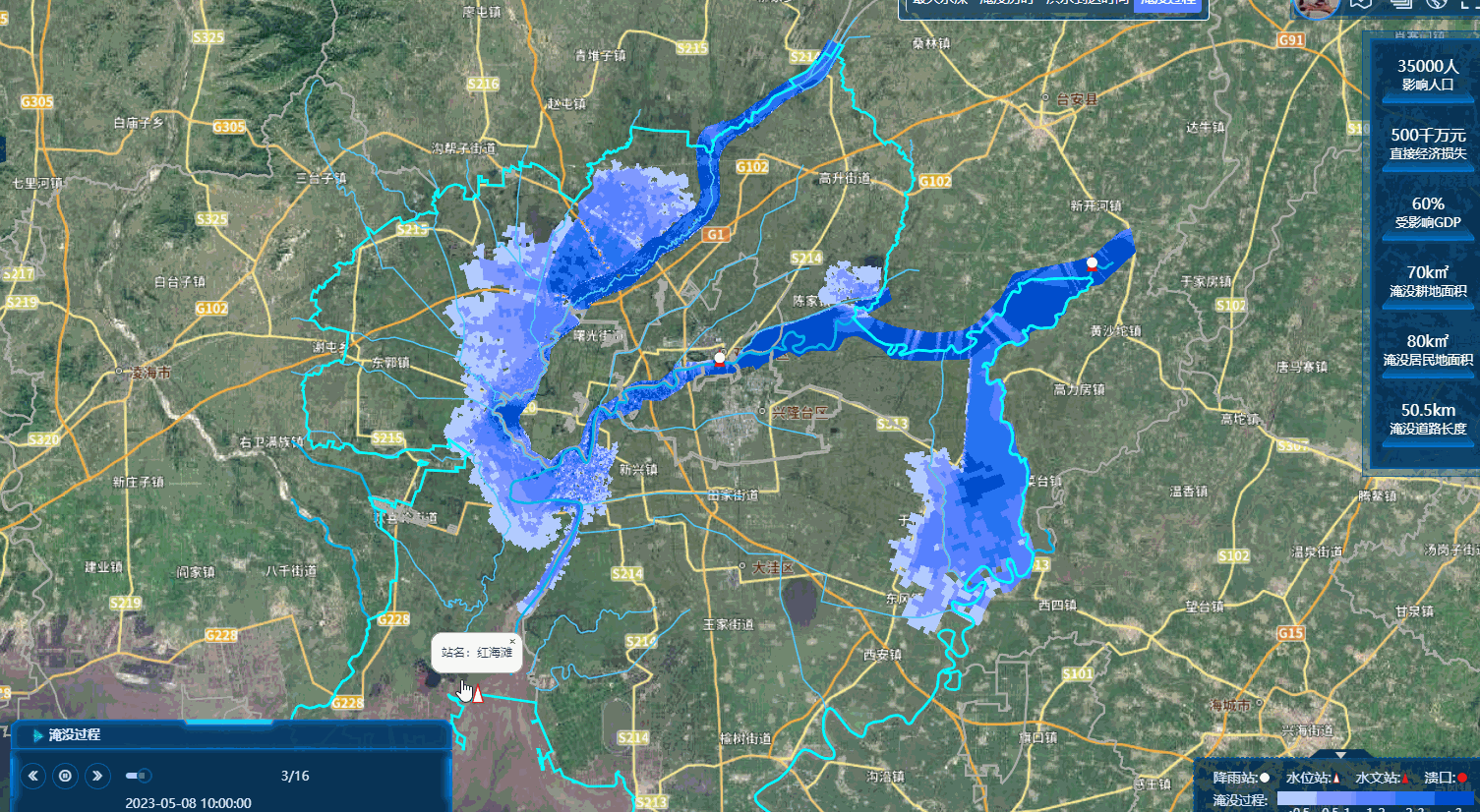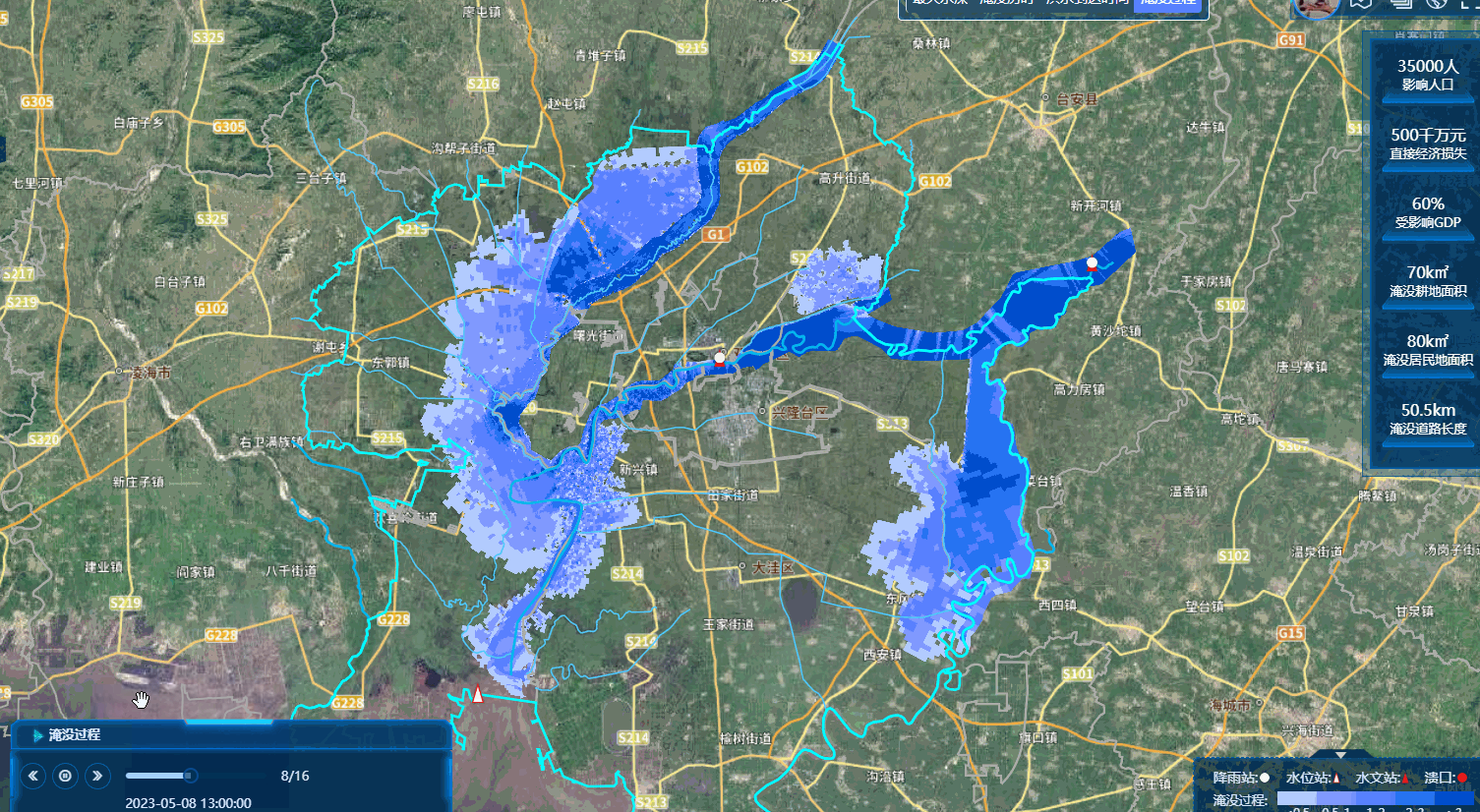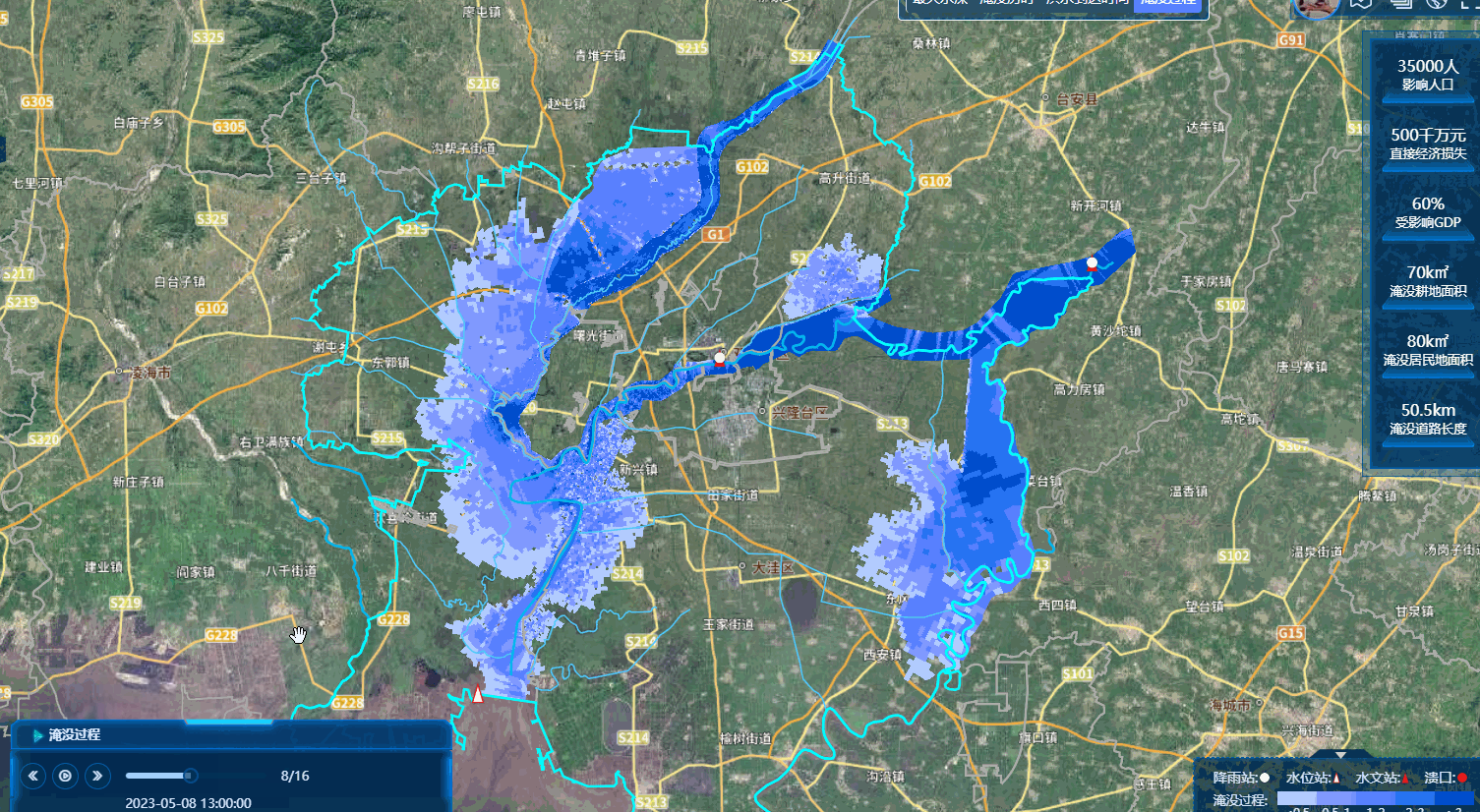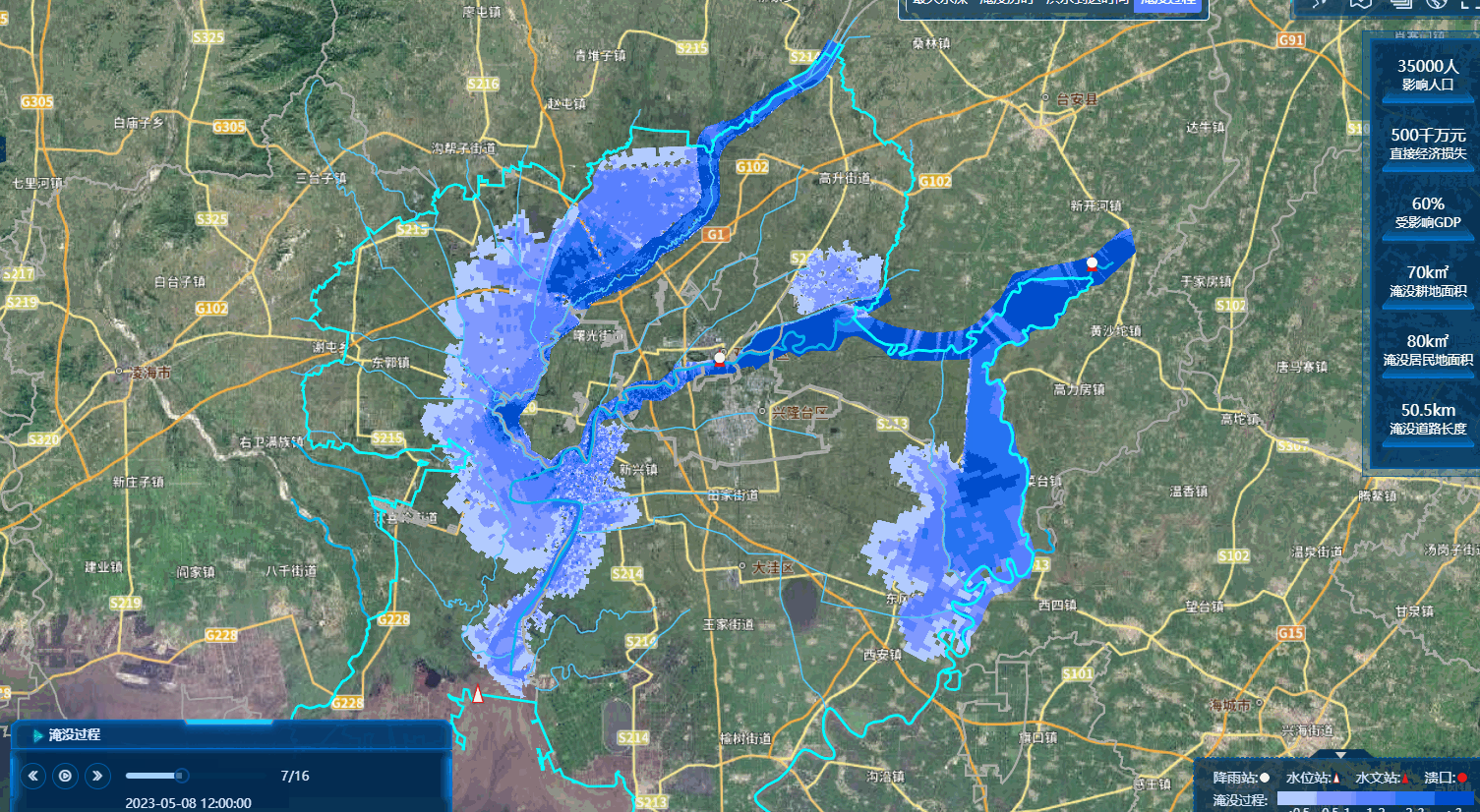
先看成果图
介绍
首先介绍一下我这个数据有15W的面数据,可以即时渲染,即时加载,然后播放。
技术路线
首先这种数量级的大数据,用别的二维API是绝对不可行的,arcgis和openlayer自动放弃,leaflet最多可以坚持到五千个点要素,一个面要素最少也得三个点,再往上就得加插件了,不过效果也很差,十五万个面要素,leaflet也是绝对支持不了的,所以我们只能选择mapbox。
mapbox经过博主本人实际测试,加载一个十五万面要素,如果是矢量切片的格式,大约一个图层有30-50M左右,如果是geojson的格式,一个图层大概有400-500M内存,而浏览器限制,比如谷歌浏览器,一个单页面最多也就4G内存,可以说,放十个geojson的格式图层基本就页面崩溃了,所以大概可以放150W个面要素,再往上就顶不住了,经过博主本人实际测试,也是大概150W面要素,页面就会崩溃。
这样看来,矢量切片仿佛是最优解,可以放置更多的图层,而且矢量切片是按需加载,只加载当前页面看到的范围,加载浏览的速度快,但是问题来了,对于这种实时计算出来的数据,我们不可能每个图层发布一个矢量切片的服务。
但是我们对数据进行观察,其实基础面要素是一样的,只不过不同时刻的属性不一样,然后会对数据进行一个过滤,没数据或者数据小于等于0的不显示,那我们可不可以只加载一个面图层,然后请求数据,给每个要素塞数据,筛选分层设色然后渲染出来?
确定这样的技术路线之后,那矢量切片就不可行了,我们无法给矢量切片里面塞数据,那只能是使用geojson格式的数据。
确定数据源格式之后,我们就开始着手开始工作,首先我们可以发布一个基础的面要素图层,这个图层我们尽量搞的小一点,多余的属性能删的就删,地理编码不能删除,那就只保留一个面要素的id,从源数据上首先就要减少文件大小,保证其最小,要不然太占内存了,将这个服务发布成矢量切片,然后调用他的geojson格式,这部分请看我这篇博客
https://blog.csdn.net/Sakura1998gis/article/details/130207840?spm=1001.2014.3001.5501
这样下去,我们请求回来的原始geojson数据经过处理,15w面要素大概有40M,当然这只是他占磁盘的大小,存到我们的系统内存里面,大概有300M,要注意,这里的内存,不可以超过4个G,否则页面会崩溃。
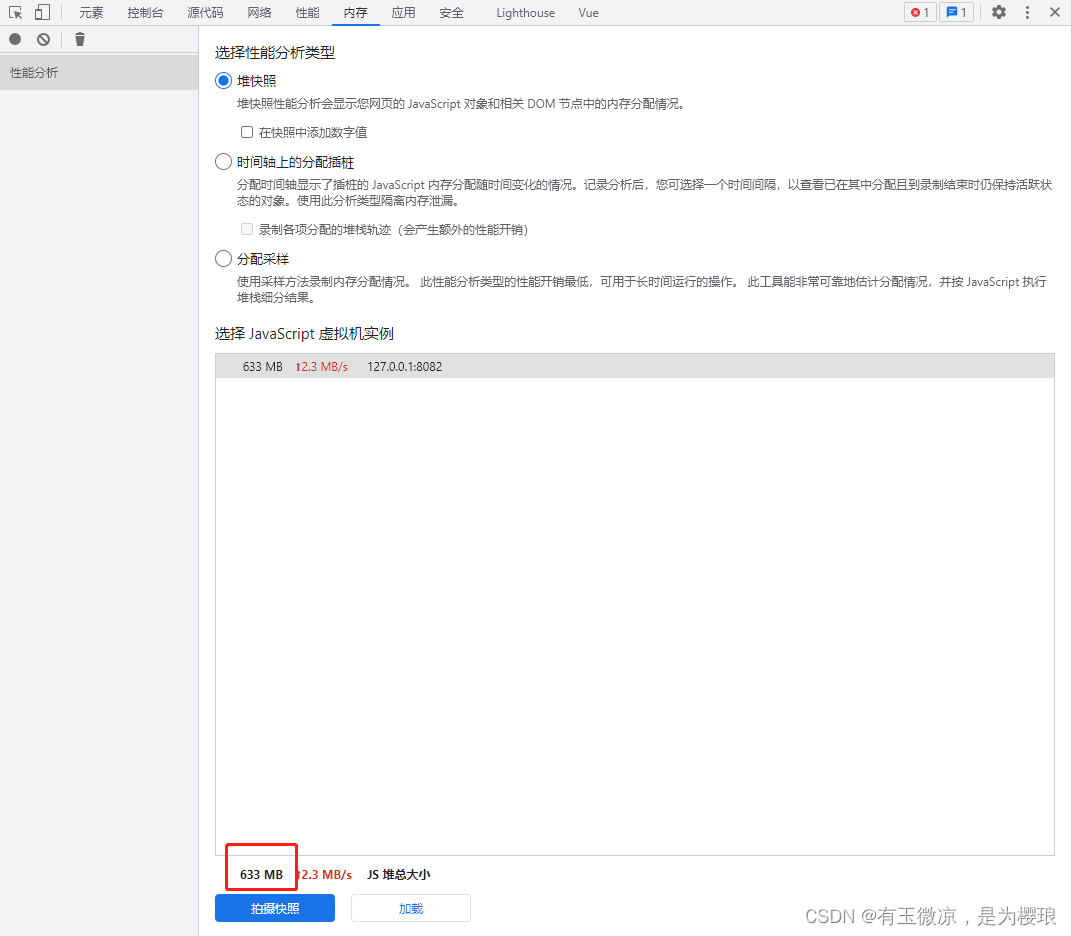
具体代码大概这样,fullScreenLoading是一个loading,用户进入页面,就会先loading,调这个接口请求回来这个数据,然后把geojson存到内存里面。
//加载十五万网格数据
initGridLayer(){
this.$axios({
url:geoserverUrl+geoserverGeojsonHeader+'test'+geoserverGeojsonEnd,
cache: false,
async: true,
}).then(res=>{
const geojson = res.data
// this.setFilterGeoJSON(geojson)
this.gridGeojson = geojson
// localStorage.setItem('test',JSON.stringify(geojson))
this.fullScreenLoading.close()
});
},
把数据请求回来之后,就要进行下一个优化,现在我们的面要素geojson文件,只有一个网格面的编号,那我们的数据该怎么拿来呢?这肯定需要一个接口,来从后台获取,但是数据的格式,也需要尽量精简,毕竟有15W条,最优解应该是返回txt文件,这样比json会更小一点。
我们的txt文件也不需要多少东西,就两列,一列编号,一列数据,比如我们这个要展示水深过程,那么第一列就是网格面的编号,第二列就是该网格点的水的深度,数据尽量精简。然后后台处理的时候。
如果我们要展示这种播放的效果的话,那么一个时刻就是一个图层,就需要一份txt文件,有多少图层,就需要多少份txt文件。
然后下一步就是要读取txt文件,通过对应编号,来把数据放到geojson里面,这里我们会新建一个geojson
let resultGeojson = {
"type": "FeatureCollection",
"features": []
}
读取txt文件
//通过服务器上的txt地址,来获取文件
let resMesh = await fetch(txtUrl).then(res => res.text())
// 处理文件成为数据
let pointRows = resMesh.split("\n");
// console.log(resMesh,pointRows)
for (let i = 0; i < pointRows.length-1; i++) {
//这是数据的每一行
let point = pointRows[i];
//每一行的数组,P[0]即是每一行的第一个数据,也就是我们的编号,这个要看你们的txt格式安排
let p = point.split(" ");
//通过基础的geojson文件的编号,来找到对应的编号,然后把数据塞进去
this.gridGeojson.features[Number(p[0])-1].properties[numberPosition.field] = p[numberPosition.numberPosition]
//再把整个的改点的geojson数据,塞到我们新创建的geojson里面
resultGeojson.features.push(this.gridGeojson.features[Number(p[0])-1])
}
这里要说一句的是后台处理txt文件的时候,可以提前把没有数据的点给清楚掉,这样我们在前端处理数据的时候,可以少循环一些次数,减少处理数据的时间,毕竟我们要即时渲染。
然后在播放之前,我们建一个source,source是存数据的数据源,因为我们播放的那么多图层,其实网格都一样,都是那十五万个,就可以使用同一个数据源,layer也使用同一个。
if(this.map.getSource('playLayer')){}else{
this.map.addSource('playLayer', { //此处的vector是我们的source的id
'type': 'geojson',
'data':[]
})
this.map.addLayer({
id: 'playLayer',
name:'最大水深',
source: 'playLayer',
type:'fill',
popup:false,
filter:['!=',["to-number",["get","MaxWDepth"]],0],
paint: {
'fill-color':["step",["to-number",["get","MaxWDepth"]],'rgb(179,204,255)',0.5,'rgb(128,153,255)',1,'rgb(89,128,255)',2,'rgb(38,115,242)',3,'rgb(0,77,204)'],
},
layout: {
visibility: 'visible'
},
},)
}
然后在播放切换图层的时候,我们先关闭掉上次的数据,注意这里我们不remove掉source,我们共用一个source,
//关闭播放图层
if(this.map.getLayer('playLayer')){
this.map.getSource('playLayer').setData({})
}
就给这个数据源塞入新的数据,挤掉上次的数据,这样虽然一个图层是500M,但是我们是来回渲染这一个图层一个source,就不会超过浏览器单页面4G的限制了。
this.map.getSource('playLayer').setData(resultGeojson)
总结
总结一下就是:
api要使用mapbox,
网格数据源要使用geojson,并且尽量精简,删除无用的属性。
渲染的属性数据要从接口上获取txt文件来读取。
渲染的时候,共用同一个source,同一个layer。不反复移除layer,而是通过给geojson来setdata来更新数据,这样图层切换的时候不会突兀显示,而是有一个丝滑的动态效果