- 论文标题:Quo Vadis, Action Recognition? A New Model and the Kinetics
- 会议期刊: CVPR 2017
- Dataset 论文地址:https://arxiv.org/pdf/1705.07750.pdf
文章目录
- 前言
- 文章核心
- 摘要
- 引入
- 方法
- a. 2DConv+LSTM
- b. 3DConv
- c d. Two-Strwam
- Two-Stream 3D-ConvNet 【本文】
- 实验效果
- 局限性
前言
在视频理解领域,I3D是一篇不得不读的文章,在他之前,当时人的解决方案大多数是以双流网络为主进行视频分类。在UCF-101和HMDB-51数据集上进行测试对比结果,当I3D提出之后,基本上将UCF-101和HMDB-51数据集刷到顶峰了,同时,使得3DCNN在视频理解领域大放异彩,直到近几年VIT的出现,才有新的方向对视频理解领域进行推进;I3D也提出了一个新的数据集–Kinetics Dataset,之后的方法都需要在这个数据集上进行对比。
文章核心
提出了一个Two-Stream Inflated 3D ConvNet(I3D)网络,也就是一个双流膨胀3D卷积神经网络。开源了一个大规模公开数据集–Kinetics Human Action Video dataset。使用这个大规模数据集科研进行预训练模型在UCF-101和HMDB-51数据集进行迁移学习可以达到更好的效果。
摘要
看一下原文是怎么描述。稍微进行提炼。
- 当前挑战:当前动作分类数据集(UCF-101 和 HMDB-51)中缺乏视频使得很难识别好的视频架构,因为大多数方法在现有的小规模基准上获得了相似的性能。【两个公开数据集有局限性,无法使模型具有区分度】
- 本文贡献
- 数据集贡献: 本文根据新的 Kinetics Human Action Video 数据集重新评估了最先进的架构。 Kinetics 拥有多两个数量级的数据,有 400 个人类动作类和每个类 400 多个clip,并且是从逼真的、具有挑战性的 YouTube 视频中收集的。【更好更大的数据集】
- 迁移学习:我们分析了当前架构如何处理该数据集的动作分类任务,以及在 Kinetics 预训练后在较小的基准数据集上性能提高了多少。【使得模型更加有区分度,同时使用迁移学习可以从大数据集迁移到小数据集】
- 新的模型架构:我们还介绍了一种新的基于 2D ConvNet 膨胀的双流膨胀 3D ConvNet(I3D):非常深的图像分类 ConvNets 的过滤器和池核扩展到 3D,使得学习无缝空间成为可能- 从视频中提取时间特征,同时利用成功的 ImageNet 架构设计以及它们的参数。【更好的模型架构,更好的预训练参数进行初始化】
- 结果:我们表明,在 Kinetics 预训练之后,I3D 模型大大改进了动作分类的最新技术水平,在 HMDB-51 上达到 80.9%,在 UCF-101 上达到 98.0%。
引入
总结提炼原文,不放置原文内容了,原文可参考论文PDF
目前的大背景是大规模数据预训练,到下游任务小规模数据上进行迁移学习这种方式取得了很好的效果。但是在视频领域缺少大规模数据集,因此在视频领域的模型,网络无法设计的太深太复杂【容易过拟合】。
视频理解涉及三维数据和时序性,一般的视频理解的方法主要可以分成三种方式:
- 卷积网络+时序网络(比如LSTM)
- 3D网络
- 双流网络(利用光流数据捕捉时序信息)
这三种方式哪种更好当时尚无定论,直到现在也是没有定论。用2D,3D,还是Transformer模型,现在也是不确定的。
如果想要充分利用预训练模型参数和前人非常完善巧妙的网络架构,就需要用某种方法解决2D到3D的之间Gap。作者针对此问题提出了Inflating和Bootstrapping来解决。
方法
原文没有相关工作,在方法部分,作者直接回顾对比了前面所提到的方法。
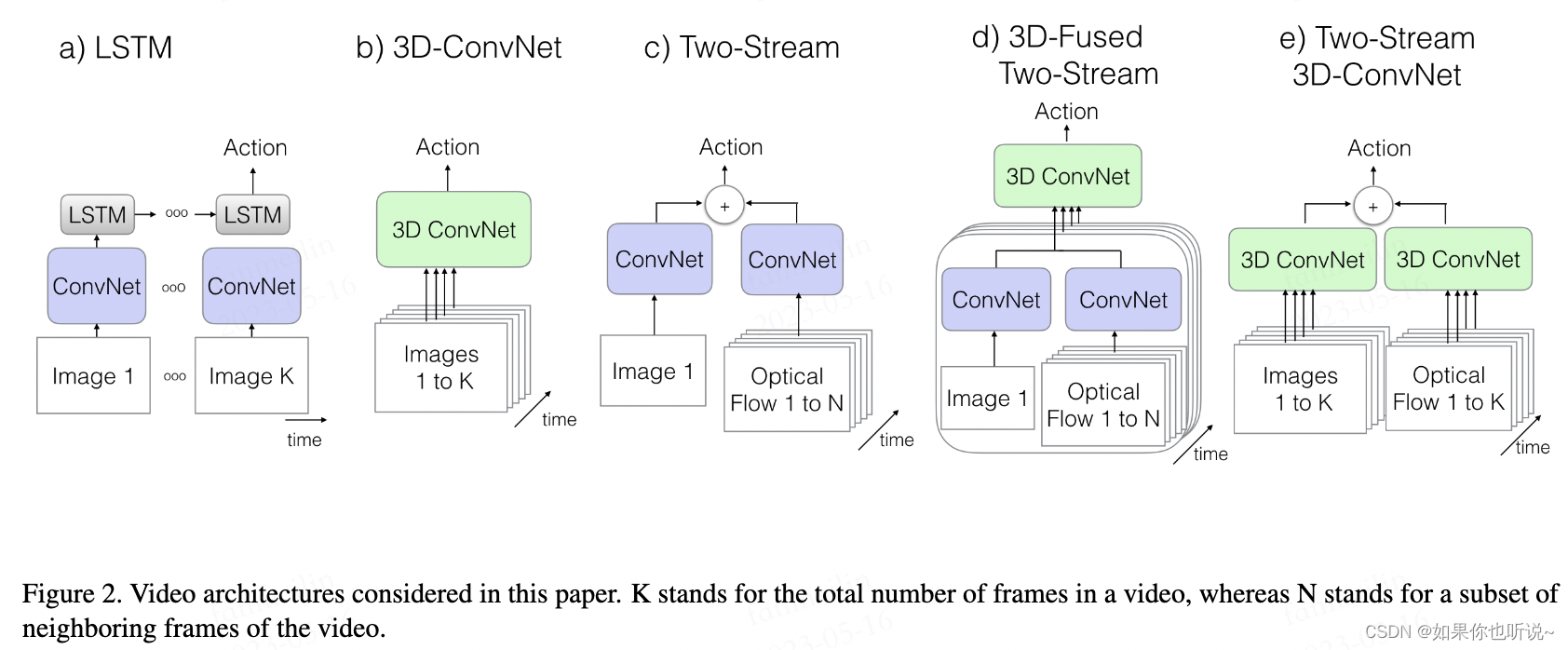
a. 2DConv+LSTM
这种方法是最直接可以想到的方法,利用2D卷积神经网络对所有帧提取特征后,使用LSTM网络对所有特征进行时序性的整合,最后加一个全连接层进行分类。
但是这种方法在实际使用中效果很一般,所以大家也不怎么用。
b. 3DConv
直接将视频帧【三维信息】放入3D卷积神经网络中,最后加一个全连接层进行分类。
这种方式的参数量相对较大,但是相比a更加主流。
c d. Two-Strwam
将视频放入成两个分支-空间流和时间流,一个分支学习场景信息,输入RGB一帧;另一个分支学习物体的运动信息,输入多帧(10帧)光流信息【抽取好的时序信息表示】,两个分支网络都是2D网络.
c. 得到logit信息;最后通过平均加权得到Action分类,这种方式是一个Later fusion【因为是在logit层面融合】。
d. 【CVPR2016】前面使用的是简单的平均加权得到最终结果,没有利用时序信息,因此可以在还未得到logit结果时,对两个分支的特征使用3Dconv的结构进行融合,获取一些时序信息,更有利于分类。这种方式就是Early fusion。【前面用2D网络,后面融合使用3D网络】
这种双流网络了方式的效果不错,也是主流方法。
Two-Stream 3D-ConvNet 【本文】
在有足够多的数据情况下,3D比2D卷积网络效果更好,并且利用光流信息可以提取更好的运动信息。因此本文结合了3DCNN和双流网络,将双流网络中的2D网络换成3D网络。
说回网络提到的两个贡献点,Inflating和Bootstrapping解决2D到3D的Gap;
- Inflating 2D ConvNets into 3D,目前有很多成功的网络架构,可以直接将其2D卷积改为3D卷积,2Dpooling改为3Dpooling,这种过程就称为Inflating。好处是可以直接保留最佳最优秀的网络架构设计。
- Bootstrapping 3D filters from 2D Filters,从预先训练的ImageNet模型中引导参数来初始化I3D:作者将图像重复复制到视频序列中将图像转换为(boring)视频。然后,在ImageNet上对3D模型进行隐式预训练,满足我们所谓的无聊视频固定点((boring)视频上的池化激活应与原始单个图像输入上的池化激活相同),这可以实现通过在时间维度上重复2D滤波器的权重N次,并且通过除以N来重新缩放它们,这确保了卷积滤波器响应是相同的。
对于2D网络上预训练的参数,如何迁移到3D网络,将某一帧复制多次成为类似video时,通过3DCNN输出也是和2DCNN一致的。如果2D的滤波器为N*N的,那么3D的则为N*N*N的。具体做法是沿着时间维度重复2D滤波器权重N次,并且通过除以N进行归一化。
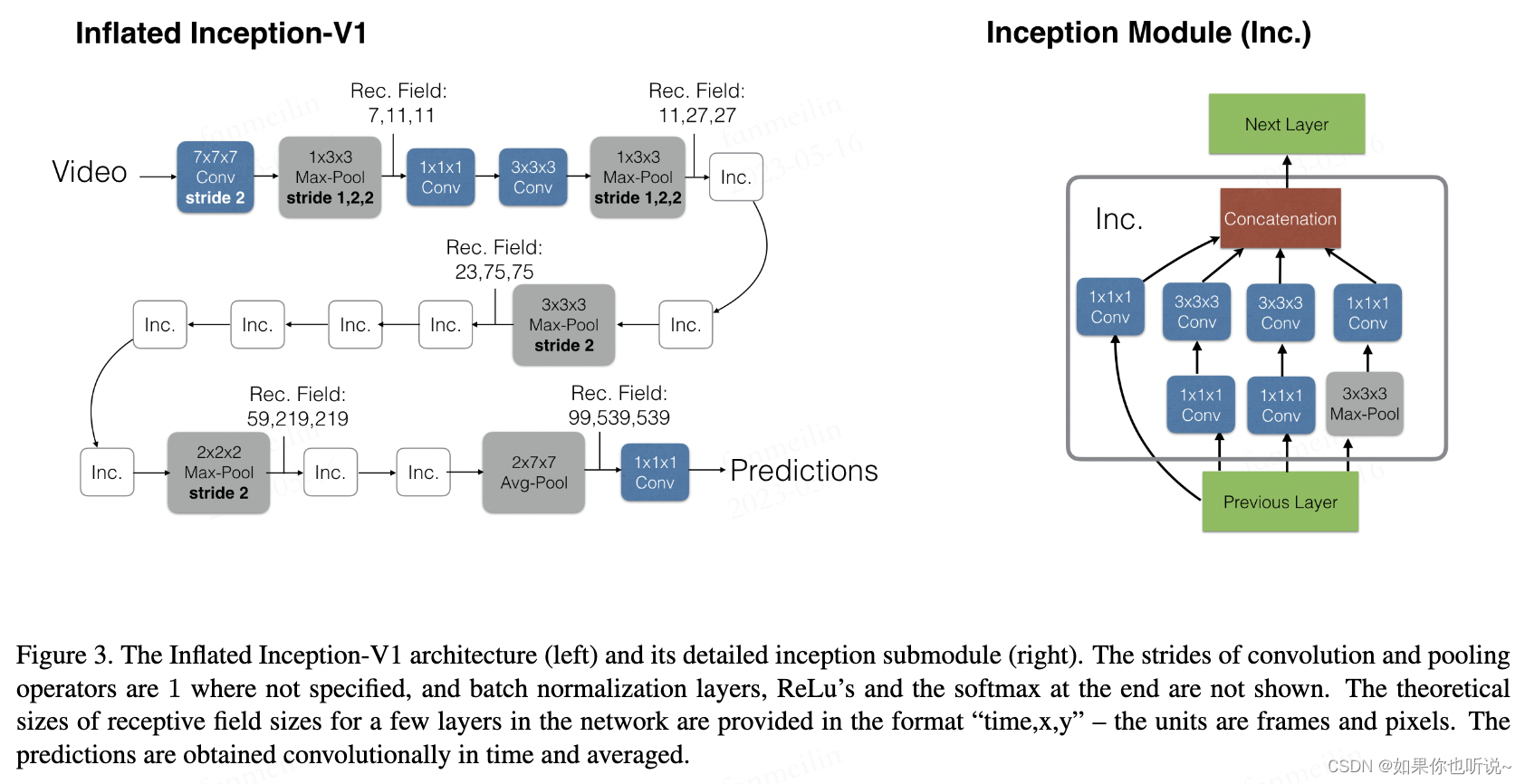
作者发现,MaxPooling在时间维度尽量不要下采样,因此前面几个stride是1*2*2。
在文章提到的基础网络是基于Inception v1,是当时效果最好的网络,不过后面很快就发现Resnet效果更好,因此后面的I3D网络,人们大多数指的是以Resnet为基础的网络。
实验效果
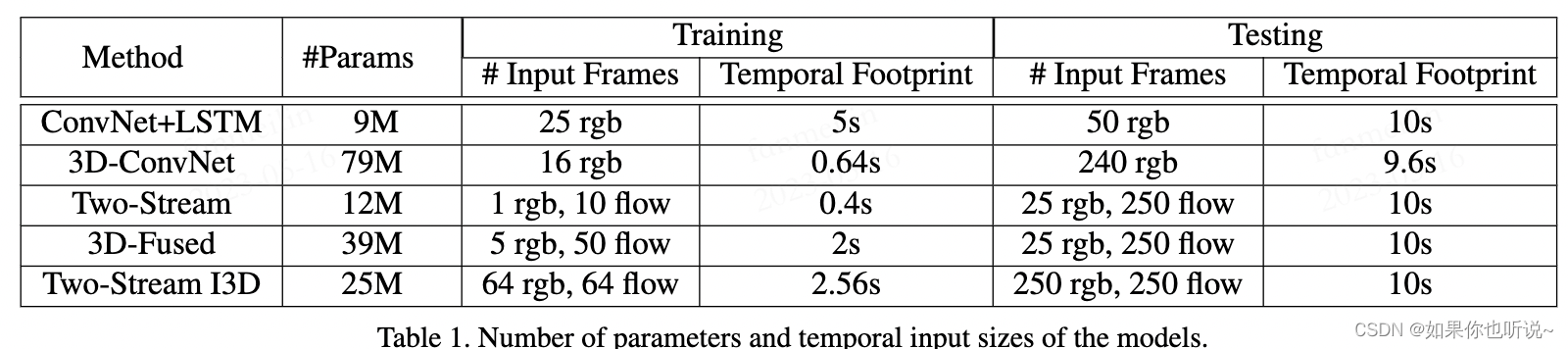
可以看到模型大小还是比较小的。测试时间都是一样的,因为都是将连续的视频直接输入,都是10s的视频。一般都是一秒有25帧,看一下Temporal Footprint这一,第一行是每隔5帧选一帧,输入25帧因此是5s时间得到输入;后面都是取连续帧。第2行是选取连续的16帧,因此为16/25为0.64;第三行是10/25为0.4;第四行为50/25;最后一行是64/25。
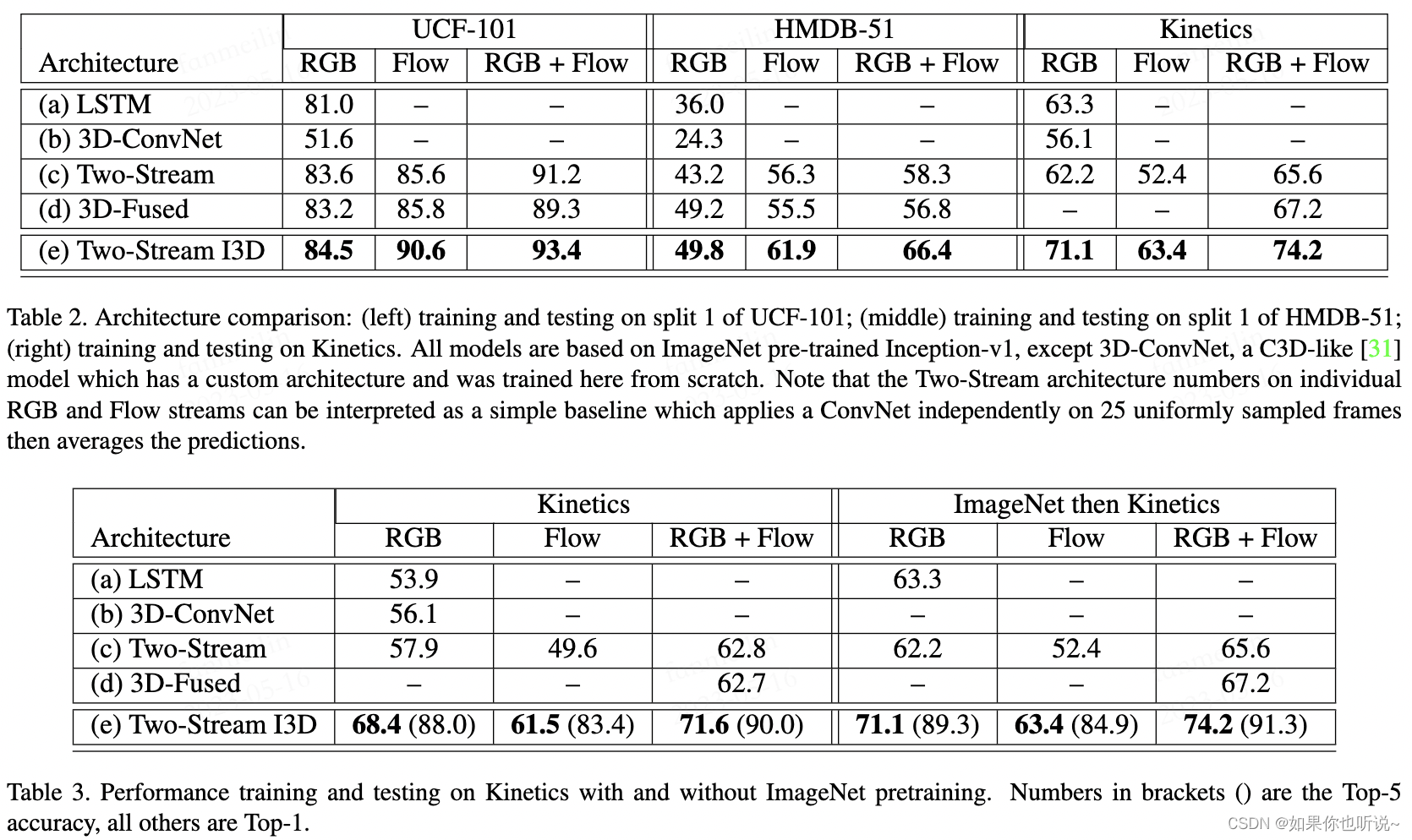 可以看到通过双流网络进行判别都比单独判别更好,同时,使用加载ImageNet参数的效果更好。
可以看到通过双流网络进行判别都比单独判别更好,同时,使用加载ImageNet参数的效果更好。
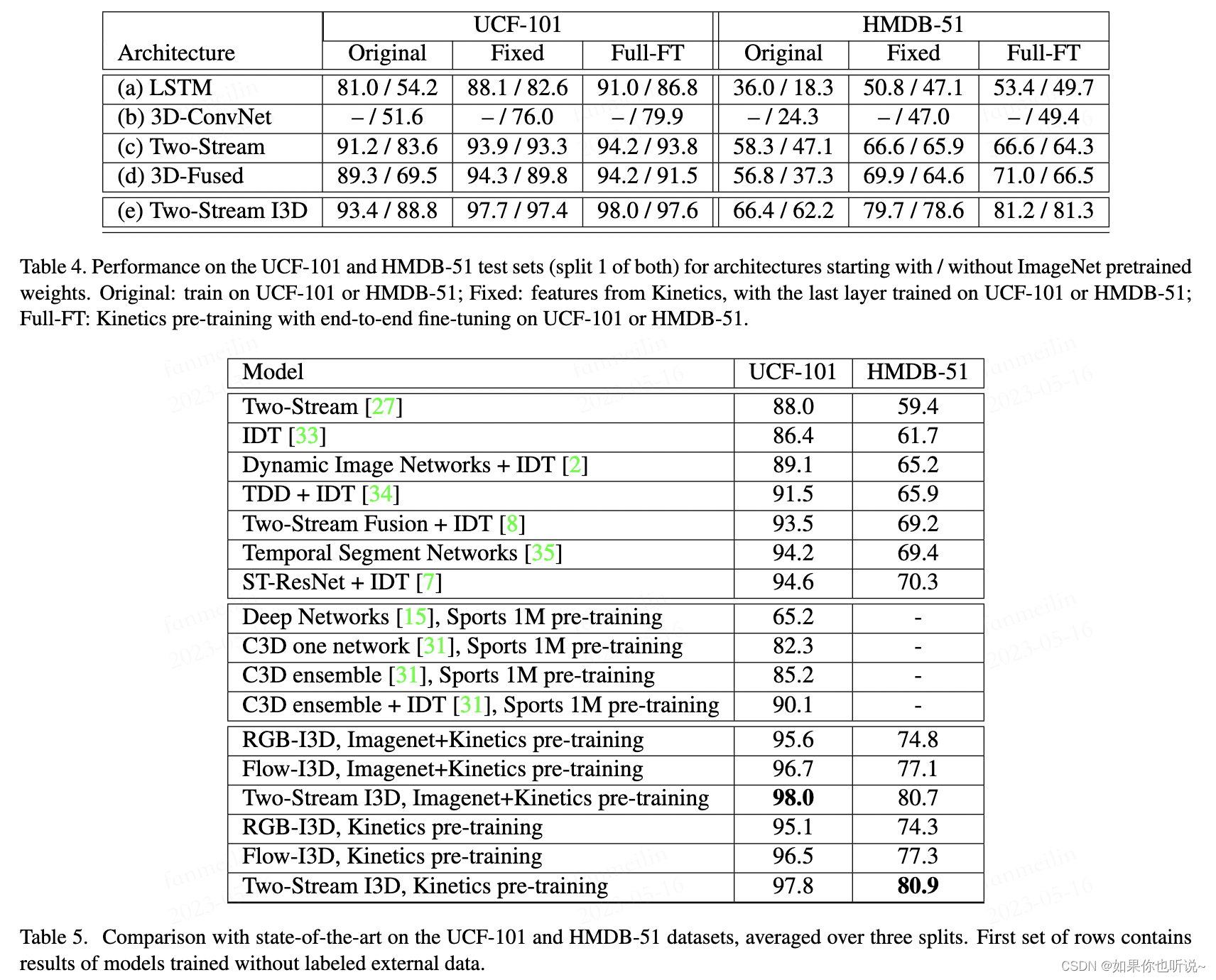
通过Kinetics预训练,再迁移到另外两个数据集上测试,可以看到效果有很大的提升,同时整体微调的方式比之训练了最后一层略好。并且加载Imagenet预训练参数也是一个很好的增益。
局限性
最后说一下局限性,目前研究者发现:
Kinetics数据集有Special heavy的问题,也就是说从视频中抽一帧,单纯进行分类效果也不错,无需太多上下文的信息,模型对时序建模能力的要求并不高。不过总体来说,I3D使得3DConv在视频理解领域的得到重视,在后续跟进的研究中,3DConv网络大放异彩。