一、引言
前面的博文,是PTQ的注意事项。本篇文章是记录QAT部分需要修改的一些要点。
注:本文仅供自己的笔记作用,防止未来自己忘记一些坑的处理方式
QAT的大致流程:(1)训练生成基础模型,通常是fp32的pt文件;(2)为fp32的pt文件插入伪量化节点;(3)PTQ获取初步int8校准模型;(4)QAT(量化感知训练),大约10几个epoch就够了,反正就是不需要像 from scratch那种长时间训练;(5)导出onnx文件
二、注意事项
2.1

注意这里在模型准备阶段。自己手动添加yaml超参数文件,这个随便一个都可以
2.2

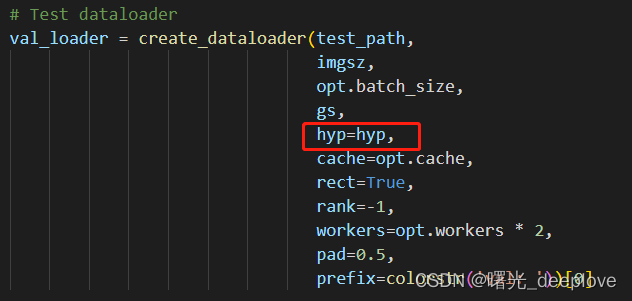

将hyp=None改为hyp=hyp
2.3

注意这边被注释掉的是PTQ后的模型精度
三、模型导出

首先可以看到QAT后的模型和原生的fp32的模型相比,整体精度低了一点点。
python quant_flow_qat_int8.py --dynamic Ture至于后续生成engine,就可以直接使用trtexec处理了。
此处不再赘述!
四、总结
最后注意的是:
(1)量化出来的onnx,对比之前的fp32的模型的onnx会增加模型文件在磁盘上的占用大小。由于(模型)onnx中多了q和dq,因此会比以前的稍微大点;
(2)我前面有疑问:fp32-》int8降低了存储字节数,不是会降低磁盘占用么?这个根据大佬们的解答也是:在onnx文件中存储的话还是FP32的数值,只不过运行的时候才是会转到int8算子计算。说白了这是两个概念上的东西了,一个是存储中(仍为fp32数值),另一个是运行时(根据量化算子转到int8计算)
(3)不要搞混了,一个模型在本地磁盘的占用,一个模型运行时占用的内存(显存),这是两个概念级的东西。比如虽然我们量化后的模型文件,本地磁盘占用变大了一些,但是实际运行时占用的显存(内存)是占用更少的!
五、参考文献
以下文章我暂时也没有时间去细看。
(1)模型量化综述及应用-云社区-华为云
(2)模型量化 - 简书
(3)模型量化笔记 - 简书
(4)如何减小机器学习模型的大小_AI_Amandeep Singh_InfoQ精选文章
(5)【技术解析】模型量化压缩,为AI(爱)发电!
(6)模型量化了解一下? - 知乎
(7)深度学习神经网络的模型量化_开源蜂鸟E203_RISC-V论坛讨论_RISC-V MCU中文社区
(8)github链接
(9)AI算力的阿喀琉斯之踵:内存墙_OneFlow一流科技有限公司
(10)Paddle Lite
(11)极市开发者平台-计算机视觉算法开发落地平台
(12)性能不打折,内存占用减少90%,Facebook提出极致模型压缩方法Quant-Noise - 腾讯云开发者社区-腾讯云(13)TensorFlow 模型优化:模型量化 - 技术分享 - tf.wiki 社区
(14)模型量化(1):模型量化简介 - 飞桨AI Studio
(15)算法原理 — PaddleSlim 文档
(16)模型量化系列 | 模型量化简介及PPQ初探 - 墨天轮
(17)https://www.toutiao.com/article/6776432142281867788/
(18)int8模型量化内存占用极大 - MXNet Gluon - MXNet / Gluon 论坛
(19)码道人
(20)深度学习之模型量化 - 大大通
(21)利用 NVIDIA TensorRT 量化感知训练实现 INT8 推理的 FP32 精度 - NVIDIA 技术博客
(22)通用目标检测开源框架YOLOv6在美团的量化部署实战 - 美团技术团队
(23)自动驾驶中神经网络模型量化技术:INT8还是INT4? - 与非网
(24)模型量化概述 - 智源社区
(25)定点量化
(26)https://www.nxp.com.cn/docs/zh/training-reference-material/TIP-MACHINE-LEARNING-TOOLCHAIN-2.pdf (27)三张图看懂深度学习模型加速及压缩 - 脉脉
(28)深度学习模型压缩与加速综述
(29)量化(Quantization) — MegEngine 1.11 文档
(30)PyTorch模型量化工具学习-技术圈
(31)深度学习中神经网络模型的量化 - davidtym - 博客园
(32)https://segmentfault.com/a/1190000022639675
(33)全网最全-网络模型低比特量化-低调大师
(34)神经网络模型量化方法简介 | 听见下雨的声音





![[附源码]Python计算机毕业设计Django基于web的建设科技项目申报管理系统](https://img-blog.csdnimg.cn/74aa88dab14c440fb6c48eb1b320c929.png)