基于 Kubernetes 实现云资源分析与成本优化平台
- 一、基本介绍
- 1.主要功能
- 2.整体架构
- 二、基于 Kubernetes 实现云资源分析与成本优化平台
- 1.准备工作
- 2.安装 Prometheus/Grafana 软件包
- 3.安装 Crane 软件包
- 4. 使用智能弹性 EffectiveHPA
- 4.配置集群
- 三、功能验证
- 1.成本展示
- 2.资源推荐
- 3.副本数推荐
- 四、总结
前言:
为推进云原生用户在确保业务稳定性的基础上做到真正的极致降本,腾讯云推出了国内第一个基于云原生技术的成本优化开源项目 Crane(
Cloud Resource Analytics and Economics)。Crane 遵循 FinOps 标准,旨在为云原生用户提供云成本优化一站式解决方案。
一、基本介绍
Crane 是一个基于 FinOps 的云资源分析与成本优化平台。它的愿景是在保护客户应用运行质量的前提下实现极致的降本。
- 官网地址
- GitHub 地址
1.主要功能
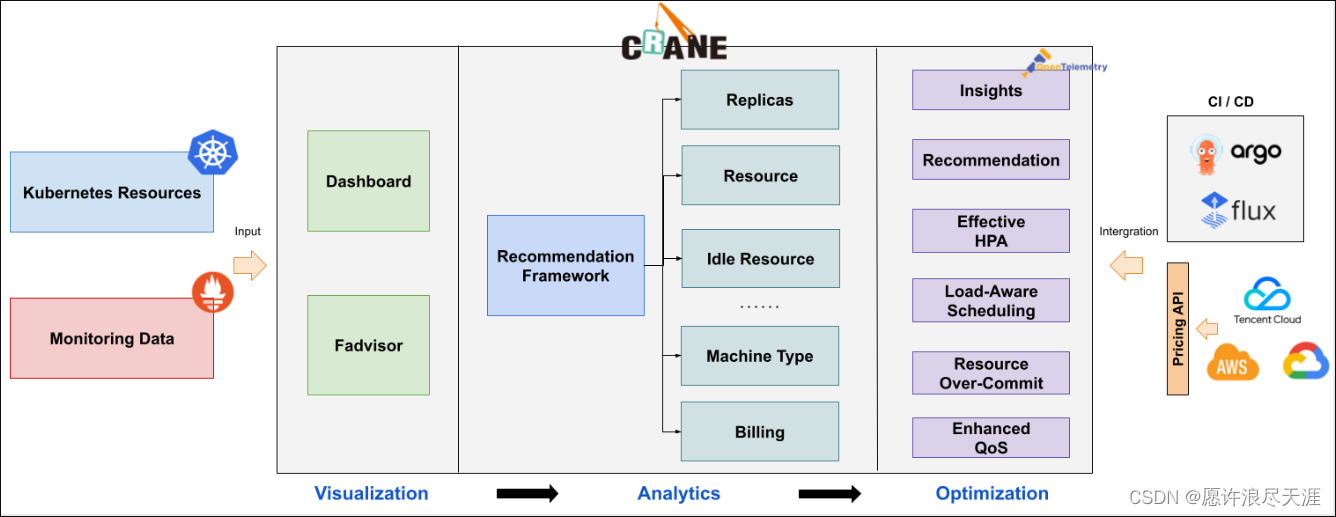
1)成本可视化和优化评估
- 提供一组 Exporter 计算集群云资源的计费和账单数据并存储到你的监控系统,比如 Prometheus。
- 多维度的成本洞察,优化评估。通过
Cloud Provider支持多云计费。
2)推荐框架
- 提供了一个可扩展的推荐框架以支持多种云资源的分析,内置了多种推荐器:资源推荐,副本推荐,HPA 推荐,闲置资源推荐。
3)基于预测的水平弹性器
EffectiveHorizontalPodAutoscaler支持预测驱动的弹性;- 基于社区的 HPA 做底层的弹性控制,支持更丰富的弹性触发策略(预测,观测,周期),让弹性更加高效,并保障了服务的质量。
4)负载感知的调度器
- 动态调度器根据实际的节点利用率构建了一个简单但高效的模型,并过滤掉那些负载高的节点来平衡集群。
5)拓扑感知的调度器
Crane Scheduler与Crane Agent配合工作,支持更为精细化的资源拓扑感知调度和多种绑核策略,使得资源得到更合理高效的利用。
6)基于 QOS 的混部
- QOS 相关能力保证了运行在 Kubernetes 上的 Pod 的稳定性。
- 具有多维指标条件下的干扰检测和主动回避能力,支持精确操作和自定义指标接入;
- 具有预测算法增强的弹性资源超卖能力,复用和限制集群内的空闲资源;
- 具备增强的旁路
cpuset管理能力,在绑核的同时提升资源利用效率。
2.整体架构
Crane 的整体架构如下:
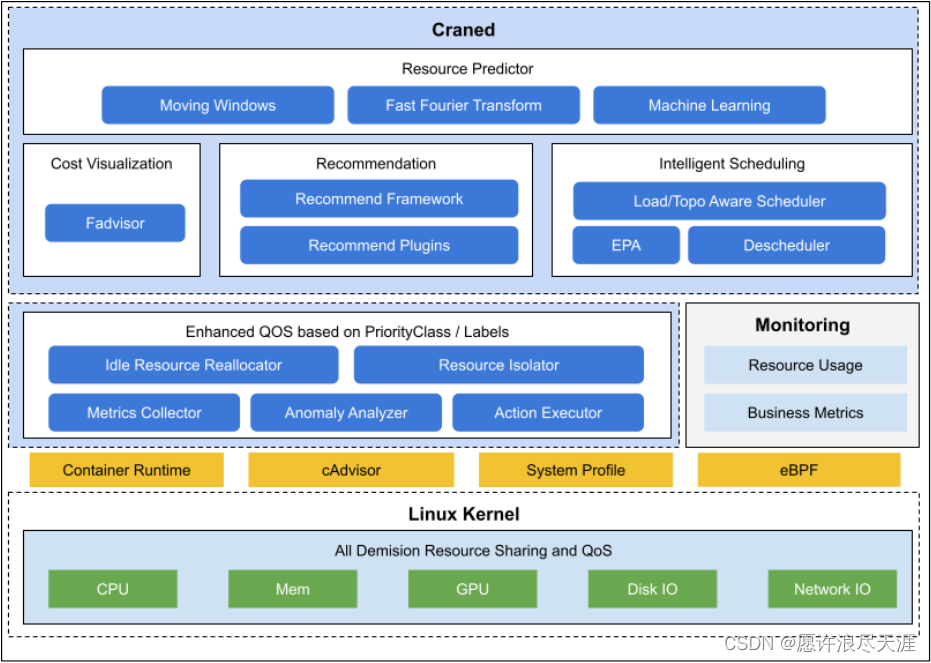
Craned 是 Crane 的最核心组件,它管理了 CRDs 的生命周期以及 API。 Craned 通过 Deployment 方式部署且由两个容器组成:
- Craned:运行了 Operators 用来管理 CRDs,向 Dashboard 提供了 WebAPI,Predictors 提供了 TimeSeries API;
- Dashboard:基于 TDesign’s Starter 脚手架研发的前端项目,提供了易于上手的产品功能。
Fadvisor 提供一组 Exporter 计算集群云资源的计费和账单数据并存储到你的监控系统, 比如 Prometheus。
- Fadvisor 通过
Cloud Provider支持了多云计费的 API。
Metric Adapter 实现了一个 Custom Metric Apiserver。
- Metric Adapter 读取 CRDs 信息并提供基于
Custom/External Metric API的 HPA Metric 的数据。
- Crane Agent 通过
DaemonSet部署在集群的节点上。
二、基于 Kubernetes 实现云资源分析与成本优化平台
1.准备工作
- Kubernetes 1.16+:二进制安装传送门
- Helm 3.7+
1)安装 Helm
[root@k8s-master01 ~]# wget https://get.helm.sh/helm-v3.7.2-linux-amd64.tar.gz
[root@k8s-master01 ~]# tar zxf helm-v3.7.2-linux-amd64.tar.gz
[root@k8s-master01 ~]# mv linux-amd64/helm /usr/local/bin
[root@k8s-master01 ~]# helm version
version.BuildInfo{Version:"v3.7.2", GitCommit:"663a896f4a815053445eec4153677ddc24a0a361", GitTreeState:"clean", GoVersion:"go1.16.10"}
2.安装 Prometheus/Grafana 软件包
1)安装 Prometheus
[root@k8s-master01 ~]# helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
[root@k8s-master01 ~]# helm install prometheus -n crane-system --version 19.6.1 \
--set pushgateway.enabled=false \
--set alertmanager.enabled=false \
--set server.persistentVolume.enabled=false \
-f https://raw.githubusercontent.com/gocrane/helm-charts/main/integration/prometheus/override_values.yaml \
--create-namespace prometheus-community/prometheus
2)安装 Grafana
[root@k8s-master01 ~]# helm repo add grafana https://grafana.github.io/helm-charts
[root@k8s-master01 ~]# helm install grafana --version 6.11.0 \
-f https://raw.githubusercontent.com/gocrane/helm-charts/main/integration/grafana/override_values.yaml \
-n crane-system \
--create-namespace grafana/grafana
3.安装 Crane 软件包
1)安装 Crane 和 Fadvisor
[root@k8s-master01 ~]# helm repo add crane https://gocrane.github.io/helm-charts
[root@k8s-master01 ~]# helm install crane -n crane-system --create-namespace crane/crane
[root@k8s-master01 ~]# helm install fadvisor -n crane-system --create-namespace crane/fadvisor
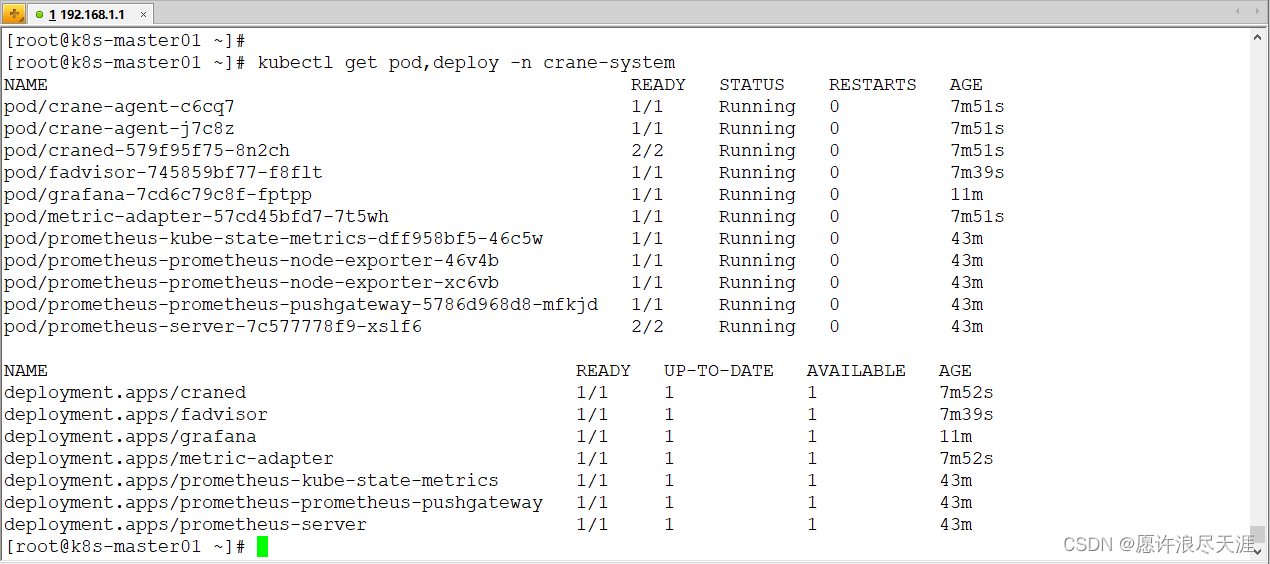
2)验证安装是否成功
[root@k8s-master01 ~]# kubectl get pod,deploy -n crane-system
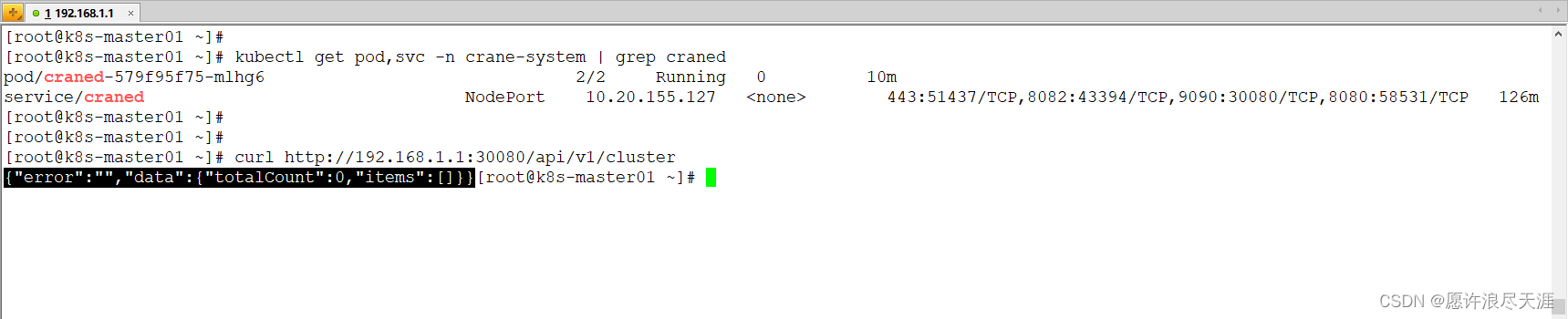
3)修改 Craned 服务的 ConfigMap 配置,调整反向代理的地址
[root@k8s-master01 ~]# kubectl get service craned -n crane-system -o yaml > 1.yaml
[root@k8s-master01 ~]# sed -i 's/type: ClusterIP/type: NodePort/g' 1.yaml
[root@k8s-master01 ~]# sed -i '/targetPort: 9090/a\ nodePort: 30080' 1.yaml
[root@k8s-master01 ~]# kubectl apply -f 1.yaml
[root@k8s-master01 ~]# kubectl edit cm nginx-conf -n crane-system
:%s/craned.crane-system:8082/127.0.0.1:8082/g
[root@k8s-master01 ~]# kubectl get pod -n crane-system | awk '/^craned/{print $1}' | xargs kubectl delete pod -n crane-system
- 因为 Dashboard 和 Craned 服务都在同一个 Pod 里,而 Dashboard 容器是通过 Service 加端口的方式代理到 Craned 服务上的;
- 但是 Pod 并不能直接通过 Service 加 端口的方式访问到本身,所以我们这里通过
127.0.0.1(Lo)的方式进行代理。
4. 使用智能弹性 EffectiveHPA
Kubernetes HPA 支持了丰富的弹性扩展能力,Kubernetes 平台开发者部署服务实现自定义 Metric 的服务,Kubernetes 用户配置多项内置的资源指标或者自定义 Metric 指标实现自定义水平弹性。
EffectiveHorizontalPodAutoscaler(简称 EHPA)是 Crane 提供的弹性伸缩产品,它基于社区 HPA 做底层的弹性控制,支持更丰富的弹性触发策略(预测,观测,周期),让弹性更加高效,并保障了服务的质量。
- 提前扩容,保证服务质量: 通过算法预测未来的流量洪峰提前扩容,避免扩容不及时导致的雪崩和服务稳定性故障。
- 减少无效缩容: 通过预测未来可减少不必要的缩容,稳定工作负载的资源使用率,消除突刺误判。
- 支持 Cron 配置: 支持 Cron-based 弹性配置,应对大促等异常流量洪峰。
- 兼容社区: 使用社区 HPA 作为弹性控制的执行层,能力完全兼容社区。
1)安装 Metrics Server
[root@k8s-master01 ~]# wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.3/components.yaml
[root@k8s-master01 ~]# sed -i '/- args:/a\ - --metric-resolution=15s' components.yaml
[root@k8s-master01 ~]# sed -i 's@image:.*@image: docker.io/gocrane/metrics-server:v0.6.3@g' components.yaml
[root@k8s-master01 ~]# kubectl apply -f components.yaml
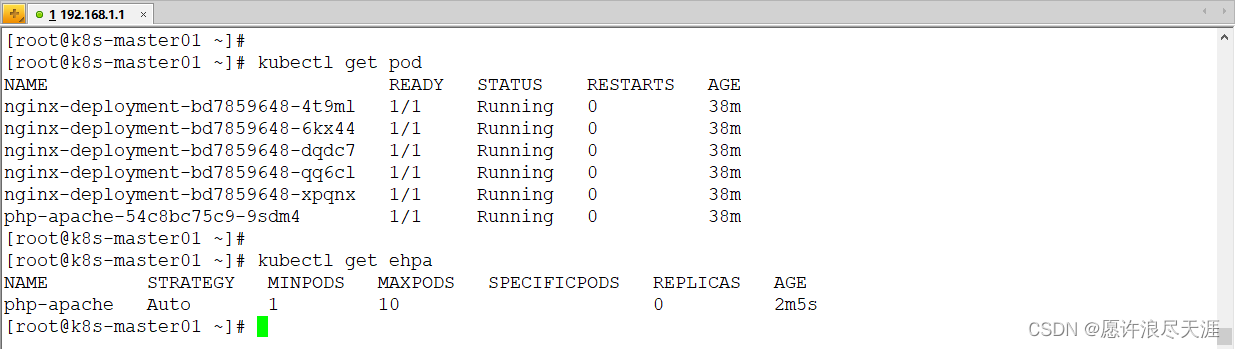
2)创建测试应用
[root@k8s-master01 ~]# kubectl apply -f https://raw.githubusercontent.com/gocrane/crane/main/examples/autoscaling/php-apache.yaml
[root@k8s-master01 ~]# kubectl apply -f https://raw.githubusercontent.com/gocrane/crane/main/examples/analytics/nginx-deployment.yaml
3)创建 EffectiveHPA
[root@k8s-master01 ~]# kubectl apply -f https://raw.githubusercontent.com/gocrane/crane/main/examples/autoscaling/effective-hpa.yaml
4)增加负载,查看应用是否能够正常扩容
[root@k8s-master01 ~]# kubectl run -i --tty load-generator --rm --image=busybox:1.28.4 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
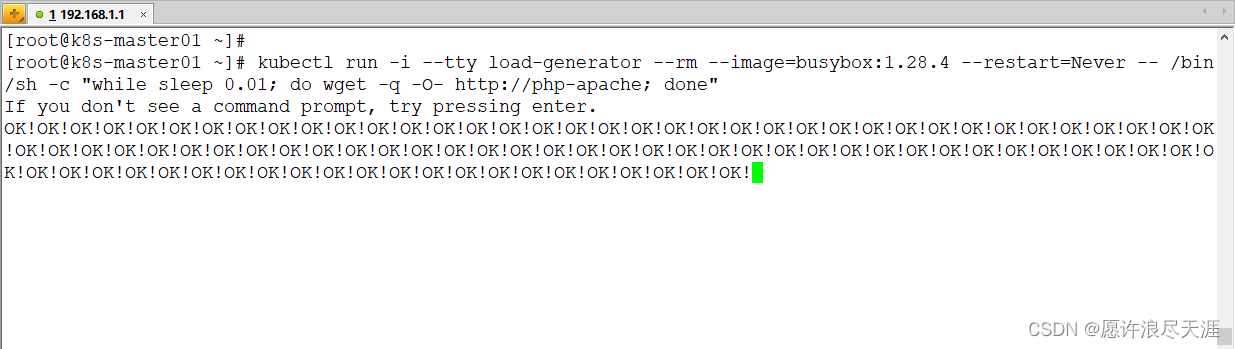
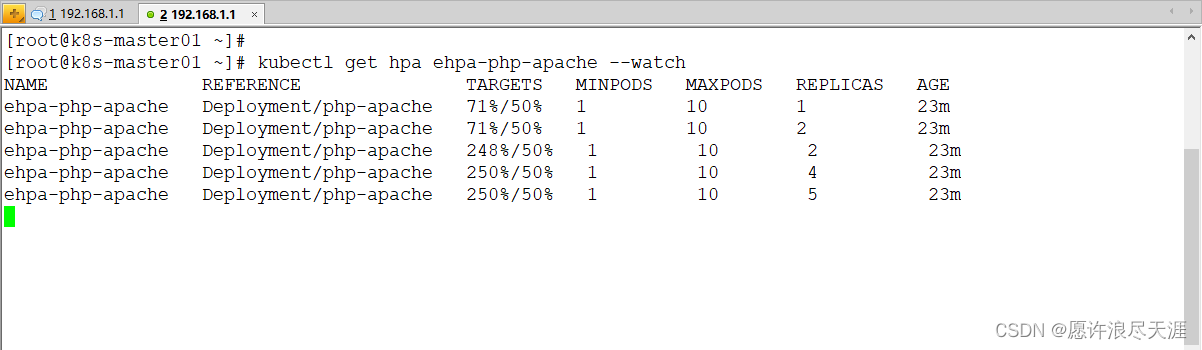
- 可以看到随着请求增多,CPU 利用率会不断提升,通过 EffectiveHPA 会自动扩容实例。
4.配置集群
访问:http://192.168.1.1:30080
三、功能验证
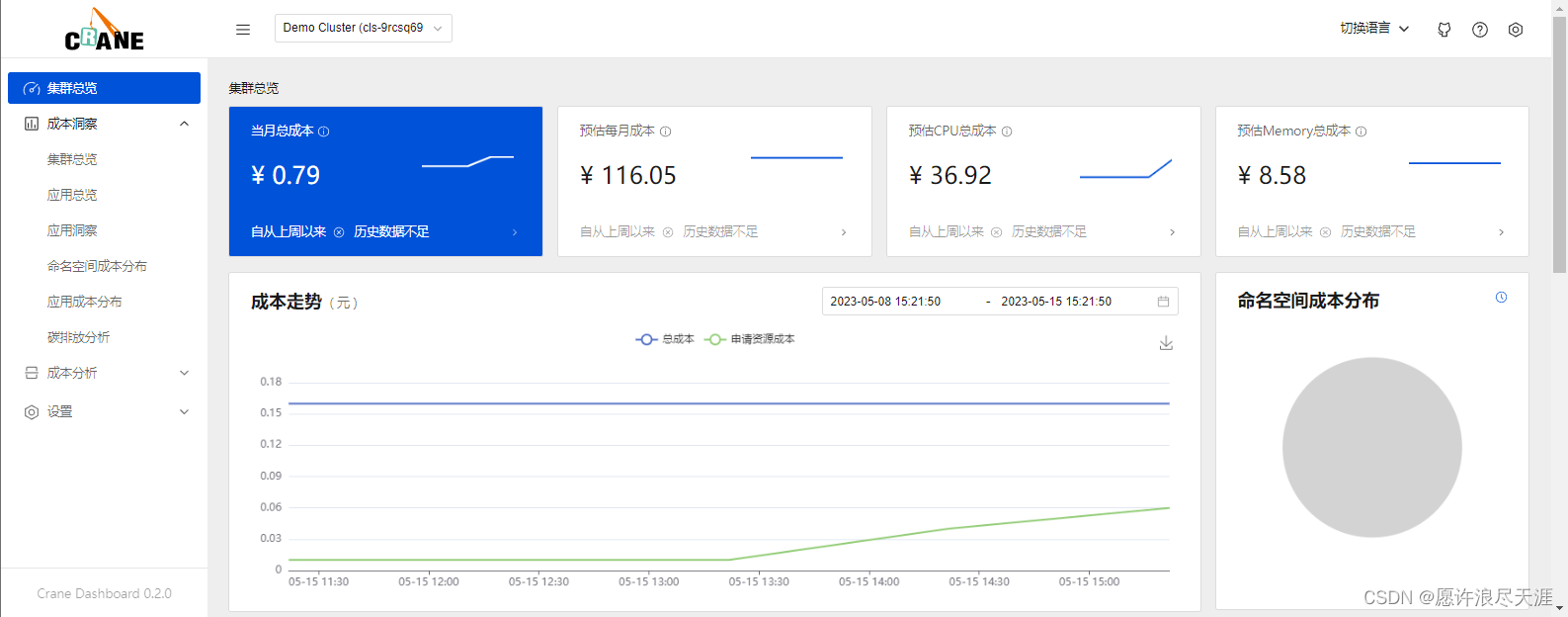
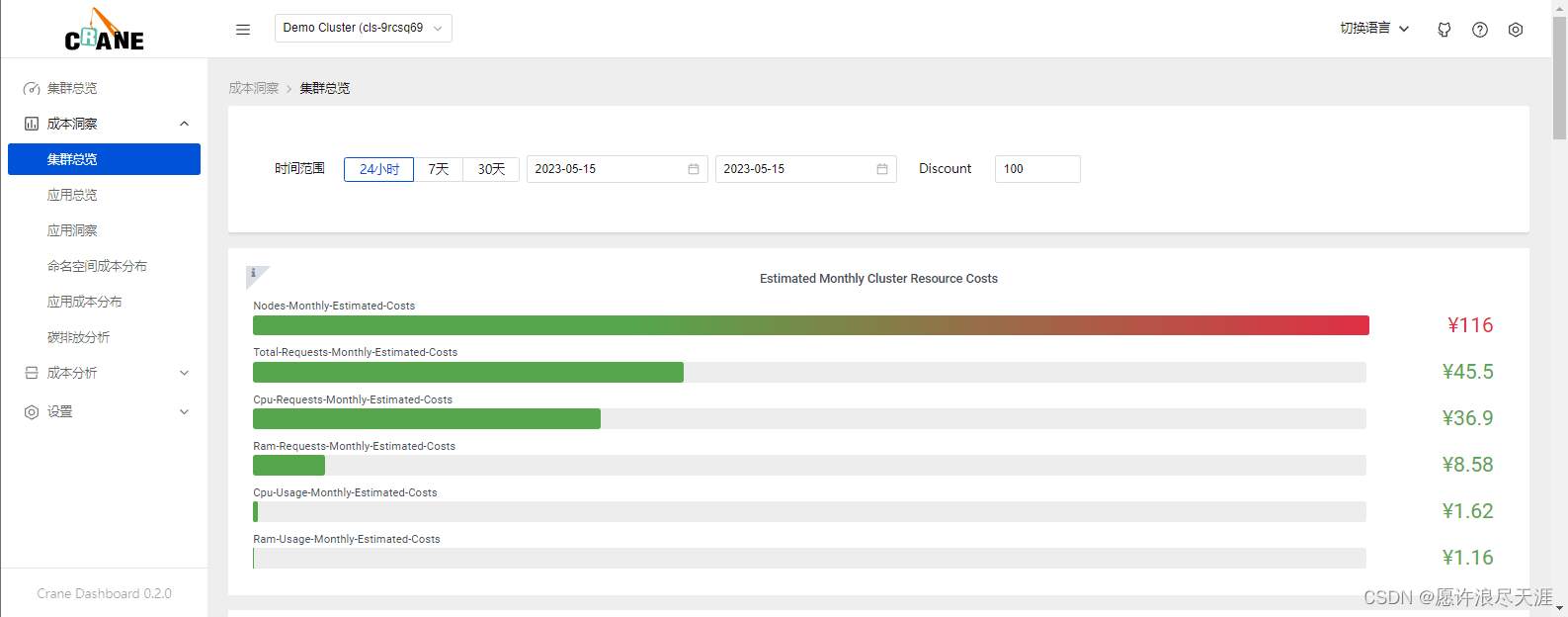
1.成本展示
Crane Dashboard 提供了各式各样的图表展示了集群的成本和资源用量。
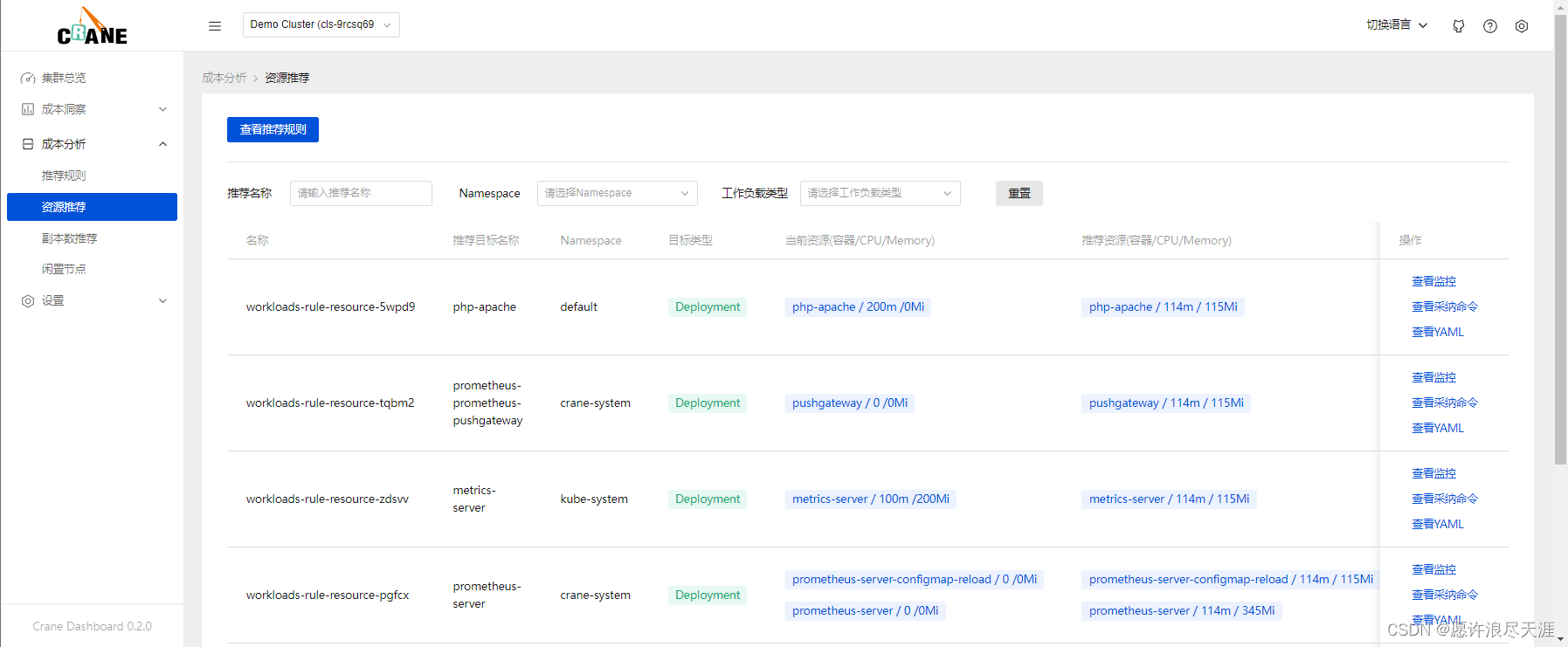
2.资源推荐
Kubernetes 用户在创建应用资源时常常是基于经验值来设置 request 和 limit,通过资源推荐的算法分析应用的真实用量推荐更合适的资源配置,你可以参考并采纳它提升集群的资源利用率。该推荐算法模型采用了 VPA 的滑动窗口(Moving Window)算法进行推荐:
- 通过监控数据,获取 Workload 过去一周(可配置)的 CPU 和内存的历史用量。
- 算法考虑数据的时效性,较新的数据采样点会拥有更高的权重。
- CPU 推荐值基于用户设置的目标百分位值计算,内存推荐值基于历史数据的最大值。
1)使用资源推荐

3.副本数推荐
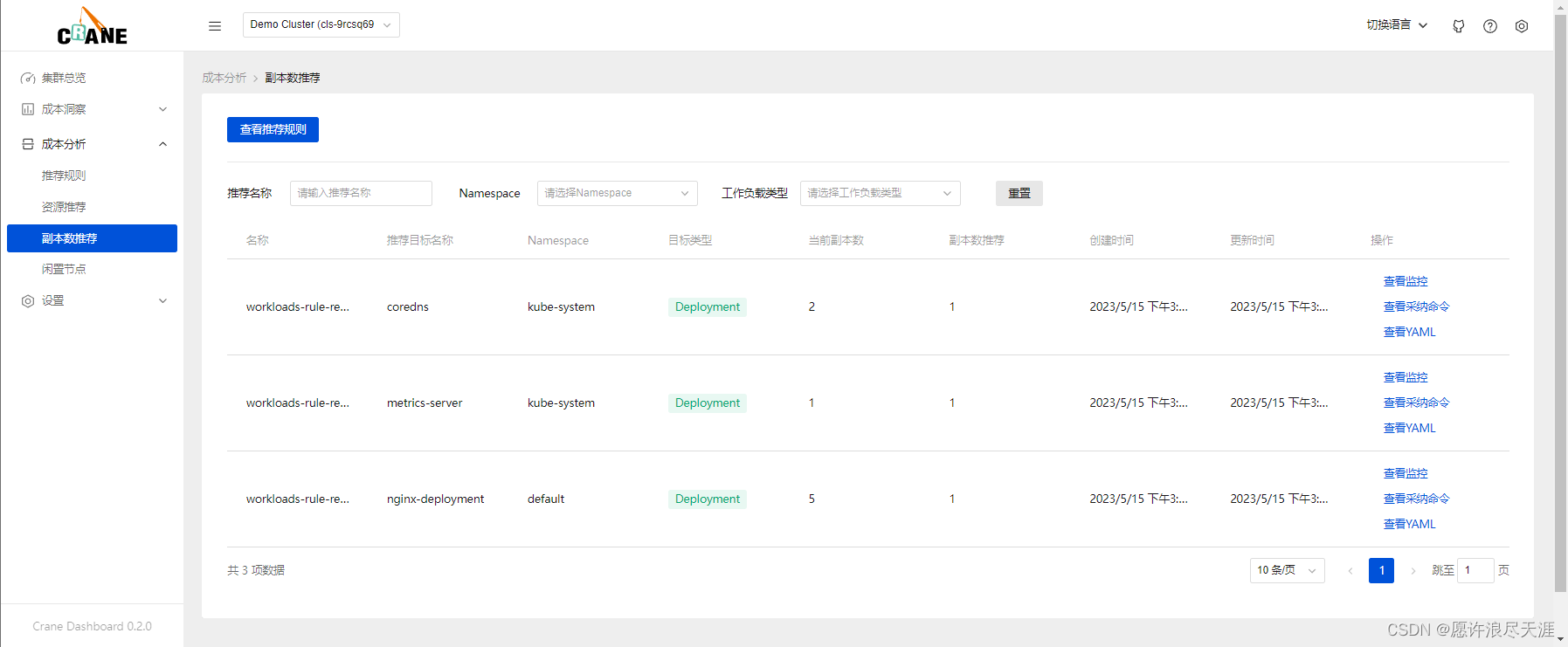
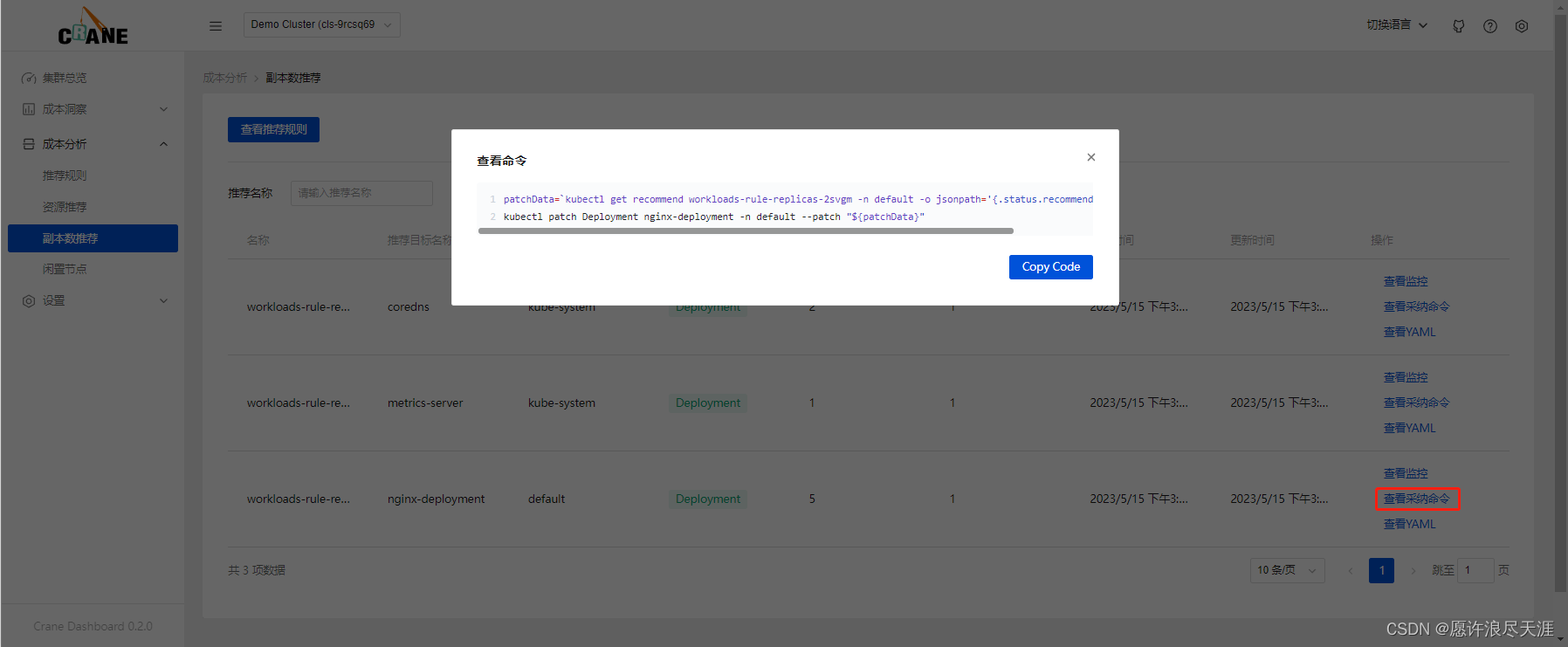
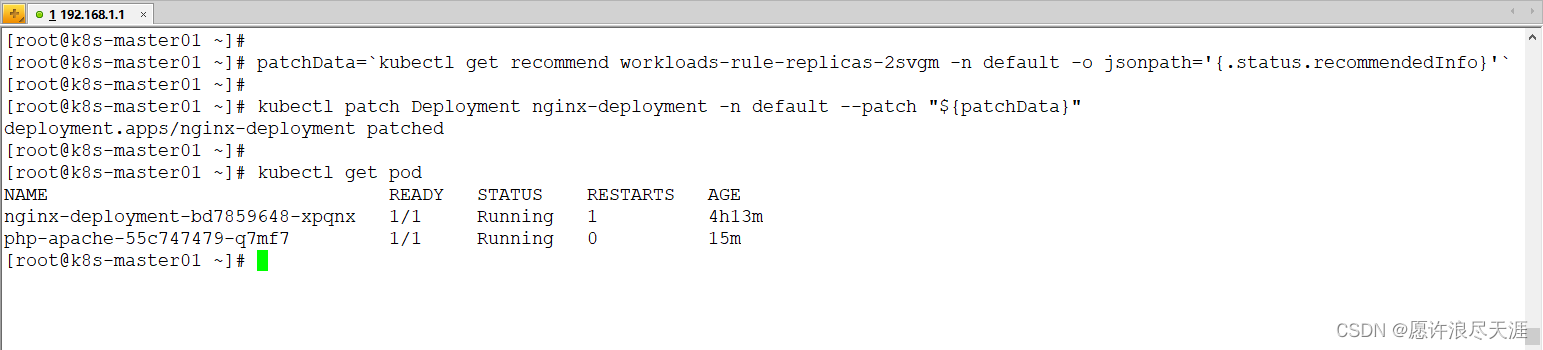
Kubernetes 用户在创建应用资源时常常是基于经验值来设置副本数。通过副本数推荐的算法分析应用的真实用量推荐更合适的副本配置,同样可以参考并采纳它提升集群的资源利用率。
其实现的基本算法是基于工作负载历史 CPU 负载,找到过去七天内每小时负载最低的 CPU 用量,计算按 50%(可配置)利用率和工作负载 CPU Request 应配置的副本数。
四、总结
整体操作体验下来,安装相对比较简单,通过使用 Helm 工具实现便捷安装。安装完成后,便可以通过提供的 Dashboard 面板来进行访问。界面简单明了,易上手,同时在功能层面上实现了实时监控成本、应用资源使用量、资源推荐、智能弹性等功能。
- 实时监控成本:Crane 提供每小时、每天、每周和每月的费用概览,并且可以按集群、命名空间和工作负载分解成本。
- 资源监控:通过调用 Prometheus 和 Grafana 实现资源监控以及可视化 UI。
- 资源推荐:使用 VPA 算法模型,先分析出应用的真实用量,再通过计算得出应用的最佳资源配置。
- 智能弹性:基于社区 HPA 做底层的弹性控制,支持更加丰富的弹性触发策略,让弹性更加高效,并保证服务的质量。
因此,我们可以通过 Crane 服务提供的成本计算、资源使用率,以及上述功能,来观察是否需要对云服务器进行资源扩容或减配。避免出现资源不足或资源浪费的情况,达到真正意义上的降本增效。








![[山海关crypto 训练营 day13]](https://img-blog.csdnimg.cn/71cb2d1e60284c3e991f8b78300882e4.png)