论文题目:《BLOOM: A 176B-Parameter Open-Access Multilingual Language Model》
论文链接:https://arxiv.org/abs/2211.05100
github链接:https://github.com/huggingface/transformers-bloom-inference/tree/main
huggingface链接:https://huggingface.co/bigscience/bloom
1 模型简介
预训练语言模型已经成为了现代自然语言处理pipeline中的基石,因为其在少量的标注数据上产生更好的结果。随着ELMo、ULMFiT、GPT和BERT的开发,使用预训练模型在下游任务上微调的范式被广泛使用。随后发现预训练语言模型在没有任何额外训练的情况下任务能执行有用的任务,进一步证明了其实用性。此外,根据经验观察,语言模型的性能随着模型的增大而增加(有时是可预测的,有时是突然的),这也导致了模型规模越来越多的趋势。抛开环境的问题,训练大语言模型(LLM)的代价仅有资源丰富的组织可以负担的起。此外,直至最终,大多数LLM都没有公开发布。因此,大多数的研究社区都被排除在LLM的开发之外。这在不公开发布导致的具体后果:例如,大多数LLM主要是在英文文本上训练的。
为了解决这些问题,我们提出了BigScience Large Open-science Open-access Multilingual Language Model(BLOOM)。BLOOM是在46种自然语言和13种编程语言上训练的1760亿参数语言模型,其是由数百名研究人员合作开发和发布的。训练BLOOM的计算力是由来自于法国公共拨款的GENCI和IDRIS,利用了IDRIS的Jean Zay超级计算机。为了构建BLOOM,对于每个组件进行了详细的设计,包括训练数据、模型架构和训练目标、以及分布式学习的工程策略。我们也执行了模型容量的分析。我们的总体目标不仅是公开发布一个能够和近期开发的系统相媲美的大规模多语言的语言模型,而且还记录其开发中的协调过程。
2 BLOOM训练与数据集
2.1. BigScience
- BLOOM 的开发由 BigScience 完成,BigScience 是一个开放的研究合作组织,其目标是公开发布 LLM。
- 超过 1200 人注册成为 BigScience 的参与者
2.2 训练语料
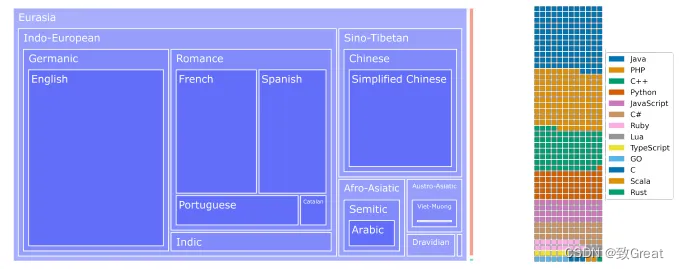
- 上述 ROOTS 语料库的动机是建立一个世界上尽可能多的人可以访问的语言模型,并且规模与之前的努力相当。
- 左图:所有 46 种自然语言的语系树状图,其中表面积与字节数成正比。 Indo-European and Sino-Tibetan 以 1321.89 GB 的总容量占据巨大部分。 细橙色表面代表 18GB 的印度尼西亚语数据,绿色矩形 0.4GB 构成尼日尔-刚果语系子集。
- 右图:13 种编程语言按文件数量分布的华夫饼图,其中一个方块代表大约 30,000 个文件。
2.3 xP3: Prompted Dataset

- 多任务提示微调(也称为指令调优)涉及在由通过自然语言提示指定的大量不同任务组成的训练混合体上微调预训练语言模型。
- 原始 P3 数据集被扩展为包括英语以外的语言的新数据集和新任务,例如翻译。 这导致了 xP3,它是 83 个数据集的提示集合,涵盖 46 种语言和 16 个任务。
在预训练 BLOOM 之后,应用大规模多任务微调方法使 BLOOM 具备多语言零样本任务泛化能力,其结果模型为 BLOOMZ。
3 BLOOM 模型结构与训练
3.1 模型结构
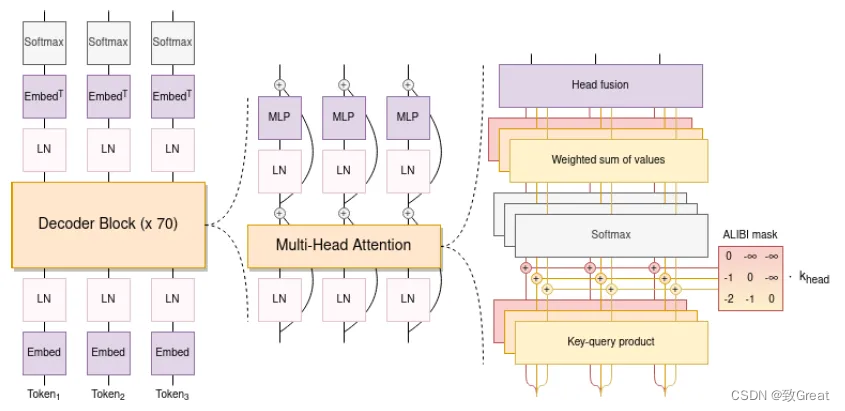
-
使用因果解码器的 Transformer 模型有两个架构偏差。
-
使用 ALiBi 位置嵌入,它根据键和查询的距离直接衰减注意力分数。 与原始的 Transformer 和 Rotary 嵌入相比,它可以带来更流畅的训练和更好的下游性能。ALiBi不会在词嵌入中添加位置嵌入;相反,它会使用与其距离成比例的惩罚来偏向查询键的注意力评分。
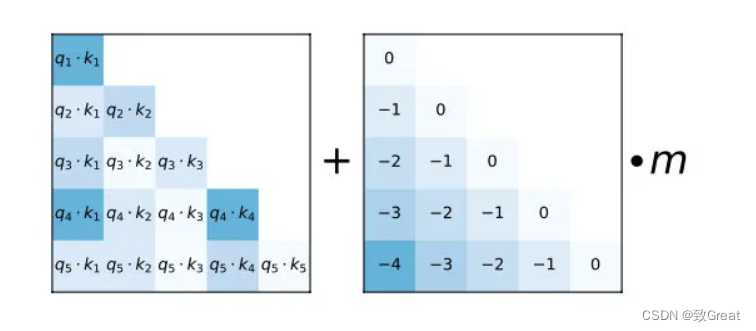
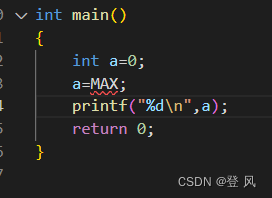
如图所示,只是给 attention score 加上一个预设好的偏置矩阵,相当于 q 和 k 相对位置差 1 就加上一个 -1 的偏置。其实相当于假设两个 token 距离越远那么相互贡献也就越低。
当然也不是就直接用这个矩阵一加就行,还是有借鉴 T5 Bias 里,加入了多组 bias. 主要的偏置矩阵都是相同的,不同的只是旁边的 m 系数,可以给 m 当成是一个斜率(Slope)。
论文中 m 系数也是预设好的,作者会根据 head 数来设置一组 m 系数,具体按照头的数量 n 从 到 的指数差值来进行设置,比如说 8 个头,那么就设置为 M 也可以训练获得,但作者们发现,训练获得的并没有带了的更好的性质。论文:https://arxiv.org/pdf/2108.12409.pdf -
Embedding Layer Norm 在第一个嵌入层之后立即使用,以避免训练不稳定。
-
使用了 25 万个标记的词汇表。 使用字节级 BPE。 这样,标记化永远不会产生未知标记
3.2 工程实现
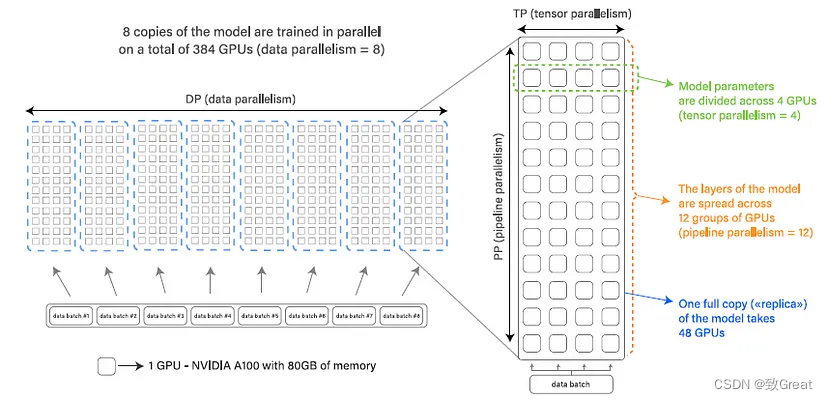
- BLOOM 使用 Megatron-DeepSpeed进行训练,它由两部分组成:Megatron-LM提供Transformer实现、张量并行性和数据加载原语,而DeepSpeed提供ZeRO优化器、模型流水线和通用分布式训练组件。
- 数据并行性 (DP) 多次复制模型,每个副本放置在不同的设备上并提供数据的一部分。处理是并行完成的,所有模型副本在每个训练步骤结束时同步。
- 张量并行性 (TP) 跨多个设备划分模型的各个层。这样,不是将整个激活或梯度张量驻留在单个 GPU 上,而是将该张量的碎片放置在单独的 GPU 上。
- 流水线并行性 (PP) 将模型的层拆分到多个 GPU 上,因此只有一小部分模型层被放置在每个 GPU 上。
使用bfloat16 混合精度。使用融合的 CUDA 内核。
3.3 模型变体
- 六个参数量的模型变体

- BLOOM 的能源消耗略高于 OPT,但BLOOM 的排放量大约减少 2/3(25 吨对 70 吨)。这要归功于用于训练 BLOOM
的能源网的低碳强度,其排放量为 57 gCO2eq/kWh。
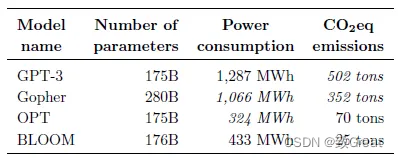
- BLOOM 和 OPT 产生的碳排放量都比GPT-3少得多,这可以归因于几个因素,包括更高效的硬件以及更少的碳密集型能源。
3.4 提示学习

提示是在 BLOOM 发布之前开发的,并且没有经过任何先验的改进,举例说明了机器翻译 (MT) 的一些提示示例。
4 实验结果
4.1 零样本能力
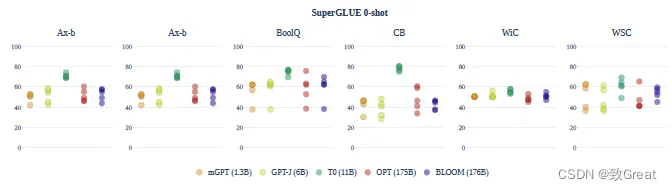
跨提示的平均表现总是徘徊在机会附近。例外的是T0 模型,它显示出强大的性能。但是,该模型在多任务设置中进行了微调,无法直接进行比较。
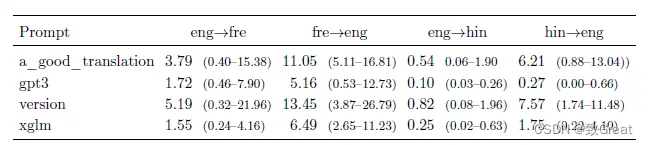
在零样本设置中,MT结果通常很差。观察到的两个主要问题是 (i)过度生成和 (ii)没有产生正确的语言。
4.2 1-shot效果
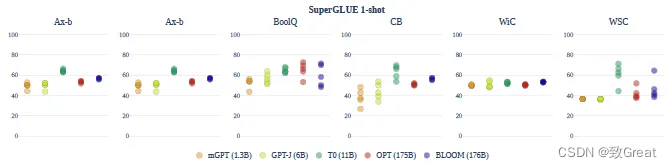
SuperGLUE的一次性性能可变性在所有提示和模型中都减少了。
总的来说,oneshot 设置没有显着改善:模型的平均准确度仍然几乎总是偶然的。
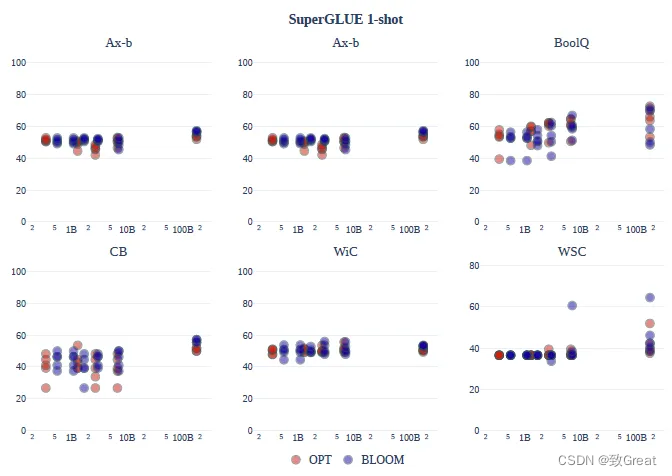
OPT 和 BLOOM模型系列都随着规模的扩大而略有改善,并且在所有任务中系列之间没有一致的差异。BLOOM-176B 在 Ax-b、CB 和 WiC 上领先于 OPT-175B。

许多低资源语言的翻译质量与受监督的 M2M 模型相当,甚至略好。
4.3 文本摘要
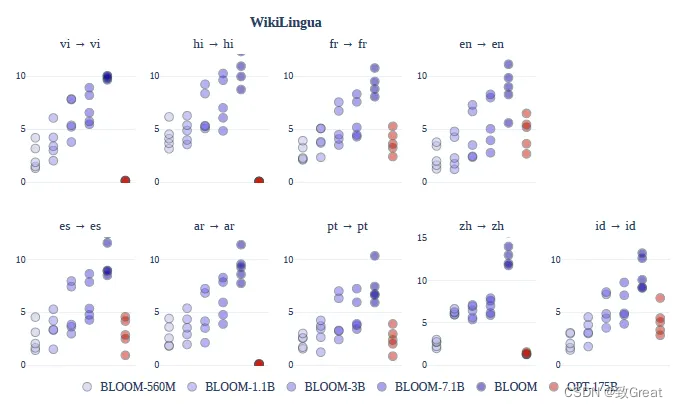
BLOOM在多语言摘要上比 OPT获得了更高的性能,并且性能随着模型参数数量的增加而增加。
4.4 多任务微调
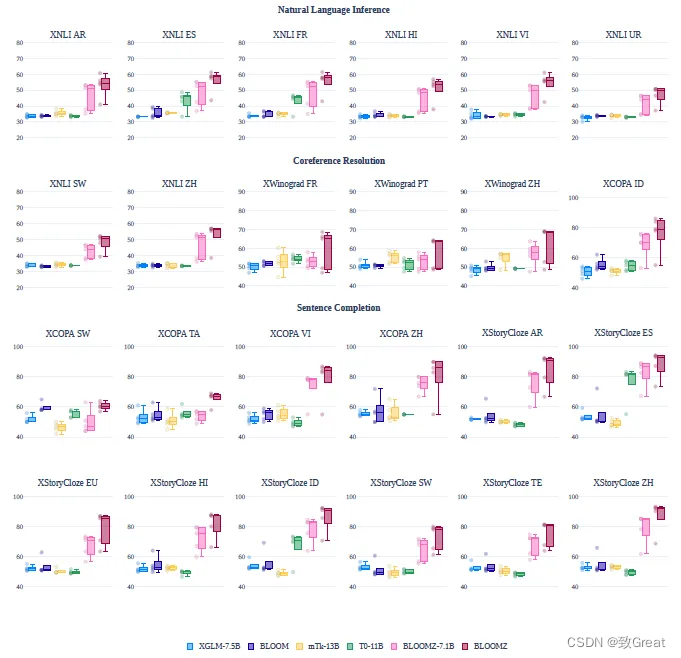
多语言多任务微调,即BLOOMZ,用于提高BLOOM模型的零样本性能。
4.5 代码生成
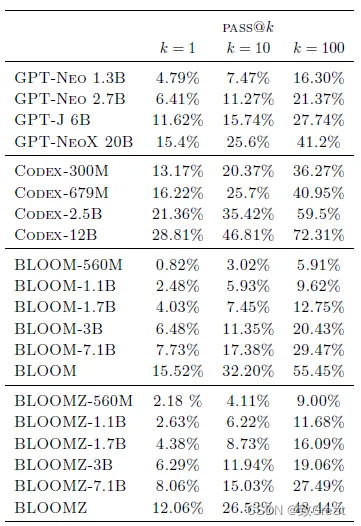
预训练的 BLOOM 模型的性能类似于在 Pile 上训练的类似大小的 GPT 模型。
然而,仅在代码上进行微调的Codex模型比其他模型强得多。
5 总结
- BLOOM主要提升LLM的多语言能力
- 优化方式采用的AIBI、层归一化,其他模型差不多