介绍几篇关于半监督学习的论文:CLS(arXiv2022),Ada-CM(CVPR2022),SemiMatch(CVPR2022).
CLS: Cross Labeling Supervision for Semi-Supervised Learning, arXiv2022
解读:CLS: Cross Labeling Supervision for Semi-Supervised Learning - 知乎 (zhihu.com)
【保证伪标签质量】CLS: Cross Labeling Supervision for Semi-Supervised Learning - 知乎 (zhihu.com)
论文:[2202.08502] CLS: Cross Labeling Supervision for Semi-Supervised Learning (arxiv.org)
代码:YaoYao1995/Cross-Labeling-Supervision-for-Semi-Supervised-Learning: A PyTorch implementation of CLS (github.com)
本文提出了Cross Labeling Supervision (CLS),一个概括典型伪标签生成框架。 基于FixMatch,弱增强样本的预测生成伪标签,用来训练强增强样本,CLS允许创建伪标签和互补标签,以支持正负样本学习。 为了减轻self-labeling的信息偏差和增强错误标签的容忍度,使用不同的参数初始化两个结构完全一样的网络,然后同时训练。每一个网络用另一个网络的高置信度标签作为监督信息。在标签生成阶段,根据预测置信度对人工标签分配权重,这个权重有两个作用:量化生成标签的质量,减少不准确标签对网络训练的干扰。
FixMatch使用弱增强图像的伪标签来监督强增强下相同图像的预测。 MixMatch对多个增强估计取平均值,并通过对估计应用温度锐化函数产生一致性正则化的训练目标。
尽管自训练方法和基于一致性的方法表现较好,但它们都存在着确认偏差的问题,即如果教师/伪标签不准确,在误导的指导下训练学生/模型本身可能会导致显著的成绩下降。为了缓解这个问题,作者提出了这个框架,与Fixmatch相比有3处改进:
- 第一种是生成互补标签来支持负性学习,由于ground truth标签被选为互补标签的机会相对较低,从而降低了提供错误信息的风险。与仅使用伪标签作为监督信号相比,额外生成的互补标签可以帮助校准不正确的预测。 伪标签和互补标签统称为人工标签.
- 二是样本重加权机制,降低低置信人工标签的权重。 与FixMatch设置置信度阈值完全过滤低置信度伪标签不同,使用重加权的优点是网络仍然可以从低置信度标签学习以更好地泛化。
- 受协同训练的启发,两个具有不同初始化的相同网络同时被训练,它们通过交换高置信度的人工标签来减轻自标记的确认偏差。 由于并行技术的发展,同时训练两个网络几乎不增加计算开销。
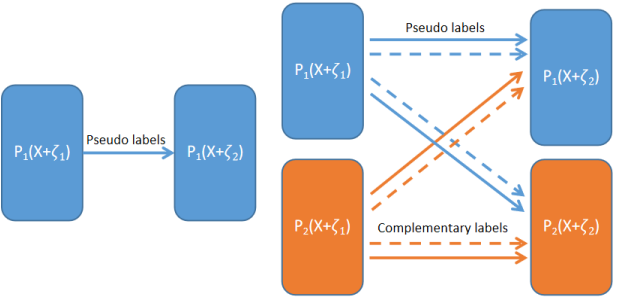

图1:FixMatch和CLS之间的区别。 左:FixMatch,其中对弱增强样本( + 1)的预测为相同样本的强增强( + 2)生成一个伪标签以供学习。 右:CLS,两个平行网络同时生成伪标签和互补标签。 在某种意义上,来自另一个网络的监督信号充当了一种正则化规则,以减轻确认信息偏差,而互补标签支持负性学习
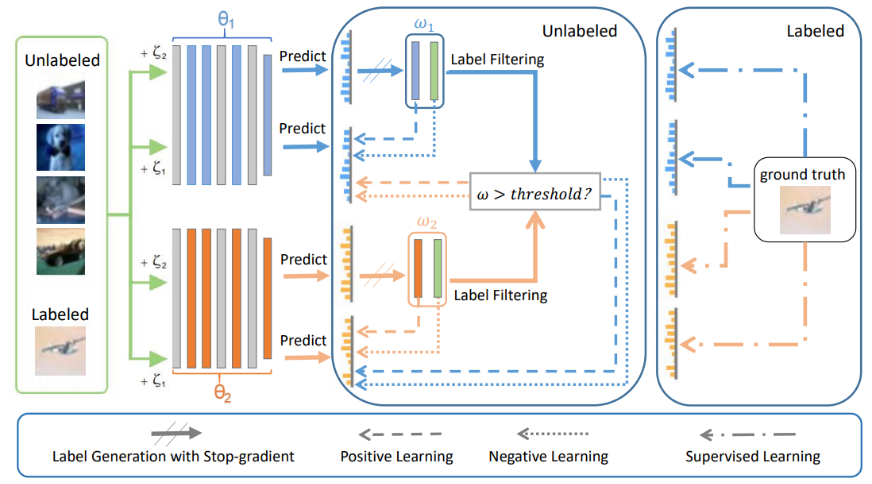

图中描述了一个batch,其中有1个label和4个unlabel。 在被送入两个单独的模型之前做弱(+ 2)和强(+ 1)增强。 利用弱增广的预测概率分布生成具有相应样本权值的伪标签和互补标签,分别通过正、负交叉熵损失监督监督强增强的预测。当两个模型之间进行知识交换时,只考虑样本权重大于阈值的标签。

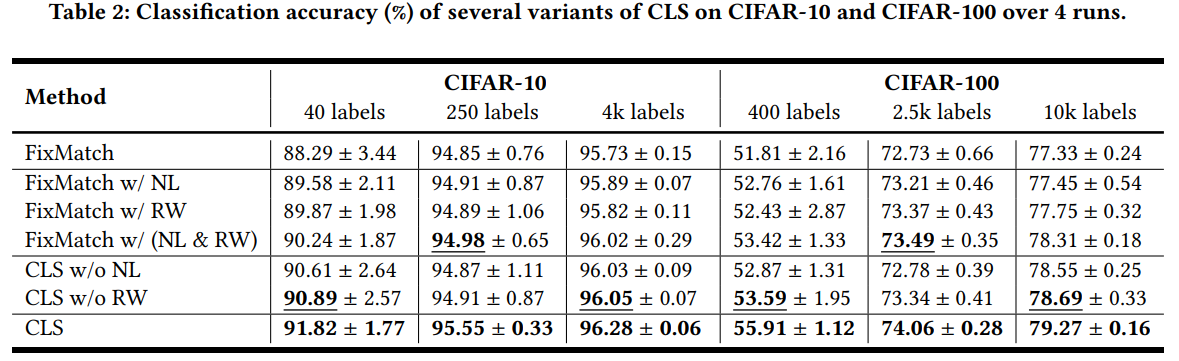
Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence Margin, CVPR2022
讲解:Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence Margin 论文笔记_勒布朗张婧仪的博客-CSDN博客
论文阅读 Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence Margin - 知乎 (zhihu.com)
论文:[2203.12341] Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence Margin (arxiv.org)
代码:hangyu94/Ada-CM: “Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence Margin”, CVPR 2022. (github.com)
总结:
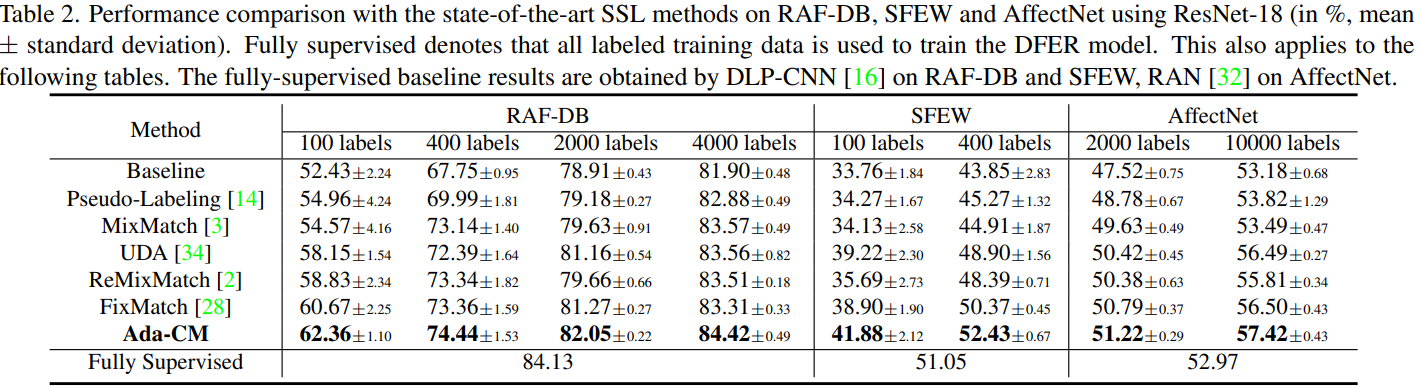
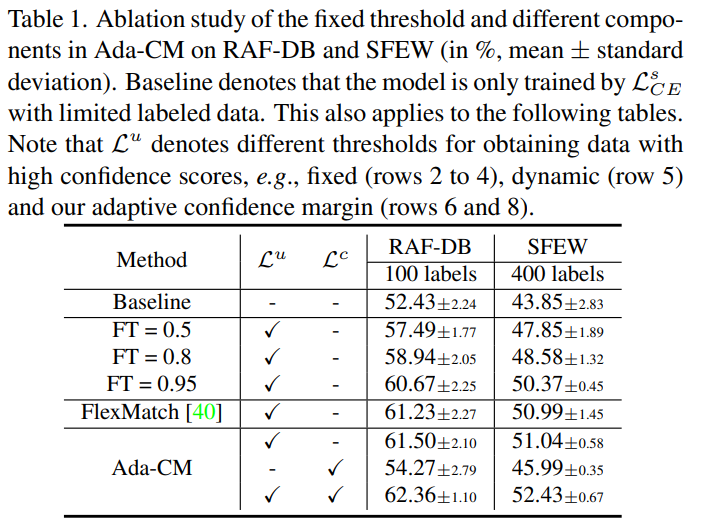
本文提出了一种自适应调整置信度阈值的半监督深度人脸表情识别方法。
- 对于无标签数据,提出了一种自适应调整置信度阈值的方法:因为每个类别本身难度存在差异,分别计算一个类别的阈值。随着模型的提升,再逐步升高这个阈值。
- 全面利用了无标签数据:对于置信度低的无标签数据采用对比学习的方法对特征进行学习。
Adaptive confidence margin (Ada-CM) 方法的流程图如下所示。(b) 模型先对有标签的数据进行训练,用正确的预测得到阈值。(a)对于无标签的数据,对其进行弱增广(Week Augmentation, WA),送入网络求出两个预测的均值。当均值大于阈值,被分到第一个类别中,用其伪标签对强增广(SA)的图片进行交叉熵训练;(c) 当阈值小于均值,用对比学习对弱增广的特征进行约束。


自适应置信度阈值:
首先,对于有标签样本,获得所有标签样本的预测值并确定预测结果,再与真实标签比较挑选出正确的预测样本。依据预测正确样本的预测值和个数,构造初步的自适应置信度(公式5)。再利用公式6逐步调整阈值。超参数B=0.97,y=e,阈值会随着epoch增加不断增加。

半监督自适应学习:
对于无标签的数据,用弱增广得到的预测分数,计算它们的平均值(公式6).
- 当预测值大于阈值:使用预测值产生伪标签,然后对其强增广的输出计算交叉熵。
- 当预测值小于阈值:使用对比学习,对弱增广的两个特征进行约束。

算法:

实验结果:
Semi-Supervised Learning of Semantic Correspondence with Pseudo-Labels, CVPR2022
论文:Semi-Supervised Learning of Semantic Correspondence with Pseudo-Labels | IEEE Conference Publication | IEEE Xplore
https://arxiv.org/abs/2203.16038v2
代码:未找到
由于类内的显著变化和背景混乱,在语义相似的图像之间建立密集的对应关系仍然是一项具有挑战性的任务。使用监督学习来训练模型,需要大量的手动标记数据,而一些方法建议使用自监督或弱监督学习来减轻对标记数据的依赖,但性能有限。
本文提出了一种简单但有效的语义对应解决方案,该解决方案通过利用大量的置信对应作为伪标签来补充少量的基本事实对应,以半监督的方式学习网络工作,称为半匹配。
提出了一种新的半监督学习框架,称为SemiMatch,该框架使用模型本身在源和弱增强目标之间的预测来生成像素级伪标签,然后使模型再次预测伪标签在源和强增强目标之间。为了解释所有伪标签可能无助于提高性能的观察结果,论文通过考虑以对象为中心的前景、前后一致性和概率本身的不确定性,引入了一种新的伪标签置信度度量。针对语义对应,还提出了一种匹配的专门增强,该增强利用了关键点感知剪切,帮助网络学习关键点周围的独特特征表示。
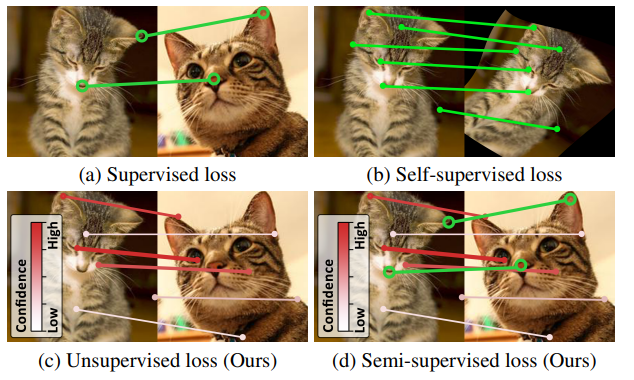
本文提出了(c)使用匹配概率的伪标签的无监督损失和(d)使用稀疏真实标签关键点和置信伪标签的半监督损失。
网络模型:
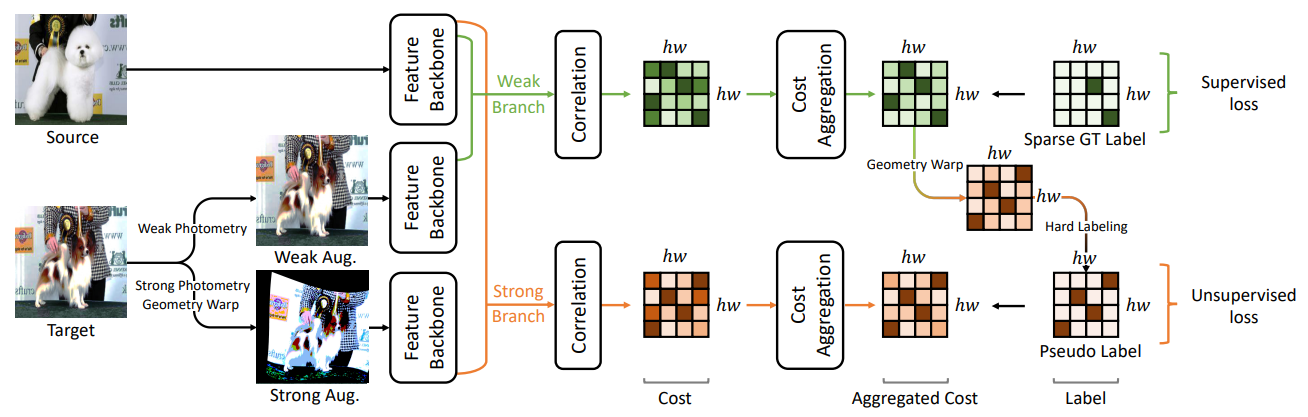

其中,Cost Aggregation操作 来源论文CATs: Cost Aggregation Transformers for Visual Correspondence
半监督采用的增强方式:

强弱图像间的匹配点:

利用强弱一致性,来检查伪标签的可靠性,以获得置信度mask。

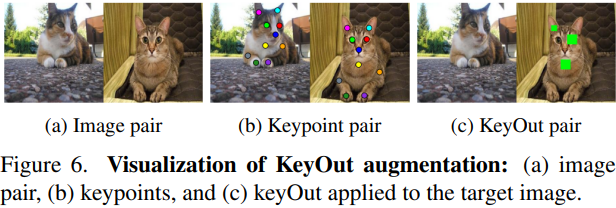
一种匹配的专用augmentation,称为关键点引导剪切(KeyOut),它剪切并删除关键点位置周围特定大小的框,如图6所示。它允许模型学习通过集成关键点外围信息来找到关键点位置
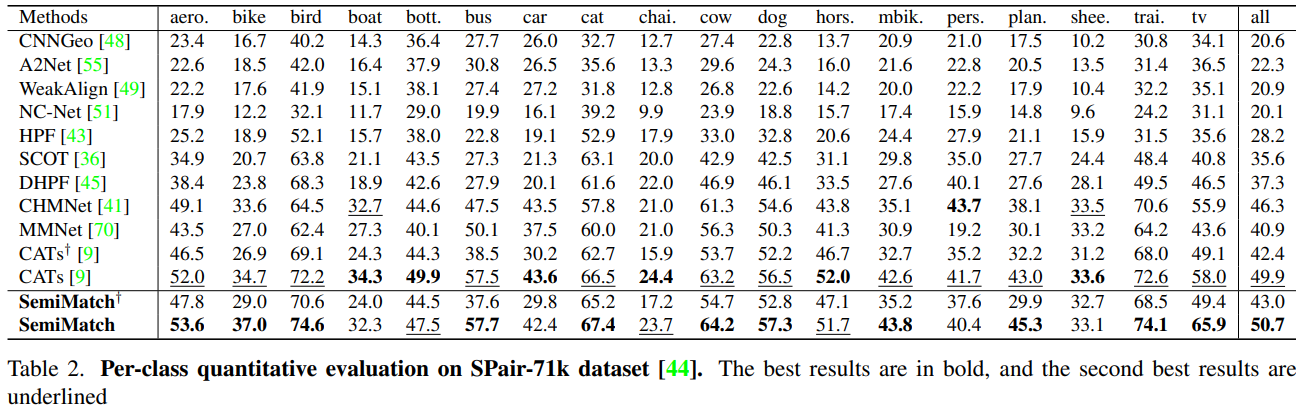
实验:







![[架构之路-201]-《软考-系统分析师》- 关键技术 - 结构化分析方法与面向对象分析(分析与设计的区别)](https://img-blog.csdnimg.cn/9e4b33f9ded947199618974ffc50f079.png)