摘要
蒙面图像建模(MIM)因其在学习可伸缩视觉表示方面的潜力而引起了广泛的研究关注。在典型的方法中,模型通常侧重于预测掩码补丁的特定内容,并且它们的性能与预定义的掩码策略高度相关。直观地说,这个过程可以被看作是训练一个学生(模型)来解决给定的问题(预测掩蔽补丁)。然而,我们认为,该模型不仅应该关注解决特定的问题,而且应该站在教师的立场上,以产生一个更具挑战性的问题本身。为此,我们提出了硬补丁挖掘Hard Patches Mining(HPM),一个全新的MIM预训练框架。我们观察到,重建损失自然可以成为预训练任务难度的度量标准。因此,我们引入了一个辅助损失预测器,首先预测补丁损失,并决定下一步掩盖在哪里。它采用相对关系学习策略,以防止对精确重建损失值的过拟合。在不同设置下的实验证明了HPM在构建掩蔽图像方面的有效性。此外,我们通过经验发现,仅仅引入损失预测目标就会导致强大的表示,验证了感知哪里难以重建的能力的有效性。
介绍
自监督学习的目标是从没有任何注释的大规模数据集中学习可扩展的特征表示,一直是计算机视觉(CV)的研究热点。受自然语言处理(NLP)中的掩蔽语言建模(MLM)的启发,该模型被敦促预测句子中的掩蔽词,CV中的掩蔽图像建模(MIM)引起了许多研究者的极大兴趣。图1a显示了MIM预训练的传统方法的范例。在这些典型的解决方案中,模型通常侧重于预测掩蔽补丁的特定内容。直观地说,这个过程可以被看作是训练一个学生(即模型)来解决给定的问题(即预测掩蔽补丁)。
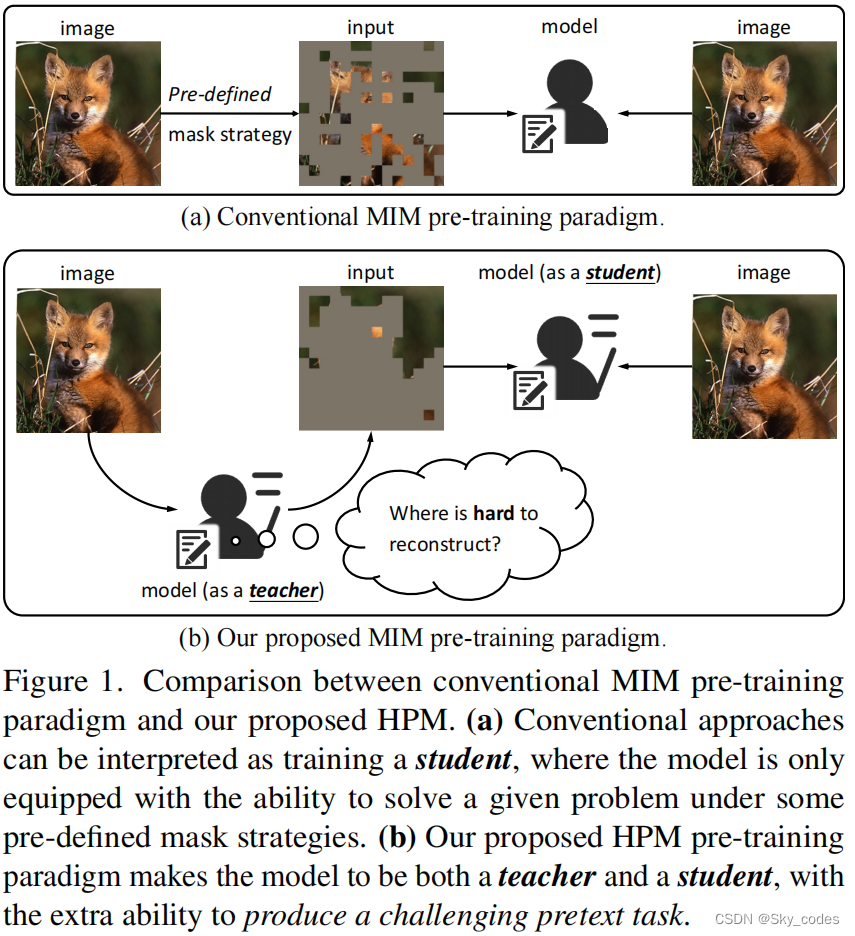
为了缓解CV中的空间冗余,产生具有挑战性的借口任务,掩蔽策略变得非常关键,这些策略通常是在预定义的方式下生成的,如随机掩蔽、块级掩蔽和统一掩蔽。然而,我们认为,一个困难的借口任务并不是我们所需要的全部,不仅学习解决MIM问题是很重要的,而且学习产生具有挑战性的任务也是至关重要的。换句话说,如图1b所示,通过学习创建具有挑战性的问题和解决它们,模型可以站在学生和老师的鞋子,被迫举行更全面的理解图像内容,从而导致自己通过生成一个更理想的任务。
为此,我们提出了硬补丁挖掘(HPM),一种新的MIM训练范式。具体来说**,给定一个输入图像,我们不是在手动设计的标准下生成一个二进制掩模,而是首先让模型作为教师生成一个要求很高的掩模,然后像传统方法一样训练模型作为学生预测掩模补丁。**通过这种方式,我们敦促模型学习在哪里值得被掩盖,以及如何同时解决问题。然后,问题就变成了如何设计辅助任务,使模型知道硬补丁在哪里。

直观地说,我们观察到重建损失可以自然地衡量MIM任务的难度,这可以通过图2中每个元组的前两个元素来验证,其中由MAE [24]预先训练的1600个时期的主干2用于可视化。正如预期的那样,我们发现图像的那些鉴别部分(例如,物体)通常很难重建,导致更大的损失。因此,通过简单地敦促模型预测每个斑块的重建损失,然后掩盖那些预测损失较高的斑块,我们可以获得一个更强大的MIM任务。为了实现这一点,我们引入了一个辅助损失预测器,首先预测斑块损失,并根据其输出决定下一步屏蔽哪里。为了防止它被重建损失的精确值所淹没,并使其集中于斑块之间的相对关系,我们设计了一种新的基于二元交叉熵的相对损失作为目标。在图2中,我们使用在200个epoch的预训练所使用的ViT-B进一步评估了损失预测器的有效性。正如图2中每个元组的最后两个元素所示,预测损失较大的斑块往往具有区别性,因此掩盖这些斑块带来了一个具有挑战性的情况,即对象几乎被掩盖。同时,考虑到训练的演变,我们提出了一个简单到困难的mask生成策略,在早期阶段提供了一些合理的提示。
根据经验,我们观察到在各种设置下,比监督基线和香草MIM预训练有显著和一致的改善。具体来说,由于预训练只有800个epoch,HPM使用ViT-B和ViTL在ImageNet-1K [58]上达到了84.2%和85.8%的前1准确率,分别比1600个时代预训练的MAE [24]高出+0.6%和+0.7%。
相关工作
-
Self-supervised learning.
-
Masked image modeling.
-
Mask strategies in masked image modeling.
方法
在本节中,我们首先在Sec中概述我们提出的HPM。3.1.然后,在第二秒中介绍了HPM中的两个目标,即重建损失和预测损失。3.2和3.3,分别。最后,在第二节中。3.4,描述了易于实现的掩模生成方式,以及整个训练过程的伪代码。
3.1 概述
如图1和第二节所介绍。1、传统的MIM预训练解决方案可以看作是训练学生解决给定的问题,而我们认为让模型站在教师的立场上,产生具有挑战性的借口任务是至关重要的。为此,我们引入了一个辅助解码器来预测每个掩蔽补丁的重建损失,并仔细设计了其目标。图3给出了我们提出的HPM的概述。
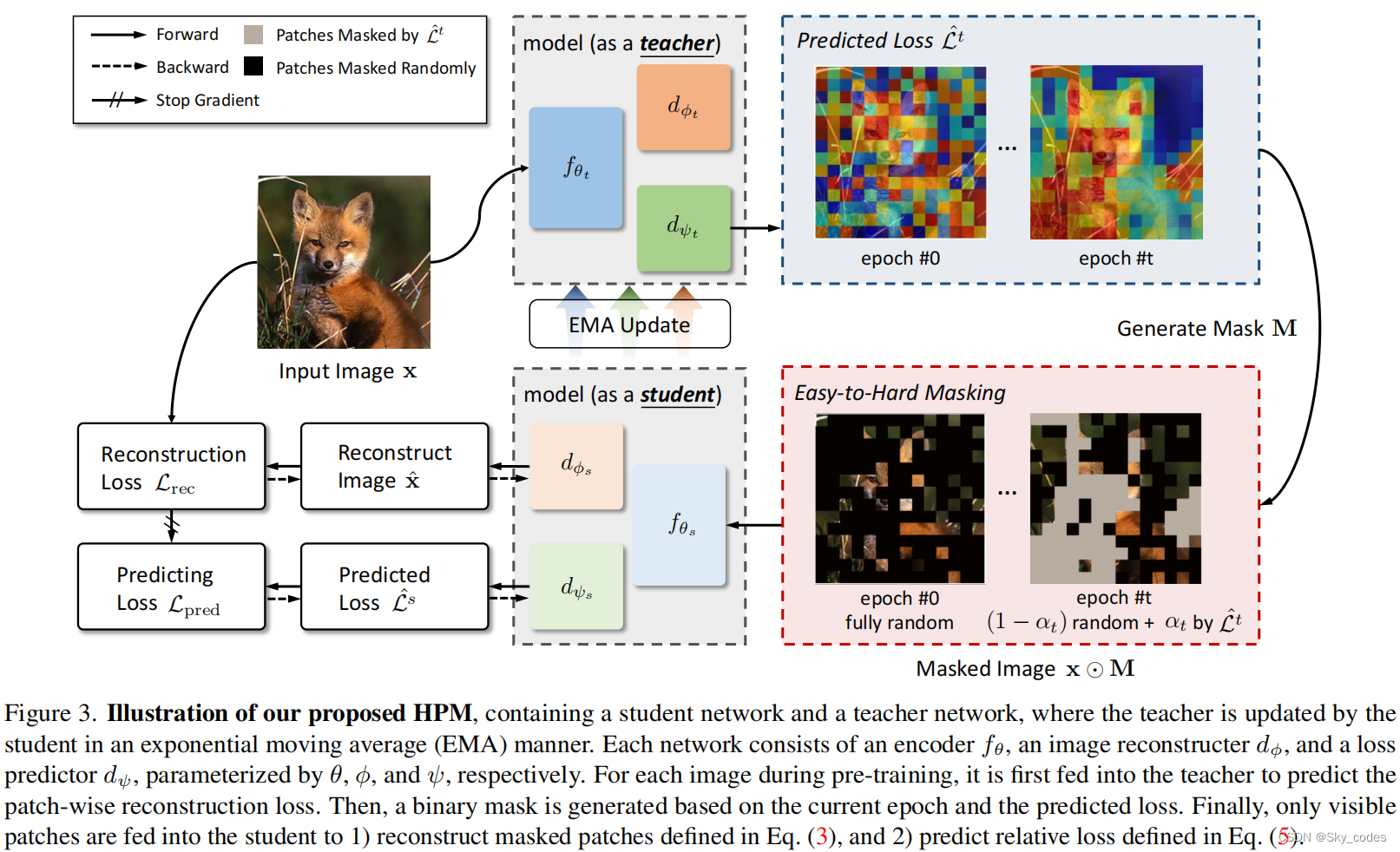
HPM由一个学生(fθs、dφs和dψs)和一个教师(fθt、dφt和dψt)组成。fθ(·)、dφ(·)和dψ(·)分别是编码器、图像重建器和重建损失预测器,分别由θ、φ和ψ参数化。下标t代表老师,s代表学生。为了产生一致的预测(特别是对于重建损失预测器),动量更新被应用于教师:其中,θt =(θt,φt,ψt)、θs =(θs,φs,ψs)、m为动量系数。
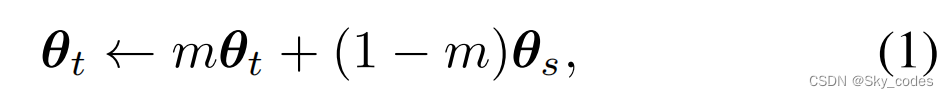
在每次训练迭代中,一个输入图像I被重塑为一系列二维补丁x∈RH×W×C∈RN×(P2C)。(H,W)为原始图像的分辨率,C为通道数,P为patch大小(例如,16),因此为N = HW/P2。然后,将x输入教师,得到章节中描述的补丁预测重建损失模型(Lˆt=dψt,fθt(x))。3.2.基于预测的重建损失Lˆt和训练状态,以一种简单到困难的方式生成了一个二进制掩码M∈{0,1} N。3.4.学生的训练基于两个目标,即重建损失(3.2)和预测损失(3.3)
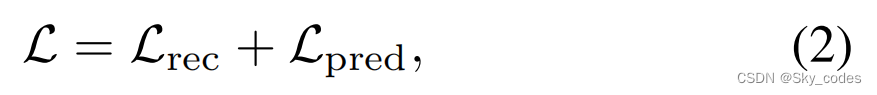
这两个目标以一种交替的方式工作,并通过逐渐敦促学生重建图像中的硬补丁来相互强化以提取更好的表示。
3.2 Image Reconstructor
掩蔽图像建模的目的是训练一个自动编码器(即图像重建器)根据预定义的目标,如原始RGB像素和特定特征。
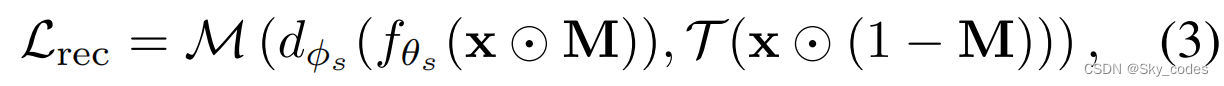
其中,对于传统的方法,二进制掩模M∈{0,1} N ^N N是通过预先定义的方式生成的。 ⊙ \odot ⊙表示元素级的点积,因此x ⊙ \odot ⊙M表示未屏蔽的(即可见的)补丁,反之亦然。T(·)是变换函数,生成重构的目标。M(·,·)表示相似性度量,如l2-距离、平滑的l1-距离、知识蒸馏和交叉熵。
3.3 Hard Patches Mining with a Loss Predictor
众所周知,在NLP中,句子中的每个单词都是高度语义的。在理解语言时,训练一个模型来只预测少数缺失的单词往往是一项具有挑战性的任务。而在CV中,图像具有较重的空间冗余,因此提出了大量的掩模策略来处理这个问题。
除了通过先验知识设计一个具有挑战性的情况外,我们认为,产生高要求的场景的能力对MIM的预训练也是至关重要的。直观地说,我们考虑了在等式中定义的具有高重建损失的补丁(3)作为硬斑块,它隐含地表示了图像中最具鉴别性的部分,这在图2中得到了验证。因此,如果该模型具有预测每个补丁的重建损失的能力,那么简单地掩盖这些硬补丁就会成为一项更具挑战性的借口任务。
为此,我们使用了一个额外的损失预测器(即图3中的dψ)来在训练过程中挖掘硬斑块。接下来,我们将介绍如何设计具有两种变量的损失预测器的目标: 1)绝对损失和2)相对损失。
Absolute loss
最简单和最直接的方法是以MSE的方式来定义目标。
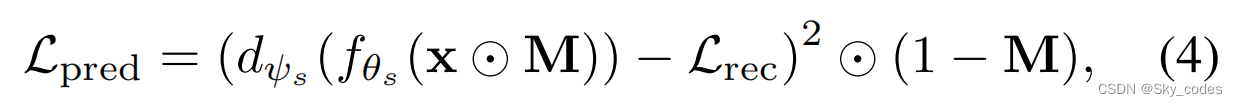
其中dψs是由ψs参数化的学生的辅助解码器,这里的Lrec与梯度分离,是损失预测的ground-truth。然而,请回想一下,我们的目标是确定图像中的硬补丁,因此我们需要学习补丁之间的相对关系。在这样的设置下,MSE并不是最合适的选择,因为Lrec的量表随着训练的进行而减小,因此损失预测器可能会被Lrec的量表和确切值所淹没。为此,我们提出了一种基于二值交叉熵的相对损失作为替代方案。
Relative loss.
给定一系列重建损失的Lrec∈RN,我们的目标是利用相对损失来预测目标排序(Lrec)。这是因为,在一个图像中,重建任务的拼块难度可以通过精射排序(Lrec)来测量。然而,由于目标排序(·)操作是不可微的,因此很难直接最小化目标排序(dψs(fθs(xM))和目标排序(Lrec)之间的一些自定义距离。
因此,我们将这个问题转化为一个等价的问题:密集关系比较。具体来说,对于每一对补丁(i,j),其中i,j = 1、2、···、N和i ≠ j,我们可以通过预测Lrec (i)和Lrec (j)的相对关系来隐式地学习目标排序(Lrec),即哪个更大。其目标的定义如下:
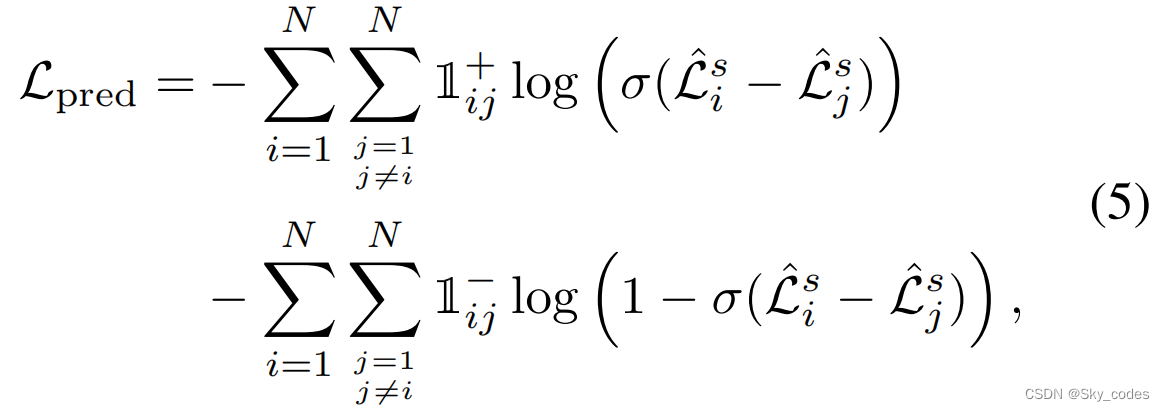
其中,Mi = Mj = 0表示补丁i和j在训练期间都被屏蔽。
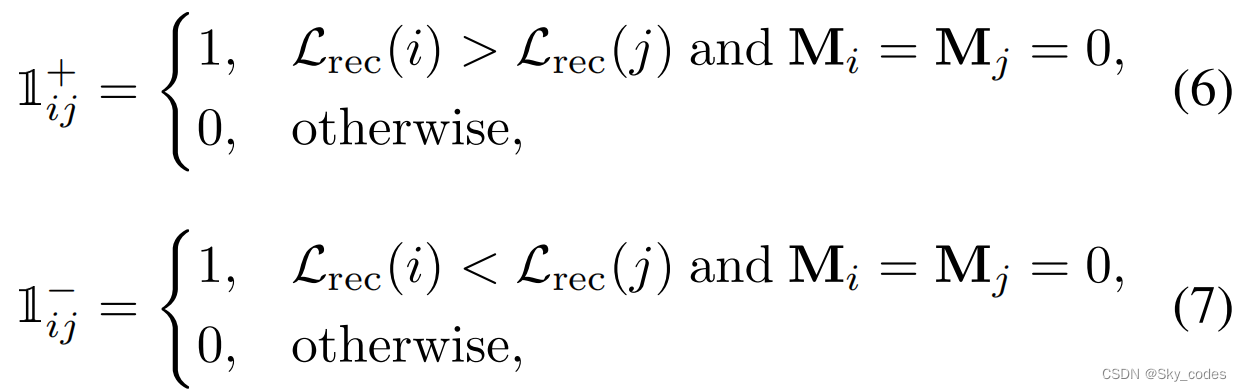
3.4 Easy-to-Hard Mask Generation
有了重建损失预测器,我们能够定义一个更具挑战性的借口任务,即掩盖输入图像的硬/鉴别部分。具体地说,我们从教师网络中获得预测的重建损失,即fθt=dψt(Lˆt=))后,对Lˆt降序进行目标排序(·)操作,以获得图像内的相对重建难度。然而,在早期的训练阶段,学习到的特征表征还没有准备好进行重建,而是被丰富的纹理所淹没,这意味着较大的重建损失可能不等同于鉴别。
然而,在早期的训练阶段,学习到的特征表征还没有准备好进行重建,而是被丰富的纹理所淹没,这意味着较大的重建损失可能不等同于鉴别。为此,我们提出了一种易于硬实现的掩模生成方法,提供了一些合理的提示,指导模型逐步重建掩模硬补丁。
如图3所示,对于每个训练阶段t,由Lˆt生成掩模补丁的αt,并随机选择其余1个−αt。具体来说,αt = α0 + t/T(αT−α0),其中T是总的训练时期,而α0,αT∈[0,1]是两个可调的超参数。我们过滤了Lˆt最高的αt·γN补丁,其余的(1个−αt)·γN补丁被随机屏蔽。αt的比例从α0以线性方式逐渐增加到αT,而没有进一步调整简单,有助于一个易于难操作的训练过程。
算法1总结了训练过程,以及计算训练重建损失预测器的目标的伪代码。由于易于硬的掩模生成的简单实现,请参考补充材料的伪代码。
实验
消融
总结
在本文中,我们发现有必要让模型站在教师的立场上进行MIM预训练,并验证补丁重建损失可以自然地作为重建难度的度量。为此,我们提出了HPM,它引入了一个辅助的重建损失预测任务,从而以生成-求解的方式迭代地指导训练过程。在实验上,HPM引导了跨各种下游任务的掩蔽图像建模的性能。跨不同学习目标的消融表明,HPM作为一个即插即用的模块,可以毫不费力地集成到现有的框架中(例如,像素回归[24,78]和特征预测[17,72,86])中,并带来一致的性能改进。
挖掘硬例子的技术被广泛应用于对象检测[34,39,60]。损失预测可以是一种全新的选择。此外,它还可以作为一种在标签高效学习[19,70,71]中过滤高质量伪标签的技术。同时,如图2和图4所示,显著性区域倾向于有较高的预测损失,因此HPM也可以用于显著性检测[67]和无监督分割[63,64]。我们希望这些观点能启发未来的工作。讨论作为MIM的一个常见问题,线性探测和k-NN分类的性能不如对比学习替代方案[24]相似。此外,由于额外的解码器,HPM需要更多的计算成本。用ViTL [18]对抗MAE [24]基线训练我们的HPM需要∼1.1×的时间。如何在没有额外的辅助解码器的情况下设计一个损失预测任务有待进一步研究。