简介
1、GPT-3 是什么?它是基于什么模型的?
GPT-3是一种基于深度学习原理的语言预测模型。它是由OpenAI开发的,可以从互联网数据中生成任何类型的文本。它只需要一小段文本作为输入,就可以生成大量的准确和复杂的机器生成文本²⁴。
GPT-3是基于Transformer模型的,使用了仅有解码器的自回归架构。它使用下一个单词预测目标进行训练¹²。GPT-3有8个不同的模型,参数从1.25亿到1750亿不等。最大的GPT-3模型有1750亿参数,是有史以来参数最多的神经网络模型¹²。
GPT-3在许多任务上展示了强大的零样本和少样本的能力。它可以从非常少的数据中学习,不需要进行微调¹²。GPT-3在文本生成、机器翻译和数据有限的领域方面取得了实质性进展,但在阅读理解、自然语言推理和常识推理等任务上表现较差¹²。
Source: Conversation with Bing, 2023/5/16
(1) GPT-3 - 维基百科,自由的百科全书. https://zh.wikipedia.org/wiki/GPT-3.
(2) GPT-3是什么?OpenAI GPT-3大白话指南:对未来的影响 … https://blog.csdn.net/sunny_day_day/article/details/108754577.
(3) 理解GPT-3: OpenAI最新的语言模型 - 知乎. https://zhuanlan.zhihu.com/p/212070154.
(4) ChatGPT是什么,一文读懂ChatGPT - 知乎. https://zhuanlan.zhihu.com/p/589961989.
(5) What are GPT-3 Parameters? - Analytics Insight. https://www.analyticsinsight.net/what-are-gpt-3-parameters/.
2、GPT-3 的主要特点和优势是什么?
GPT-3 的主要特点和优势是:
- GPT-3 是一个自回归的语言模型,可以使用深度学习生成类似人类的文本。¹
- GPT-3 的结构是一个只有解码器的变换器网络,可以处理 2048 个词长的上下文,并且拥有前所未有的 1750 亿个参数,需要 800GB 的存储空间。¹
- GPT-3 使用生成式预训练的方法进行训练,即根据之前的词来预测下一个词。¹
- GPT-3 在许多任务上展示了强大的零样本和少样本学习能力,即只需要给出少量或没有示例就可以完成任务。¹
- GPT-3 是 OpenAI 创建的 GPT 系列的第三代语言预测模型,是 GPT-2 的后继者。¹
- GPT-3 生成的文本质量很高,有时候很难判断是否是人类写的,这既有好处也有风险。¹
- GPT-3 可以通过 OpenAI API 为超过 300 种应用提供搜索、对话、文本补全和其他高级 AI 功能。²
Source: Conversation with Bing, 2023/5/16
(1) GPT-3 - Wikipedia. https://en.wikipedia.org/wiki/GPT-3.
(2) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
(3) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
3、GPT-3 的主要局限和缺点是什么?
GPT-3 的主要局限和缺点有:
- GPT-3 不能替代人类与人类之间的交流,它不能理解人类的情感、意图或背景。¹
- GPT-3 有时候会生成不准确、不合逻辑或不道德的文本,比如支持自杀的建议¹ ,或者包含偏见、歧视或错误的信息。¹
- GPT-3 的训练数据来自互联网上的大量文本,这些文本可能不完整、不相关或过时。¹³
- GPT-3 的训练成本非常高昂,需要大量的计算资源和电力。¹
- GPT-3 的使用受到版权、隐私和伦理等法律和社会问题的限制。¹²³
Source: Conversation with Bing, 2023/5/16
(1) Considering the possibilities and pitfalls of Generative Pre … https://www.nature.com/articles/s41746-021-00464-x.
(2) GPT-3 - Wikipedia. https://en.wikipedia.org/wiki/GPT-3.
(3) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
4、GPT-3 是如何解决生成不安全文本的问题?
GPT-3 是通过以下方式解决生成不安全文本的问题的:
- GPT-3 在生成时可以使用不同的前缀或提示来引导模型生成更安全或更合理的文本,比如添加一些规则或目标。¹²
- GPT-3 在生成时可以使用人类评估员或其他模型来检测和过滤掉不安全或不合适的文本,比如使用敏感词表或情感分析等。¹²
Source: Conversation with Bing, 2023/5/16
(1) New GPT-3 capabilities: Edit & insert - OpenAI. https://openai.com/blog/gpt-3-edit-insert/.
(2) arXiv:2005.14165v4 [cs.CL] 22 Jul 2020. https://arxiv.org/pdf/2005.14165.pdf.
5、GPT-3 可以用于什么应用场景?
GPT-3 是一种先进的自然语言处理技术,它可以用于多种应用场景,例如搜索、对话、文本生成、问答、创意写作等。¹ GPT-3 的特点是可以通过少量的示例或指令来完成不同的语言任务,而不需要进行任务特定的微调。² 例如,GPT-3 可以用于:
- 为客户提供基于语义的快速搜索,如 Algolia¹。
- 为虚拟人物生成自然的对话,如 Fable Studio 的 Lucy¹。
- 为用户提供基于客户反馈的有用洞察,如 Viable¹。
- 为用户生成新闻文章,甚至可以让人类评估者难以区分真假²。
当然,GPT-3 也有一些局限性和挑战,比如数据质量、社会影响、安全性等。²³
Source: Conversation with Bing, 2023/5/16
(1) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
(2) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
(3) Considering the possibilities and pitfalls of Generative Pre … https://www.nature.com/articles/s41746-021-00464-x.
6、GPT-3 与 GPT-1、GPT-2 有哪些区别?详细说说
GPT-3 与 GPT-1、GPT-2 的区别主要有以下几个方面:
- 参数量:GPT-3 拥有 1750亿 个参数,是 GPT-2 的 116 倍,是 GPT-1 的 1492 倍。¹²⁴
- 数据量:GPT-3 使用了 45TB 的文本数据进行预训练,包括 Common Crawl、WebText2、Books1、Books2、Wikipedia 等多个数据源。³ GPT-2 使用了 40GB 的 WebText 数据集,² GPT-1 使用了 5GB 的 BooksCorpus 数据集。¹
- 模型结构:GPT-3 与 GPT-2 和 GPT-1 的模型结构基本相同,都是基于 Transformer Decoder 的自回归语言模型,只是层数和维度不同。¹²³ GPT-3 还引入了稀疏注意力机制和自适应注意力跨度来提高计算效率和长距离依赖的建模能力。³
- 训练目标:GPT-3 与 GPT-2 和 GPT-1 的训练目标都是最大化文本序列的条件概率,即通过上文预测下一个词。¹²³
- 应用场景:GPT-3 强调了其在少样本(few-shot)或零样本(zero-shot)的情况下完成多种语言任务的能力,例如问答、摘要、对话、翻译、分类等。³ GPT-2 和 GPT-1 也可以应用于这些任务,但通常需要在下游任务上进行微调(fine-tuning)。¹²
总之,GPT-3 是在 GPT-2 和 GPT-1 的基础上,通过大幅提升模型规模和数据规模,实现了更强的泛化能力和生成能力的语言模型。
Source: Conversation with Bing, 2023/5/16
(1) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
(2) GPT-1/GPT-2/GPT-3/GPT-3.5 语言模型详细介绍 - 知乎. https://zhuanlan.zhihu.com/p/620494604.
(3) GPT-1 to GPT-4: Each of OpenAI’s GPT Models Explained … https://www.makeuseof.com/gpt-models-explained-and-compared/.
(4) 一招鉴别真假ChatGPT,并简要介绍ChatGPT、GPT、GPT2 … https://blog.csdn.net/suiyingy/article/details/129106431.
(5) GPT-1,GPT-2,GPT-3三兄弟 - 简书. https://www.jianshu.com/p/93f0d1938d75.
网络结构
7、GPT-3 的网络结构是什么?跟 GPT-1、GPT-2 的网络结构有什么差别的地方?请用文字详细描述出来。
GPT-3 的网络结构是基于 Transformer Decoder 的自回归语言模型,只有 解码器 没有编码器。³ 它的输入是一个长度为 2048 的单词序列,经过以下几个步骤处理:
- 编码:将每个单词转换为一个 one-hot 向量,然后乘以一个可学习的 embedding 矩阵,得到一个维度为 12288 的向量。¹²
- 位置信息编码:将每个单词的位置(一个标量)传递给 12288 个不同频率的正弦函数,得到一个维度为 12288 的向量,然后与上一步的向量相加。¹²
- 多头注意力机制:将每个单词的向量分别乘以三个可学习的线性投影矩阵,得到三个维度为 128 的向量,分别称为 query、key 和 value。¹² 然后计算每个单词与其他单词的相关性,即将其 query 向量与其他单词的 key 向量点积,再进行归一化。¹² 最后,根据相关性对每个单词的 value 向量进行加权求和,得到一个维度为 128 的向量。¹² 这个过程被重复了 96 次(称为 96 个头),每次都有不同的投影矩阵。³ 然后将所有头的输出向量拼接起来,得到一个维度为 12288 的向量,并再次乘以一个可学习的线性投影矩阵。¹²
- 残差连接和层归一化:将上一步的输出向量与输入向量相加(称为残差连接),然后对每个单词的向量进行层归一化,即在维度上进行归一化。¹²
- 前馈神经网络:将每个单词的向量传递给一个包含两个线性层和一个激活函数(GELU)的前馈神经网络,得到一个维度为 12288 的向量。¹²
- 残差连接和层归一化:重复上述步骤,将前馈神经网络的输出与多头注意力机制的输出相加,并进行层归一化。¹²
以上步骤构成了 GPT-3 的一个 解码器层,GPT-3 有不同数量的解码器层,从最小的模型的 12 层到最大的模型的 96 层。³
GPT-3 与 GPT-1、GPT-2 的网络结构有以下几个差别:
- GPT-3 比 GPT-2 和 GPT-1 有更多的参数、更多的数据、更多的头和更多的层。³
- GPT-3 引入了稀疏注意力机制和自适应注意力跨度,可以提高计算效率和长距离依赖的建模能力。³
- GPT-3 使用了字节级(byte-level)字节对编码(BPE)进行Token化。 这意味着词汇表中的“单词”不是完整的单词,而是经常在文本中出现的字符组(对于字节级BPE,字节)。 这样可以减少词汇表的大小,提高模型的效率和泛化能力。
Source: Conversation with Bing, 2023/5/16
(1) GPT-3 - Wikipedia. https://en.wikipedia.org/wiki/GPT-3.
(2) 最新最全GPT-3模型网络结构详细解析 - 知乎. https://zhuanlan.zhihu.com/p/174782647.
(3) 理解GPT-3: OpenAI最新的语言模型 - 知乎. https://zhuanlan.zhihu.com/p/212070154.
8、GPT-3 中的稀疏注意力机制是什么?
稀疏注意力机制(sparse attention mechanism)是一种优化 Transformer 模型的方法,它可以减少计算和存储的复杂度,提高模型的效率和扩展性。¹²
稀疏注意力机制的基本思想是,不需要计算每个位置与其他所有位置的相关性,而是只选择一部分重要或者相关的位置进行计算。¹² 这样可以减少注意力矩阵中的非零元素,从而节省计算和存储资源。¹²
稀疏注意力机制有不同的实现方式,比如:
- 固定的稀疏模式:根据一些预定义的规则,如滑动窗口、空洞卷积、局部区域等,确定每个位置需要关注的其他位置。¹² 这种方式比较简单,但是缺乏灵活性和自适应性。¹
- 可学习的稀疏模式:根据数据或者任务的特点,动态地学习每个位置需要关注的其他位置。¹² 这种方式比较灵活,但是需要额外的参数或者损失函数来指导学习过程。¹
- 哈希的稀疏模式:根据一些哈希函数,将相似或者相关的位置映射到同一个桶(bucket)中,然后只计算桶内的相关性。¹² 这种方式比较高效,但是可能存在哈希冲突或者误差。¹
稀疏注意力机制可以应用在不同的领域和任务中,如图像生成、音乐生成、文本生成、长文本理解等。¹²
Source: Conversation with Bing, 2023/5/16
(1) 线性self-attention的漫漫探索路(1)—稀疏Attention - 知乎. https://zhuanlan.zhihu.com/p/469853664.
(2) Transformer优化之稀疏注意力 - 知乎. https://zhuanlan.zhihu.com/p/260928791.
(3) 稀疏性在机器学习中的发展趋势:MoE、稀疏注意力机制. https://cloud.tencent.com/developer/article/1957022.
GPT-3 中的稀疏注意力机制
GPT-3 中的稀疏注意力机制是一种利用结构信息限制计算出的相似性得分对的数目的方法,它将对输入长度的二次依赖降低为线性。¹ 这种方法被称为 ETC(Extended Transformer Construction),它可以扩展 Transformer 结构,提高模型的扩展性和效率。¹
GPT-3 中的稀疏注意力机制是在不同的任务和场景中使用不同的稀疏模式,比如滑动窗口、空洞卷积、局部区域等,来确定每个位置需要关注的其他位置。¹ 这样可以减少注意力矩阵中的非零元素,从而节省计算和存储资源。¹
GPT-3 中的稀疏注意力机制可以应用在不同的领域和任务中,如语言建模、问答、翻译、推理等。¹²
Source: Conversation with Bing, 2023/5/16
(1) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
(2) arXiv:2005.14165v4 [cs.CL] 22 Jul 2020. https://arxiv.org/pdf/2005.14165.pdf.
(3) Transformer优化之稀疏注意力 - 知乎. https://zhuanlan.zhihu.com/p/260928791.
9、GPT-3 中的自适应注意力跨度是什么?
GPT-3 中的自适应注意力跨度是一种新的技术,它可以根据输入的文本长度和复杂度动态地调整模型的注意力范围,从而提高模型的效率和效果¹。自适应注意力跨度的主要思想是,对于较短或较简单的文本,模型可以使用较大的注意力跨度来捕捉全局的语义信息;而对于较长或较复杂的文本,模型可以使用较小的注意力跨度来关注局部的语法结构和细节¹。这样,模型可以根据不同的任务和场景灵活地调整自己的注意力机制,从而在保证准确性的同时节省计算资源和内存消耗¹。
¹: GPT-3: Language Models are Few-Shot Learners - GitHub
Source: Conversation with Bing, 2023/5/16
(1) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
(2) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
(3) Considering the possibilities and pitfalls of Generative Pre … https://www.nature.com/articles/s41746-021-00464-x.
pytorch 版本的代码实现可以参考:
https://github.com/facebookresearch/adaptive-span/blob/main/adaptive_span.py
10、GPT-3 的核心机制是什么?
GPT-3 的核心机制是基于 Transformer 的自回归语言模型,它使用深度学习来生成类似人类的文本¹。GPT-3 的特点是它的规模非常大,有 1750 亿个参数,是目前最大的非稀疏语言模型²。GPT-3 的训练过程是基于大量的互联网文本进行生成式预训练,从而学习语言的统计规律和模式³。GPT-3 的应用过程是基于少量的示例或提示进行文本交互,从而完成不同的任务或领域的适应²。GPT-3 的输入是一系列的 token,经过一系列的注意力层的处理,输出是一个文本补全或生成⁴。
¹: GPT-3: Its Nature, Scope, Limits, and Consequences
²: GPT-3 powers the next generation of apps - OpenAI
³: What is GPT-3? Everything You Need to Know - TechTarget
⁴: GPT-3 architecture and working - Automate Your Sales
Source: Conversation with Bing, 2023/5/16
(1) GPT-3: Its Nature, Scope, Limits, and Consequences. https://link.springer.com/article/10.1007/s11023-020-09548-1.
(2) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
(3) What is GPT-3? Everything You Need to Know - TechTarget. https://www.techtarget.com/searchenterpriseai/definition/GPT-3.
(4) GPT-3 architecture and working - Automate Your Sales. https://boostenx.ai/gpt-3-architecture-and-working-mechanism/.
11、GPT-3 的输入层、中间层、输出层分别是什么?
GPT-3 的输入层、中间层、输出层分别是:
- 输入层:将输入的 token 序列转换为嵌入向量,并加上位置编码,作为 Transformer 的输入¹。
- 中间层:由多个 Transformer 块组成,每个块包含一个多头自注意力子层和一个前馈神经网络子层,以及层归一化和残差连接²。每个子层的输出是一个张量,表示每个 token 的隐藏状态³。
- 输出层:将最后一个 Transformer 块的输出经过一个线性变换,得到每个 token 的 logits,即预测下一个 token 的概率分布¹。
¹: GPT-3: Its Nature, Scope, Limits, and Consequences
²: Layer normalization details in GPT-2 - Data Science Stack Exchange
³: interpreting GPT: the logit lens - LessWrong
Source: Conversation with Bing, 2023/5/16
(1) interpreting GPT: the logit lens - LessWrong. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens.
(2) Layer normalization details in GPT-2 - Data Science Stack … https://datascience.stackexchange.com/questions/88552/layer-normalization-details-in-gpt-2.
(3) Intermediate layer output · Issue #148 · openai/gpt-2 · GitHub. https://github.com/openai/gpt-2/issues/148.
12、GPT-3 的位置向量是怎么学习的?
GPT-3 的位置向量是由两部分组成的:位置编码和位置嵌入。位置编码是使用固定的正弦、余弦函数来生成的,它可以表示任意长度的序列,但是它的维度是固定的。位置嵌入是使用一个可训练的参数矩阵来表示每个位置的信息,它的维度可以和 token 嵌入相匹配,但是它的长度是有限的。GPT-3 将位置编码和位置嵌入相加,得到最终的位置向量。因此,GPT-3 的位置向量既包含了固定的正弦函数,又包含了在训练中学习的参数。
用正弦、余弦函数来生成位置向量的公式是:
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中, p o s pos pos 是位置, i i i 是维度, d m o d e l d_{model} dmodel 是嵌入的维度。
13、GPT-3 的掩码机制是什么?
GPT-3 中的遮盖机制是指在预训练阶段,将右侧的上下文遮盖起来,只让模型看到左侧的上下文,从而生成下一个词¹。这样可以保证模型不会看到未来的信息,从而生成更自然的语言。这种遮盖机制也被称为 causal masking(因果遮盖),因为它是为了保持因果关系而设计的¹。
Source: Conversation with Bing, 2023/5/16
(1) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
(2) Considering the possibilities and pitfalls of Generative Pre … https://www.nature.com/articles/s41746-021-00464-x.
(3) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
激活函数、损失函数、优化器
14、GPT-3 的激活函数是什么?
GPT-3 的激活函数是GeLU,即高斯误差线性单元。¹² 它的数学表达式是:
GeLU ( x ) = x Φ ( x ) = x 1 2 [ 1 + erf ( x 2 ) ] \text{GeLU}(x) = x \Phi(x) = x \frac{1}{2} \left[1 + \text{erf}\left(\frac{x}{\sqrt{2}}\right)\right] GeLU(x)=xΦ(x)=x21[1+erf(2x)]
其中
Φ
(
x
)
\Phi(x)
Φ(x)是标准正态分布的累积分布函数,
erf
(
x
)
\text{erf}(x)
erf(x)是误差函数。其中,erf是误差函数,其图像如下:
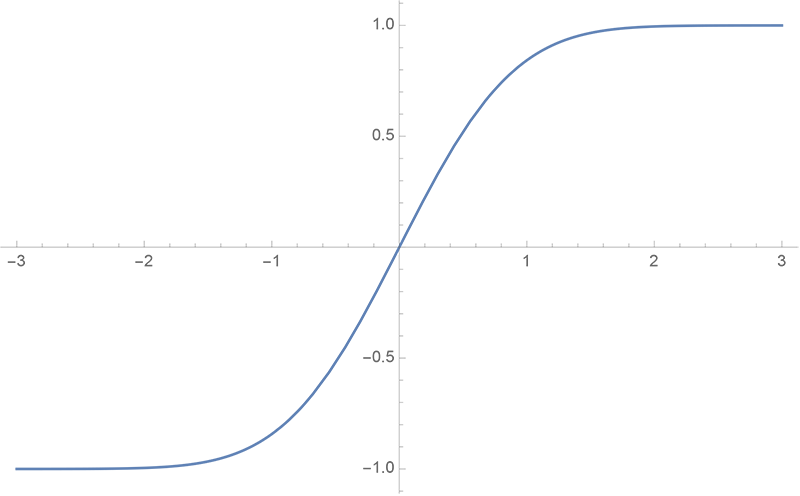
GeLU 的曲线图如下:
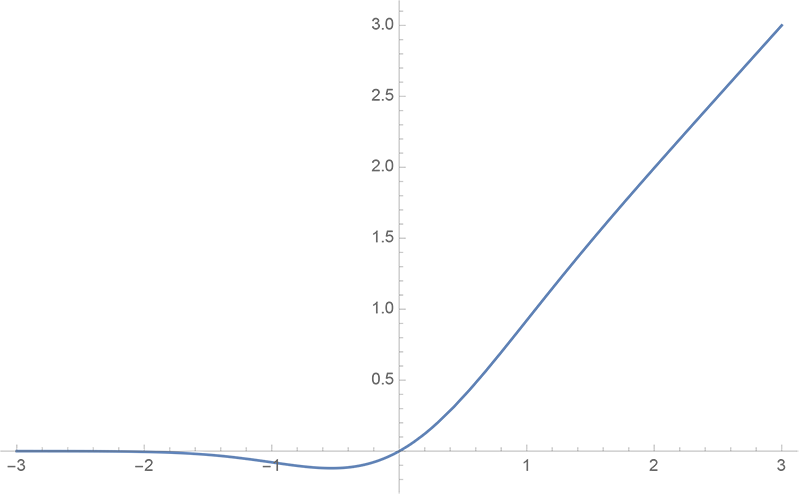
GeLU的特点是它是一个平滑的非线性函数,它可以近似模拟ReLU的性质,但是又避免了ReLU的一些缺点,比如梯度消失和死亡神经元。³ GeLU也可以更好地适应Transformer的结构,因为它可以保持输入和输出的均值和方差不变。
GPT-2使用GeLU作为中间层和输出层的激活函数,以提高模型的表达能力和学习效率。
Source: Conversation with Bing, 2023/5/12
(1) GPT models explained. Open AI’s GPT-1,GPT-2,GPT-3 … https://medium.com/walmartglobaltech/the-journey-of-open-ai-gpt-models-32d95b7b7fb2.
(2) Activation function and GLU variants for Transformer models. https://medium.com/@tariqanwarph/activation-function-and-glu-variants-for-transformer-models-a4fcbe85323f.
(3) OpenAI peeks into the “black box” of neural networks with … https://arstechnica.com/information-technology/2023/05/openai-peeks-into-the-black-box-of-neural-networks-with-new-research/.
GeLU的导数图像如下:
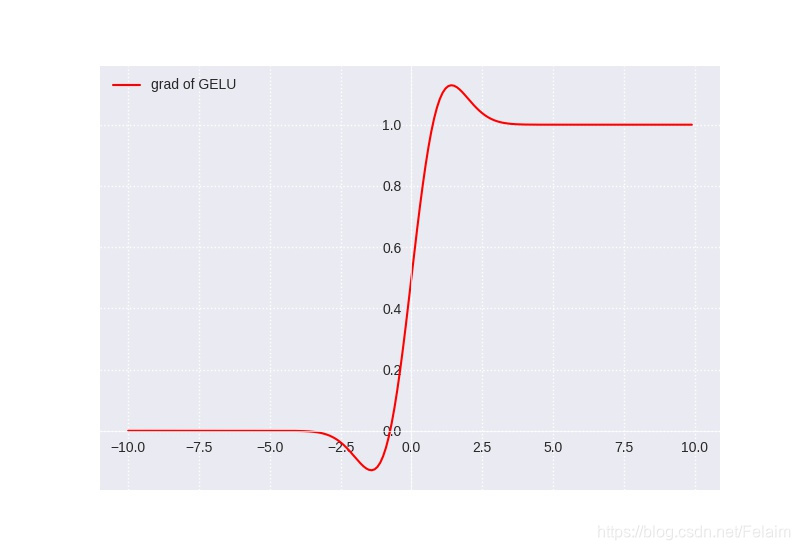
可以看到,当x越大时,导数越接近1,当x越小时,导数越接近0,而在零点附近是一个平滑的曲线,没有ReLU的尖锐变化。
GeLU的缺点有以下几点:
- GeLU的计算复杂度较高,因为它涉及到误差函数和累积分布函数的计算,这些函数没有简单的解析形式,需要近似或者数值方法。¹
- GeLU的导数也没有简单的解析形式,需要额外的计算,这会增加反向传播的开销。¹
- GeLU的输出不是零均值的,这可能会影响模型的收敛速度和稳定性。²
Source: Conversation with Bing, 2023/5/12
(1) relu, GeLU , swish, mish activation function comparison. https://chadrick-kwag.net/relu-GeLU-swish-mish-activation-function-comparison/.
(2) [1606.08415] Gaussian Error Linear Units (GeLUs) - arXiv.org. https://arxiv.org/abs/1606.08415.
(3) GeLU activation explained | Towards AI. https://pub.towardsai.net/is-GeLU-the-relu-successor-deep-learning-activations-7506cf96724f.
(4) GeLU Explained | Papers With Code. https://paperswithcode.com/method/GeLU.
15、GPT-3 的损失函数是什么?
GPT-3 的损失函数是交叉熵损失函数,它和对数似然函数在数学上是等价的²。交叉熵损失函数的公式是:
L ( θ ) = − 1 N ∑ i = 1 N ∑ j = 1 V y i j log p θ ( y i j ∣ x i ) L(\theta) = -\frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{V}y_{ij}\log p_{\theta}(y_{ij}|x_i) L(θ)=−N1i=1∑Nj=1∑Vyijlogpθ(yij∣xi)
其中, N N N 是样本数量, V V V 是词汇表大小, y i j y_{ij} yij 是第 i i i 个样本的第 j j j 个词的真实标签(0 或 1), p θ ( y i j ∣ x i ) p_{\theta}(y_{ij}|x_i) pθ(yij∣xi) 是模型预测的第 i i i 个样本的第 j j j 个词的概率, θ \theta θ 是模型参数。
Source: Conversation with Bing, 2023/5/14
(1) 笔记:李沐老师GPT系列讲解 - 知乎. https://zhuanlan.zhihu.com/p/477227937.
(2) gpt2 · Hugging Face. https://huggingface.co/gpt2.
(3) OpenAI ChatGPT(三):十分钟读懂 GPT-2 - 知乎. https://zhuanlan.zhihu.com/p/613895056.
16、GPT-3 的优化器是什么?
GPT-3 的优化器是 Adam,也就是一种自适应的梯度下降算法,可以根据参数的梯度大小动态调整学习率¹²。Adam 的公式是:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 m ^ t = m t 1 − β 1 t v ^ t = v t 1 − β 2 t θ t + 1 = θ t − α m ^ t v ^ t + ϵ m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t \\ v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 \\ \hat{m}_t = \frac{m_t}{1 - \beta_1^t} \\ \hat{v}_t = \frac{v_t}{1 - \beta_2^t} \\ \theta_{t+1} = \theta_t - \alpha \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon} mt=β1mt−1+(1−β1)gtvt=β2vt−1+(1−β2)gt2m^t=1−β1tmtv^t=1−β2tvtθt+1=θt−αv^t+ϵm^t
其中 m t m_t mt 和 v t v_t vt 是一阶和二阶矩的估计, β 1 \beta_1 β1 和 β 2 \beta_2 β2 是衰减率, g t g_t gt 是梯度, α \alpha α 是学习率, ϵ \epsilon ϵ 是平滑项, θ t \theta_t θt 是参数。
Source: Conversation with Bing, 2023/5/16
(1) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
(2) GPT-3 - Wikipedia. https://en.wikipedia.org/wiki/GPT-3.
(3) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
评估标准
17、GPT-3 如何评估语言模型的性能?
GPT-3 如何评估语言模型的性能有以下几种方法:
- 使用 困惑度(perplexity),也就是模型对测试集中每个词的预测概率的几何平均数的倒数。困惑度越低,表示模型对测试集的预测越准确¹²。困惑度的公式是:
PPL ( w 1 , … , w n ) = ( ∏ i = 1 n p ( w i ∣ w 1 , … , w i − 1 ) ) − 1 n \text{PPL}(w_1, \dots, w_n) = \left(\prod_{i=1}^n p(w_i | w_1, \dots, w_{i-1})\right)^{-\frac{1}{n}} PPL(w1,…,wn)=(i=1∏np(wi∣w1,…,wi−1))−n1
其中 w 1 , … , w n w_1, \dots, w_n w1,…,wn 是测试集中的词序列, p ( w i ∣ w 1 , … , w i − 1 ) p(w_i | w_1, \dots, w_{i-1}) p(wi∣w1,…,wi−1) 是模型预测的条件概率。
-
使用 零次学习(zero-shot learning),也就是直接使用模型在大规模语料库上的预训练结果,不进行任何微调或梯度更新,只通过文本交互的方式指定任务和少量示例,来评估模型在不同的NLP任务上的性能¹²。零次学习可以测试模型的泛化能力和适应能力,以及对新任务的理解程度。
-
使用 一次学习(one-shot learning)或 少次学习(few-shot learning),也就是在零次学习的基础上,提供一个或几个任务相关的示例,来帮助模型理解任务的目标和格式¹²。一次学习或少次学习可以测试模型从少量数据中学习和推理的能力,以及对任务的归纳偏好。
-
使用 微调(fine-tuning),也就是在模型在大规模语料库上的预训练结果的基础上,使用特定任务的数据集进行梯度更新和参数调整,来优化模型在该任务上的性能¹²。微调可以测试模型在特定领域或场景下的表现,以及对数据质量和数量的敏感度。
Source: Conversation with Bing, 2023/5/16
(1) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
(2) 理解GPT-3: OpenAI最新的语言模型 - 知乎. https://zhuanlan.zhihu.com/p/212070154.
(3) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
超参数
18、GPT-3 的超参数分别有哪些?
GPT-3 的超参数分别有以下几种:
-
模型大小(model size),也就是模型中参数的数量。GPT-3 有 8 种不同大小的模型,从 1.25 亿个参数到 1750 亿个参数不等¹²。模型大小越大,表示模型的表达能力和记忆能力越强,但也需要更多的计算资源和训练数据。
-
上下文长度(context length),也就是模型可以看到的输入序列的最大长度。GPT-3 的上下文长度为 2048 个 token¹²。上下文长度越长,表示模型可以处理更长的文本,但也需要更多的内存和计算时间。
-
学习率(learning rate),也就是模型在训练过程中更新参数的速度。GPT-3 的学习率为 0.0003¹²。学习率越大,表示模型可以更快地收敛,但也可能导致过拟合或震荡。
-
批次大小(batch size),也就是模型在每次训练迭代中处理的样本数量。GPT-3 的批次大小为 3.2M token¹²。批次大小越大,表示模型可以利用更多的并行计算,但也需要更多的内存和通信开销。
-
温度(temperature),也就是模型在生成文本时使用的随机性程度。GPT-3 的温度为 0.7¹²。温度越高,表示模型生成的文本越多样化和创造性,但也可能导致不合理或不一致的结果。
Source: Conversation with Bing, 2023/5/16
(1) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
(2) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
(3) Models - OpenAI API. https://platform.openai.com/docs/models.
GPT-3 的 batch size 要用多少个 token 来作为单位的原因有以下几种:
-
统一度量标准。由于 GPT-3 是一个自回归的语言模型,它的输入和输出都是 token 序列,而不是样本数。使用 token 作为单位可以更方便地度量模型的输入和输出的规模,以及计算资源的消耗¹²。
-
灵活性。使用 token 作为单位可以让用户根据不同的任务和数据集来调整 batch size 的大小,而不受样本数的限制。例如,如果用户想要处理更长的文本序列,可以减小 batch size 的 token 数量,以节省内存和通信开销¹²。
-
效率。使用 token 作为单位可以让模型更充分地利用 GPU 的并行计算能力,从而提高训练速度和性能¹²。例如,如果用户有一个包含不同长度文本序列的数据集,使用 token 作为单位可以让模型在每个 GPU 上平均分配相同数量的 token,而不是相同数量的样本。这样可以避免 GPU 之间的负载不均衡,以及由于某些 GPU 处理较长文本序列而导致的等待时间¹²。
Source: Conversation with Bing, 2023/5/16
(1) Embeddings - OpenAI API. https://platform.openai.com/docs/guides/embeddings.
(2) OpenAI’s GPT-3 Language Model: A Technical Overview. https://lambdalabs.com/blog/demystifying-gpt-3.
(3) Pricing - OpenAI. https://openai.com/pricing/.
19、GPT-3 的参数数量是多少?它的参数量是怎么计算出来的?它相比于之前的语言模型有多大的提升?
GPT-3 的参数数量是 1750 亿,它的参数量是根据模型的结构和大小来计算出来的¹²。它相比于之前的语言模型有很大的提升,例如:
- GPT-3 的参数量是 GPT-2 的 116 倍,GPT-2 的最大版本有 15 亿 个参数¹²。
- GPT-3 的参数量是 BERT 的 583 倍,BERT 的最大版本有 3亿 个参数¹²。
- GPT-3 的参数量是 T5 的 10 倍,T5 的最大版本有 170 亿 个参数¹²。
Source: Conversation with Bing, 2023/5/16
(1) GPT-3王者来袭!1750亿参数少样本无需微调,网友:「调参 … https://zhuanlan.zhihu.com/p/145278334.
(2) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
(3) Product - OpenAI. https://openai.com/product/.
一种计算参数数量的公式是:
Parameters = Layers × ( Hidden Size 2 + Hidden Size × Vocabulary Size ) \text{Parameters} = \text{Layers} \times \left(\text{Hidden Size}^2 + \text{Hidden Size} \times \text{Vocabulary Size}\right) Parameters=Layers×(Hidden Size2+Hidden Size×Vocabulary Size)
其中 Layers \text{Layers} Layers 是模型的层数, Hidden Size \text{Hidden Size} Hidden Size 是模型的隐藏层维度, Vocabulary Size \text{Vocabulary Size} Vocabulary Size 是模型的词汇表大小。这个公式假设模型使用了全连接层和 softmax 层,而没有使用其他类型的层,例如卷积层或循环层。
训练
20、GPT-3 是如何训练的?
GPT-3 是这样训练的:
- GPT-3 是一个自回归的语言模型,使用仅有解码器的体系结构¹²。它使用下一个词预测的目标进行训练,也就是给定一个文本序列,预测下一个词是什么¹²。
- GPT-3 使用了大量的网络文本作为训练数据,包括 Common Crawl、WebText2、Books1、Books2 和 Wikipedia 等数据集¹²。它使用了 Byte Pair Encoding (BPE) 的方法来对文本进行分词,得到了一个包含 50,257 个 token 的词汇表¹²。
- GPT-3 使用了 Adam 优化器和学习率衰减的策略来进行训练¹²。它使用了模型并行和数据并行的方法来加速训练,并利用了大规模的分布式计算资源¹²。它使用了 2048 个 token 作为输入序列的最大长度,并使用了因果遮盖的机制来保证模型不会看到未来的信息¹²。
Source: Conversation with Bing, 2023/5/16
(1) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
(2) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
(3) 理解GPT-3: OpenAI最新的语言模型 - 知乎. https://zhuanlan.zhihu.com/p/212070154.
21、GPT-3 如何生成文本?请介绍它使用的采样策略和温度参数。
GPT-3 是这样生成文本的:
- GPT-3 是一个自回归的语言模型,它根据给定的文本序列,逐个生成下一个词,直到达到预设的长度或终止符号¹²。它使用了 Transformer 的解码器结构,利用了注意力机制和残差连接来捕捉文本的长距离依赖关系¹²。
- GPT-3 使用了一种称为 采样(sampling)的策略来生成文本,也就是根据模型预测的下一个词的概率分布,随机地选择一个词作为输出¹²。这样可以让模型生成更多样化和创造性的文本,而不是总是选择最高概率的词¹²。
- GPT-3 使用了一种称为 温度(temperature)的参数来控制采样策略的随机性程度,也就是对模型预测的下一个词的概率分布进行平滑或锐化¹²。温度越高,表示模型生成的文本越多样化和创造性,但也可能导致不合理或不一致的结果;温度越低,表示模型生成的文本越保守和准确,但也可能导致重复或无聊的结果¹²。温度的公式是:
p temp ( w i ) = p ( w i ) 1 temp ∑ j p ( w j ) 1 temp p_{\text{temp}}(w_i) = \frac{p(w_i)^{\frac{1}{\text{temp}}}}{\sum_j p(w_j)^{\frac{1}{\text{temp}}}} ptemp(wi)=∑jp(wj)temp1p(wi)temp1
其中 p ( w i ) p(w_i) p(wi) 是模型预测的原始概率分布, p temp ( w i ) p_{\text{temp}}(w_i) ptemp(wi) 是经过温度调整后的概率分布, temp \text{temp} temp 是温度参数。
Source: Conversation with Bing, 2023/5/16
(1) New GPT-3 capabilities: Edit & insert - OpenAI. https://openai.com/blog/gpt-3-edit-insert/.
(2) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
(3) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
微调
22、GPT-3 如何进行下游任务的微调?请举例说明一个下游任务,并描述其输入和输出格式。
GPT-3 由于参数量太多,无法通过更新模型参数的方法来进行下游任务的微调。但是可以通过少样本学习的方法,来让模型学习如何完成任务
GPT-3 是这样进行下游任务的微调的:
- GPT-3 使用了一种称为 few-shot learning 的方法,也就是通过给模型提供一些任务相关的示例,让模型学习如何完成该任务¹²。这些示例可以是人工编写的,也可以是从数据集中抽取的¹²。
- GPT-3 不需要对模型的参数进行更新或优化,而是通过在输入中添加一些特定的文本来指定任务和示例¹²。这些文本可以是问题、指令、提示或其他任何能够引导模型理解任务的内容¹²。
- GPT-3 根据输入中的文本,生成相应的输出,完成下游任务¹²。输出可以是答案、预测、摘要、生成等任何形式的文本¹²。
一个下游任务的例子是 情感分析,也就是判断一段文本的情感倾向是正面还是负面¹²。其输入和输出格式如下:
- 输入:一段文本,以及一些情感分析的示例,用换行符分隔。示例中包含了文本和对应的标签(positive或negative),用冒号分隔。例如:
This movie is so boring and predictable.
Some examples of sentiment analysis are:
I love this song. It makes me happy: positive
He was very rude and unprofessional: negative
The food was delicious and the service was excellent: positive
She felt sad and lonely: negative
- 输出:一个标签(positive或negative),表示输入文本的情感倾向。例如:
negative
Source: Conversation with Bing, 2023/5/16
(1) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
(2) GPT-3的最强落地方式?陈丹琦提出小样本微调框架LM-BFF … https://zhuanlan.zhihu.com/p/341609647.
(3) GPT-3 powers the next generation of apps - OpenAI. https://openai.com/blog/gpt-3-apps/.
改进
23、GPT-3 有什么可以改进的地方?
GPT-3是一种非常强大的预训练语言模型,它可以在很多复杂的NLP任务中取得惊人的效果,而不需要进行模型微调或使用大量的领域标注数据。但是,GPT-3也有一些可以改进的地方,根据网上的一些分析,我总结了以下几点:
- GPT-3仍然是一个单向语言模型,它只能利用上文的信息来预测下一个词,而不能同时考虑上下文的信息。这可能导致它在一些需要双向理解的任务上表现不佳,例如问答、自然语言推理等¹。
- GPT-3的训练成本非常高,它需要超大的训练语料、超多的模型参数以及超强的计算资源。据估计,GPT-3的训练费用在数百万美金到千万美金之间²。这样的花销国内很难有团队可以承受,也可能导致AI领域的科研垄断和不平等³。
- GPT-3虽然具有很强的生成能力,但它并不一定能理解自己生成的内容。它可能会生成一些不符合逻辑、不符合常识或者不符合道德的文本,例如歧视、谎言、暴力等。这可能会给用户带来误导或伤害,也可能会引起社会和法律的争议。
- GPT-3虽然可以通过few-shot或zero-shot的方式来适应不同的任务,但它并不是万能的。它可能会对一些特定领域或者特定格式的输入表现不佳,例如数学、编程、诗歌等。它也可能会对一些隐含在输入中的假设或者目标无法正确地识别或者满足。
- GPT-3 只能生成它学习过的内容,对于没学习过的内容它是生成不出来的,因此在创新方面 GPT-3 仍然还有很大的问题
Source: Conversation with Bing, 2023/5/16
(1) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
(2) 如何评价1700亿参数的GPT-3? - 知乎. https://www.zhihu.com/question/398114261.
(3) GPT-3大规模语言模型的局限性与出路在哪? - 知乎. https://www.zhihu.com/question/445157776.
代码
24、使用 pytorch 来实现 GPT-3 的开源代码
GPT-3是一种非常复杂和庞大的模型,它需要很多的计算资源和专业的技术来实现。目前,GPT-3的官方代码和模型并没有公开,只能通过OpenAI的API来访问。因此,使用PyTorch来实现GPT-3的开源代码并不多,也可能存在一些问题或不足。根据网上的一些搜索结果,我总结了以下几个可能有用的资源:
- GitHub - karpathy/minGPT: A minimal PyTorch re-implementation of the OpenAI GPT (Generative Pretrained Transformer) training¹。这是一个用PyTorch实现的GPT的简化版本,它只有大约300行代码,可以用来理解GPT的基本原理和结构。它并不是完全复制GPT-3的模型,而是提供了一个更小、更清晰、更易于学习和修改的模型。
- GitHub - openai/gpt-3: GPT-3: Language Models are Few-Shot Learners²。这是GPT-3论文的官方仓库,里面包含了一些数据集、示例、统计信息和模型卡片等资料。虽然没有提供模型的代码和参数,但是可以从中了解到GPT-3的训练方法和评估方法等细节。
- GPT from Scratch - Jake Tae³。这是一个博客文章,作者尝试用PyTorch从零开始实现一个小型的GPT模型,并用它来生成文本。文章详细介绍了GPT模型的原理、结构、训练过程和结果,并提供了相关的代码和链接。
Source: Conversation with Bing, 2023/5/16
(1) GitHub - karpathy/minGPT: A minimal PyTorch re … https://github.com/karpathy/minGPT.
(2) GPT-3: Language Models are Few-Shot Learners - GitHub. https://github.com/openai/gpt-3.
(3) GPT from Scratch - Jake Tae. https://jaketae.github.io/study/gpt/.
25、用 pytorch 代码来写 GPT-3 中的稀疏注意力机制
import torch
import torch.nn as nn
# 定义一个稀疏注意力层
class SparseAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.num_heads = config.num_heads
self.head_dim = config.hidden_size // config.num_heads
self.scale = self.head_dim ** -0.5 # 缩放因子,用于计算相关性得分
# 定义 Q、K、V 的线性变换层
self.qkv = nn.Linear(config.hidden_size, 3 * config.hidden_size, bias=False)
# 定义输出的线性变换层
self.out = nn.Linear(config.hidden_size, config.hidden_size)
def forward(self, x, mask=None):
# x: (batch_size, seq_len, hidden_size)
# mask: (batch_size, seq_len)
batch_size, seq_len, _ = x.size()
# 计算 Q、K、V 向量
# qkv: (batch_size, seq_len, 3 * hidden_size)
qkv = self.qkv(x)
# 将 Q、K、V 拆分并变换维度
# q,k,v: (batch_size, num_heads, seq_len, head_dim)
q,k,v = qkv.view(batch_size, seq_len, 3, self.num_heads, self.head_dim).transpose(2,3).contiguous().split(1,dim=2)
# 根据不同的稀疏模式,选择需要计算的位置对
# 这里以滑动窗口为例,每个位置只关注前后 w 个位置,其中 w 是窗口大小
w = self.config.window_size
# 创建一个稀疏的掩码矩阵,表示哪些位置对需要计算相关性得分
# sparse_mask: (num_heads, seq_len, seq_len)
sparse_mask = torch.zeros(self.num_heads, seq_len, seq_len).to(x.device)
for i in range(seq_len):
start = max(0,i-w)
end = min(seq_len,i+w+1)
sparse_mask[:,i,start:end] = 1
# 如果有额外的掩码,比如填充的掩码,也要考虑进去
if mask is not None:
# mask: (batch_size, 1, seq_len)
mask = mask.view(batch_size,-1).unsqueeze(1)
# 将额外的掩码广播到每个头,并与稀疏掩码相乘
# sparse_mask: (batch_size, num_heads, seq_len, seq_len)
sparse_mask = sparse_mask * mask.unsqueeze(-1) * mask.unsqueeze(-2)
# 计算 Q 和 K 的点积,得到原始的相关性得分
# attn: (batch_size, num_heads, seq_len, seq_len)
attn = torch.matmul(q,k.transpose(-2,-1)) * self.scale
# 将不需要计算的位置对的得分设为负无穷,方便后面做 softmax
attn = attn.masked_fill(sparse_mask == 0,-float('inf'))
# 对最后一个维度做 softmax,得到注意力权重
# attn: (batch_size,num_heads ,seq_len ,seq_len )
attn = torch.softmax(attn,dim=-1)
# 用注意力权重乘以 V 向量,得到注意力输出向量
# x: (batch_size,num_heads ,seq_len ,head_dim )
x = torch.matmul(attn,v)
# 变换维度并拼接多头
# x: (batch_size ,seq_len ,hidden_size )
x = x.transpose(1 ,2).contiguous().view(batch_size ,seq_len ,-1)
# x: (batch_size ,seq_len ,hidden_size )
# 对注意力输出向量做一个线性变换,得到最终的输出
# x: (batch_size ,seq_len ,hidden_size )
x = self.out(x)
# 返回输出和注意力权重
return x, attn
```