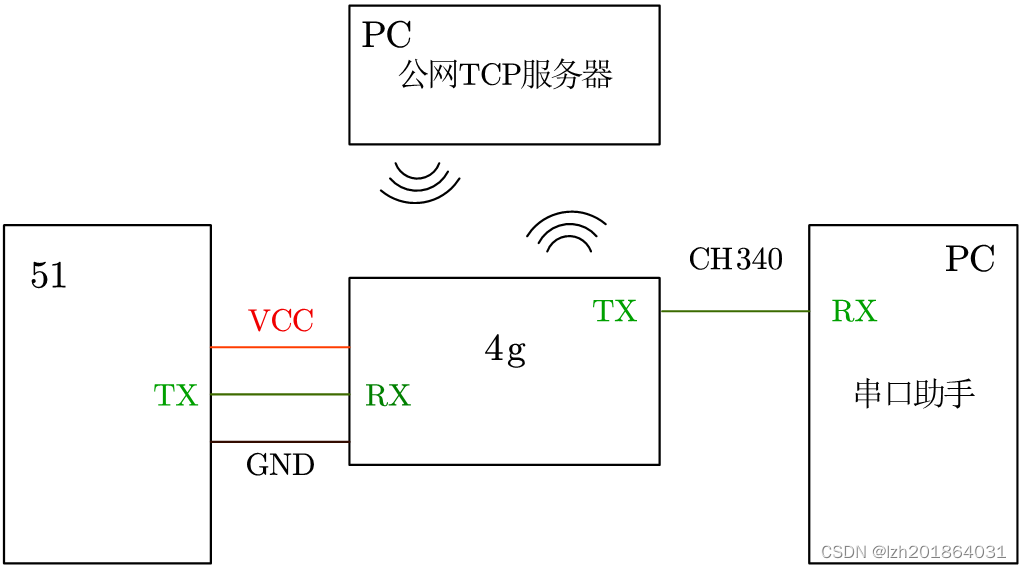
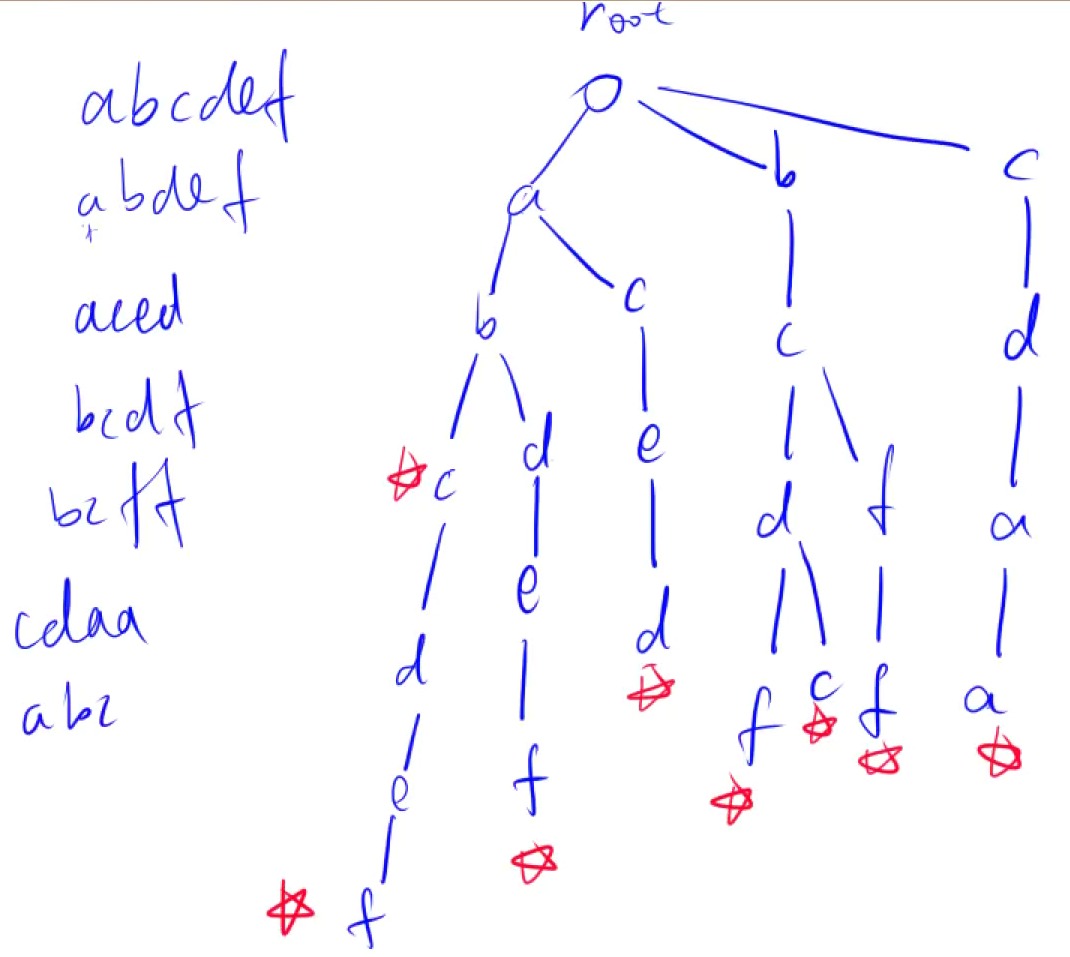
目录标题
- 为什么会有继承
- 继承的概念
- 继承的定义
- 基类和派生类对象赋值转换
- 继承中的作用域
- 派生类的默认成员函数
- 继承和友元
- 继承与静态成员
- 什么是菱形继承
- 如何解决菱形继承
- 解决的底层原理
- 继承和组合
为什么会有继承
在平时的使用过程中通常会出现一部分数据会在很多其他地方被使用,比如说person这个类专门用来描述人员,那么这个类中就会有这个人的姓名性别和省份证号,比如说下面的代码:
class person
{
public:
person(const char* _name,
const char* _sexual,
const char* _id)
:name(_name)
,sexual(_sexual)
,id(_id)
{}
void print_name() { cout << name << endl; }
void print_sexual() { cout << sexual << endl; }
void print_id() { cout << id << endl; }
private:
string name;
string sexual;
string id;
};
我们就可以使用这个类来记录一些数据并打印,比如说下面的测试代码
int main()
{
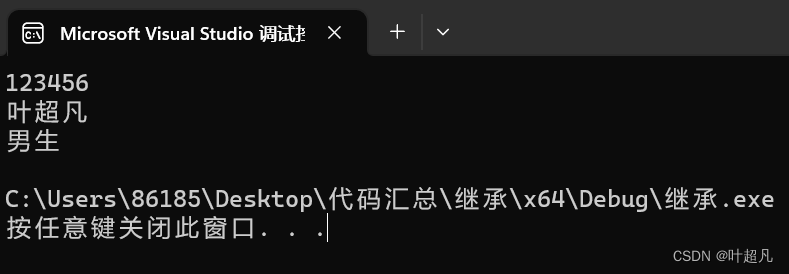
person p1("叶超凡", "男生", "123456");
p1.print_id();
p1.print_name();
p1.print_sexual();
return 0;
}
这段代码运行的结果如下:
但是在平时的使用过程中,我们还会创建很多其他的类比如说student专门用来描述学生,teacher专门用来描述教师,这里的代码就如下:
class student
{
public:
student(const char* _name,
const char* _sexual,
const char* _id,
const char* _grade)
:name(_name)
, sexual(_sexual)
, id(_id)
,grade(_grade)
{}
void print_name() { cout << name << endl; }
void print_sexual() { cout << sexual << endl; }
void print_id() { cout << id << endl; }
void print_grade() { cout << grade << endl; }
private:
string name;
string sexual;
string id;
string grade;
};
class teacher
{
public:
teacher(const char* _name,
const char* _sexual,
const char* _id,
const char* _subjects)
:name(_name)
, sexual(_sexual)
, id(_id)
, subjects(_subjects)
{}
void print_name() { cout << name << endl; }
void print_sexual() { cout << sexual << endl; }
void print_id() { cout << id << endl; }
void subjects_id() { cout << subjects << endl; }
private:
string name;
string sexual;
string id;
string subjects;
};
从整体上看这两个类是不一样的,但是仔细观察一下就会发现这两个类中都有person这个类中的全部数据,那么这里就会存在一个问题,既然我们实现了一个person类而student类和teacher类中又有person类中的数据,那我们在实现这两个类的时候是不是会干很多和person类相同的事情啊,所以为了解决这个问题就有了继承这个东西,他可以帮我们节省节省很多相同的事情。
继承的概念
继承机制是面向对象程序设计使代码可复用的重要手段,它允许程序员在保持原有类的基础上进行扩展,增加功能,这样产生新的类,称为派生类。继承呈现了面向对象程序设计的层次结构,提现了由简单到复杂的认知过程。以前我们接触的复用都是函数复用比如说:在实现排序算法的时候经常将两个位置上的元素数据进行转换,使得数据的顺序可以更加的有序,交换两个元素的代码都是一样的,所以我们可以把这个代码放到一个函数里面,在得用到交换两个函数的时候直接调用这个函数就可以了那么这就是函数的复用,继承是类设计层次的复用,这里就可以简单的举一个例子,上面的teacher类和student类中有person类中的数据,那么在创建这两个类的时候可以直接使用继承来节省创建类时的工作量,比如说下面的代码就采用的是继承的方法来创建类:
class teacher:public person
{
public:
teacher(const char* _name,
const char* _sexual,
const char* _id,
const char* _subjects)
:person(_name,_sexual,_id)
,subject(_subjects)
{}
void print_subject() {cout << subject << endl;}
private:
string subject;
};
class student :public person
{
public:
student(const char* _name,
const char* _sexual,
const char* _id,
const char* _grade)
:person(_name,_sexual,_id)
,grade(_grade)
{}
void print_grade() {cout << grade << endl;}
private:
string grade;
};
虽然这里省略很多的内容,但是因为继承了person类,所以person类中的函数和数据都是存在的,比如说下面的测试代码:
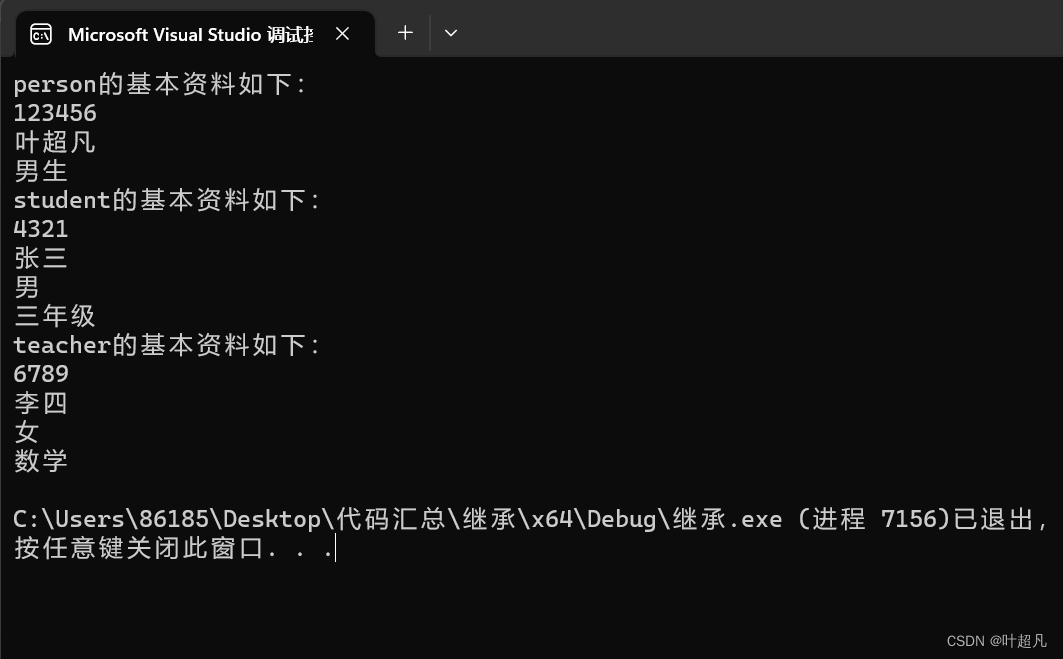
int main()
{
person p1("叶超凡", "男生", "123456");
cout << "person的基本资料如下:" << endl;
p1.print_id();
p1.print_name();
p1.print_sexual();
student s1("张三", "男", "4321", "三年级");
cout << "student的基本资料如下:" << endl;
s1.print_id();
s1.print_name();
s1.print_sexual();
s1.print_grade();
teacher t1("李四", "女", "6789", "数学");
cout << "teacher的基本资料如下:" << endl;
t1.print_id();
t1.print_name();
t1.print_sexual();
t1.print_subject();
return 0;
}
这段代码的运行结果如下:
通过上面的例子可以看到使用继承的方式创建类可以节省很多重复的操作,那么接下来我们就来看看如何使用继承创建类。
继承的定义
继承定义的格式如下:
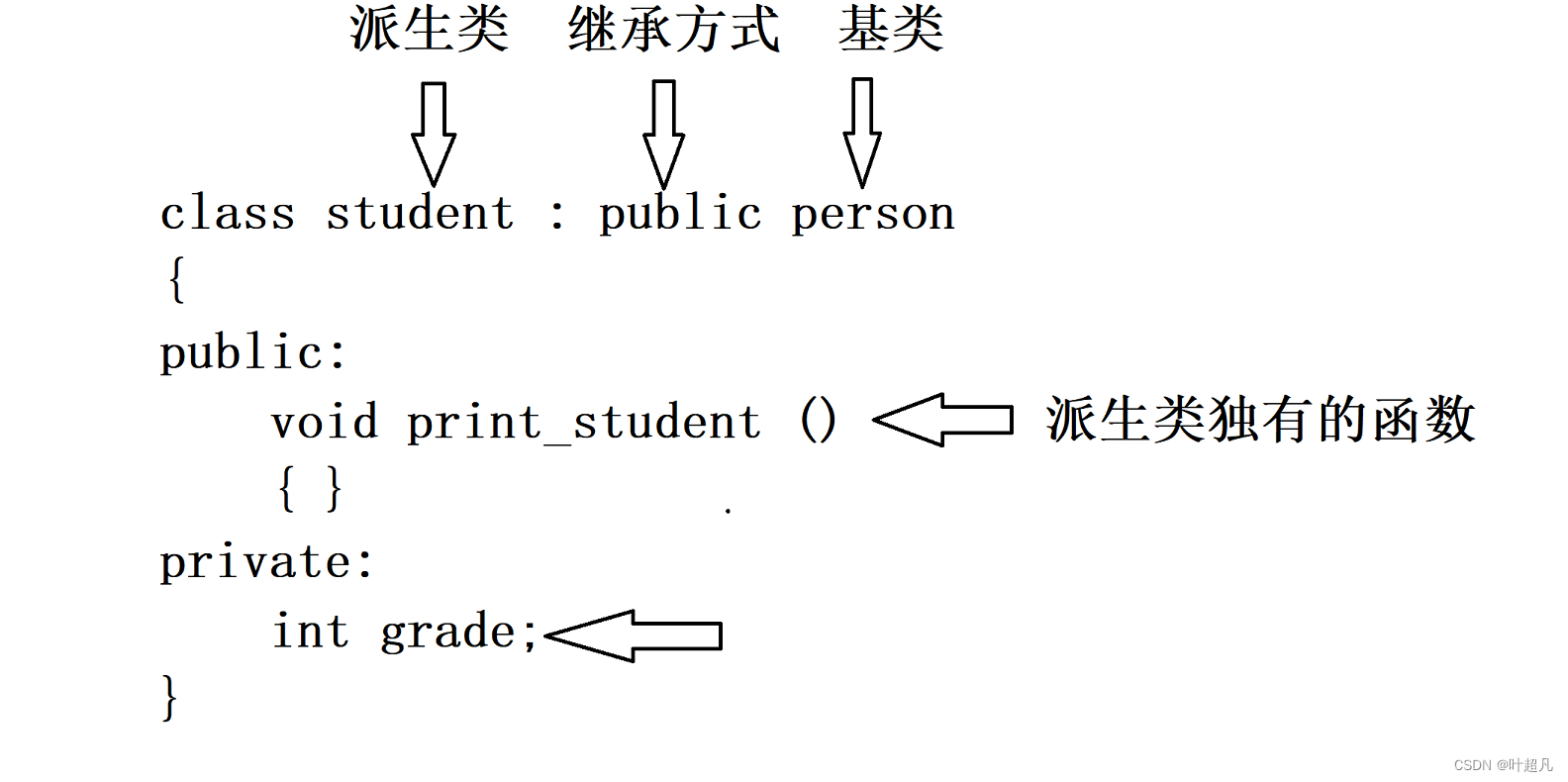
新生成的类称为派生类也可以称为子类 ,冒号后面的称为继承的方式 最后就是被继承的类这个通常称为基类也可以称为父类,类中有三个不同类型的数据分别为public protect private 而继承的方式又有三中也分别为public protect private,所以在继承的时候不同的数据和函数就会出现面临9种不同的情况,比如说基类的数据是public类型而继承的方式是protect继承,那新生成的子类中原来的父类数据是什么类型呢?那这里就可以看看下面的表格:
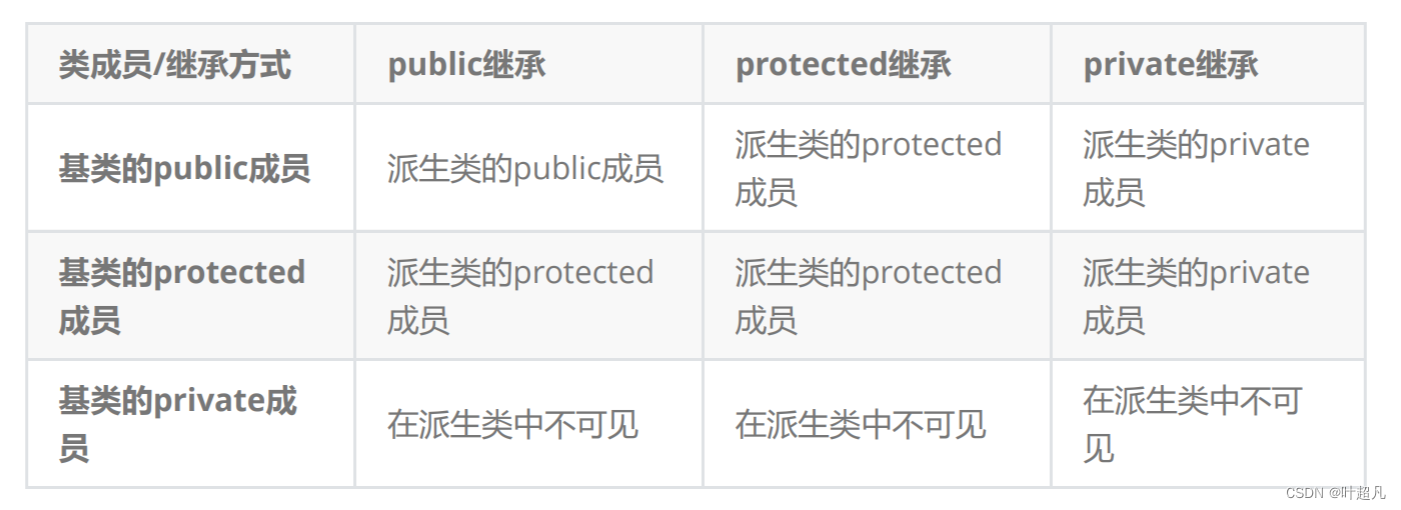
对于这9种情况我们可以做一个总结:
第一点:
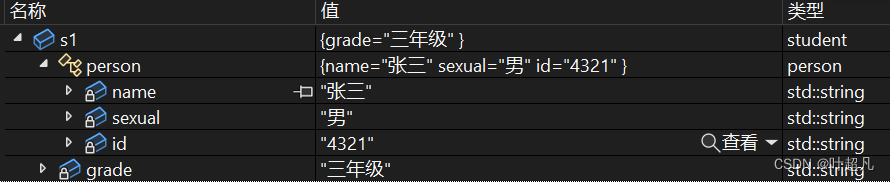
基类private成员在派生类中无论以什么样的方式继承都是不可见的。这里的不可见是指基类的私有成员还是被继承到了派生类对象中,但是语法上限制了派生类对象不管在类里面还是类外面都不能去访问到基类的私有数据,比如说上面的子类student,它继承了父类person,但是通过调试我们还是可以看到student创建出来的对象s1含有父类的内容
第二点:
基类private成员在派生类中是不能被访问的,如果基类成员不想在类外直接被访问,但需要在派生类中能够被访问那么就定义为Protected,可以看出保护成员限定符是应继承才出现的,比如说下面的操作父类的三个变量全部都被protect修饰:
class person
{
public:
person(const char* _name,
const char* _sexual,
const char* _id)
:name(_name)
,sexual(_sexual)
,id(_id)
{}
void print_name() { cout << name << endl; }
void print_sexual() { cout << sexual << endl; }
void print_id() { cout << id << endl; }
protected:
string name;
string sexual;
string id;
};
因为这三个变量被protected限定符修饰,所以在子类里面就可以使用这三个变量来做一些其他事情,比如说给子类的变量进行赋值等等,比如说下面的代码:
class student :public person
{
public:
student()
:person("张三","男","123")
{}
void tmp_func()
{
tmp = name;
cout << tmp << endl;
}
private:
string tmp;
};
这里直接使用了父类的protected限定符修饰的变量来给子类的tmp变量进行赋值,然后就可以使用下面的代码来进行一下测试:
int main()
{
student s1;
s1.tmp_func();
return 0;
}
这段代码的运行结果如下:
可以看到这里确实将父类的数据赋值给了子类,那我们能不能在子类或者父类的外面使用protected修饰的数据呢?那这里就可以看看下面的测试代码
int main()
{
student s1;
person p1;
cout << s1.name << endl;
cout << s1.id << endl;
cout << s1.sexual<< endl;
cout << p1.name << endl;
cout << p1.id << endl;
cout << p1.sexual << endl;
return 0;
}
这段代码的运行结果如下:
运行的结果是完全运行不下去,因为protected修饰的成员只能在子类种被访问其他地方是没有权限访问的。
第三点:
将上面的表格进行一下总结会发现基类的私有成员在子类都是不可见的,基类的其他成员在子类的访问方式==min(成员在基类的访问限定符,继承方式),public>protected>private。成员的权限和继承的权限谁的权限小那么子类数据的权限就是谁,比如说父类的数据name的权限是public但是采用的protected继承,那么name在子类的权限就变成了protected,如果name的权限是private即使采用public继承但是在子类里面name的权限依然是private。
第四点:
继承的的时候可以不写继承方式,这样的话如果子类是class的话就是私有继承,如果子类是struct的话就是公有继承。但是大家在使用的过程种最好还是写上继承的方法,比如说子类是采用class来实现的,所以当我们继承父类不添加继承方法时,我们可以发现是无法使用父类中被public限定符修饰的函数或者数据的,比如说下面的代码:
class student : person
{
public:
student()
:person("张三","男","123")
{}
void tmp_func()
{
tmp = name;
cout << tmp << endl;
}
private:
string tmp;
};
在main函数里面我们无法使用子类中的父类任何内容,因为这里是class所以默认采用私有继承:
int main()
{
student s1;
s1.print_name();
s1.print_sexual();
s1.print_id();
s1.tmp_func();
return 0;
}
这段代码肯定是运行不了的并且会爆出一堆错误:
但是我们将子类中的class修改成struct的话就可以发现这里的错误全部都消失了,可以正常的使用父类中的函数:
那么这就是继承方法省略的情况,但是大家最好还是别省略。
第五点:
在实际运行中,一般使用都是public继承,几乎很少使用provide和protect 继承,也不提倡使用proctetced/private继承,因为protetced/private继承下来的成员都只能在派生类的类里面使用,实际中扩展的维护性不强。
基类和派生类对象赋值转换
派生类对象可以赋值给基类对象,基类指针,基类引用,这里有个形象的说法叫做切片或者切割。寓意把派生类中父类那部分切来赋值给子类,比如说下面的操作:
class student :public person
{
public:
student(const char* _name="张三",
const char* _sexual="男",
const char* _id="12345",
const char* _grade="三年级")
:person(_name,_sexual,_id)
,grade(_grade)
{}
void print_grade()
{
cout << grade << endl;
}
private:
string grade;
};
子类student继承了父类person,那么我们通过子类创建出来的对象是可以赋值给父类对象,父类指针或者引用的,比如说下面的操作:
int main()
{
student s1;
person p1("李四", "女", "6789");
p1 = s1;
person* p2=nullptr;
p2 = &s1;
person& p3 = s1;
return 0;
}
将这段代码运行一下是没有报任何问题的:
并且我们对上面测试的代码进行一下修改,让其调用一下函数可以发现夫类型的变量,指针,引用都可以调用父类中的内容比如说下面的代码:
int main()
{
student s1;
person p1("李四", "女", "6789");
p1 = s1;
person* p2=nullptr;
p2 = &s1;
person& p3 = s1;
cout << "父类的内容为:" << endl;
p1.print_id();
p2->print_name();
p3.print_sexual();
cout << "子类中父类的内容为:" << endl;
s1.print_id();
s1.print_name();
s1.print_sexual();
return 0;
}
这段代码的运行结果如下:
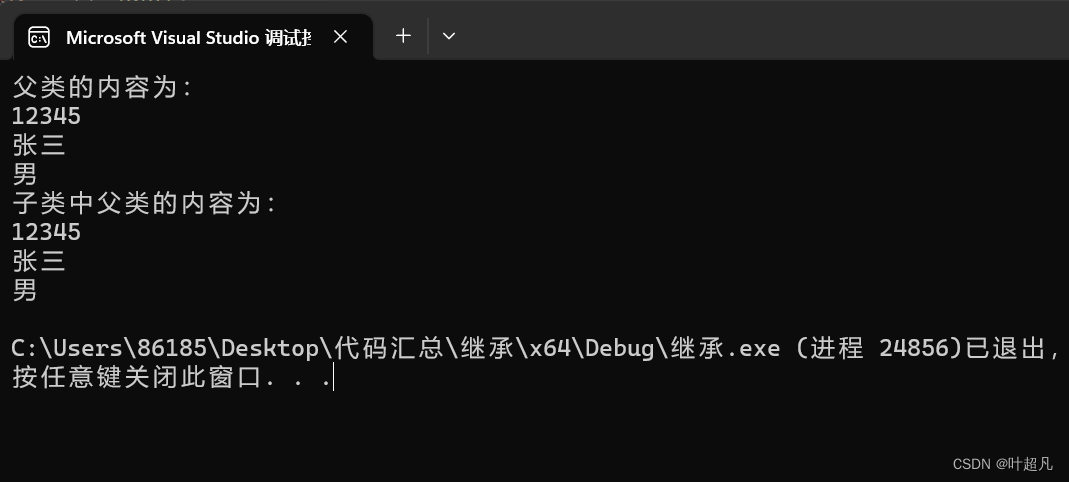
可以看到虽然通过将子类赋值给了父类,但是内部的内容还是一样的和,之所以可以这样是因为子类在继承父类的时候将父类的所有内容全部都继承下来了,虽然父类private修饰的成员无法在子类中被访问,但是子类中依然有这些成员的数据,所以可以将子类赋值给父类的对象,指针和引用,我们来看看下面的这张图片:
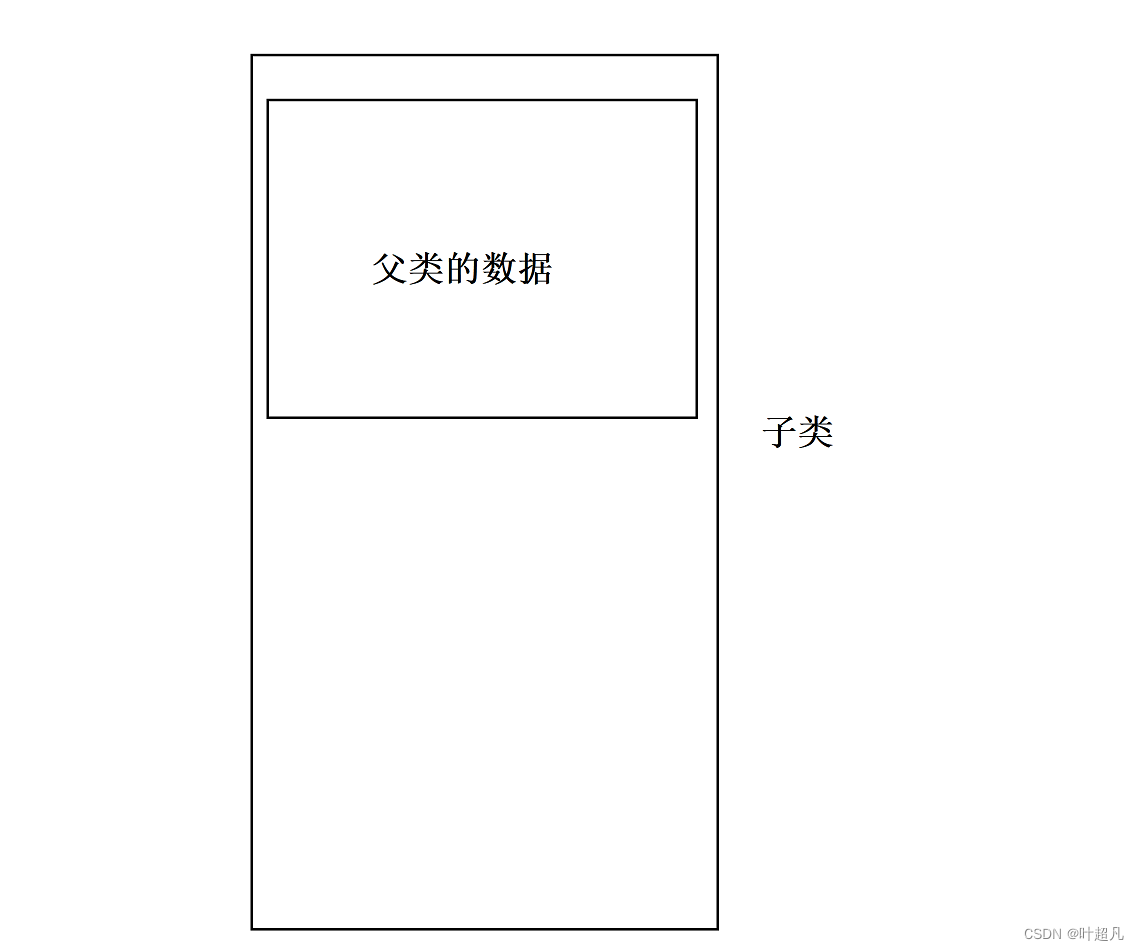
当将子类赋值给父类的指针时,父类的指针实际上保存的是子类中父类的地址,将子类赋值给父类的引用时,那个引用实际上就是子类中父类的数据的别名,这里希望大家能够理解,子类可以赋值给父类,但是不能将父类的对象赋值给子类对象,子类的指针,子类的引用。比如说下面的代码:
int main()
{
person p1("李四", "女", "6789");
student s1;
s1 = p1;
student* s2;
s2 = &p1;
student& s3 = p1;
return 0;
}
上面这段代码是无法运行成功的,爆出的错误如下:
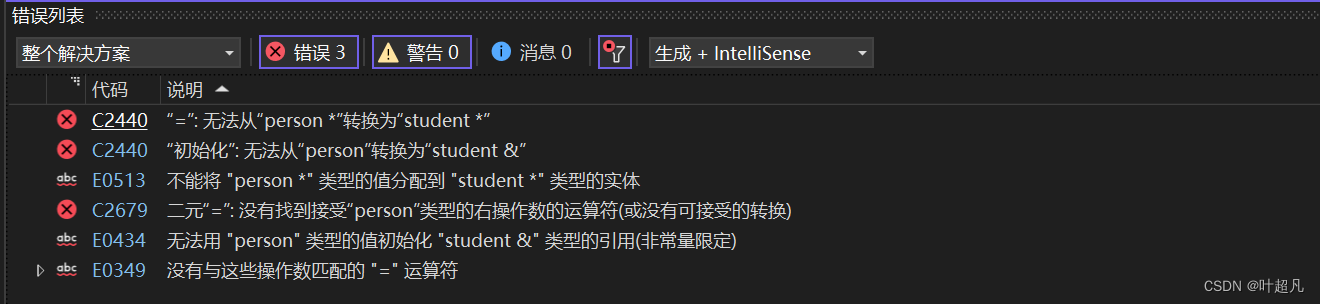
父类无法赋值给子类的原因也很简单,子类中含有父类的数据,但是父类中不会含有子类的数据,所以无法赋值这里大家要注意一下。在将子类的对象赋值给父类的时候不存在类型转换而是直接切片并赋值,这也就意味着中间不会产生临时对象。大家可以看看下面这张图片:
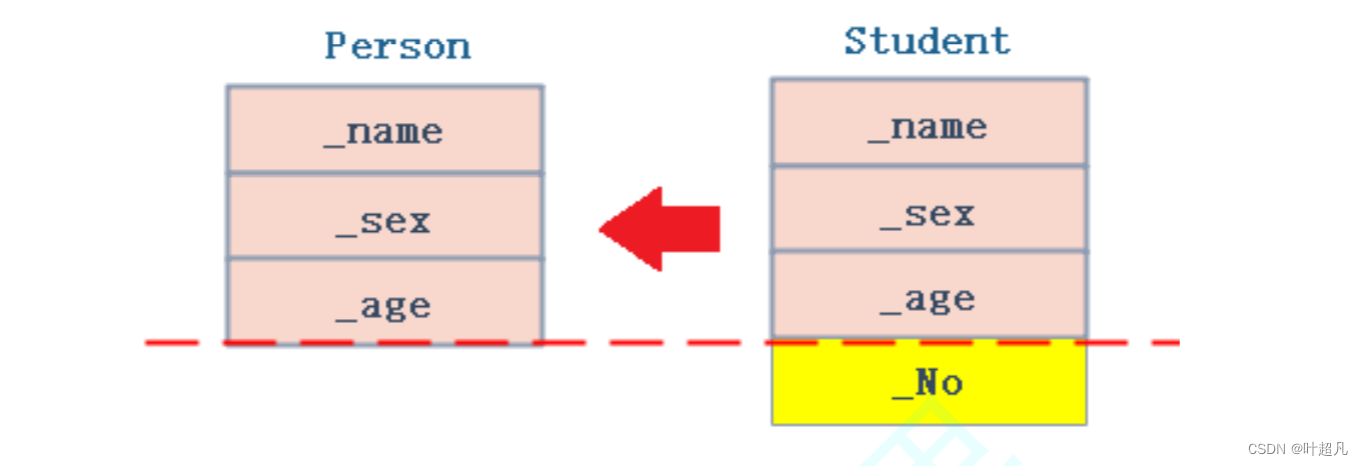
那我们如何来验证这一个现象呢?我们说两个不同的对象在赋值的时候会产生临时对象,比如说将一个double类型的变量赋值给一个int类型的变量的时候就会产生临时变量,因为在赋值的时候并不是将double数据本身变成整型然后进行赋值,而是创建一个临时变量该变量里面存放的是double变量变成整型后的数据,然后将临时变量的值赋值整型变量,而临时变量具有常性,所以在不同类型进行引用的时候得加上const,比如说下面的代码:
int main()
{
double x = 3.14;
int& y = x;
cout << y << endl;
return 0;
}
由于这里两个变量的类型不一样,所以在赋值的时候会产生临时变量,这里y是x的别名,但是y和x的类型不同所以y是临时变量的别名,因为临时变量具有常性,而这里的引用没有加const所以就会报错:

加上const就能正常运行:
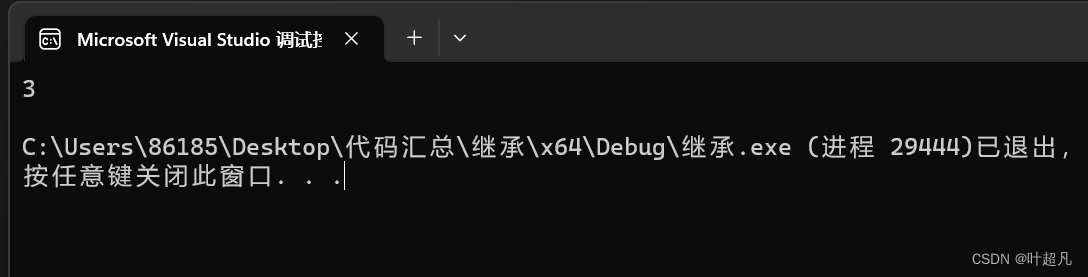
但是我们使用父类的引用给子类取别名的时候即使不加const也可以正常的运行,比如说下面的代码:
int main()
{
student s1;
person& p1 = s1;
return 0;
}
那么这就说明将子类赋值给子类的时候没有发生类型转换而是直接切片赋值。基类的指针或者引用可以通过强制类型转换赋值给派生类的指针或者引用。但是必须是基类的指针是指向派生类对象时才是安全的。这里基类如果是多态类型的话,可以使用RTTI来进行识别后进行安全转换。这里我们后面再进行讲解。
继承中的作用域
当子类和父类都有相同的成员时,不加指定作用域默认访问的是子类的成员比如说下面的测试代码:
class A
{
public:
A(const int& x=10)
:a(x)
{}
int a;
};
class B :public A
{
public:
B(const int &x)
:a(x)
{}
int a;
};
A是父类,B是子类,但是父类和子类中却含有同名的变量,所以我们就可以使用下面的代码来测试一下
int main()
{
B tmp(20);
cout << tmp.a << endl;
return 0;
}
代码的运行结果如下:
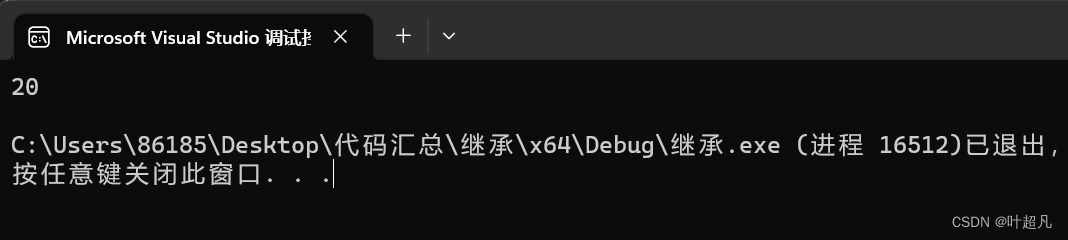
如果我们想访问父类的变量A的话就得加上指定的作用域比如说下面的代码:
int main()
{
B tmp(20);
cout << tmp.A::a << endl;
return 0;
}
这样的话打印的结果就是父类的变量a的值。当父子类有同名的成员变量时子类对象默认访问的是子类的变量,那父类和子类有同名的成员函数时,子类对象也是默认访问子类的成员函数,比如说下面的父子类中就有个同名的成员函数:
class c
{
public:
void func() {cout << "我是父类的函数" << endl;}
};
class d : public c
{
public:
void func() { cout << "我是子类的函数" << endl; }
};
父子类有同名的成员函数,但是这两个函数打印的内容却不相同,所以我们就可以用下面的代码来进行测试
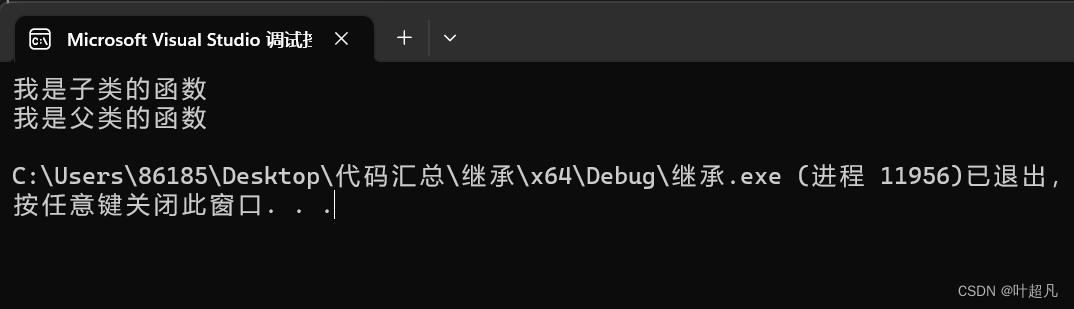
int main()
{
d tmp;
tmp.func();
tmp.c::func();
return 0;
}
这段代码运行的结果如下:
在继承体系中基类和派生类都有独立的作用域,子类和父类中有同名成员时,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫做隐藏,也叫重定义。但是在子类成员函数中,可以使用基类::基类成员来显示访问。当子类和父类有同名的成员函数的时候不会构成重载,因为重载得有相同的作用域,但是子类和父类不是相同的作用域,所以不构成重载,这里叫做隐藏。这里需要注意的一点就是如果是成员函数的隐藏,只需要函数名相同就能构成隐藏,比如说下面的代码:
class C
{
public:
int func(int x)
{
cout << "我是父类的函数,我只接收一个参数,参数值为:" << x << endl;
return x;
}
private:
};
class D:public C
{
public:
void func(int x,int y)
{
cout << "我是子类的函数,我接收两个参数,参数值为:" << x<<" " << y << endl;
}
private:
};
父子类都有名为func的函数,虽然这两个函数的参数不同返回值也不同,但是这两个函数依然构成隐藏,但是隐藏可能会带来一些问题比如说父类和子类的参数不同,但是函数名相同的话,在外面不指定作用域来调用父类的函数的话就会报错,比如说下面的代码:
int main()
{
D tmp;
tmp.func(10);
return 0;
}
这里只传了一个参数所以这段代码的目的就是调用父类的函数,但由于父类和子类的func函数构成隐藏的关系,这里没有指定作用域,所以上面这段代码是会报错的:

那么这就是隐藏所带来的一个问题希望大家能够理解。所以大家在继承体系里面最好不用唉定义同名的成员
派生类的默认成员函数
构造函数
如果基类中含有默认构造函数的话,在派生类的初始化列表中会自动的调用父类的默认构造来帮助自己初始化父类的成员。比如说下面的代码:
class A
{
public:
A()
{
cout << "调用了父类的构造函数" << endl;
}
};
class B:public A
{
public:
B(const int& x)
:b(x)
{
cout << "调用了子类的构造函数" << endl;
}
int b;
};
使用下面的代码就可以看到子类在初始化的时候自动调用了父类的构造函数来初始化子类中的父类数据
int main()
{
B tmp(10);
return 0;
}
这段代码的运行结果如下:
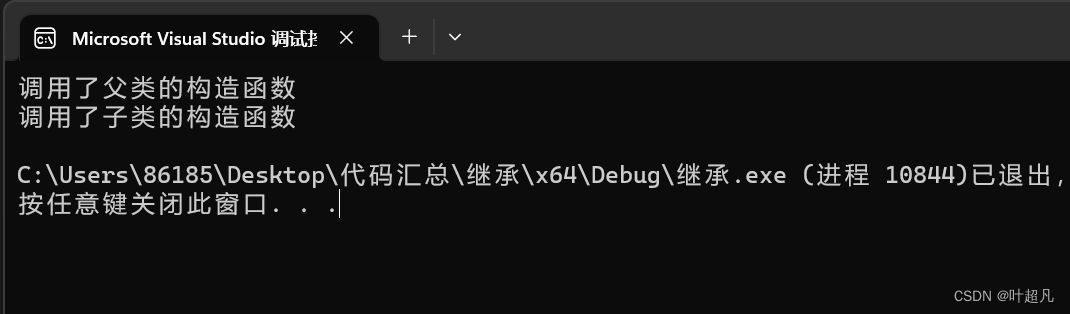
因为构造函数函数体中只有一段打印语句,所以可以推断出在子类的构造函数的初始化列表中调用的父类的构造函数,如果父类没有默认构造函数只有需要传参的构造函数的话我们得在子类的初始化列表里面调用父类的构造函数,并且不能在初始化列表里面单独的初始化父类成员的一部分,而是得把父类当成一个整体来调用其构造函数,我们来看看下面的例子:
class A
{
public:
A(const int& x, const int& y)
:tmp1(x)
,tmp2(y)
{
}
int tmp1;
int tmp2;
};
class B:public A
{
public:
B(const int& x)
:b(x)
,A(10, 20)
,A::tmp1(10)
,A::tmp2(20)
{
cout << "调用了子类的构造函数" << endl;
}
int b;
};
这段代码的运行结果如下:
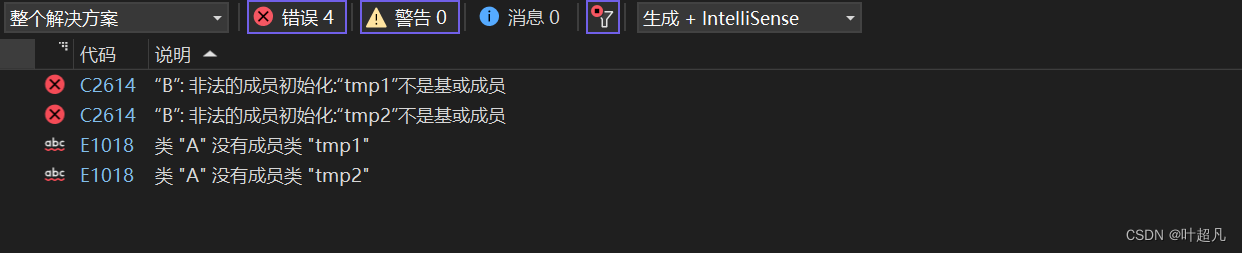
无法正常通过,所以不能在子类的初始化列表中初始化父类的成员变量,而是得将父类作为一个整体,调用其构造函数来进行初始化,比如说下面的代码:
class B:public A
{
public:
B(const int& x)
:b(x)
,A(10, 20)
{
cout << "调用了子类的构造函数" << endl;
}
int b;
};
这样就能正常的运行不会报错。
赋值重载和拷贝构造
派生类中实现赋值重载和拷贝构造的时候依然是通过调用父类的赋值重载和拷贝构造来进行实现,虽然子类的赋值重载和拷贝构造不会传来父类对象的参数,但是子类可以通过切断的方式来赋值给父类,所以这里依然可以调用父类的赋值重载或者拷贝构造来修改父类的数据,这里大家要注意的一点就是调用父类的成员函数的时得指定作用域,不指定的话会出现循环的情况,比如说下面的代码:
class Person
{
public:
Person(const char* name = "peter")
: _name(name)
{
cout << "Person()" << endl;
}
Person(const Person& p)
: _name(p._name)
{
cout << "Person(const Person& p)" << endl;
}
Person& operator=(const Person& p)
{
cout << "Person operator=(const Person& p)" << endl;
if (this != &p)
_name = p._name;
return *this;
}
void print()
{
cout << _name << endl;
}
protected:
string _name; // 姓名
};
class Student : public Person
{
public:
Student(const char* name, int num)
: Person(name)
, _num(num)
{
cout << "Student()" << endl;
}
Student(const Student& s)
: Person(s)
, _num(s._num)
{
cout << "Student(const Student& s)" << endl;
}
Student& operator = (const Student& s)
{
cout << "Student& operator= (const Student& s)" << endl;
if (this != &s)
{
Person::operator =(s);
_num = s._num;
}
return *this;
}
void print()
{
Person::print();
cout << _num << endl;
}
protected:
int _num; //学号
};
我们可以用下面的代码来进行一下子类的拷贝构造函数:
int main()
{
Student s1("叶超凡", 123);
Student s2(s1);
s2.print();
return 0;
}
这段代码的运行结果如下:
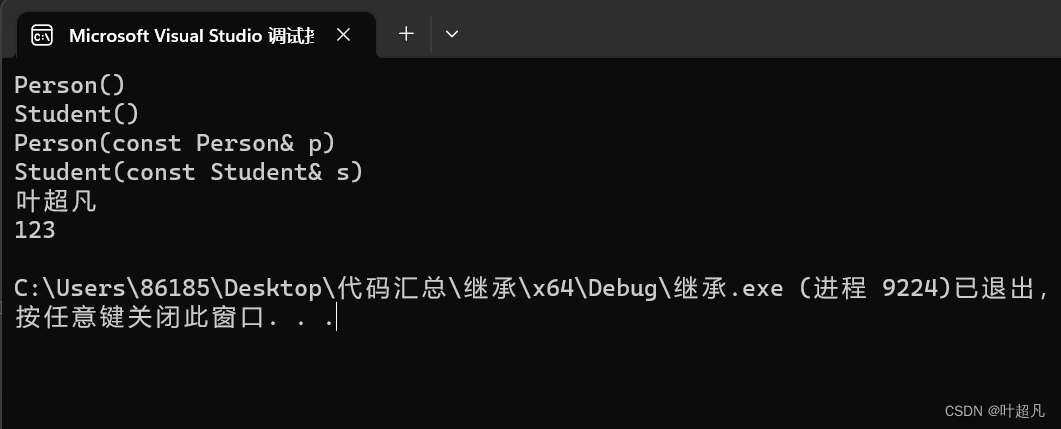
接下来这段代码就是测试赋值重载函数:
int main()
{
Student s1("叶超凡", 123);
Student s2("徐贝贝", 456);
s2.print();
s2 = s1;
s1.print();
return 0;
}
这段代码的运行结果如下:
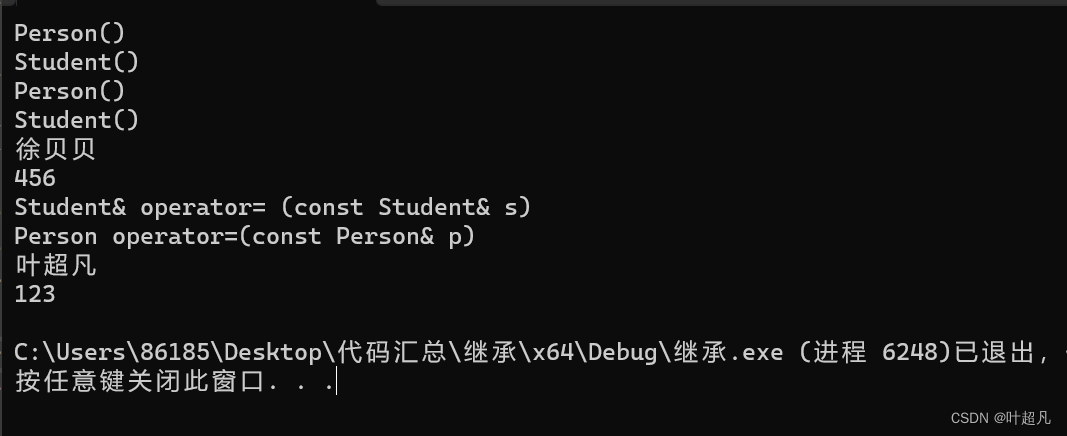
那么这就是子类的赋值重载函数和拷贝构造函数希望大家能够理解。
析构函数
在基类的析构函数结尾会自动的调用父类的析构函数来实现数据释放。比如说下面的代码:
class A
{
public:
~A()
{
cout << "A的析构函数" << endl;
}
private:
int x;
};
class B : public A
{
public:
~B()
{
cout << "B的析构函数" << endl;
}
};
我们这里没有在子类的析构函数里面调用父类的A的析构函数,但是通过下面的例子我们可以看到因为继承关系,这里自动调用了父类的析构函数:
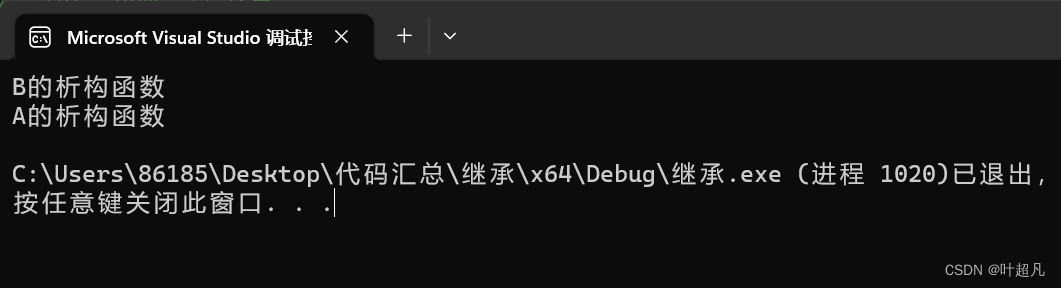
调用的顺序为先调用子类的析构函数再调用父类的析构函数。由于多态关系的需求所有析构函数都会进行特殊的处理将名字变为destructor,所以虽然父子类的析构函数名不相同但是他们依然会构成隐藏关系。 c++在创建对象的时候是先构造父类对象再构造子类对象,调用析构函数的时候是先调用子类的析构函数,再调用父类的析构函数,编译器之所以要自己调用析构函数来释放子类是因为他得保证函数调用的顺序(得子类的析构函数调用完了再调用父类的析构函数),如果我们自己调用析构函数的话无法保证先释放子类再释放父类,所以在实现子类的析构函数的时候不用手动的调用父类的析构函数,让编译器自己调用就可以了。
继承和友元
友元关系无法继承,也就是说父类的友元可以访问父类的私有和保护的数据,但是父类友元不能访问子类的私有和保护成员,比如说下面的代码:
class B;
class A
{
public:
friend void test_printf(const A & tmp1, const B & tmp2);
protected:
int a=10;
};
class B :public A
{
public:
private:
int b=20;
};
void test_printf(const A& tmp1, const B& tmp2)
{
cout << tmp1.a << endl;
cout << tmp2.b << endl;
}
int main()
{
A tmp1;
B tmp2;
test_printf(tmp1,tmp2);
return 0;
}
test_printf函数是类A的有元,但不是类B的有元,所以这段代码就无法正常的运行:

要想让test_print函数也是类B的有元的话就得再在类B中添加对应的声明函数,比如说下面的代码:
class B :public A
{
public:
friend void test_printf(const A& tmp1, const B& tmp2);
private:
int b=20;
};
这样就可以正常地运行。
继承与静态成员
我们都知道非静态成员在不同的类中是不同的,即使一个父类被多个不同的子类继承这些子类创建出来的对象也是不同份的,但是父类的静态成员在不同的子类确实是同一份的。父类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出来多少个子类都只有一个这样的静态对象,比如说下面的代码:
class A
{
public:
A()
{ sum++;}
static int sum;
private:
};
int A::sum = 0;
class B : public A
{
public:
private:
};
class C : public A
{
public:
private:
};
int main()
{
A a;
B b;
C c;
cout << "创建的对象的个数为:" << A::sum << endl;
A::sum = 0;
cout << "静态变量的值为:" << B::sum << endl;
return 0;
}
这段代码的运行结果如下:
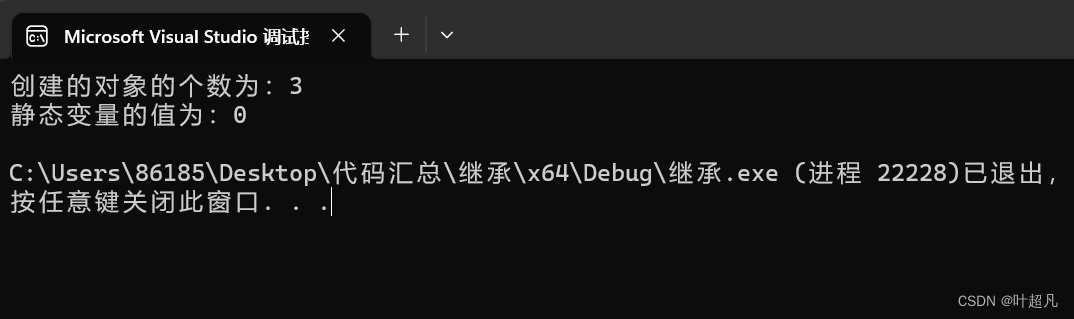
之所以出现这样的原因是因为非静态成员是存储着对象里面的,而静态成员是属于这个类的所有对象,同时也属于所有派生类及对象。
什么是菱形继承
单继承
一个子类只有一个直接父类时,称这个继承关系为单继承,比如说下面的代码:
class A
{
public:
int a=10;
string sa = "A类的字符串";
};
class B : public A
{
public:
int b=20;
string sb = "B类的字符串";
};
子类B只有一个父类A,所以我们把这样的继承称为单继承。
多继承
一个子类可以继承多个不同父类的数据,比如说下面的代码:
class A
{
public:
int a=10;
};
class B
{
public:
int b=20;
};
class C : public A ,public B
{
public:
int c=30;
private:
};
这里的子类c继承了多个不同父类的数据,所以我们把这样的继承称为多继承。
菱形继承
首先来看看下面的代码:
class A
{
public:
int a=10;
};
class B :public A
{
public:
int b=20;
};
class C : public A
{
public:
int c=30;
};
类B和类C都继承了A,所以类B和C中都有类A中的内容,一个类可以继承多个父类的资源,那我们这里再创建一个类D让其继承B C 会出现什么样的情况呢?比如说下面的代码:
class D :public B, public C
{
public:
int d=40;
};
D继承了B和C的内容,可是B和C中都有A的内容,那要是按照上面的代码进行继承的话那D中也会有A的内容,这里可以通过下面的代码进行一下验证:
int main()
{
D tmp;
cout << tmp.a << endl;
return 0;
}
这段代码的意思就是创建了一个D类的对象然后访问A类的数据,这段代码的运行结果如下:
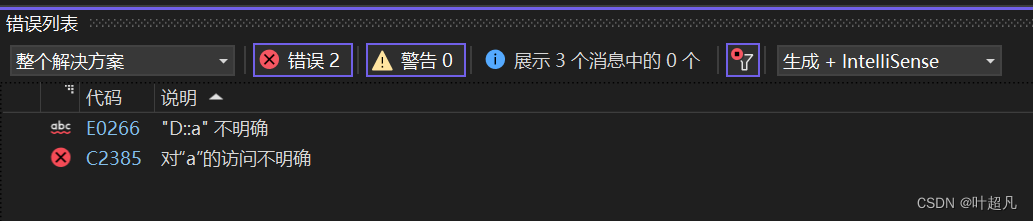
我们发现这段代码并没有正常的运行下去,报出的错误为对a的访问不明确那这是为什么呢?原因很简单B和C中都有A的数据,D继承了B和C所以D中就会有两份A的数据,上面的代码是在类D中访问A的数据,可是D中有两份A的数据,一份来自于B一份来自于C所以在访问的时候如果没有加指定的区域就会报错
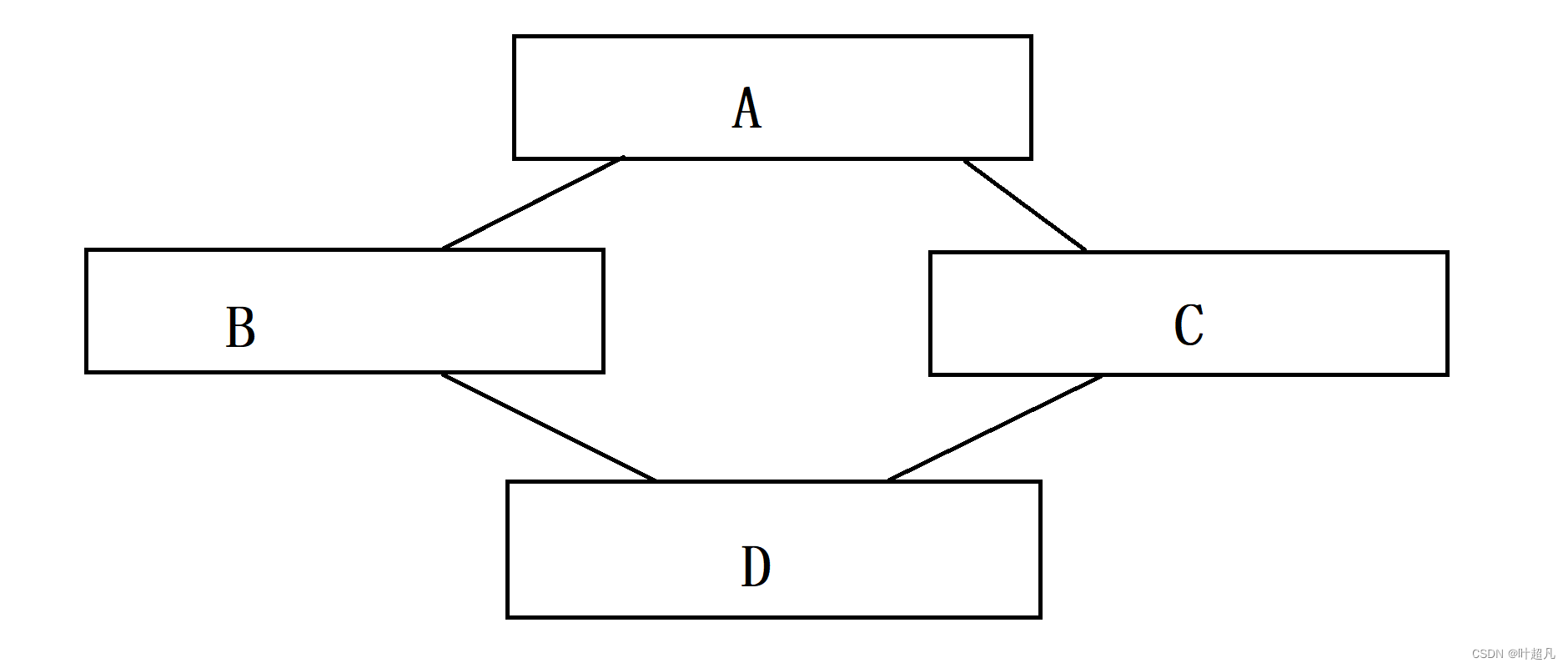
上面的继承逻辑长的像菱形,所以我们就把这种继承方式称为菱形继承,如果我们想要访问A类数据的话就得指定作用域,并且不同作用域的A类数据是单独的他们之间是没有联系的,比如说下面的代码:
int main()
{
D tmp;
cout << tmp.B::a << endl;
cout << tmp.C::a << endl;
tmp.B::a = 100;
tmp.C::a = 200;
cout << tmp.B::a << endl;
cout << tmp.C::a << endl;
return 0;
}
这段代码的运行结果如下:
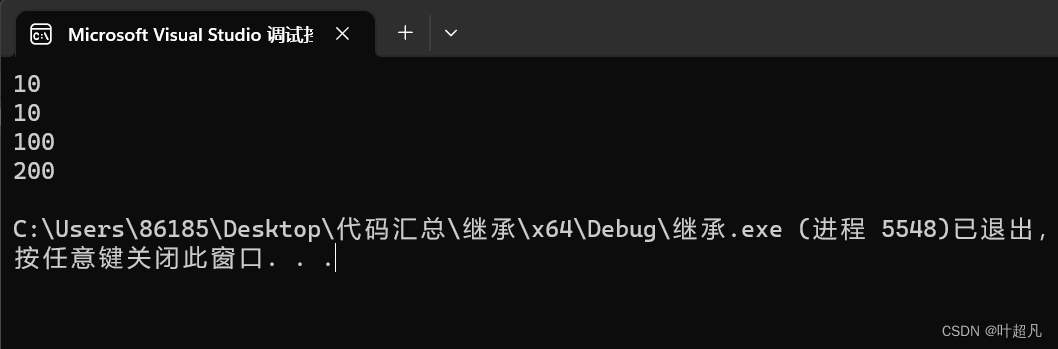
我们可以通过调试来看看内存中的数据情况:
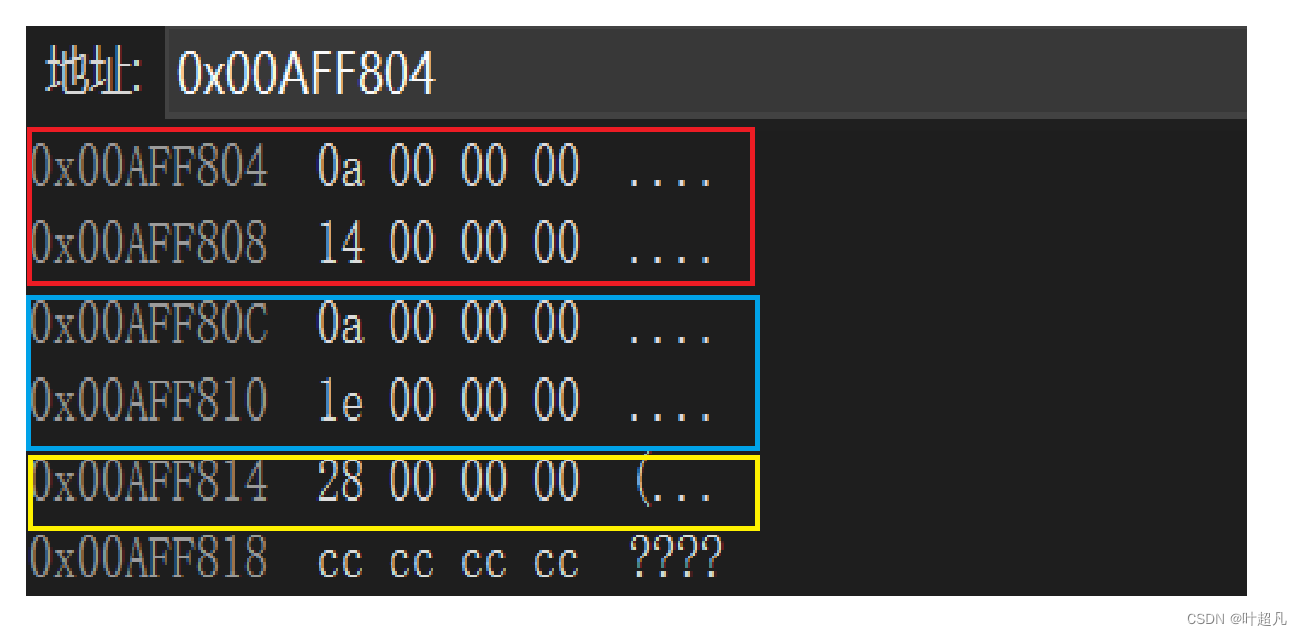
tmp在内存中的数据分布如上,红色框中是B的数据,蓝色框中是C的数据,黄色框中是D的数据,并且红色框中和蓝色框中还都有一份A的数据,因为D在继承的时候是先继承的B再继承的C,所以在数据分布的时候B的数据会在C的数据的前面,那这里就可以简单的画出D类型对象中的数据分布:
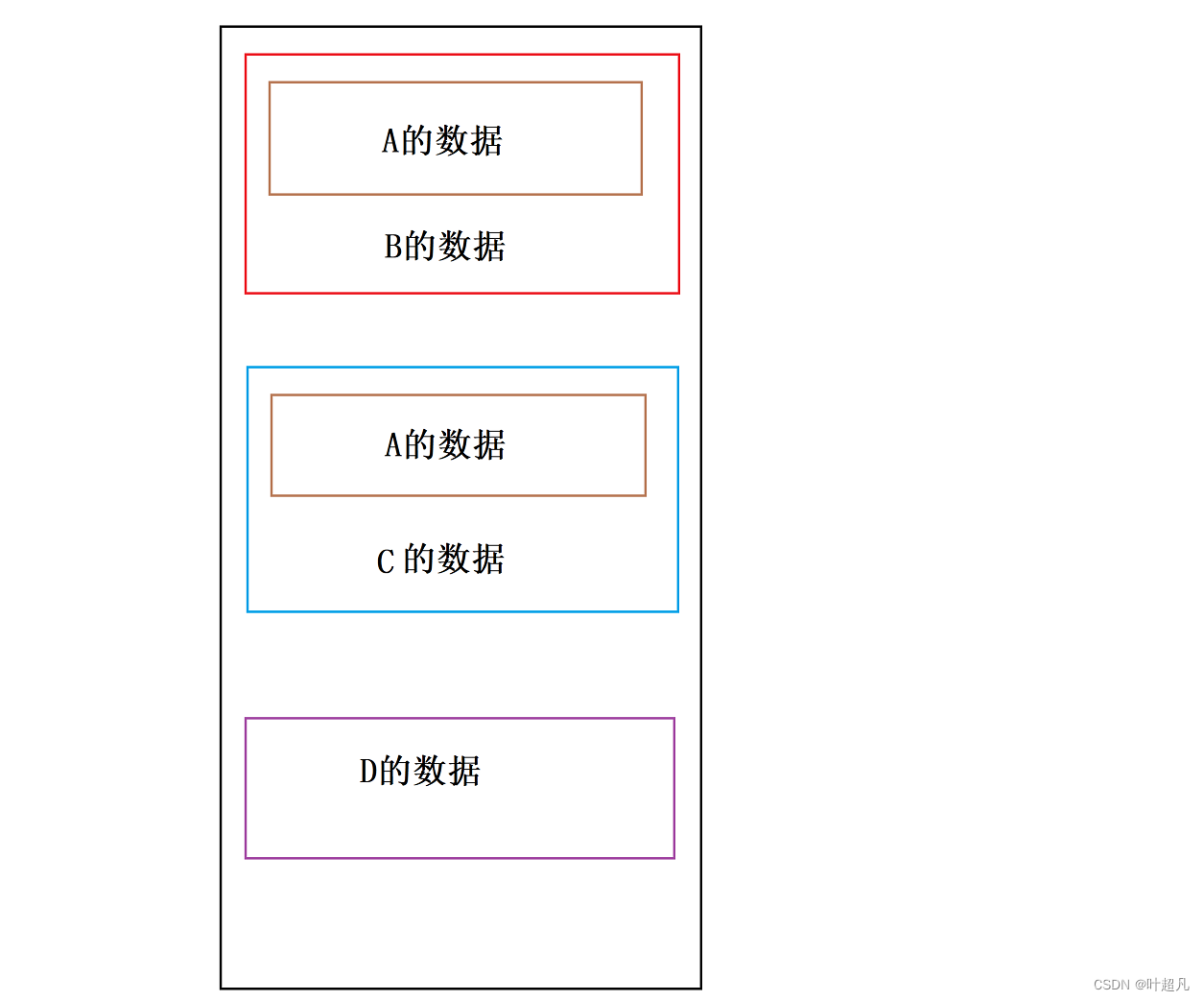
看到这里想必大家应该知道了什么是菱形继承,那么接下来我们就来看看菱形继承所带来的问题,菱形继承有数据冗余和二义性的问题,一个派生类有两个父类的内容这肯定不是我们想要看到的所以从数据层面来看这里是数据冗余造成了空间的浪费,从数据的访问角度来看这里是二义性的问题,因为菱形继承这里访问数据的时候得指定作用域不然就无法访问A类的数据,那么这就是菱形继承带来的问题,接下来我们就要看看如何解决菱形继承。
如何解决菱形继承
虚拟继承可以解决菱形继承的二义性和数据冗余的问题。在继承的方式前面加上virtual便可以实现虚拟继承比如说说下面的代码:
class A
{
public:
int a=10;
};
class B :virtual public A
{
public:
int b=20;
};
class C :virtual public A
{
public:
int c=30;
};
class D :public B, public C
{
public:
int d=40;
};
类B和类C都是虚拟继承的类A,当类D同时继承B C的时候就可以将多份虚拟继承的A合并成为同一份,这样就可以减少内存的消耗,并且访问类A的时候也不用加上指定的作用域,比如说下面的测试代码:
int main()
{
D tmp;
cout << tmp.a << endl;
cout << tmp.a << endl;
tmp.a = 100;
tmp.a = 200;
cout << tmp.a << endl;
cout << tmp.a << endl;
return 0;
}
这段代码的运行结果如下:
那么这就是虚拟继承的作用,它可以解决菱形继承带来的问题。那虚拟继承为什么可以解决数据的冗余和二义性的问题呢?那这里我们接着往下看。
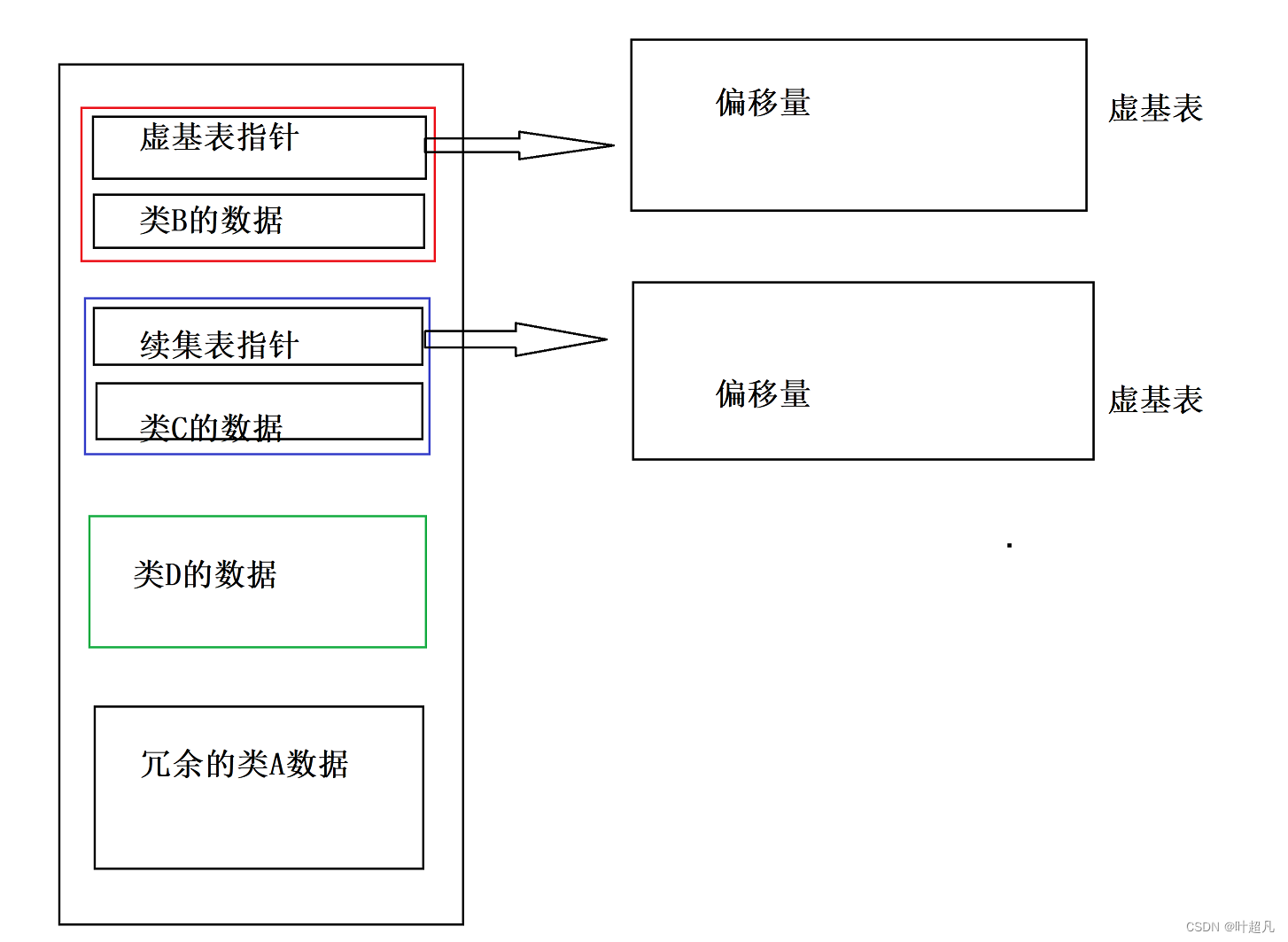
解决的底层原理
如果不采用虚拟继承的话,在基类里面就都会存储着冗余的数据,如果采用虚拟继承的方式进行继承的话,冗余的数据就会放到一个地方并且只有一份,然后在每个对象里面就会存储着一个指针,这个指针称为虚基表指针,指针指向的表称为虚基表,在虚基表中存储的就是冗余数据的偏移量,通过偏移量就可以找到公共的数据,这里我们可以通过下面的图片来验证一下上面话,采用虚继承的D类型的对象的数据分布如下:
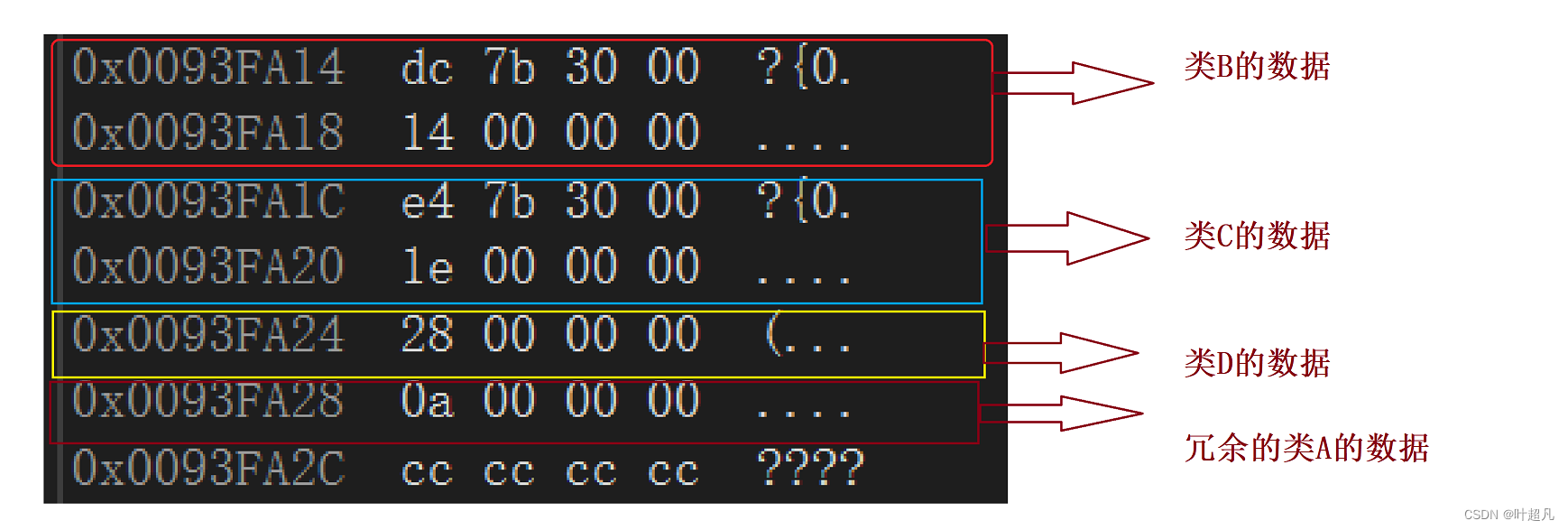
其中类B和类C里面都分别包含一个指针
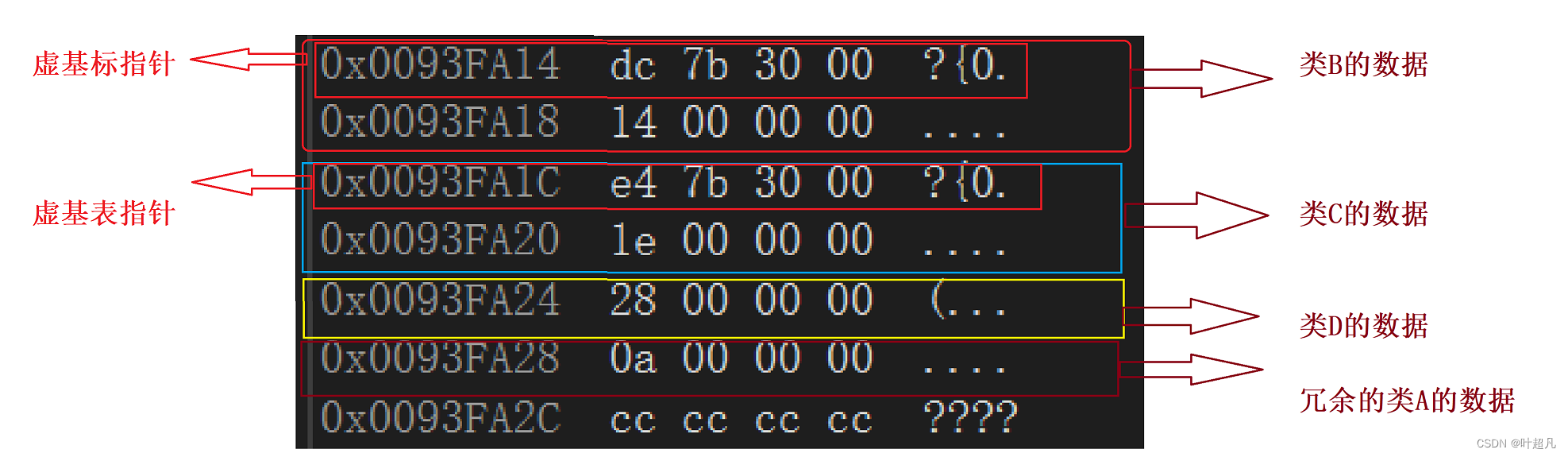
这个虚基表指针指向的对象就是偏移量比如说下面的图片就是00 31 7b dc指向的内容,:
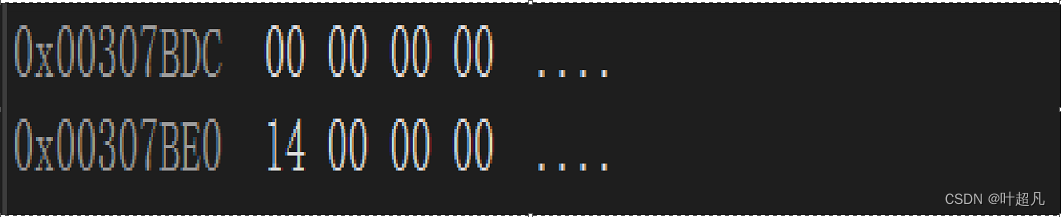
这是一个虚基表,该表的是以NULL作为结尾,这个表里面记录了偏移量14,这里的14是16进制,所以偏移量应该为20,类B的起始地址为0093FA14,冗余类的数据地址为0093FA28,这两个地址相减刚好就是20,那么这就说明通过虚基表的指针可以找到虚基表,虚基表里面装的是到冗余数据位置的偏移量,通过这个偏移量便可以找到冗余的数据,同样的道理类C的数据里面也有一个虚基表指针,这个指针也指向一个虚基表,表里面的内容为:
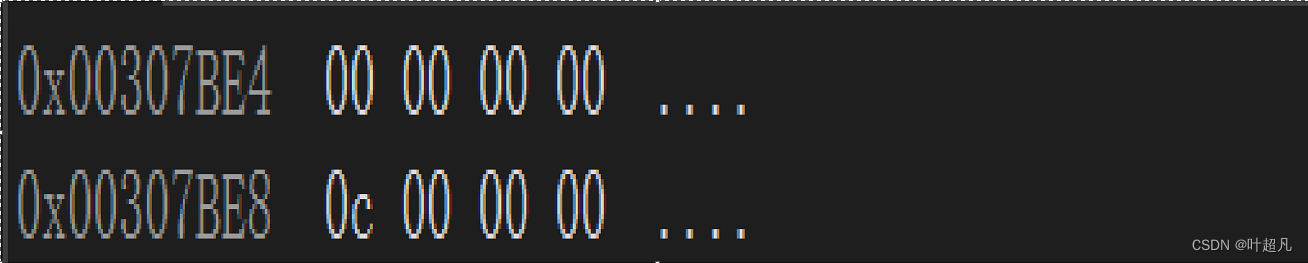
偏移量为10而且0093FA28减去0093FA1C的值也刚好为10,那么这也就验证了我们上面的猜想,大家可以通过下面的图片来再进行一下理解:
之所以采用这样的方法来解决菱形继承的问题是因为存在下面的场景
B*ptr = &d;
ptr ->_a=1;
C*ptr =&d;
ptr->_a=2;
d的类型是D,但是当我们使用父类型的指针指向d对象的时候会发生切片,这里不同的类型指针实际上只能访问d对象的数据中的一部分,为了使他们都能够找到共有的A类数据,所以就各类的数据里面存放一个地址,通过这个地址,就可以找到偏移量,通过偏移量就可以找到共有的A类数据,所以不管是对象本身,还是对象发生了切片,采用这个方法都可以访问到父类的成员,这样的方法会造成点效率的损失,因为不是直接访问,而是间接的访问,但是这种方法解决了数据的冗余和访问的二义性。
继承和组合
public继承是一种is-a的关系。也就是说每个派生类对象都是一个基类对象。组合是一种has-a的关系。假设B组合了A,每个B对象中都有一个A对象。比如说下面的代码:
class A
{
public:
private:
};
class B :public A
{
public:
private:
};
这个就是继承,而下面就是组合:
class A
{
public:
private:
};
class B
{
public:
private:
A tmp;
};
在平时写代码的时候优先使用对象组合,而不是类继承 。继承允许你根据基类的实现来定义派生类的实现。这种通过生成派生类的复用通常被称为白箱复用(white-box reuse)。术语“白箱”是相对可视性而言:在继承方式中,基类的内部细节对子类可见 。继承一定程度破坏了基类的封装,基类的改变,对派生类有很大的影响。派生类和基类间的依赖关系很强,耦合度高。对象组合是类继承之外的另一种复用选择。新的更复杂的功能可以通过组装或组合对象来获得。对象组合要求被组合的对象具有良好定义的接口。这种复用风格被称为黑箱复用(black-box reuse),因为对象的内部细节是不可见的。对象只以“黑箱”的形式出现。组合类之间没有很强的依赖关系,耦合度低。优先使用对象组合有助于你保持每个类被封装。实际尽量多去用组合。组合的耦合度低,代码维护性好。不过继承也有用武之地的,有些关系就适合继承那就用继承,另外要实现多态,也必须要继承。类之间的关系可以用
继承,可以用组合,就用组合。比如说A类中有100个数据其中20个是共有80个是保护,如果采用继承的方式来创建B,则当我们修改A类中的任意一个数据都可能会影响到B类的使用,可是使用组合的方式来创建B的话,只有修改那20个共有数据的时候才会可能影响到B的使用,那么这就是组合和继承的区别。