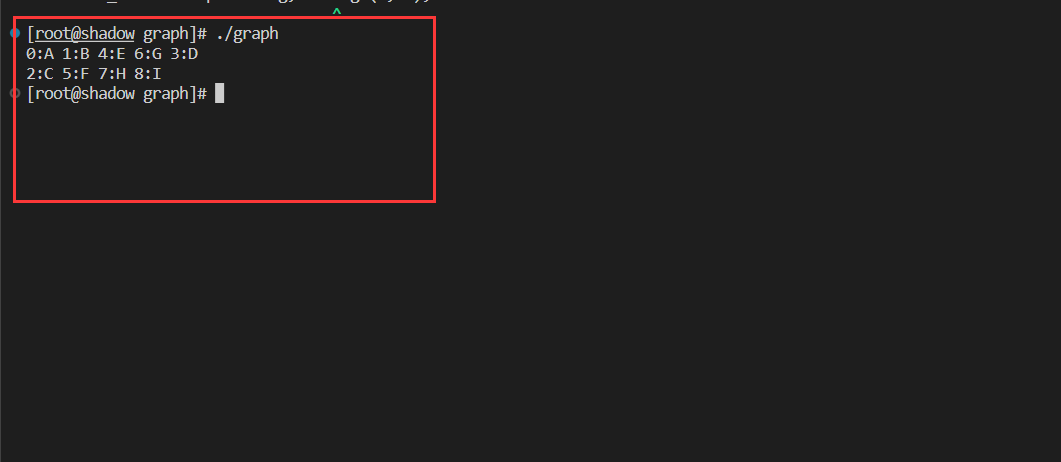
5.3如何遍历不连通的图?
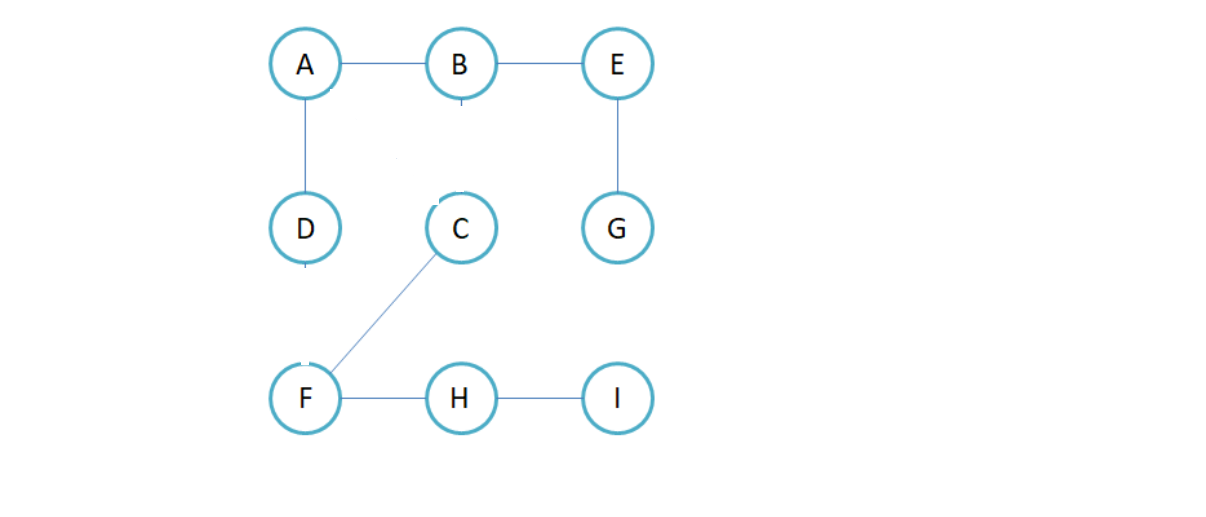
比如上面的图:
在进行图的遍历的时候,我们使用了一个遍历数组记录该顶点是否被遍历。
如何遍历不连通的图:在bool数组中寻找还没有遍历过的点进行遍历。
以上面的图为例:
void test_matrix()
{
matrix::Graph<char, int> g("ABCDEFGHI",9);
g.addedge('A','B',1);
g.addedge('A','D',1);
g.addedge('B','E',1);
g.addedge('E','G',1);
g.addedge('C','F',1);
g.addedge('F','H',1);
g.addedge('H','I',1);
g.BFS('A');
}
广度优先遍历
void _BFS(size_t srci, vector<bool> &visited)
{
//遍历队列
queue<int> q;
q.push(srci);
visited[srci] = true;
int n = _vertexs.size();
int num = 0;
int size = 1;
while (!q.empty())
{
cout << "第" << num << "层:" << endl;
for (int i = 0; i < size; i++)
{
int front = q.front();
q.pop();
cout << front << ":" << _vertexs[front] << " ";
for (int i = 0; i < n; i++)
{
if (_matrix[front][i] != MAX_W && !visited[i])
{
q.push(i);
visited[i] = true;
}
}
cout << endl;
}
num++;
size = q.size();
}
cout << endl;
}
void BFS(const V &src)
{
//标记数组
vector<bool> visited(_vertexs.size(), false);
size_t srci = GetVertexIndex(src);
_BFS(srci, visited);
for (int i = 0; i < visited.size(); i++)
{
if (!visited[i])
{
cout << endl;
_BFS(i, visited);
}
}
}

深度优先遍历
void _DFS(size_t srci, vector<bool> &visited)
{
cout << srci << ":" << _vertexs[srci] << " ";
visited[srci] = true;
for (int i = 0; i < _vertexs.size(); i++)
{
if (_matrix[srci][i] != MAX_W && !visited[i])
{
_DFS(i, visited);
}
}
}
//非连通图的遍历
void DFS(const V &src)
{
size_t srci = GetVertexIndex(src);
vector<bool> visited(_vertexs.size(), false);
_DFS(srci, visited);
for (int i = 0; i < visited.size(); i++)
{
if (!visited[i])
{
cout << endl;
_DFS(i, visited);
}
}
cout << endl;
}






![[附源码]Python计算机毕业设计Django基于web的建设科技项目申报管理系统](https://img-blog.csdnimg.cn/74aa88dab14c440fb6c48eb1b320c929.png)

