1、日志收集基本概念
k8s中pod的路径:
containers log: /var/log/containers/*.log
Pod log: /var/log/pods
docker log: /var/lib/docker/containers/*/*.log
如何收集日志
使用 EFK+Logstash+Kafka
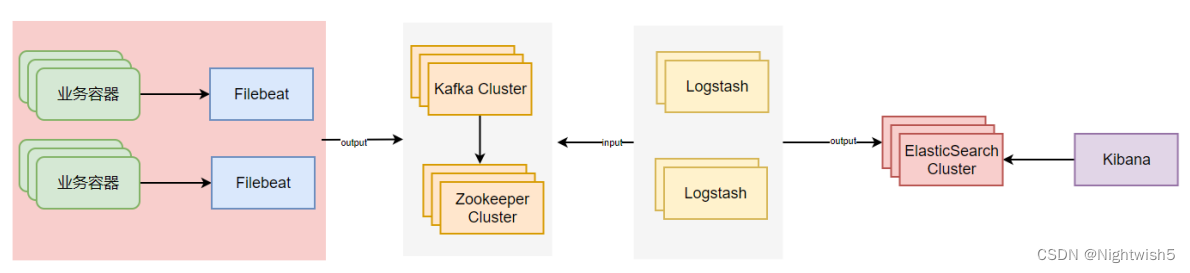
1、filebeat读取容器中的日志,然后写入Kafka集群中对应的topic(重点在于filebeat如何收集容器日志);
2、logstash从Kafka中读取数据,然后对数据进行清洗,而后写入ES对应的索引中;
3、Kibana匹配对应的ES索引,进行日志展示,分析
收集K8S哪些日志?


2、交付Elastic集群
#创建ns 、 docker-registry
kubectl create namespace logging
kubectl create secret docker-registry harbor-admin \
--docker-username=admin \
--docker-password=Harbor12345 \
--docker-server=harbor.oldxu.net \
-n logging
2.1 ES集群的构建
传统方式部署ES集群,参考:
https://blog.csdn.net/weixin_42890981/article/details/126692731
和
https://blog.csdn.net/opensystem123/article/details/128131030
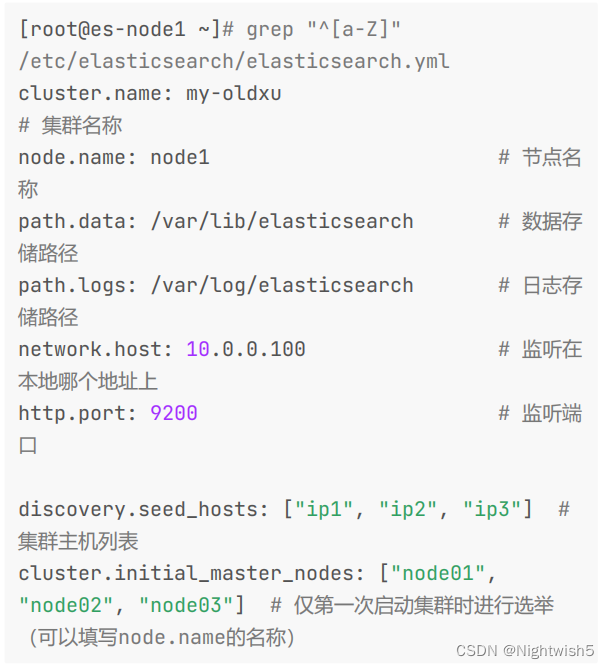
1、 ES 集群是由多个节点组成的,通过 cluster.name设置ES集群名称,同时用于区分其它的ES集群。
2、每个节点通过 node.name 参数来设定所在集群的节点名称。
3、节点使用 discovery.send_hosts 参数来设定集群节点的列表。
4、集群在第一次启动时,需要初始化,同时需要指定参与选举的master节点IP,或节点名称。
5、每个节点可以通过 node.master:true 设定为master角色,通过 node.data:true 设定为data角色。
demo:
2.2 交付ES-Service
#docker pull docker.elastic.co/elasticsearch/elasticsearch:7.17.6
docker pull elasticsearch:7.17.6
docker tag 5fad10241ffd harbor.oldxu.net/base/elasticsearch:7.17.6
docker push harbor.oldxu.net/base/elasticsearch:7.17.6
01-es-svc.yaml
#创建es-headlessService,为每个ES Pod设定固定的DNS名称,无论它是Master或是Data,易或是Coordinating
apiVersion: v1
kind: Service
metadata:
name: es-svc
namespace: logging
spec:
selector:
app: es
clusterIP: None
ports:
- name: cluster
port: 9200
targetPort: 9200
- name: transport
port: 9300
targetPort: 9300
2.3 交付ES-Master节点
1、ES无法使用root直接启动,需要授权数据目录UID=1000,同时还需要持久化/usr/share/elasticsearch/data
2、ES所有节点都需要设定 vm.max_map_count 内核参数以及ulimit;
3、ES启动是通过ENV环境变量传参来完成的
3.1、集群名称、节点名称、角色类型
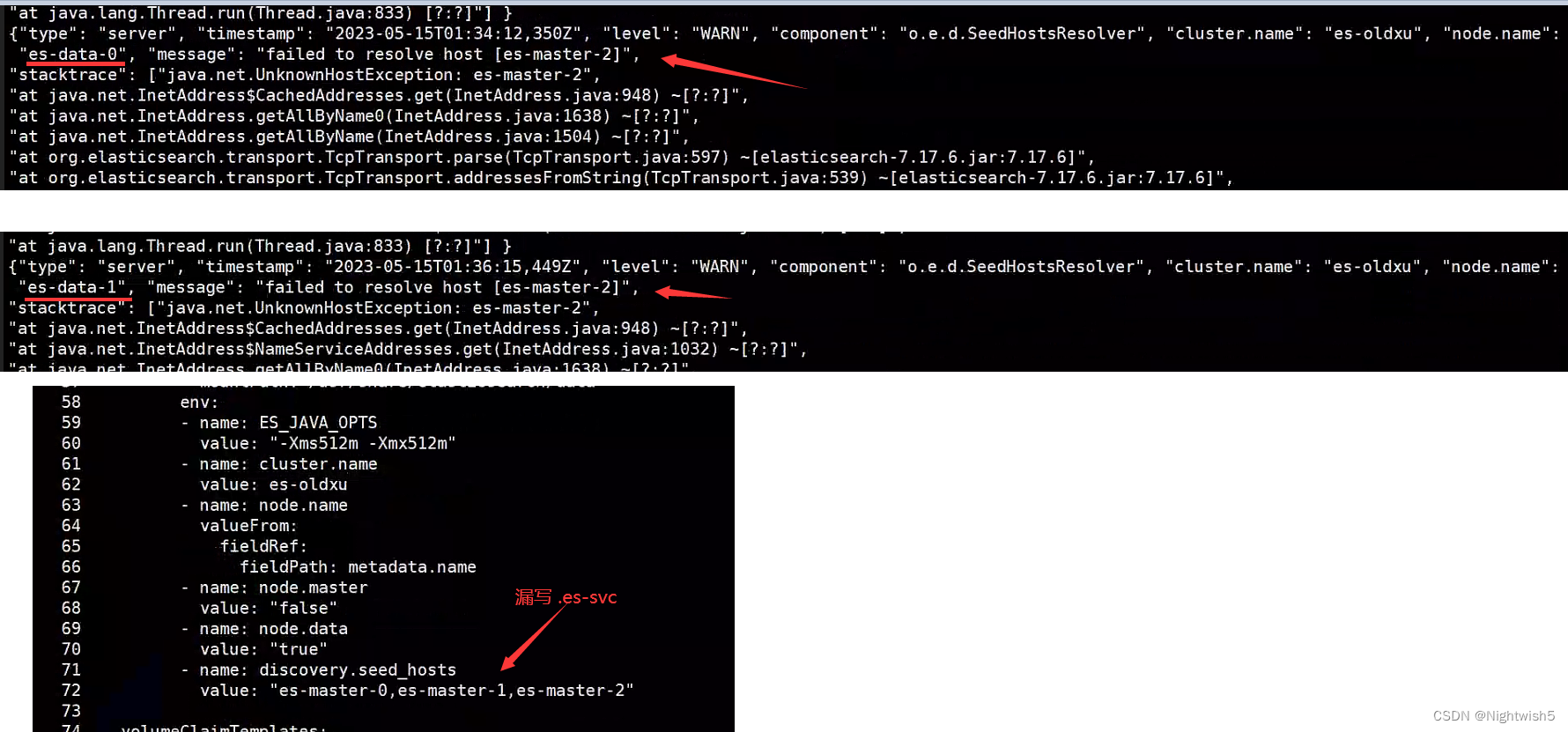
3.2、 discovery.seed_hosts 集群地址列表
3.3、 cluster.initial_master_nodes 初始集群参与选举的master节点名称;
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-master
namespace: logging
spec:
serviceName: "es-svc"
replicas: 3
selector:
matchLabels:
app: es
role: master
template:
metadata:
labels:
app: es
role: master
spec:
imagePullSecrets:
- name: harbor-admin
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["es"]
- key: role
operator: In
values: ["master"]
topologyKey: "kubernetes.io/hostname"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh","-c","chown -R 1000:1000 /usr/share/elasticsearch/data ; sysctl -w vm.max_map_count=262144; ulimit -n 65536"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
containers:
- name: es
image: harbor.oldxu.net/base/elasticsearch:7.17.6
resources:
limits:
cpu: 1000m
memory: 1024Mi
ports:
- name: cluster
containerPort: 9200
- name: transport
containerPort: 9300
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
- name: cluster.name
value: es-oldxu
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: node.master
value: "true"
- name: node.data
value: "false"
- name: discovery.seed_hosts
value: "es-master-0.es-svc,es-master-1.es-svc,es-master-2.es-svc"
- name: cluster.initial_master_nodes
value: "es-master-0,es-master-1,es-master-2"
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "nfs"
resources:
requests:
storage: 25Gi
2.4交付ES-Data节点
1、ES无法使用root直接启动,需要授权数据目录UID=1000,同时还需要持久化 /usr/share/elasticsearch/data
2、ES所有节点都需要设定 vm.max_map_count 内核参数以及ulimit;
3、ES启动是通过ENV环境变量传参来完成的
3.1、集群名称、节点名称、角色类型
3.2、 discovery.seed_hosts 集群节点地址,任意填写Master节点域名
#资源内存有限,部署2个ES-data节点
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-data
namespace: logging
spec:
serviceName: "es-svc"
replicas: 2
selector:
matchLabels:
app: es
role: data
template:
metadata:
labels:
app: es
role: data
spec:
imagePullSecrets:
- name: harbor-admin
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["es"]
- key: role
operator: In
values: ["data"]
topologyKey: "kubernetes.io/hostname"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh","-c","chown -R 1000:1000 /usr/share/elasticsearch/data ; sysctl -w vm.max_map_count=262144; ulimit -n 65536"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
containers:
- name: es
image: harbor.oldxu.net/base/elasticsearch:7.17.6
resources:
limits:
cpu: 1000m
memory: 1024Mi
ports:
- name: cluster
containerPort: 9200
- name: transport
containerPort: 9300
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
- name: cluster.name
value: es-oldxu
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: node.master
value: "false"
- name: node.data
value: "true"
- name: discovery.seed_hosts
es-master-0.es-svc,es-master-1.es-svc,es-master-2.es-svc
#value: "es-master-0,es-master-1,es-master-2"
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "nfs"
resources:
requests:
storage: 20Gi
2.5 验证ES集群
[root@master01 02-es-data-service]# dig @10.96.0.10 es-svc.logging.svc.cluster.local +short
10.244.2.169
10.244.0.3
10.244.1.213
10.244.1.212
10.244.2.164
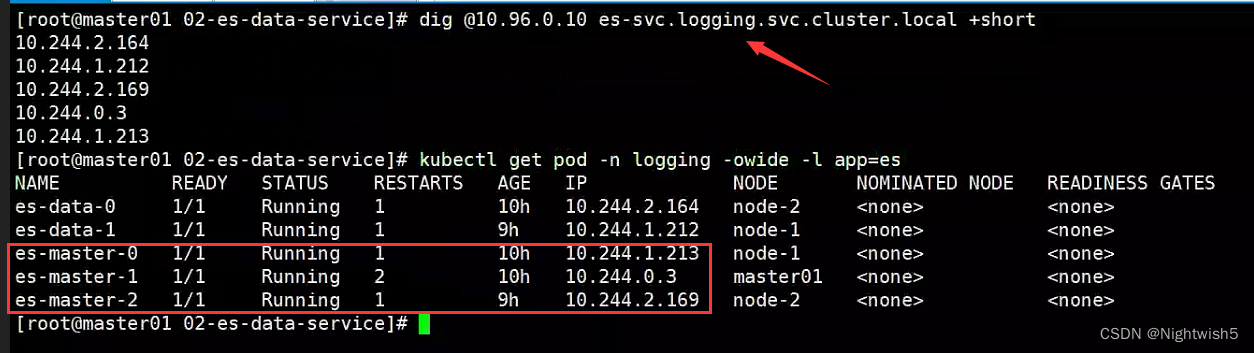
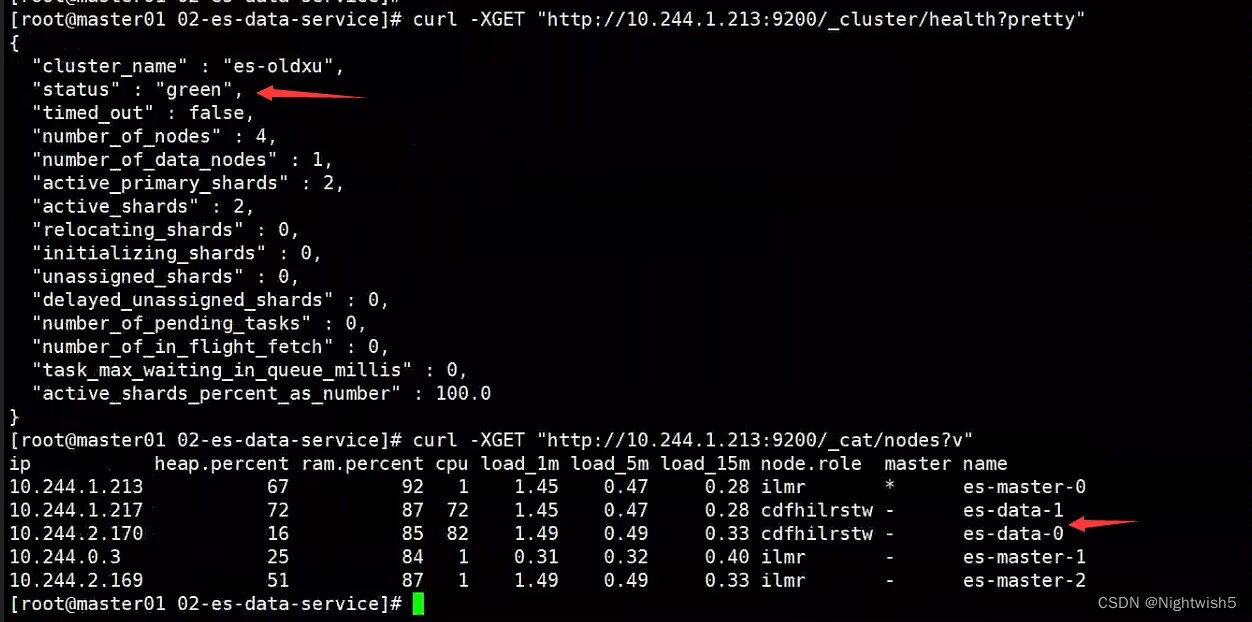
通过curl访问ES,检查ES集群是否正常(如果仅交付Master,没有data节点,集群状态可能会Red,因为没有数据节点进行数据存储;)
curl -XGET "http://10.244.1.213:9200/_cluster/health?pretty"
curl -XGET "http://10.244.1.213:9200/_cat/nodes?/v"
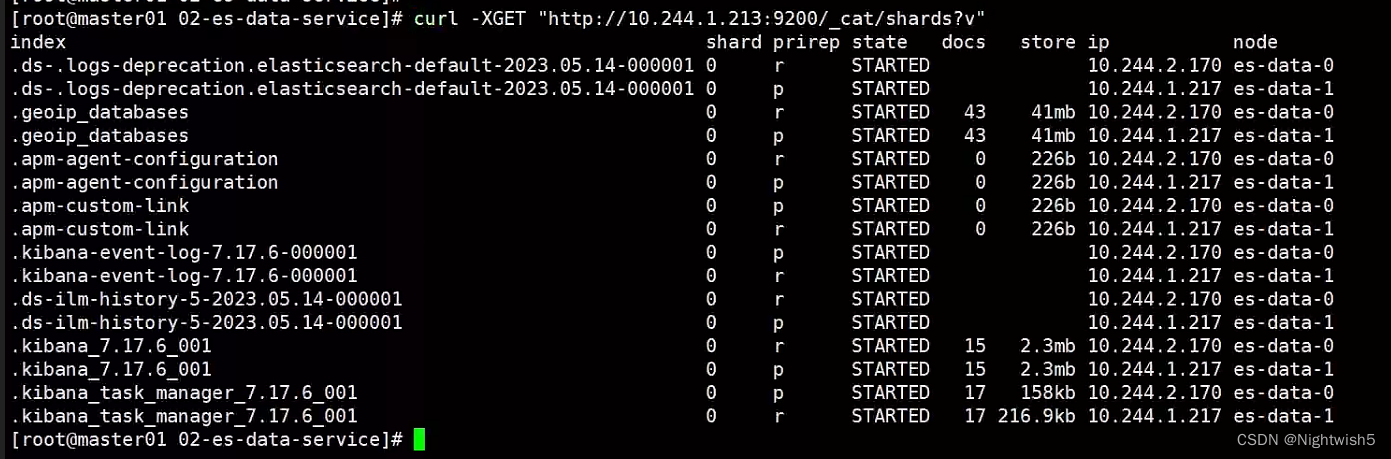
curl -XGET "http://10.244.1.213:9200/_cat/shards?v"
注意: yaml文件的- name: discovery.seed_hosts 的值,否则也会是red。
3.交付Kibana可视化
3.1 交付Kibana(dp、svc、ingress)
docker pull kibana:7.17.6
docker tag kibana:7.17.6 harbor.oldxu.net/base/kibana:7.17.6
docker push harbor.oldxu.net/base/kibana:7.17.6
#说明:
#cat /etc/kibana/kibana.yml
server.port: 5601 #kibana默认监听端口
server.host: "0.0.0.0" #kibana监听地址段
elasticsearch.hosts: ["http://localhost:9200"]
# kibana丛coordinating节点获取数据
i18n.locale: "zh-CN" #kibana汉化
01-kibana-dp.yam
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: logging
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
imagePullSecrets:
- name: harbor-admin
containers:
- name: kibana
image: harbor.oldxu.net/base/kibana:7.17.6
resources:
limits:
cpu: 1000m
ports:
- containerPort: 5601
env:
- name: ELASTICSEARCH_HOSTS
value: '["http:/es-data-0.es-svc:9200","http:/es-data-1.es-svc:9200"]'
- name: I18N_LOCALE
value: "zh-CN"
- name: SERVER_PUBLICBASEURL
value: "http://kibana.oldxu.net"
02-kibana-svc.yam
apiVersion: v1
kind: Service
metadata:
name: kibana-svc
namespace: logging
spec:
selector:
app: kibana
ports:
- name: web
port: 5601
targetPort: 5601
03-kibana-ingress.yam
#apiVersion: networking.k8s.io/v1
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: kibana-ingress
namespace: logging
spec:
ingressClassName: "nginx"
rules:
- host: "kibana.oldxu.net"
http:
paths:
- path: /
pathType: Prefix
backend:
serviceName: kibana-svc
servicePort: 5601
#service:
# name: kibana-svc
# port:
# number: 5601
3.2 访问kibana
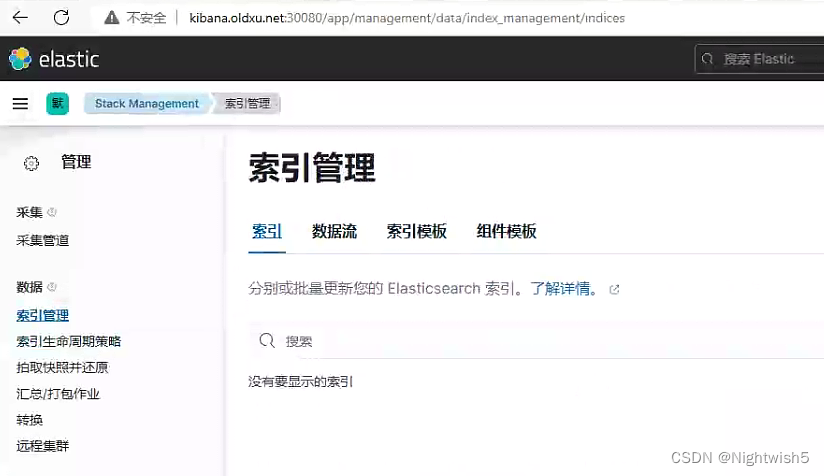
4、交付Zookeeper集群至K8S
镜像: harbor.oldxu.net/base/zookeeper:3.8.0
变量 ZOOK_SERVERS :zk集群节点通信地址
01-zk-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: zk-svc
namespace: logging
spec:
clusterIP: None
selector:
app: zk
ports:
- name: client
port: 2181
targetPort: 2181
- name: leader-follwer
port: 2888
targetPort: 2888
- name: selection
port: 3888
targetPort: 3888
02-zk-sts.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zookeeper
namespace: logging
spec:
serviceName: "zk-svc"
replicas: 3
selector:
matchLabels:
app: zk
template:
metadata:
labels:
app: zk
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["zk"]
topologyKey: "kubernetes.io/hostname"
imagePullSecrets:
- name: harbor-admin
containers:
- name: zk
image: harbor.oldxu.net/base/zookeeper:3.8.0
imagePullPolicy: IfNotPresent
ports:
- name: client
containerPort: 2181
- name: leader-follwer
containerPort: 2888
- name: selection
containerPort: 3888
env:
- name: ZOOK_SERVERS
value: "server.1=zookeeper-0.zk-svc.logging.svc.cluster.local:2888:3888 server.2=zookeeper-1.zk-svc.logging.svc.cluster.local:2888:3888 server.3=zookeeper-2.zk-svc.logging.svc.cluster.local:2888:3888"
readinessProbe:
exec:
command:
- "/bin/bash"
- "-c"
- '[[ "$(/zookeeper/bin/zkServer.sh status 2>/dev/null|grep 2181)" ]] && exit 0 || exit 1'
initialDelaySeconds: 5
livenessProbe:
exec:
command:
- "/bin/bash"
- "-c"
- '[[ "$(/zookeeper/bin/zkServer.sh status 2>/dev/null|grep 2181)" ]] && exit 0 || exit 1'
volumeMounts:
- name: data
mountPath: /data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteMany"]
storageClassName: "nfs"
resources:
requests:
storage: 21Gi
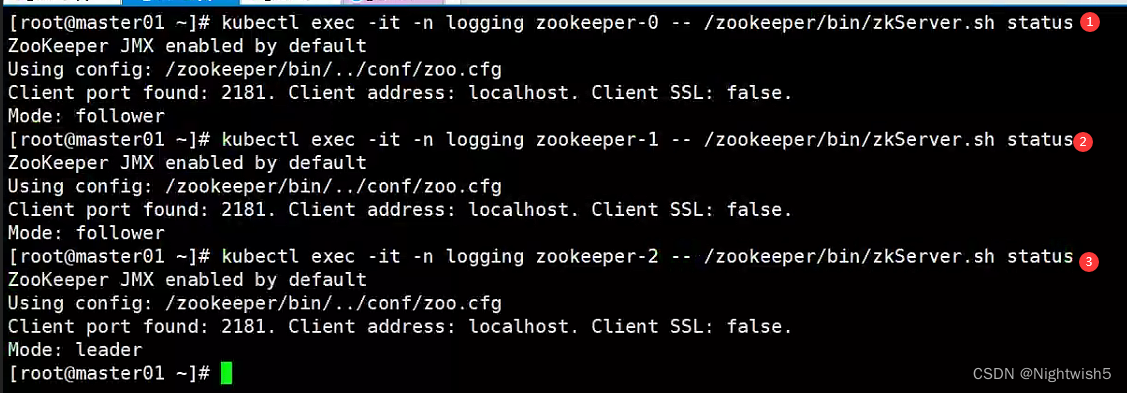
验证zk集群
kubectl exec -it -n logging zookeeper-0 -- /zookeeper/bin/zkServer.sh status
kubectl exec -it -n logging zookeeper-1 -- /zookeeper/bin/zkServer.sh status
kubectl exec -it -n logging zookeeper-2 -- /zookeeper/bin/zkServer.sh status
5、交付Kafka集群至K8S
镜像名称及tag: harbor.oldxu.net/base/kafka:2.12
变量: ZOOK_SERVERS :Kafka元数据存储ZK,需明确指定Zookeeper集群地址
01-kafka-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: kafka-svc
namespace: logging
spec:
clusterIP: None
selector:
app: kafka
ports:
- name: client
port: 9092
targetPort: 9092
- name: jmx
port: 9999
targetPort: 9999
02-kafka-sts.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
namespace: logging
spec:
serviceName: "kafka-svc"
replicas: 3
selector:
matchLabels:
app: kafka
template:
metadata:
labels:
app: kafka
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
value: ["kafka"]
topologyKey: "kubernetes.io/hostname"
imagePullSecrets:
- name: harbor-admin
containers:
- name: kafka
image: harbor.oldxu.net/base/kafka:2.12
imagePullPolicy: IfNotPresent
ports:
- name: client
containerPort: 9092
- name: jmxport
containerPort: 9999
env:
- name: ZOOK_SERVERS
value: "zookeeper-0.zk-svc:2181,zookeeper-1.zk-svc:2181,zookeeper-2.zk-svc:2181"
readinessProbe:
tcpSocket:
port: 9092
initialDelaySeconds: 5
livenessProbe:
tcpSocket:
port: 9092
initialDelaySeconds: 5
volumeMounts:
- name: data
mountPath: /data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteMany"]
storageClassName: "nfs"
resources:
requests:
storage: 20Gi
验证Kafka集群
#1、登陆任意kafka Pod,然后创建topic主题
[root@master01 ~]# kubectl exec -it -n logging kafka-0 -- bash
root@kafka-0:/# /kafka/bin/kafka-topics.sh --create --zookeeper zookeeper-0.zk-svc:2181,zookeeper-1.zk-svc:2181,zookeeper-2.zk-svc:2181 --partitions 1 --replication-factor 3 --topic oldl33
Created topic oldl33.
#2、消息发布
[root@master01 ~]# kubectl exec -it -n logging kafka-1 -- bash
root@kafka-1:/# /kafka/bin/kafka-console-producer.sh \
> --broker-list kafka-0.kafka-svc:9092,kafka-1.kafka-svc:9092,kafka-2.kafka-svc:9092 \
> --topic oldl33
>
>deploy kafka ok
>heloo kafka on k8s
>
#3、消息订阅(可以登陆其他Pod进行消息订阅)
[root@master01 ~]# kubectl exec -it -n logging kafka-2 -- bash
root@kafka-2:/# ls
bin boot data dev entrypoint.sh etc home kafka lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
root@kafka-2:/#
root@kafka-2:/# /kafka/bin/kafka-console-consumer.sh \
> --bootstrap-server kafka-0.kafka-svc:9092,kafka-1.kafka-svc:9092,kafka-2.kafka-svc:9092 \
> --topic oldl33 \
> --from-beginning
deploy kafka ok
heloo kafka on k8s
6、交付EFAK至K8S
镜像名称及tag: harbor.oldxu.net/base/efak:3.0
变量: ZOOK_SERVERS :efak需要连接Zk获取zk和kafka集群各种状态指标信息
01-efak-dp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: efak
namespace: logging
spec:
replicas: 1
selector:
matchLabels:
app: efak
template:
metadata:
labels:
app: efak
spec:
imagePullSecrets:
- name: harbor-admin
containers:
- name: efak
image: harbor.oldxu.net/base/efak:3.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 8048
env:
- name: ZOOK_SERVERS
value: "zookeeper-0.zk-svc:2181,zookeeper-1.zk-svc:2181,zookeeper-2.zk-svc:2181"
02-efak-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: efak-svc
namespace: logging
spec:
selector:
app: efak
ports:
- port: 8048
targetPort: 8048
03-efak-ingress.yaml
apiVersion: networking.k8s.io/betav1
kind: Ingress
metadata:
name: efak-ingress
namespace: logging
spec:
ingressClassName: "nginx"
rules:
- host: "efak.oldxu.net"
http:
paths:
- path: /
pathType: Prefix
backend:
serviceName: efak-svc
servicePort: 8048
#service:
# name: efak-svc
# port:
# number: 8048
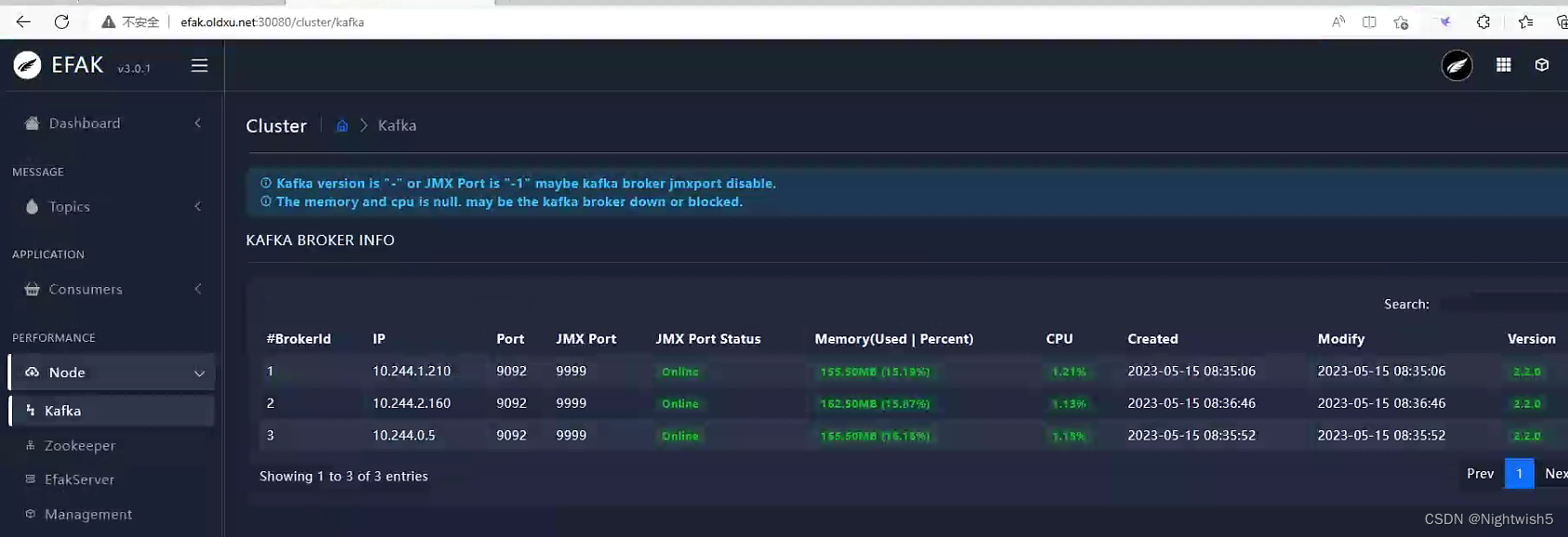
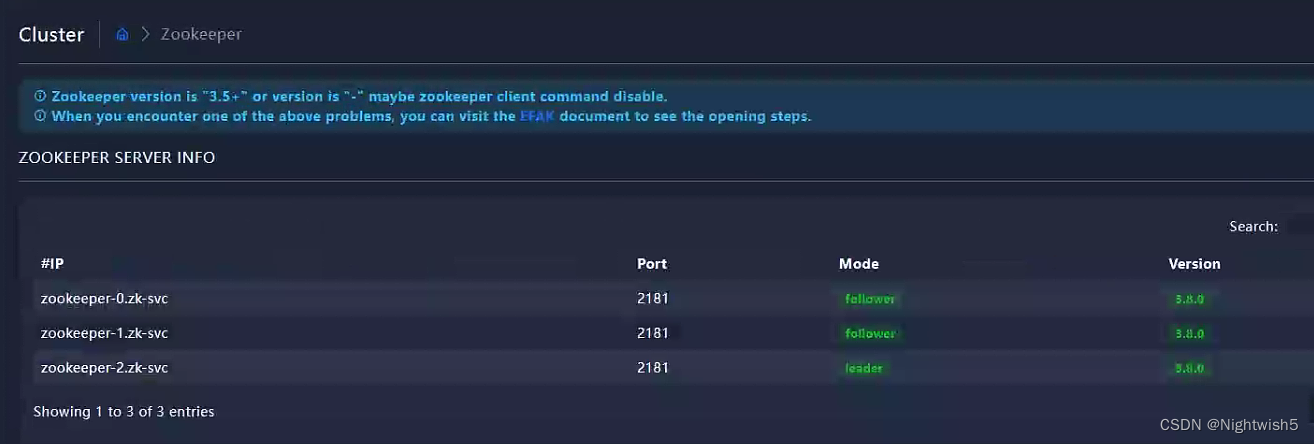
访问eagle
admin / 123456
zk和kafka状态:
END
备注:
以前的博文有详细部署zookeeper 、kafka、efak的描述
https://blog.csdn.net/Nightwish5/article/details/130389581 《zookeeper》
https://blog.csdn.net/Nightwish5/article/details/130402955 《kafka集群,efak 》