从微信公众号及百度文章来看,全文检索的前置工作是分词,首先将要做全文检索的内容分词,然后采用全文检索模块或工具进行全文检索。参考文献4介绍了基于Lucene.net实现全文检索的大致思路,其采用的是Lucene.net+盘古分词的方式实现。参考文献5-6中介绍了近些年常用的.net的中文分词组件,准备从中选几个进行使用测试。本文就先以盘古分词为例测试及分词功能的基本用法。
Lucene.Net.Analysis.PanGu是盘古分词的.netcore升级版(参考文献1,其实也有不少年头了,GitHub最后更新时间都是七年前了),由于老版本不支持最新Lucene.Net 3.0.3,对其进行了升级,可以支持最新的Lucene.Net 3.0.3。可以直接NuGet安装。另外把词库打包到dll文件里面了,无需拷贝词库。
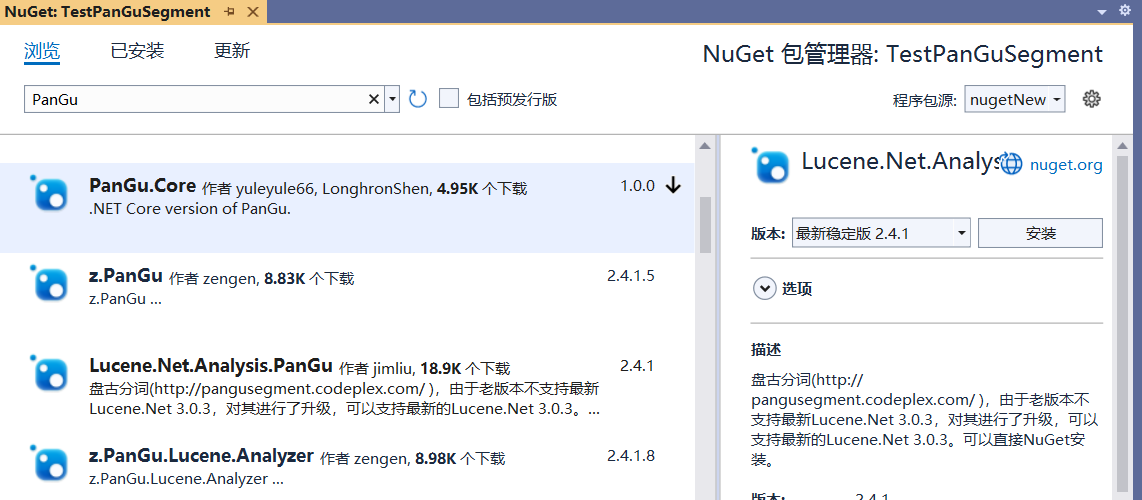
新建项目,在NuGet包管理器中搜索并找到Lucene.Net.Analysis.PanGu包,可以看到NuGet服务器中与PanGu相关的包还是不少。
Lucene.Net.Analysis.PanGu包中最重要的类是Lucene.Net.Analysis.PanGu命名空间中的PanGuAnalyzer类,该类用于根据输入的字符串或文本流返回分词集合,也即TokenStream对象。

PanGuAnalyzer类既可以直接读取字符串进行分词,也可以读取本地文件分词(其实都是转成TextReader类的实例),下面是直接读取字符串分词的示例及结果(示例代码参考自参考文献2-3)。
Analyzer analyzer = new PanGuAnalyzer();
TokenStream tokenStream = analyzer.TokenStream("", new StringReader("白日依山尽,黄河入海流。欲穷千里目,更上一层楼。"));
ITermAttribute ita = null;
bool hasNext = tokenStream.IncrementToken();
while (hasNext)
{
ita = tokenStream.GetAttribute<ITermAttribute>();
txtResult.Text += ita.Term + "/";
hasNext = tokenStream.IncrementToken();
}

然后是读取本地文件的,从网易新闻上找了一段话存到文本文件中,然后读取后分词,下面是示例及结果。
txtResult.Text = String.Empty;
using (TextReader tr = File.OpenText(txtPath.Text))
{
Analyzer analyzer = new PanGuAnalyzer();
TokenStream tokenStream = analyzer.TokenStream("", tr);
ITermAttribute ita = null;
bool hasNext = tokenStream.IncrementToken();
while (hasNext)
{
ita = tokenStream.GetAttribute<ITermAttribute>();
txtResult.Text += ita.Term + "/";
hasNext = tokenStream.IncrementToken();
}
}
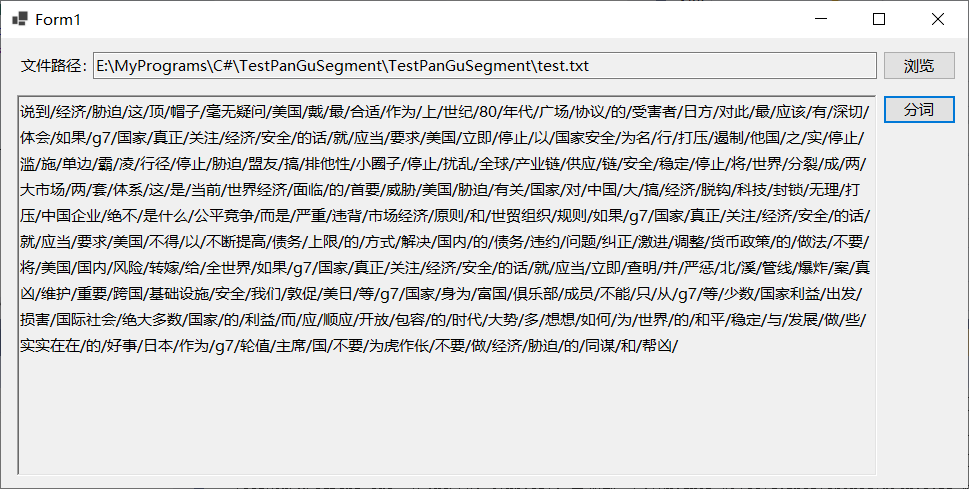
测试过程中发现的问题包括:1)文本文件的编码格式应为UTF-8或者Unicode,ANSI格式的文本文件读出来分词时是乱码;2)文本文件内容多了的话会卡死(试了几M及几十K的文本文件),可能是程序太简单,很多设置没有配置的原因,后续准备再继续学习Lucene.Net.Analysis.PanGu的用法。
参考文献:
[1]https://github.com/JimLiu/Lucene.Net.Analysis.PanGu
[2]https://www.cnblogs.com/zhang1f/p/14330506.html
[3]https://blog.csdn.net/m0_37554403/article/details/105684181
[4]https://blog.csdn.net/sd7o95o/article/details/119121420
[5]https://www.jianshu.com/p/6f47b670fcb0
[6]https://blog.51cto.com/u_15834522/5766716