PPT下载链接:https://pan.baidu.com/s/1PJ671YEj6M9khtdhh6TSxA?pwd=g37t
提取码:g37t
源码下载链接:ppt.rar - 蓝奏云
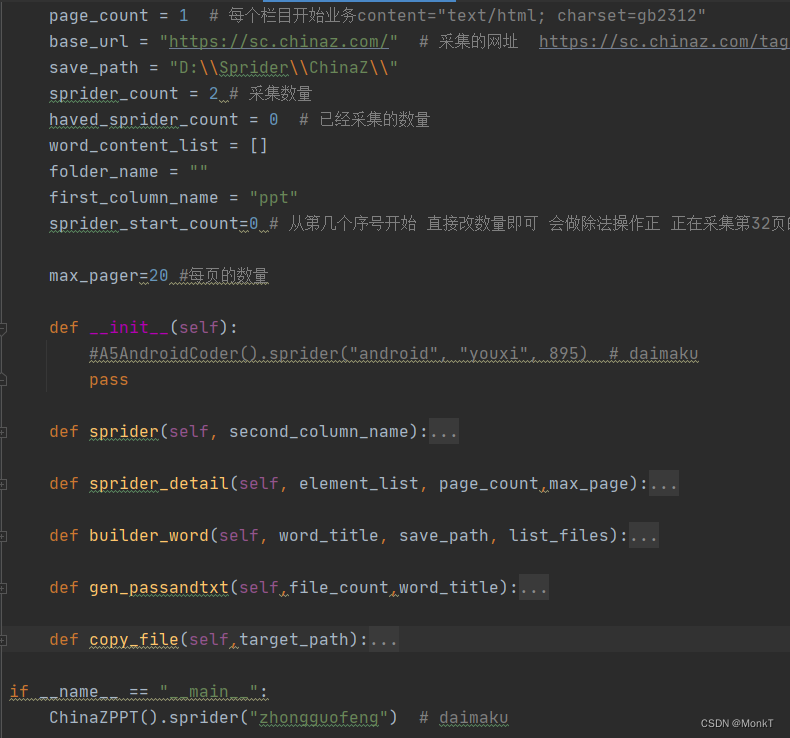
采集的参数
page_count = 1 # 每个栏目开始业务content="text/html; charset=gb2312"
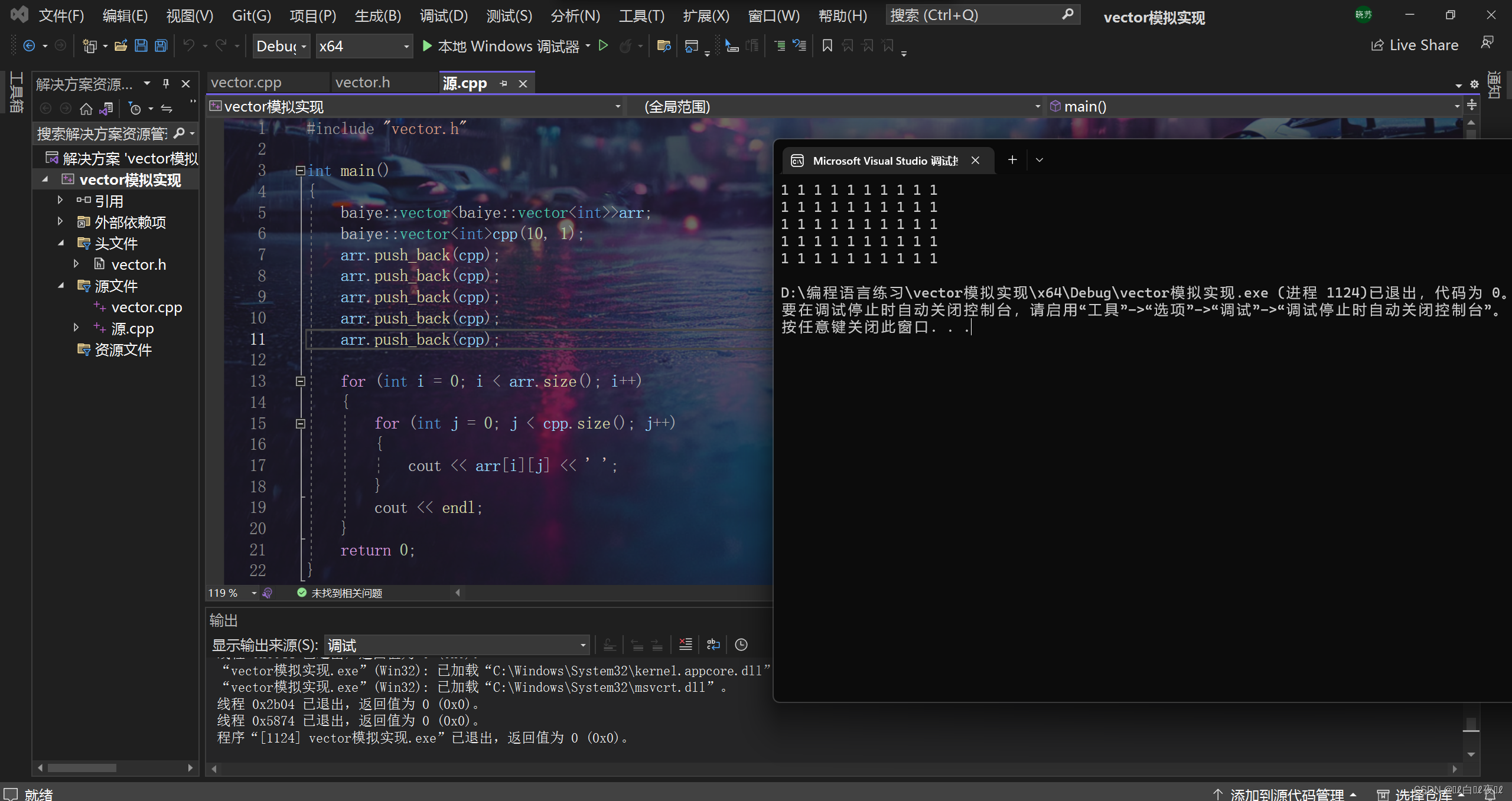
base_url = "https://sc.chinaz.com/" # 采集的网址 https://sc.chinaz.com/tag_ppt/zhongguofeng.html
save_path = "D:\\Sprider\\ChinaZ\\"
sprider_count = 110 # 采集数量
haved_sprider_count = 0 # 已经采集的数量
word_content_list = []
folder_name = ""
first_column_name = "ppt"
sprider_start_count=800 # 从第几个序号开始 直接改数量即可 会做除法操作正 正在采集第32页的第16个资源 debug
max_pager=20 #每页的数量采集主体代码
def sprider(self, second_column_name):
"""
采集Coder代码
:return:
"""
if second_column_name == "zhongguofeng":
self.folder_name = "中国风"
self.first_column_name="tag_ppt"
elif second_column_name == "xiaoqingxin":
self.folder_name = "小清新"
self.first_column_name = "tag_ppt"
elif second_column_name == "kejian":
self.folder_name = "课件"
self.first_column_name = "ppt"
merchant = int(self.sprider_start_count) // int(self.max_pager) + 1
second_folder_name = str(self.sprider_count) + "个" + self.folder_name
self.save_path = self.save_path+ os.sep + "PPT" + os.sep + second_folder_name
BaseFrame().debug("开始采集ChinaZPPT...")
sprider_url = (self.base_url + "/" + self.first_column_name + "/" + second_column_name + ".html")
response = requests.get(sprider_url, timeout=10, headers=UserAgent().get_random_header(self.base_url))
response.encoding = 'UTF-8'
soup = BeautifulSoup(response.text, "html5lib")
#print(soup)
div_list = soup.find('div', attrs={"class": 'ppt-list'})
div_list =div_list.find_all('div', attrs={"class": 'item'})
#print(div_list)
laster_pager_url = soup.find('a', attrs={"class": 'nextpage'})
laster_pager_url = laster_pager_url.previous_sibling
#<a href="zhongguofeng_89.html"><b>89</b></a>
page_end_number = int(laster_pager_url.find('b').string)
#print(page_end_number)
self.page_count = merchant
while self.page_count <= int(page_end_number): # 翻完停止
try:
if self.page_count == 1:
self.sprider_detail(div_list,self.page_count,page_end_number)
else:
if self.haved_sprider_count == self.sprider_count:
BaseFrame().debug("采集到达数量采集停止...")
BaseFrame().debug("开始写文章...")
self.builder_word(self.folder_name, self.save_path, self.word_content_list)
BaseFrame().debug("文件编写完毕,请到对应的磁盘查看word文件和下载文件!")
break
#https://www.a5xiazai.com/android/youxi/qipaiyouxi/list_913_1.html
#https://www.a5xiazai.com/android/youxi/qipaiyouxi/list_913_2.html
#next_url = sprider_url + "/list_{0}_{1}.html".format(str(url_index), self.page_count)
# (self.base_url + "/" + first_column_name + "/" + second_column_name + "/"+three_column_name+"")
next_url =(self.base_url + "/" + self.first_column_name + "/" + second_column_name + "_{0}.html").format(self.page_count)
# (self.base_url + "/" + self.first_column_name + "/" + second_column_name + "")+"/list_{0}_{1}.html".format(str(self.url_index), self.page_count)
response = requests.get(next_url, timeout=10, headers=UserAgent().get_random_header(self.base_url))
response.encoding = 'UTF-8'
soup = BeautifulSoup(response.text, "html5lib")
div_list = soup.find('div', attrs={"class": 'ppt-list'})
div_list = div_list.find_all('div', attrs={"class": 'item'})
self.sprider_detail(div_list, self.page_count,page_end_number)
pass
except Exception as e:
print("sprider()执行过程出现错误" + str(e))
pass
self.page_count = self.page_count + 1 # 页码增加1
def sprider_detail(self, element_list, page_count,max_page):
try:
element_length = len(element_list)
self.sprider_start_index = int(self.sprider_start_count) % int(self.max_pager)
index = self.sprider_start_index
while index < element_length:
a=element_list[index]
if self.haved_sprider_count == self.sprider_count:
BaseFrame().debug("采集到达数量采集停止...")
break
index = index + 1
sprider_info = "正在采集第" + str(page_count) + "页的第" + str(index) + "个资源"
BaseFrame().debug(sprider_info)
title_image_obj = a.find('img', attrs={"class": 'lazy'})
url_A_obj=a.find('a', attrs={"class": 'name'})
next_url = self.base_url+url_A_obj.get("href")
coder_title = title_image_obj.get("alt")
response = requests.get(next_url, timeout=10, headers=UserAgent().get_random_header(self.base_url))
response.encoding = 'UTF-8'
soup = BeautifulSoup(response.text, "html5lib")
#print(next_url)
down_load_file_div = soup.find('div', attrs={"class": 'download-url'})
if down_load_file_div is None:
BaseFrame().debug("需要花钱无法下载因此跳过哦....")
continue
down_load_file_url = down_load_file_div.find('a').get("href")
#print(down_load_file_url)
image_obj = soup.find('div', attrs={"class": "one-img-box"}).find('img')
image_src = "https:"+ image_obj.get("data-original")
#print(image_src)
if (DownLoad(self.save_path).__down_load_file__(down_load_file_url, coder_title, self.folder_name)):
DownLoad(self.save_path).down_cover_image__(image_src, coder_title) # 资源的 封面
sprider_content = [coder_title,
self.save_path + os.sep + "image" + os.sep + coder_title + ".jpg"] # 采集成功的记录
self.word_content_list.append(sprider_content) # 增加到最终的数组
self.haved_sprider_count = self.haved_sprider_count + 1
BaseFrame().debug("已经采集完成第" + str(self.haved_sprider_count) + "个")
if (int(page_count) == int(max_page)):
self.builder_word(self.folder_name, self.save_path, self.word_content_list)
BaseFrame().debug("文件编写完毕,请到对应的磁盘查看word文件和下载文件!")
except Exception as e:
print("sprider_detail:" + str(e))
pass
采集的文件名
2017恩师教师节快乐ppt模板
2020中国风元旦商务PPT模板
2021中国风新年快乐PPT模板
2021中国风春节PPT模板
2021福牛贺新春PPT模板
ppt动态中国风模板下载
中国风ppt模板
中国风PPT模板免费下载
中国风ppt模板图片下载
中国风七夕情人节活动策划PPT模板
中国风中国年春节拜年PPT模板
中国风中秋传统节日ppt模板
中国风京剧戏曲文化ppt模板下载
中国风传统中秋节ppt模板
中国风传统感恩重阳节ppt模板
中国风传统文化教育ppt模板
中国风传统节日绿色清明节ppt模板
中国风传统鼠年新春PPT模板
中国风信仰ppt模板下载
中国风儒雅文化清明节PPT模板
中国风儒雅茶文化ppt模板
中国风党政民法典婚姻家庭编详细解读PPT模板
中国风古典青花瓷ppt模板
中国风国企政府党政工作汇报PPT模板
中国风国庆水墨背景ppt模板
中国风大气简约素雅墨荷ppt模板
中国风年会贺岁风喜庆PPT模板
中国风建筑项目ppt模板下载
中国风形象展示ppt模板下载
中国风时尚商务ppt模板下载
中国风春节PPT模板下载
中国风水墨怀旧ppt模板
中国风水墨淡雅商务汇报PPT模板
中国风水墨清明节PPT模板
中国风水墨素雅ppt模板下载
中国风水墨背景儒雅教师节ppt模板
中国风水墨莲花ppt模板下载
中国风水墨项目策划ppt模板
中国风清廉竹林ppt模板下载
中国风特色建筑ppt模板
中国风猪年新春联欢晚会通用PPT模板
中国风祥云喜庆ppt模板
中国风素雅工作总结报告PPT模板
中国风红色新春晚会PPT模板
中国风茶艺ppt模板
中秋节传统习俗ppt模板
中秋节传统节日ppt模板
企业年会策划书PPT模板
传统中国风水墨ppt模板
传统文化弘扬ppt模板下载
传统文化春节PPT模板
公司年会策划方案PPT模板
典雅中国风策划书ppt模板下载
创意2018狗年ppt模板
创意中国风中秋赏月ppt模板
创意中国风剪纸狗年新春快乐ppt模板
创意古典风淡雅中国风工作汇总PPT模板
创意时尚中国风工作总结ppt模板
动态励志公司年会ppt模板
古典中国风ppt动态模板下载
古典中国风ppt模板
古典中国风艺术ppt模板
古典腊梅素雅ppt模板
可爱玉兔中秋ppt模板
吉祥好运仙鹤ppt模板
唯美中国风水彩画ppt模板下载
唯美中国风霜降节气ppt模板
团团圆圆中秋节ppt模板
复古中国风韵味国庆节PPT模板
大气中国风八一建军节91周年通用ppt模板
大气中国风欢度国庆PPT模板
大气古典中国风ppt模板
大红灯笼年味中国风商务PPT模板
山水风格党政党务PPT模板
年终总结春节喜庆PPT模板
弘扬优良家风党员学习党课ppt模板
恭喜发财大红色中国风商务汇报PPT模板
新年贺新春ppt模板
时尚极简中国风ppt模板下载
春节PPT模板主题下载
极简中国风九九重阳节ppt模板
水墨中国风ppt模板
水墨中国风ppt模板免费下载
水墨中国风大学生入党答辩ppt模板
水墨中国风工作总结PPT模板
水墨中国风总结ppt模板
水墨中国风意境ppt模板
水墨中国风清明节祭祖ppt模板
水墨中国风韵味清明节PPT模板
水墨中国风餐饮行业调查ppt模板
水墨元素中国风通用ppt模板
水墨风山清水秀PPT模板
沉稳黑灰水墨中国风工作报告PPT模板
淡雅韵味创意中国风ppt模板
清新简约廉政党政中国风PPT模板
清新简约竹子ppt模板
清明节祭奠PPT模板
灰色简约素雅古典中国风ppt模板
竹中国风ppt模板下载
简洁清新陶瓷ppt模板
素色清明节古风ppt制作模板
素雅中国风情怀中秋佳节ppt模板
素雅中国风茶道文化展示ppt模板
素雅古典中国风端午节ppt模板
红色中国风党政总结工作汇报PPT模板
红色中国风新春企业商业计划书PPT模板
绿色中国风浓情端午节PPT模板
茶韵中国风ppt模板下载
黑色个性极简ppt模板

![[附源码]Python计算机毕业设计Django基于web的建设科技项目申报管理系统](https://img-blog.csdnimg.cn/74aa88dab14c440fb6c48eb1b320c929.png)