动动发财的小手,点个赞吧!
简介
多亏了 GIL,使用多个线程来执行 CPU 密集型任务从来都不是一种选择。随着多核 CPU 的普及,Python 提供了一种多处理解决方案来执行 CPU 密集型任务。但是直到现在,直接使用多进程相关的API还是存在一些问题。
在本文[1]开始之前,我们还有一小段代码来帮助演示:
import time
from multiprocessing import Process
def sum_to_num(final_num: int) -> int:
start = time.monotonic()
result = 0
for i in range(0, final_num+1, 1):
result += i
print(f"The method with {final_num} completed in {time.monotonic() - start:.2f} second(s).")
return result
该方法接受一个参数并从 0 开始累加到该参数。打印方法执行时间并返回结果。
多进程存在的问题
def main():
# We initialize the two processes with two parameters, from largest to smallest
process_a = Process(target=sum_to_num, args=(200_000_000,))
process_b = Process(target=sum_to_num, args=(50_000_000,))
# And then let them start executing
process_a.start()
process_b.start()
# Note that the join method is blocking and gets results sequentially
start_a = time.monotonic()
process_a.join()
print(f"Process_a completed in {time.monotonic() - start_a:.2f} seconds")
# Because when we wait process_a for join. The process_b has joined already.
# so the time counter is 0 seconds.
start_b = time.monotonic()
process_b.join()
print(f"Process_b completed in {time.monotonic() - start_b:.2f} seconds")
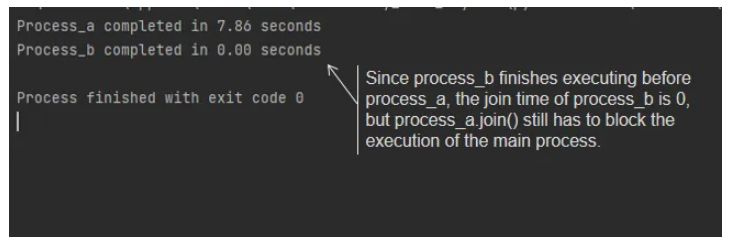
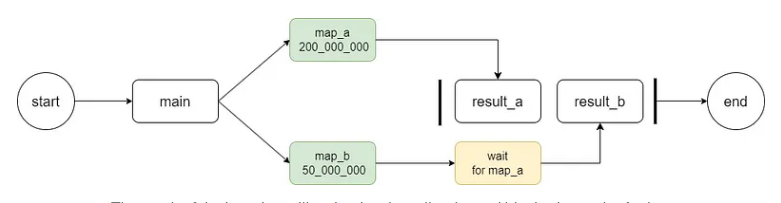
如代码所示,我们直接创建并启动多个进程,调用每个进程的start和join方法。但是,这里存在一些问题:
-
join 方法不能返回任务执行的结果。 -
join 方法阻塞主进程并按顺序执行它。
即使后面的任务比前面的任务执行得更快,如下图所示:
使用池的问题
如果我们使用multiprocessing.Pool,也会存在一些问题:
def main():
with Pool() as pool:
result_a = pool.apply(sum_to_num, args=(200_000_000,))
result_b = pool.apply(sum_to_num, args=(50_000_000,))
print(f"sum_to_num with 200_000_000 got a result of {result_a}.")
print(f"sum_to_num with 50_000_000 got a result of {result_b}.")
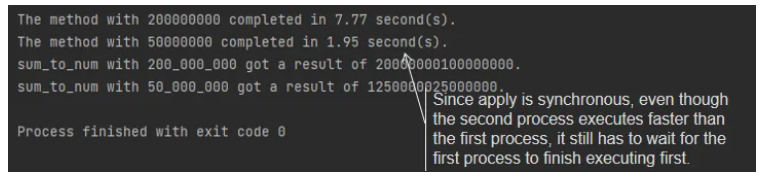
如代码所示,Pool 的 apply 方法是同步的,这意味着您必须等待之前的 apply 任务完成才能开始执行下一个 apply 任务。
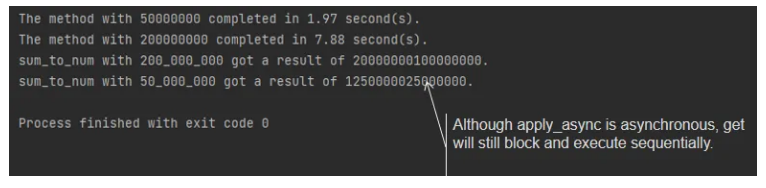
当然,我们可以使用 apply_async 方法异步创建任务。但是同样,您需要使用 get 方法来阻塞地获取结果。它让我们回到 join 方法的问题:
def main():
with Pool() as pool:
result_a = pool.apply_async(sum_to_num, args=(200_000_000,))
result_b = pool.apply_async(sum_to_num, args=(50_000_000,))
print(f"sum_to_num with 200_000_000 got a result of {result_a.get()}.")
print(f"sum_to_num with 50_000_000 got a result of {result_b.get()}.")
直接使用ProcessPoolExecutor的问题
那么,如果我们使用 concurrent.futures.ProcesssPoolExecutor 来执行我们的 CPU 绑定任务呢?
def main():
with ProcessPoolExecutor() as executor:
numbers = [200_000_000, 50_000_000]
for result in executor.map(sum_to_num, numbers):
print(f"sum_to_num got a result which is {result}.")
如代码所示,一切看起来都很棒,并且就像 asyncio.as_completed 一样被调用。但是看看结果;它们仍按启动顺序获取。这与 asyncio.as_completed 完全不同,后者按照执行顺序获取结果:
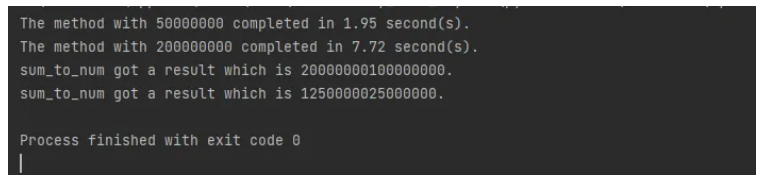
使用 asyncio 的 run_in_executor 修复
幸运的是,我们可以使用 asyncio 来处理 IO-bound 任务,它的 run_in_executor 方法可以像 asyncio 一样调用多进程任务。不仅统一了并发和并行的API,还解决了我们上面遇到的各种问题:
async def main():
loop = asyncio.get_running_loop()
tasks = []
with ProcessPoolExecutor() as executor:
for number in [200_000_000, 50_000_000]:
tasks.append(loop.run_in_executor(executor, sum_to_num, number))
# Or we can just use the method asyncio.gather(*tasks)
for done in asyncio.as_completed(tasks):
result = await done
print(f"sum_to_num got a result which is {result}")
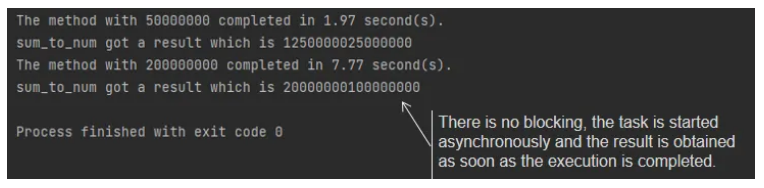
由于上一篇的示例代码都是模拟我们应该调用的并发过程的方法,所以很多读者在学习之后在实际编码中还是需要帮助理解如何使用。所以在了解了为什么我们需要在asyncio中执行CPU-bound并行任务之后,今天我们将通过一个真实世界的例子来解释如何使用asyncio同时处理IO-bound和CPU-bound任务,并领略asyncio对我们的效率代码。
Reference
Source: https://towardsdatascience.com/combining-multiprocessing-and-asyncio-in-python-for-performance-boosts-15496ffe96b
本文由 mdnice 多平台发布