CPU性能提升:Cache机制
随着半导体工艺和芯片设计技术的发展,CPU的工作频率也越来越高,和CPU进行频繁的数据交换的内存的运行速度却没有相应的提升,于是两者之间产生了带宽问题。进而影响计算机系统的整体性能。CPU执行一条指令需要零点几纳秒,而RAM则需要30纳秒左右,读写一次RAM的时间,CPU都可以执行几百条指令了。为了不给CPU拖后腿,解决内存带宽瓶颈的方法一般有两个,一个是大幅度提升内存RAM的工作频率,目前最新的DDR 4内存条的工作频率可以飙到2GHz,但是和高端的CPU相比,还是存在一定的差距的,这就需要第二种方法来弥补差距。使用Cache缓存机制,有速度瓶颈的地方就有缓存,这种思想在计算机中随处可见。
2.4.1 Cache的工作原理
Cache在物理实现上其实就是静态随机访问存储器Random Access memory SRAM,Cache的运行速度介于CPU和内存DRAM之间,是在CPU和内存之间插入一组告诉缓冲存储器,就是利用空间局部性和时间局部性原理,通过自有的存储空间,缓存一部分内存中的指令和数据,减少CPU访问内存的次数,从而提高系统的整体性能。
Cache的工作流程图2-28为例,当CPU读取内存中的地址为8的数据时,CPU会将内存中的地址为8的一片数据缓存到Cache中,等下一次CPU读取内存中地址为12的数据时,会首先到Cache中检查地址是否在Cache中,如果在,就称为缓存命中,CPU就直接从Cache中取数据,如果该地址不在Cache中,就称为缓存未命中,Cache Miss。CPU就重新转向内存读取数据,并重新缓存该地址数据到Cache中。
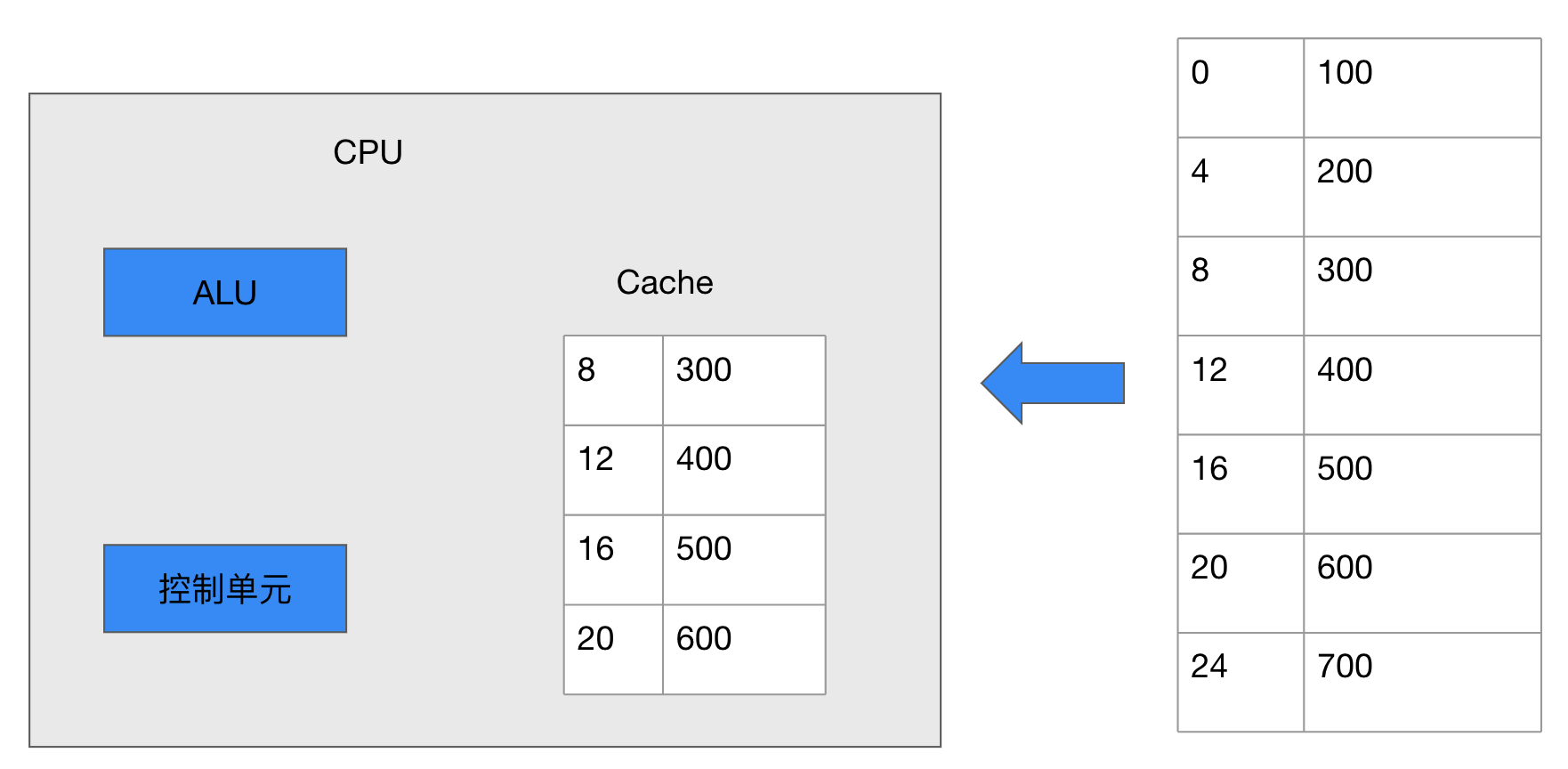
CPU写内存的工作流程和读取类似,,当CPU网地址为16的内存中写入数据0时,并没有直接写入RAM,而是暂时写到了Cache中。此时Cache中的数据和内存中的就不一致了,缓存的每一块空间一般有一个特殊的标记,Dirty Bit。用来记录这种变化,当Cache需要刷新时,如Cache空间已经满了而CPU又需要缓存新的数据的时候,在清理缓存之前,会检查这些Dirty Bit标记的变化,并把这些变化的数据回写到RAM中,然后菜腾出Cache中的存储空间。
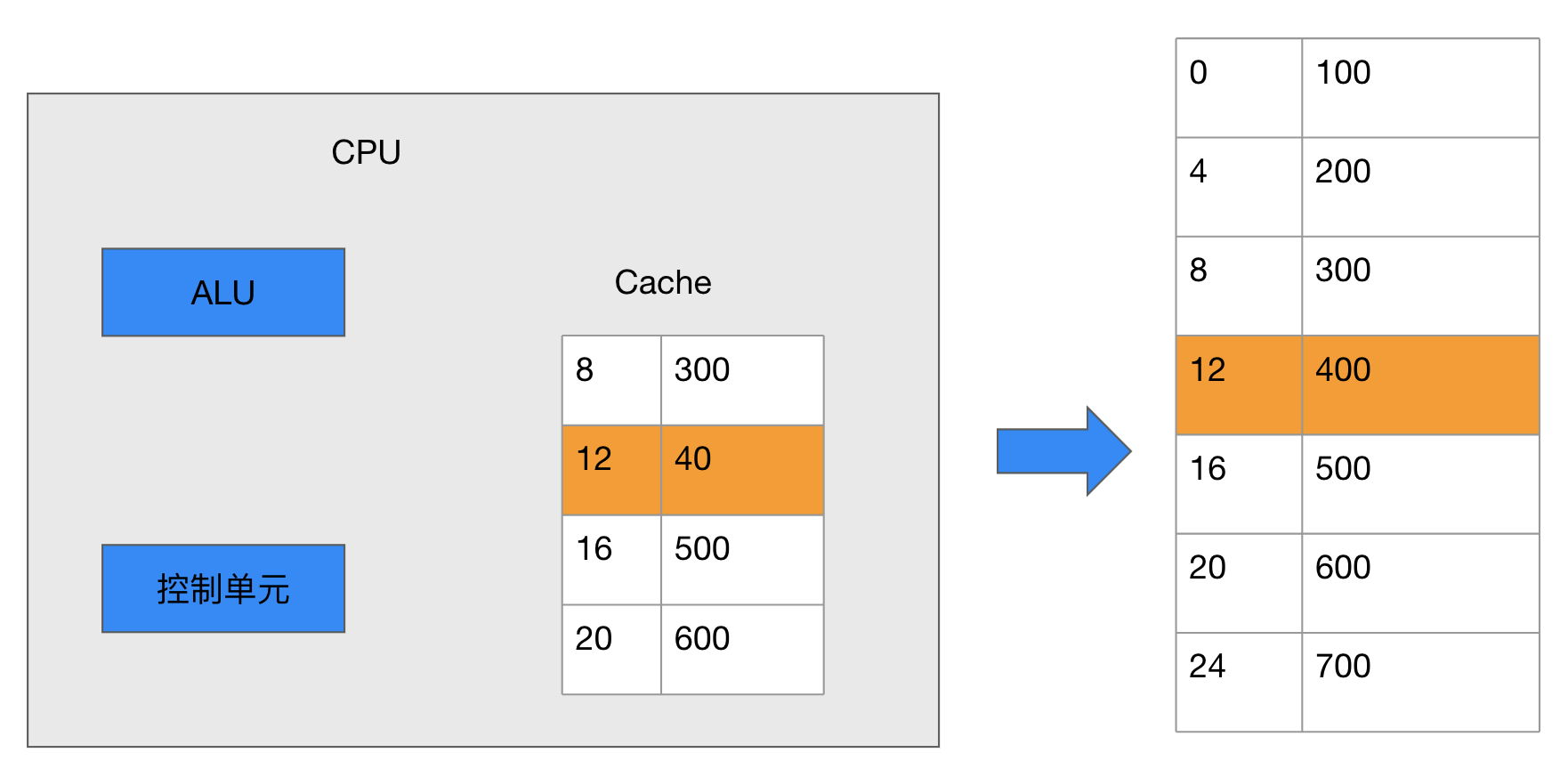
以上只是对Cache的工作原理简化了分析。实际的Cache远比这复杂,如Cache里面存储的内存地址,一般要经过地址映射,转换为更容易存储和检索的形式,另外,现在的CPU为了进一步提高性能,大多采用多级Cache, L1, L2 L3
2.4.2 一级Cache和二级Cache
CPU从Cache里读取数据,如果缓存命中,就不用访问内存了,效率大大提升,如果缓存没有命中,情况就不太乐观了。CPU不仅需要重新到内存取数据,还要缓存一片新的数据到Cache中,如果Cache已经满了,还要清理Cache,如果Cache中的数据有Dirty Bit,还需要先回写数据到RAM,这些操作需要几十甚至上百个指令。消耗上百个时钟周期的时间,严重影响了CPU的读写效率,为了减少这种情况的发生,我们可以通过增大Cache的容量来提高缓存命中的概率。但是随着而来的成本的上升,在CPU内部,Cache和寄存器的电路比内存DRAM复杂了很多,会占用很大的芯片面积,如果大量使用,芯片发热量会急剧上升,所以在CPU内部寄存器一般也就几十个,靠近CPU的一级Cache也就几十K字节,既然无法增加Cache的容量,一个折中的办法就是在一级Cache和内存之间添加二级Cache。 二级Cache的工作频率比一级Cache低,但是是电路成本会低一些。元器件的运行速度总是和电路成本成正比。

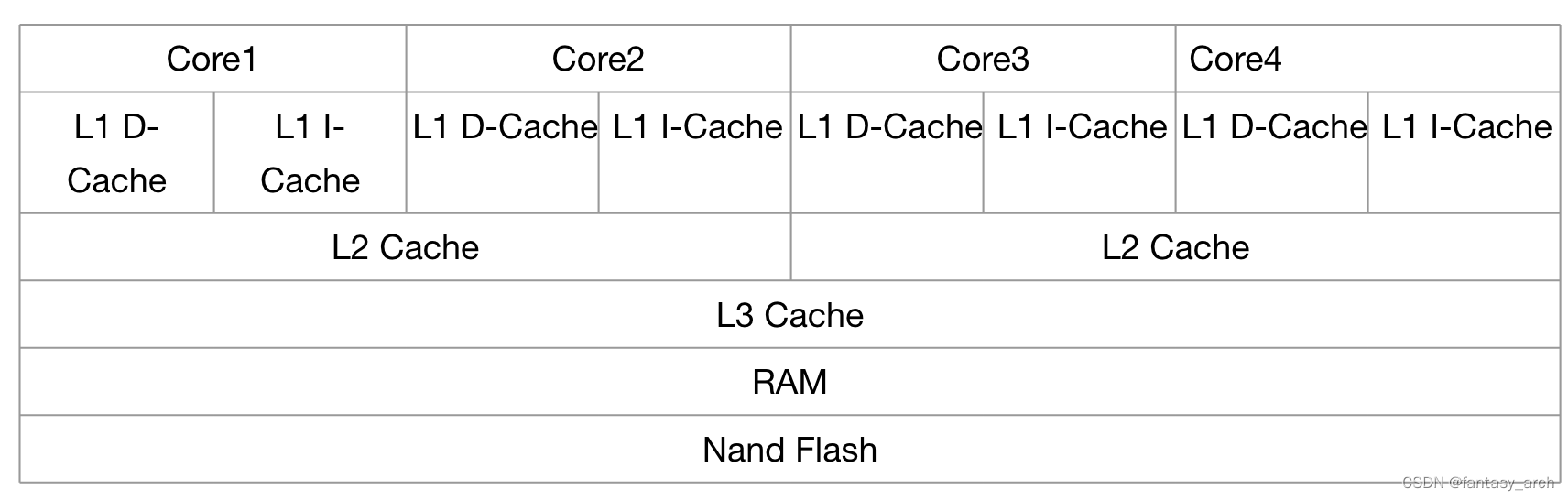
现在的CPU一般都是多核结构,一个CPU芯片内部会集成多个Core,每个Core都会有自己的独立的L1 Cache,包括D-Cache 和I-Cache,在x86架构的CPU中,一般每个Core也会有自己的独立的L2 Cache, L3 Cache被所有的Core共享。而在RAM架构的CPU中,L2 Cache共享的。RAM架构Soc芯片的存储结构如下/
2.4.3 为什么有的处理器没有Cache
Cache一般用于高性能处理中,并不是所有的CPU都有Cache。例如C51单片机,cortex-MO,cortex-MI等系列的ARM处理器就没有Cache,这些处理器功耗低,成本低,L3 Cache的面积占了整个CPU的1/4. 再加上每个Core独立的L1 L2 Cache, 这样Cache就占了CPU面积的1/3.
二是这些处理器工作频率不高,不存在RAM和CPU主频之间带宽差距
三 使用Cache无法保证实时性,缓存未命中时,CPU从RAM读取数据的时间是不确定的。



![基于PyQt5的图形化界面开发——Windows内存资源监视助手[附带编译exe教程]](https://img-blog.csdnimg.cn/524ef5f6882a4229af2d7c2d63a04d98.png)