文章目录
- 哈希概念
- 例子:
- 哈希冲突
- 哈希函数
- 哈希冲突解决方法1:闭散列
- 哈希表的闭散列实现
- 闭散列结构设计
- **哈希表的插入过程:**
- **哈希表的查找过程:**
- 哈希表的删除过程:
- 只能存储key为整形的元素 那其他类型怎么解决
- CloseHash.h
- 哈希表的开散列实现
- 开散列概念
- 开散列的最坏情况及解决
- 确定负载因子
- 开散列的结构设计:
- 插入
- 查找
- 删除
- LinkHash.h
- 开散列与闭散列比较
哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较,顺序查找时间复杂度为O(N),平衡树中为树的高度,即O(logN ),搜索的效率取决于搜索过程中元素的比较次数
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素, 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素
当向该结构中:
- 插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
- 搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式即哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表或者称散列表
例子:
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小
这个函数本质是除留余数法
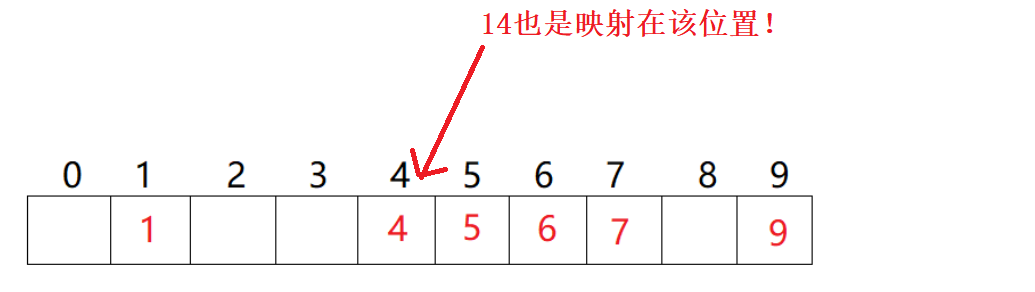
例子:集合为:{1,4,5,6,7,9} 如果我们把其存放在容量为10的哈希表中,则各元素的存储位置如下图:

用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快
哈希冲突
不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞 把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”
如上述例子中,如果我们插入14到哈希表中,就会出现哈希冲突!,因为通过哈希函数hash(14) = 14%10=4得到的地址和元素4的地址相同!都是下标为4的位置
哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理, 哈希函数设计原则
1.哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时其值域必须在0到m-1之间
2.哈希函数计算出来的地址能均匀分布在整个空间中
3.哈希函数应该比较简单
常见哈希函数
1.直接定制法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀 每个值都有一个位置的位置对应,效率高!每个元素都是一次就可以找到
缺点:需要事先知道关键字的分布情况,通常要求数据是整数/字符 范围比较集中
使用场景:适合查找比较小且连续的情况
例子:https://leetcode.cn/problems/first-unique-character-in-a-string/
2.除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p (p<=m),将关键码转换成哈希地址
优点:使用广泛,不受限制
缺点:存在哈希冲突,需要解决哈希冲突! 哈希冲突的值越多,效率越低
3.平方取中法–(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址,再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址
平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
4.折叠法–(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址
折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况
5.随机数法–(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数
通常应用于关键字长度不等时采用此法
6.数学分析法–(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现,可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址,例如:

假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是相同的,那么我们可以选择后的四位作为散列地址,如果这样的抽取工作还容易出现冲突,还可以对抽取出来的数字进行反转(如1234改成4321)、右环位移(如1234改成4123)、左环移位、前两数与后两数叠加(如1234改成12+34=46)等方法
数字分析法适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀的情况
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
哈希冲突解决方法1:闭散列
解决哈希冲突两种常见的方法是:闭散列和开散列
闭散列:也叫开放定址法,当发生哈希冲突时**,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去,那如何寻找下一个空位置呢?**
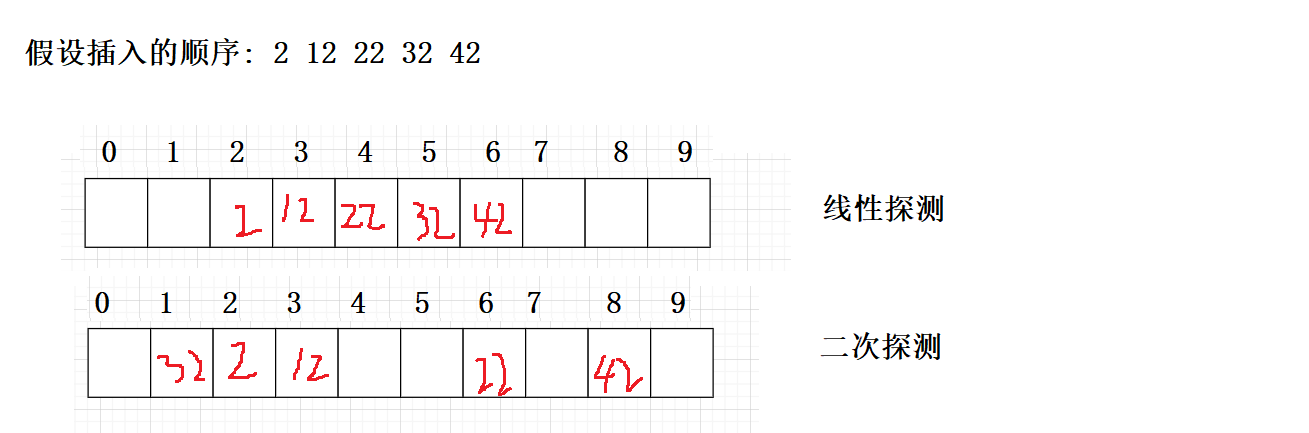
方法1:线性探测
从发生冲突的位置开始往后找,依次探测,直到找到一个空位置,插入到该位置
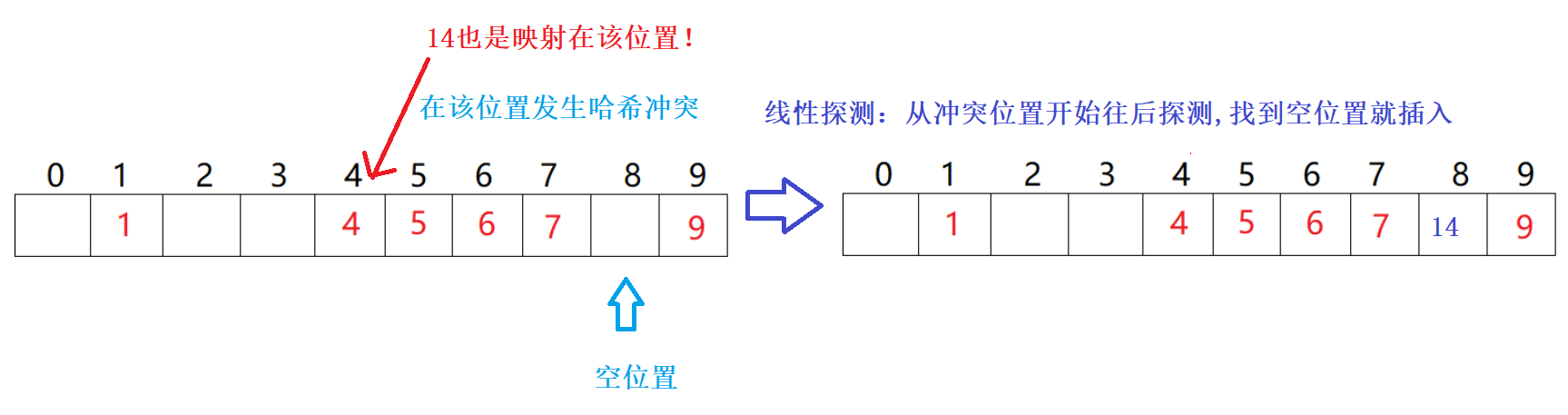
Hi=(H0+i)%m(i=1,2,3,…) 要%m ,因为不可以超出范围!
其中:
- Hi:通过哈希函数对元素的关键码进行计算得到的位置
- Hi:冲突元素通过线性探测后得到的存放位置
- m:表的大小
随着哈希表中数据的增多,产生哈希冲突的可能性也随着增加.我们将数据插入到有限的空间,那么空间中的元素越多,插入元素时产生冲突的概率也就越大,冲突多次后插入哈希表的元素,在查找时的效率必然也会降低,介于此,哈希表当中引入了负载因子(载荷因子):
负载因子的定义:负载因子 = 表中有效数据个数 / 空间的大小
- 负载因子越大,产出冲突的概率越高,增删查改的效率越低
- 负载因子越小,产出冲突的概率越低,增删查改的效率越高
负载因子越小,也就意味着空间的利用率越低,此时大量的空间实际上都被浪费了
对于闭散列(开放定址法)来说,负载因子是特别重要的因素,一般控制在0.7~0.8以下,超过0.8会导致在查表时CPU缓存不命中(cache missing)按照指数曲线上升
因此,一些采用开放定址法的hash库,如JAVA的系统库限制了负载因子为0.75,当超过该值时,会对哈希表进行增容
线性探测的优点:实现简单
线性探测的缺点:一旦发生冲突,所有的冲突连在一起,容易产生数据“堆积”,即不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要多次比较(踩踏效应),导致搜索效率降低
所以方法2:二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为
Hi = (H0 + i^i) %m i = 0,1,2,3...
其中:
- Hi:通过哈希函数对元素的关键码进行计算得到的位置
- Hi:冲突元素通过线性探测后得到的存放位置
- m:表的大小
采用二次探测为产生哈希冲突的数据寻找下一个位置,相比线性探测而言,采用二次探测的哈希表中元素的分布会相对稀疏一些,不容易导致数据堆积,和线性探测一样,采用二次探测也需要关注哈希表的负载因子
闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷
哈希表的闭散列实现
闭散列结构设计
我们这里的哈希函数是:计算哈希起始地址使用的是除留余数法 size_t start = hash(key) = key % n 其中n是元素个数
- **A%B ->其结果一定在[0,B)范围内!!!**l
哈希表中除了存放数据,还要标识当前位置的状态,其状态可能为:
- EMPTY :该位置没有存放位置,是空位置
- EXIST : 该位置已经存放数据了
- DELETE : 该位置虽然有数据,但是已经被删除了,如果我们要查找,是查不到的
我们可以使用枚举来标识这三个状态:
//每个位置状态的可能性
enum Status
{
EXIST,
EMPTY,
DELETE
};
问:为什么要用枚举来标识每个位置的状态呢?
首先我们要知道,如果我们要在哈希表查找一个元素,只要碰到空位置还没有找到,说明就没有该元素,因为我们是线性探测存放元素的,如果不设置状态,一个已经被删除的值可能被找到!
例如:

当我们在哈希表中查找元素的过程中,若当前位置的元素与待查找的元素不匹配,但是当前位置的状态是EXIST或是DELETE,那么我们都应该继续往后进行查找,而当我们插入元素的时候,可以将元素插入到状态为EMPTY或是DELETE的位置
哈希表中的每个位置节点存储的结构,应该包括所给数据和该位置的当前状态
//哈希表每个位置存储的结构
template<class K, class V>
struct HashData
{
pair<K, V> _kv;//该位置存放的数据
Status _status = EMPTY; //该位置的状态,给缺省值为EMPTY!!!否则可能是随机值
HashData(const pair<K, V>& kv)
{
_kv = kv;
_status = EMPTY;
}
HashNode() { _status = EMPTY; }//默认构造函数
};
为了在插入元素时好计算当前哈希表的负载因子,我们还应该存储哈希表中的有效元素个数,当负载因子过大时就应该进行哈希表的增容:
//哈希表
template<class K, class V>
class HashTable
{
public:
//...
private:
vector<HashData<K, V>> _table; //哈希表,vector存放的是每个节点
size_t _n = 0; //哈希表中的有效元素个数,这里是给缺省值,并不是初始化!这里是声明,初始化列表才是初始化的地方
};
哈希表的查找和删除过程都是按key来进行的 插入的是pair对象, 然后再修改状态
哈希表的插入过程:
-
不能插入重复的键值对 !所以如果已存在该键值的键值 则插入失败,直接返回
-
判断是否需要增容,若哈希表的大小为0 || 负载因子过大 都需要对哈希表的大小进行调整,进行增容
-
负载因子:
表中有效数据个数 / 空间的大小 -> 即_n/_tables.size() -
如何增容?
最初哈希表的大小为0: 先给哈希表开10个空间
若哈希表的负载因子大于0.7,则重新构造一个新的哈希表,该哈希表的大小为原哈希表的两倍,之后遍历原哈希表,将原哈希表中的数据插入到新哈希表,最后将原哈希表与新哈希表交换即可
注意: 在将原哈希表的数据插入到新哈希表的过程中,不能只是简单的将原哈希表中的数据对应的挪到新哈希表中,而是需要根据新哈希表的大小重新计算每个数据在新哈希表中的位置,然后再进行插入 (因为增容了,原来冲突的位置可能不冲突了,相对位置发生改变)
如:

-
-
插入键值对到哈希表中
-
如何插入?
- 通过哈希函数计算出对应的哈希地址
- 若产生哈希冲突,则从计算出的哈希地址位置开始,采用线性探测的方式, 向后寻找一个状态为EMPTY或DELETE的位置进行插入
- 将键值对插入到该位置,并将该位置的状态设置为EXIST
-
注意: 产生哈希冲突向后进行线性探测时,一定会找到一个合适位置进行插入,因为哈希表的负载因子是控制在0.7以下的,也就是说哈希表永远都不会被装满
-
-
哈希表中的有效元素n加一
//插入函数
bool Insert(const pair<K, V>& kv)
{
//现在哈希表中是否存在该键值的键值对.存在则不需要处理,返回false
//查找是根据key查找,所以传kv的第一个成员!!!!!
HashData<K, V>* ret = Find(kv.first);
if (ret) //哈希表中已经存在该键值的键值对(不允许数据冗余)
{
return false; //插入失败
}
//判断是否需要调整哈希表的大小(判断是否需要增容)
if (_table.size() == 0) //最初哈希表大小为0
{
_table.resize(10); //初始化哈希表的大小为10
}
// 负载因子到0.7,就扩容
// 负载因子越小,冲突概率越低,效率越高,空间浪费越多
// 负载因子越大,冲突概率越高,效率越低,空间浪费越少
else if ((double)_n / (double)_table.size() > 0.7) //负载因子大于0.7需要增容
{
//增容
//先创建一个新的哈希表,新哈希表的大小设置为原哈希表的2倍
HashTable<K, V> newHT;
newHT._table.resize(2 * _table.size());
//将原哈希表当中的数据插入到新哈希表
for (auto& e : _table)
{
if (e._state == EXIST)
{
newHT.Insert(e._kv); //会去调用Insert函数,然后根据新插入后的大小去重新计算哈希地址
}
}
//交换这两个哈希表
_table.swap(newHT._table);
}
/* 写法2
//判断是否需要增容 -> 没有元素 || 负载因子>=0.7
//为了不强制成浮点数,所以*10
if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7)
{
//最初大小为0.先给10个,不够就2倍增
size_t newSize = _tables.size() == 0 ? 10 : 2 * _tables.size();
HashTable<K, V> newHT;//创建一个新表
newHT._tables.resize(newSize);//为新表开辟newSize个空间
for (int i = 0; i < _tables.size(); i++)
{
//不能直接插入!要检测该位置的状态是否存在
if (_tables[i].status == EXIST)
{
newHT.insert(_tables[i]._kv);
}
}
//交换两个表的数据 ->相当于是两个vector交换
_tables.swap(newHT._tables);
}
*/
//将键值对插入哈希表
//通过哈希函数计算哈希起始地址
// 此时的key是:kv.first
size_t start = kv.first % _table.size(); //除数不能是capacity
size_t index = start;
size_t i = 0;
//找到一个状态为EMPTY或DELETE的位置插入
while (_table[index]._state == EXIST)
{
i++;
index = start + i; //线性探测
//index = start + i*i; //二次探测
index %= _table.size(); //防止下标超出哈希表范围,相当于一个闭环圈
}
//在index位置插入 _table存放的是节点(数据+状态)
_table[index]._kv = kv;
_table[index]._state = EXIST;//状态设置为存在
//哈希表中的有效元素个数加一
_n++;
return true;
}
问:计算哈希地址的时候选哪个计算
//kv是要插入的元素
size_t i = kv.first % _tables.size() //选择它!
size_t i = kv.first % _tables.capacity()
为什么是%size呢? 因为最后插入的时候:vector的[]会检查范围,而[i]的范围是: i<size
比如说:
现在有20个空间(capacity = 20),而size = 11,只有11个有效元素,我们不能访问10下标后面的元素!否则就会导致越界
vector<int> v;
v.reserve(10);
for(int i = 0;i<10;i++)
{
cin >> v[i];
}
//为什么会出错呢?
因为[]有检查,只能访问size范围之内的数, reserve(10) :capacity=10,但是size仍为0,空间是你的,但是你展示不能直接访问!
//怎么修改呢?
v.resize(10) resize(10):capacity=size=10
当连续位置值冲突比较多的时候,会引发“踩踏洪水效应”.为此我们可以选择二次探测更好
例如:
哈希表的查找过程:
- 通过哈希函数计算出对应的哈希地址
- 从哈希地址处开始向后采用线性探测向后查找数据,如果找到待查找的元素判定为查找成功,或找到一个状态为EMPTY的位置判定为查找失败
注意: 在查找过程中,必须找到位置状态为EXIST,并且key值匹配的元素,才算查找成功,若仅仅是key值匹配,但该位置当前状态为DELETE,则还需继续进行查找,因为该位置的元素已经被删除了
还要注意的是:我们的HashData结构的构造函数要给初始值给_status,否则就是随机值!!!
//查找函数 -返回被查找节点的地址
HashData<K, V>* Find(const K& key)
{
if (_table.size() == 0) //哈希表大小为0,查找失败
{
return nullptr;
}
size_t start = key % _table.size(); //通过哈希函数计算哈希地址(除数不能是_tables.capacity())
size_t index = start;
size_t i = 0;
//直到找到空位置为止,不止探测一次,所以循环探测
while (_table[index]._state != EMPTY)
{
//若该位置的状态为EXIST,并且key值匹配,则查找成功
if (_table[index]._state == EXIST && _table[index]._kv.first == key)
{
return &_table[index];
}
i++;
index = start + i; //线性探测
//index = start + i*i; //二次探测
index %= _table.size(); //防止下标超出哈希表范围
}
return nullptr; //直到找到空位置还没有找到目标元素,查找失败
}
哈希表的删除过程:
我们只需要把要删除位置的元素的状态设置为DELETE即可
- 查看哈希表中是否存在该键值的键值对,若不存在则删除失败
- 若存在,则将该键值对所在位置的状态改为DELETE
- 哈希表中的有效元素个数减一
注意: 虽然删除元素时没有将该位置的数据清0,只是将该元素所在状态设为了DELETE,但是并不会造成空间的浪费,因为我们在插入数据时是可以将数据插入到状态为DELETE的位置的,此时插入的数据就会把该数据覆盖
//删除函数
bool Erase(const K& key)
{
if(_tables.size() == 0)
{
return false;
}
//1、查看哈希表中是否存在该键值的键值对
HashData<K, V>* ret = Find(key);
if (ret)
{
//若存在,则将该键值对所在位置的状态改为DELETE即可
ret->_state = DELETE;
//3、哈希表中的有效元素个数减一
_n--;
return true;
}
return false;
}
只能存储key为整形的元素 那其他类型怎么解决
如果我们的key是string类型或者是其它类型呢? 那就不能支持hash(key) = key/n取模求哈希起始地址
如果是string类型:我们可以把字符串转为固定的值,然后用该值取模
方法1:将所有字符的ascii拼接起来 ->不可行!!因为会导致相同的字母,顺序不同,但是值相同 导致不插入
方法2:BKDR算法 先让value乘一个数,然后再加上当前字符的ascii值
struct HashStr
{
size_t operator()(const string& s)
{
size_t value = 0;
for(auto ch :s)
{
value*=31;
value+=ch;
}
return value;
}
}
但是仍是解决不了哈希冲突的!因为字符串是无限的,整形是有限的
所以如何做呢?如果我们想让所有类型都能取模: 加一个仿函数模板参数 对不能直接求值的:偏特化一个模板
//int直接转化 string就特化
template<class K>
//仿函数
struct Hash
{
//将返回值转为无符号整数!这样可以把负数也处理了!
//负数也可以取模, 我们把其的hash(key)转为无符号数
//不可以用abs处理负数,因为可能导致-9和9这种重复,导致不插入
size_t operator()(const K& key)
{
return key;
}
};
// 为string特化一个仿函数!
template<>
struct Hash < string > //为字符串准备的
{
//字符串转为整形
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
//第三个模板的参数是缺省值为key的仿函数
template<class K, class V, class HashFunc = Hash<K>>
class HashTable
{
//当key是定义类型时,需要配置一个仿函数,将key转为整形
//所有需要计算哈希起始地址的都写成:size_t start = HashFunc(key) % _tables.size();
//定义HashTable的时候,也需要传仿函数:HashTable<K, V, HashFunc> newHT; HashFunc是默认的,也可以不写
//调用仿函数HashFunc处理key. 转为整型值计算
};
//使用例子:
HashTable<Date,string,HashDate> htds;//key为Date类 HashDate是为Date类实现的仿函数转为整形
这样如果我们想要用日期类作为key:我们只需要考虑如何实现这个仿函数把这个类型的对象转为可以取模的整形值即可, 可以年月日加起来 …
如果是Person类作为key,可以用身份证 /电话号码等来作为取模的方式
不管用什么作为key,如果不能直接转为整形值,就为该类型特化一个仿函数即可!
CloseHash.h
template<class K>
struct Hash
{
size_t operator()(const K& key)
{
return key;
}
};
// 特化
template<>
struct Hash <string>
{
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
namespace CloseHash
{
enum Status
{
EXIST,
EMPTY,
DELETE
};
template<class K, class V>
struct HashData
{
pair<K, V> _kv;
Status _status = EMPTY;
};
template<class K, class V, class HashFunc = Hash<K>>
class HashTable
{
public:
bool Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret == nullptr)
{
return false;
}
else
{
--_n;
ret->_status = DELETE;
return true;
}
}
HashData<K, V>* Find(const K& key)
{
if (_tables.size() == 0)
{
return nullptr;
}
HashFunc hf;
size_t start = hf(key) % _tables.size();
size_t i = 0;
size_t index = start;
// 线性探测 or 二次探测
while (_tables[index]._status != EMPTY)
{
if (_tables[index]._kv.first == key && _tables[index]._status == EXIST)
{
return &_tables[index];
}
++i;
//index = start + i*i;
index = start + i;
index %= _tables.size();
}
return nullptr;
}
bool Insert(const pair<K, V>& kv)
{
HashData<K, V>* ret = Find(kv.first);
if (ret)
{
return false;
}
// 负载因子到0.7,就扩容
// 负载因子越小,冲突概率越低,效率越高,空间浪费越多
// 负载因子越大,冲突概率越高,效率越低,空间浪费越少
if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7)
{
// 扩容
size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;
HashTable<K, V, HashFunc> newHT;
newHT._tables.resize(newSize);
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i]._status == EXIST)
{
newHT.Insert(_tables[i]._kv);
}
}
_tables.swap(newHT._tables);
}
HashFunc hf;
size_t start = hf(kv.first) % _tables.size();
size_t i = 0;
size_t index = start;
// 线性探测 or 二次探测
while (_tables[index]._status == EXIST)
{
++i;
//index = start + i*i;
index = start + i;
index %= _tables.size();
}
_tables[index]._kv = kv;
_tables[index]._status = EXIST;
++_n;
return true;
}
private:
vector<HashData<K, V>> _tables;
size_t _n = 0; // 有效数据个数
};
void TestHashTable1()
{
//HashTable<int, int, Hash<int>> ht;
HashTable<int, int> ht;
int a[] = { 2, 12, 22, 32, 42, 52, 62 };
for (auto e : a)
{
ht.Insert(make_pair(e, e));
}
ht.Insert(make_pair(72, 72));
ht.Insert(make_pair(32, 32));
ht.Insert(make_pair(-1, -1));
ht.Insert(make_pair(-999, -999));
Hash<int> hs;
cout << hs(9) << endl;
cout << hs(-9) << endl;
cout << ht.Find(12) << endl;
ht.Erase(12);
cout << ht.Find(12) << endl;
}
}
哈希表的开散列实现
开散列概念
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中
闭散列解决哈希冲突, 采用的是一种强盗的方式----我的位置被占用了就去往后占用其他位置
而开散列解决哈希冲突,采用的是一种往下挂的方式,虽然我的位置被占用了->我可以‘挂’在这个位置下面,形成一条链
例如:在表长为10的哈希表中插入:{3,23,33,43,20,30}
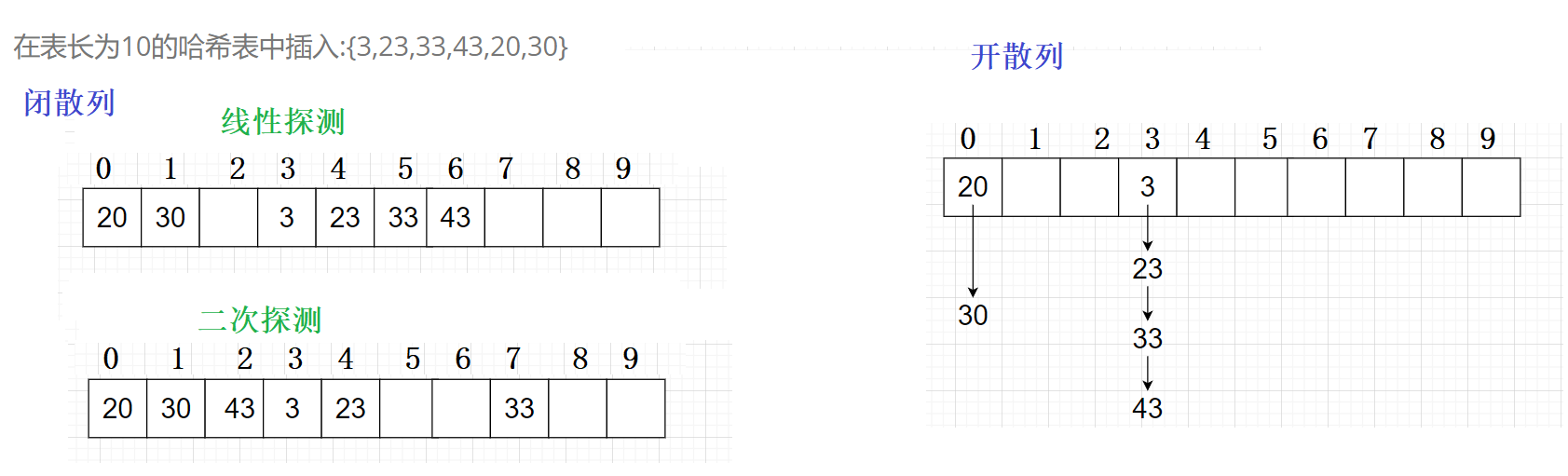
开散列中每个桶中放的都是发生哈希冲突的元素 每个位置相当于是一个桶,桶里面是一条链表
开散列不会影响与自己哈希地址不同的元素的增删查改的效率,因此开散列的负载因子相比闭散列而言,可以稍微大一点
- 闭散列的开放定址法,负载因子不能超过1,一般建议控制在[0.0, 0.7]之间
- 开散列的哈希桶,负载因子可以超过1,一般建议控制在[0.0, 1.0]之间
开散列的最坏情况及解决
为什么开散列的哈希桶结构比闭散列更实用?
哈希桶的负载因子可以更大,空间利用率高 哈希桶在极端情况下还有可用的解决方案
最坏情况:所有元素全部产生冲突,最终都放到了同一个哈希桶中 此时该哈希表增删查改的效率就是O(N)
此时我们的解决办法是:将单链表结构改为红黑树结构,并将红黑树的根结点存储在哈希表中 此时每个位置是一个桶,桶里面是一棵红黑树
- 就算此时有10E个元素全部冲突到一个哈希桶中,我们也只需要在这个哈希桶中查找30次左右
为了避免出现这种极端情况,当桶当中的元素个数超过一定长度,有些地方就会选择将该桶中的单链表结构换成红黑树结构
- 比如在JAVA中比较新一点的版本中,当桶当中的数据个数超过8时,就会将该桶当中的单链表结构换成红黑树结构,而当该桶当中的数据个数减少到8或8以下时,又会将该桶当中的红黑树结构换回单链表结构
但有些地方也会选择不做此处理,因为随着哈希表中数据的增多,该哈希表的负载因子也会逐渐增大,最终会触发哈希表的增容条件,此时该哈希表当中的数据会全部重新插入到另一个空间更大的哈希表,此时同一个桶当中冲突的数据个数也会减少,增容之后,冲突的数据可能不冲突了!
确定负载因子
如何确定负载因子定为多少的时候增容:
桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下可能会导致一个桶中链表节点非常多会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容
开散列最好的情况是:每个哈希桶中刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此在元素个数刚好等于桶的个数时可以给哈希表增容 **即:负载因子为1 —_n==_tables.size() **的时候增容
开散列的结构设计:
开散列中: 哈希表的每个位置存储的实际上是每个位置的单链表的头结点
即每个哈希桶中存储的数据实际上是一个结点类型,该结点类型除了存储所给数据之外,还需要存储一个结点指针用于指向下一个结点
//每个哈希桶存储的结构-单链表节点
template<class K,class V>
struct HashNode
{
pair<K, V> _kv;//存放数据
HashNode<K, V>* _next;//指向下一个位置
HashNode(const pair<K,V>& kv)
:_kv(kv)
,_next(nullptr)
{}
};
开散列的方式实现的时候 : 不需要为每个位置设置一个状态 因为此时是将哈希地址相同的元素都放到了同一个哈希桶中,并不需要经过探测寻找下一个位置
但是我们仍需要知道哈希表中有效数据的个数,在插入数据时也需要根据负载因子判断是否需要增容
哈希函数采用处理余数法被模的key必须要为整形才可以处理,为了方便转化其它类型,我们直接增设一个仿函数的模板参数
整形数据不需要转化
template<class K>
struct Hash
{
//将返回值转为无符号整数!这样可以把负数也处理了!
size_t operator()(const K& key)
{
return key;
}
};
// 特化key为字符串类型,需要将其转化为整形
template<>
struct Hash < string >
{
size_t operator()(const string& s)
{
// BKDR算法 -保证每个字符串对应的值不同
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
template<class K, class V,class HashFunc = Hash<K>>
class HashTable
{
public:
typedef HashNode<K, V> Node;//结点的类型
private:
vector<Node*> _tables;//哈希表,每个位置都是一个桶存放一条单链表
size_t _n = 0;//哈希表中的有效元素个数
};
所以计算利用哈希函数计算哈希地址就变为:
//K,V,和HashFunc都是类型
HashFunc hf;//定义仿函数,默认就是Hash<K>
size_t index = hf(key) %_tables.size();
其中hf(key)的作用就是:利用自己实现/特化的仿函数将key转化为整形,然后使用除留余数法计算哈希地址
表达式的含义:
- _tables[i] 得到的是哈希表中下标为i桶位置链表的头节点,类型是Node*
- 插入的是pair对象,查找/计算哈希地址/比较是根据key来的, 所以应该用pair的第一个成员作为计算
- 插入的时候:计算哈希地址:
hf(kv.first)%_tables.size()
- 插入的时候:计算哈希地址:
插入
具体步骤:
-
先查找要插入的数据是否已经存在,若已存在则返回,不再插入 (不允许数据冗余)
-
判断是否需要增容, 何时增容: 最初我们将哈希表的大小设为0|| 负载因子过大(看上面分析,负载因子为1的时候就需要增容)
-
增容方法:
若哈希表的大小为0,则将哈希表的初始大小设置为10
若哈希表的负载因子为1 ,则先创建一个新的哈希表该哈希表的大小为原哈希表的两倍,之后遍历原哈希表,将原哈希表中的数据插入到新哈希表,最后将原哈希表与新哈希表交换
-
问:我们闭散列的时候,将原哈希表的数据插入到新哈希表的过程中是通过复用插入函数将原哈希表中的数据插入到新哈希表,这里为什么不这样干呢?
- 因为在这个过程中我们需要创建相同数据的结点插入到新哈希表, 在插入完成后还需要将原哈希表中的结点进行释放,麻烦!
- 我们只需要遍历原哈希表的每个哈希桶,通过哈希函数将每个哈希桶中的结点重新找到对应位置插入到新哈希表即可,不用进行结点的创建与释放
-
-
因为哈希表的大小发生改变,原来冲突的可能不冲突了,我们要根据哈希函数计算出插入元素对应的哈希地址 然后将数据插入到哈希表,若产生哈希冲突则直接将该结点头插到对应单链表即可
- 此时何为哈希冲突呢?如果当前哈希地址的位置为空,说明当前节点是第一个节点,没有哈希冲突,更新当前位置的头节点为当前节点, 否则就是哈希冲突 得头插当前节点,也要更新头节点
-
哈希表中的有效元素个数加一
问:插入的时候以及增容的时候选择什么方式插入比较好?
- 在增容时取结点都是从单链表的表头开始向后依次取的,在插入结点时也是直接将结点头插到对应单链表
- 头取头插
bool Insert(const pair<K, V>& kv)
{
//先查找是否已经有该Key对应的元素了,如果已经有,则不插入
Node* ret = Find(kv.first);
if (ret)
{
return false;//插入失败,直接返回
}
HashFunc hf;//声明仿函数(HashFunc是一个类型,我们已经实现了Hash,HashFunc就是Hash),用于将key转为整形
//判断是否需要增容-负载因子为1就增容
if (_n == _tables.size())
{
//最初哈希表大小为0,给10个空间,否则二倍增容
size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;
//创建一个新的哈希表,新哈希表的大小设置为原哈希表的2倍 (最初:新哈希表大小设置为10)
vector<Node*> newTables;
newTables.resize(newSize);//为新哈希表开辟空间
//把原哈希表的数据拷贝到新哈希表
for (int i = 0; i < _tables.size(); i++)
{
//将每个桶位置的链表中的所有节点都插入到新哈希表
//需要重新计算每个桶中节点的哈希地址
Node* cur = _tables[i];//拿到当前桶中链表的头节点
//处理整条链表
while (cur)
{
Node* next = cur->_next;//提前保存下一个节点位置
//通过哈希函数计算当前节点应该插入到新哈希表的哪个桶,注意%的是新哈希表的大小
size_t index = hf(cur->_kv.first) % newTables.size();
//头插到新哈希表下标为index位置桶的链表中
cur->_next = newTables[index];
newTables[index] = cur;//更换头
//处理原哈希表i位置桶的链表的下一个节点
cur = next;
}
//原哈希表的i位置桶的链表头节点置为空
_tables[i] = nullptr;
}
//交换两个哈希表
_tables.swap(newTables);
}
//插入当前对象
//利用哈希函数计算当前对象应该插入到哪个桶中
size_t index = hf(kv.first) % _tables.size();
Node* newnode = new Node(kv);//新建头节点插入
//头插到index桶的链表中
newnode->_next = _tables[index];
_tables[index] = newnode;//更新头节点
++_n;//有效元素++
return true;//插入成功
}
查找
具体步骤:
1.如果哈希表的大小为0,则直接返回false
2.通过哈希函数计算出要查找的元素所在的桶号(哈希地址)
3.遍历该哈希地址对应的哈希桶的单链表,进行查找
//根据key查找
//返回待查找节点
Node* Find(const K& key)
{
//如果哈希表的大小为0,查找失败,返回空指针
if (_tables.size() == 0)
{
return nullptr;
}
HashFunc hf;//声明仿函数(HashFunc是一个类型,我们已经实现了Hash,HashFunc就是Hash),用于将key转为整形
size_t index = hf(key) % _tables.size();//用哈希函数计算该元素所在的桶编号
//遍历index位置桶对应的链表,判断该条链表是否有与Key值相同的元素
Node* cur = _tables[index];
while (cur)
{
//如果key值匹配,则查找成功,返回该节点
if (cur->_kv.first == key)
{
return cur;
}
else
{
cur = cur->_next;
}
}
//如果index号桶遍历完成都没有找到,说明待查找元素不在哈希表中
return nullptr;
}
删除
具体步骤:
1.通过哈希函数计算出要查删除的元素的哈希地址
2.遍历该哈希地址对应的哈希桶的单链表,找到要删除的节点
3.更新待删除节点的前后节点的关系,如果是头节点则需要更新头节点
4.释放该节点,有效元素个数减1
注意:这里我们不必先调用查找函数判断我们要删除的节点是否存在,如果不存在还好,直接返回了,如果存在,我们找到之后,还需要重新查找到该节点然后调整其前后节点的关系再删除, 直接一开始就找效率更高!找到了就删除
bool Erase(const K& key)
{
//哈希表为空,直接返回,不删除
if (_tables.size() == 0)
{
return false;
}
HashFunc hf;
//利用哈希函数计算出要删除元素所在哈希表的桶号
size_t index = hf(key) % _tables.size();
Node* cur = _tables[index];//得到该桶中链表的节点
Node* pre = nullptr;//用于保存前一个节点,因为要前后节点链接
while (cur)
{
//key匹配->找到了删除节点的位置
if (cur->_kv.first == key)
{
//要删除cur位置节点,处理前后节点关系
//有可能要删除的是该桶的头节点
if (cur == _tables[index]) //头删 判断条件也可以写成:pre == nullptr
{
_tables[index] = cur->_next;//更换头节点
}
else //待删节点不是头节点
{
//pre cur->_next 链接
pre->_next = cur->_next;
}
--_n;//有效元素减1
delete cur;//删除节点
return true;//删除成功
}
else
{
pre = cur;//记录当前节点
cur = cur->_next;//往后走
}
}
//说明要删除的元素不存在,删除失败
return false;
}
LinkHash.h
#pragma once
#include<vector>
//哈希函数1
template<class K>
struct Hash
{
size_t operator()(const K& key)
{
return key;
}
};
//哈希函数2
template<>
struct Hash<string>
{
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
//每个哈希桶存储的结构-哈希表节点
template<class K,class V>
struct HashNode
{
pair<K, V> _kv;//存放数据
HashNode<K, V>* _next;//指向下一个位置
HashNode(const pair<K,V>& kv)
:_kv(kv)
,_next(nullptr)
{}
};
//开散列的哈希实现
namespace LinkHash
{
template<class K, class V, class HashFunc = Hash<K>>
class HashTable
{
public:
typedef HashNode<K, V> Node;//结点的类型
//根据key查找
//返回待查找节点
Node* Find(const K& key)
{
//如果哈希表的大小为0,查找失败,返回空指针
if (_tables.size() == 0)
{
return nullptr;
}
HashFunc hf;//定义仿函数,用于将key转为整形
size_t index = hf(key) % _tables.size();//用哈希函数计算该元素所在的桶编号
//遍历index位置桶对应的链表,判断该条链表是否有与Key值相同的元素
Node* cur = _tables[index];
while (cur)
{
//如果key值匹配,则查找成功,返回该节点
if (cur->_kv.first == key)
{
return cur;
}
else
{
cur = cur->_next;
}
}
//如果index号桶遍历完成都没有找到,说明待查找元素不在哈希表中
return nullptr;
}
bool Insert(const pair<K, V>& kv)
{
//先查找是否已经有该Key对应的元素了,如果已经有,则不插入
Node* ret = Find(kv.first);
if (ret)
{
return false;//插入失败,直接返回
}
HashFunc hf;//声明仿函数(HashFunc是一个类型,我们已经实现了Hash,HashFunc就是Hash),用于将key转为整形
//判断是否需要增容-负载因子为1就增容
if (_n == _tables.size())
{
//最初哈希表大小为0,给10个空间,否则二倍增容
size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;
//创建一个新的哈希表,新哈希表的大小设置为原哈希表的2倍 (最初:新哈希表大小设置为10)
vector<Node*> newTables;
newTables.resize(newSize);//为新哈希表开辟空间
//把原哈希表的数据拷贝到新哈希表
for (int i = 0; i < _tables.size(); i++)
{
//将每个桶位置的链表中的所有节点都插入到新哈希表
//需要重新计算每个桶中节点的哈希地址
Node* cur = _tables[i];//拿到当前桶中链表的头节点
//处理整条链表
while (cur)
{
Node* next = cur->_next;//提前保存下一个节点位置
//通过哈希函数计算当前节点应该插入到新哈希表的哪个桶,注意%的是新哈希表的大小
size_t index = hf(cur->_kv.first) % newTables.size();
//头插到新哈希表下标为index位置桶的链表中
cur->_next = newTables[index];
newTables[index] = cur;//更换头
//处理原哈希表i位置桶的链表的下一个节点
cur = next;
}
//原哈希表的i位置桶的链表头节点置为空
_tables[i] = nullptr;
}
//交换两个哈希表
_tables.swap(newTables);
}
//插入当前对象
//利用哈希函数计算当前对象应该插入到哪个桶中
size_t index = hf(kv.first) % _tables.size();
Node* newnode = new Node(kv);//新建头节点插入
//头插到index桶的链表中
newnode->_next = _tables[index];
_tables[index] = newnode;//更新头节点
++_n;//有效元素++
return true;//插入成功
}
bool Erase(const K& key)
{
//哈希表为空,直接返回,不删除
if (_tables.size() == 0)
{
return false;
}
HashFunc hf;
//利用哈希函数计算出要删除元素所在哈希表的桶号
size_t index = hf(key) % _tables.size();
Node* cur = _tables[index];//得到该桶中链表的节点
Node* pre = nullptr;//用于保存前一个节点,因为要前后节点链接
while (cur)
{
//key匹配->找到了删除节点的位置
if (cur->_kv.first == key)
{
//要删除cur位置节点,处理前后节点关系
//有可能要删除的是该桶的头节点
if (cur == _tables[index]) //头删 判断条件也可以写成:pre == nullptr
{
_tables[index] = cur->_next;//更换头节点
}
else //待删节点不是头节点
{
//pre cur->_next 链接
pre->_next = cur->_next;
}
--_n;//有效元素减1
delete cur;//删除节点
return true;//删除成功
}
else
{
pre = cur;//记录当前节点
cur = cur->_next;//往后走
}
}
//说明要删除的元素不存在,删除失败
return false;
}
private:
vector<Node*> _tables;//哈希表,每个位置都是一条单链表
size_t _n = 0;//哈希表中的有效元素个数
};
}
void TestHashTable()
{
int a[] = { 4, 24, 14,7,37,27,57,67,34,14,54 };
LinkHash::HashTable<int, int> ht;
for (auto e : a) //只插入了10个元素,因为14冗余了不插入
{
ht.Insert(make_pair(e, e));
}
ht.Insert(make_pair(84, 84));//触发增容
}
开散列与闭散列比较
应用链地址法处理溢出,需要增设链接指针,似乎增加了存储开销
事实上: 由于开地址法必须保持大量的空闲空间以确保搜索效率,如二次探查法要求装载因子a <= 0.7,而表项所占空间又比指针大的多,所以使用链地址法反而比开地址法节省存储空间