ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。
ZooKeeper 的架构通过冗余服务实现高可用性。
Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
简单的剖析一下这几个关键的功能:
数据发布/订阅:用到了zookeeper的watcher机制
负载均衡:一般是将负载均衡的算法 外加上 zookeeper的分布式锁相结合使用,例如kafka中,就使用了改功能,详情的话,请查看kafka的文章。
集群管理、Master选举,分布式锁:等都是主要使用了分布式的锁的概念,外加一下其他的思想实现。
那对于我们想要快速的开发的话,其实去了解到zookeeper的watcher机制,以及zookeeper的分布式锁相关,那就已经能去快速开发了。
但是想要利用zookeeper去面试相关的,那就得需要了解一下zookeeper的选举机制以及数据同步机制。
一、zookeeper的watcher机制
分为四部分:1:客户端注册watcher;2:服务端响应watcher;3:服务端触发watcher;4:客户端调用回调函数。
背景说明:zk的存储数据的模式,类似于一个树的数据结构,每个节点上可以存储数据,也可以有子节点。

watcher可以监听三种模式,增删改.假设我们监听了header的节点,那么如果这个节点下的数据增删改,或者子节点有增删改,都会触发 客户端的 回调函数。执行回调函数里面的内容。这里要注意一下,原生的watcher机制是执行一次之后 就自动注销掉了,也就是只能触发一次回调函数,如果我们想持续的监听这个节点的状态,必须的自己实现重新去注册watcher。或者使用封装好的类,比如java的NodeCache 、PathChildrenCache、Tree Cache。这个里面简单讲解一下,NodeCache会监听某一个节点的数据变化,节点的新增,但是监听不了节点的删除。PathChildrenCache会监听自己节点下的子节点的变化,子节点的增删改。Tree Cache就是监听节点下面的全部的节点变化。
二、zookeeper的分布式锁
分布式锁,是控制分布式系统访问某一资源的一种控制方式。
分布式锁分为两种:排他锁跟共享锁:
排他锁:顾名思义,加上排他锁之后,就禁止其他的进程再去对这个节点加锁。
底层实现原理:多个线程并行去创建一个临时节点,那个线程先创建成功了,则这个线程就会获取到这个锁,那其他线程怎么再去抢夺呢,并且怎么实现及时性,那自然就是watcher机制了,创建失败的线程会在这个节点上创建watcher,获取锁的线程任务执行完之后,会断开连接,临时节点有个特性,就是没有线程连接的时候,会自动消亡,节点一旦消亡,就会触发起来watch机制,引导其他线程在抢夺这个锁。
共享锁:就是可以多个线程去对同一节点进行加锁,但是获取执行权的永远是编号最小的线程。
底层实现原理:
1:多个线程创建临时节点,会按照读锁或者写锁,然后加上序列号,比如说001
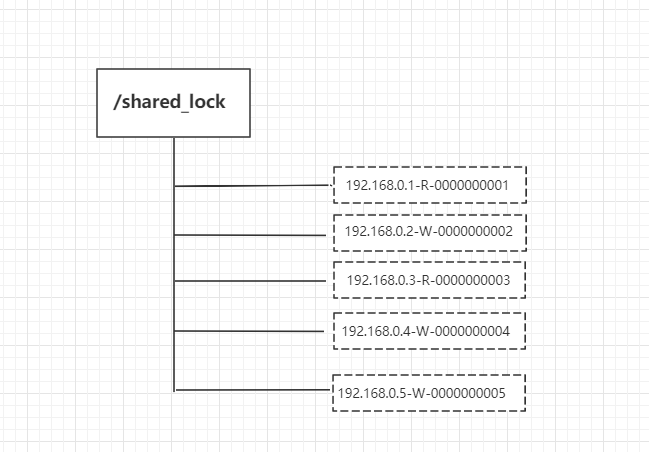
2:客户端获取这个节点下的所有节点,判断一下,是否自己的序号小于其他的节点。读锁判断读锁的,写锁判断写锁的。如果自己的节点是最小的,那么自己获得了这个锁。
3:那如果自己的序号不是最小的,那么会找到比自己的锁序号小一个的节点上,注册watcher。读锁跟写锁分开找。
这种共享锁很适合用作分布式系统中,分布式微服务的选主。