👉个人主页:highman110
👉作者简介:一名硬件工程师,持续学习,不断记录,保持思考,输出干货内容
参考书籍:《PCI.EXPRESS系统体系结构标准教材 Mindshare》
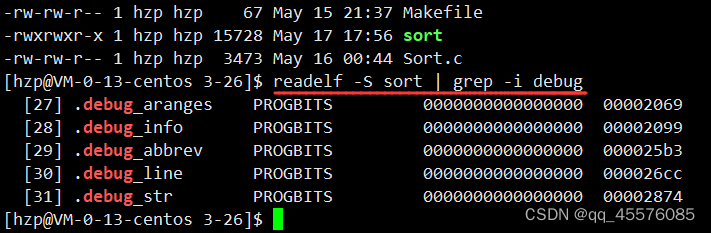
PCIE规范中有描述PCIE支持公共参考时钟架构和独立参考时钟架构,描述了发送端和接收端各自的100MHz本地参考时钟频偏要求为-300ppm~+2800ppm(来自PCIE 5.0规范文档,其中正偏多了2500ppm是给负向扩频留的裕量),这个100MHz参考时钟经过内部PLL倍频到2.5GHz(假设PCIE传输速率为5GT/s)作为串行数据发送和接收的参考时钟。可想而知,如果两端的100M本地时钟有频偏差异,两端PLL倍频后的时钟也是有频偏差异的,这就使发送和接收数据的参考时钟不一致,一个快一点,一个慢一点。有人可能有疑问了,接收端不是用CDR恢复的时钟来接收数据的吗?这个CDR恢复的时钟和发送时钟之间是没有频偏的,接收端的本地时钟快一点或者慢一点又有什么关系呢?这是因为数据在CDR恢复时钟作用下完成串并转换、符号锁定等之后,还需要进入到8B/10B解码、解扰、字节拆分合并等模块,后面这些模块的参考时钟源头是本地100MHz时钟,不是CDR恢复的时钟,这就产生了一个跨时钟域问题,这两个时钟一个快一个慢是不行的。
通常解决跨时钟域问题都是用FIFO,或者叫弹性缓存(elastic buffer),也称为CTC Buffer或者Synchronization Buffer。除了PCIE,诸如USB、以太网等serdes应用基本都使用了此技术。如下图,弹性缓存左边数据输入使用的是接收时钟域,右边数据输出使用的是本地时钟域,弹性缓冲区负责补偿这两个时钟间的差别,方法是从弹性缓冲区的数据符号中删除一个SKP符号,或向缓冲区里的符号中插入一个SKP符号。

1、如果发送时钟频率高于接收时钟频率达600ppm,则从缓冲区中删除一个SKP符号。
2、如果发送时钟频率低于接收时钟频率达600ppm,则向缓冲区中添加一个SKP符号。
链路发送端会定期发送SKIP有序集的特殊符号序列,从该有序集可删除一个“不用关心”的SKP符号,或向其添加一个“不用关心”的SKP符号。SKIP有序集包含4个控制符号(一个COM和3个SKP;Skip是“不用关心”的字符,所以才名为“跳过”)。在弹性缓冲区中的SKIP有序集里删除或添加一个SKP符号可分别防止缓冲区的上溢或下溢状况。
这里有一点需要注意,Intel提出的PIPE规范中,只允许每次从一个SKP Ordered Set中插入或者移除一个SKP。如果需要插入或者移除两个SKP,则需要对两个SKP Ordered Set进行操作。
这里笔者有点疑问,以太网serdes也用了弹性缓冲,但是以太网规范里似乎没有定义类似PCIE的SKIP ordered sets,以太网是怎么补偿这个时钟的呢?如下是千兆以太网定义的ordered sets。
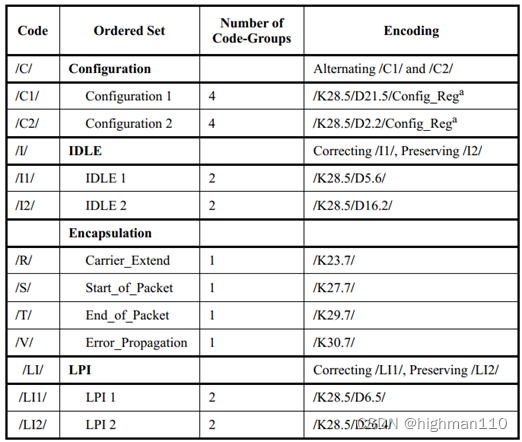
假设现在是两个1000base-x光口对接,发送端和接收端PHY的参考时钟为25M±50ppm,也是一样可能出现一个快一个慢的情况,也一样的用了弹性缓存来解决跨时钟域问题,这里有两种情况:
1、接收端参考时钟比发送端快,就是发送端以较慢的速度把数据往FIFO里填,接收端以较快的速度把数据从FIFO里拿出来,接收要快一点,如果不做任何处理,那么累计一段时间后,FIFO将会输出空数据,发生下溢。我理解要解决这个问题只需要将输出端时钟做一下门控,让FIFO中数据达到一定阈值才打开输出时钟进行输出,否则不FIFO输出,我的理解,不一定对,不知道PHY里面具体怎么做的。
2、接收端参考时钟比发送端慢,发送要快一点,如果不做任何处理,那么累计一段时间后,FIFO将会被填满,发生上溢。有人说了,流控pause帧是否可以解决这个问题,我这边快满了,发个流控帧过去高速发送端停一会再发。这样看似可以解决这个问题,但我理解流控应该不是用来解决这个问题的,因为这里的FIFO数据收发还是物理层的处理,而流控是MAC层的功能,物理层的问题应该由物理层自己解决,就像PCIE一样,物理层的PLP不会去到数据链路层,数据链路层的DLLP也不会去到事务层。那这个问题我理解只能加大FIFO深度来延缓上溢的发生。
基于以上原因,一些做数通设备的厂家,常常会把自己的PHY本地参考时钟用正偏时钟,这样在用打流仪(打流仪一般是精准时钟)进行测试时,设备的接收端不会因为时钟偏慢而导致打流时间长了以后物理层有丢包。
最后这里还有个问题,为什么接收端PHY的子模块不都使用CDR的恢复时钟作为参考时钟,非要搞一个跨时钟域出来?这个问题我也不是很清楚,大家有兴趣可以继续深入研究。