💓博主CSDN主页:杭电码农-NEO💓
⏩专栏分类:C语言学习分享⏪
🚚代码仓库:NEO的学习日记🚚
🌹关注我🫵带你学习更多C语言知识
🔝🔝

操作符详解
- 1. 前言🚩
- 2. 移位操作符🚩
- 2.1 右移操作符🏁
- 3. 位操作符🚩
- 4. sizeof和数组🚩
- 5. 隐式类型转换🚩
- 5.1 整型提升的意义🏁
- 6. 操作符的属性🚩
- 6.1 问题表达式🏁
- 7. 总结🚩
1. 前言🚩
我们已经在了解C语言的内一章节熟悉了所有的操作符了解C语言.其实操作符还有一些更细节更有用的延申内容,本章就给大家带来操作符详解!
2. 移位操作符🚩

我们之前介绍过,这里的移位操作符移动的是二进制位
注意:这里的移位操作符的操作数只能是正整数.
比如说:
int a=10;
int b=a>>1;
int c=a<<-1;
这种移动负数位的行为是未定义的,在不同编译器下可能出现不同的情况
2.1 右移操作符🏁
这里的左移操作符很简单,就是左边舍弃,右边补0,然而我们的右移操作符相对比较复杂,首先右移运算分为两种:
- 逻辑移位
左边用0填充,右边丢弃
- 算术移位
左边用原该值的符号位填充,右边丢弃
我们的编译器往往采用的是算术移位
对于逻辑移位来说,比较容易理解,和左移一样直接补0即可,但是这里的算术移位还要分情况:
int main()
{
int a = 15;
//00000000000000000000000000001111 - 原码
//00000000000000000000000000001111 - 反码
//00000000000000000000000000001111 - 补码
int b = -15;
//10000000000000000000000000001111 - 原码
//11111111111111111111111111110000 - 反码(原码的符号位不变,其他位按位取反得到的就是反码)
//11111111111111111111111111110001 - 补码(反码+1就是补码)
//整数在内存中存储的是补码
//计算的时候也是使用补码计算的
return 0;
}
这里我们首先需要知道,数据在内存中存储和运算是用的补码.假设我们将a算术右移1,再将b算术右移1,我们来看看结果:
//移位移动的是补码的二进制序列
int main()
{
int a = 15;
int b = a >> 1;
printf("%d\n", b);//7
printf("%d\n", a);//15
return 0;
}
int main()
{
int a = -15;
int b = a >> 1;
printf("%d\n", b);
printf("%d\n", a);
return 0;
}
结论1:
我们可以打印出这里的第一个 a b和第二个 a b,.我们发现第一个打印的a还是15,这说明这个运算: a>>1对a没有影响(不像a++会让a改变),如果我们想要a的二进制位向右移动,应该写成:a=a>>1
结论2:
当我们打印第二个 a b 时,会发现a等于-8,那么这个-8是怎么来的?这里我们画图来理解:

我们发现最终得到的源码为-8的源码.这里-15向右移动时,左边不是补0,而是补1,因为-15的符号位是1,所以前面补1.
3. 位操作符🚩

这里的按位与&和按位或|大家都比较熟悉了就不多讲解.主要是这个按位异或操作^,两个数对应的二进制位相同为0,相异为1,所以这里我们可以得出一个结论:
- 任何数与0按位异或的结果都是这个数本身
- 任何数按位异或自己本身的结果都为0.
知道了上面的结论后,这里我给出一道非常经典的面试题:不能创建临时变量,交换a和b的值按照我们以往的方法,我们会先将a,b中一个值保存起来然后再挨个赋值,当然我们学到位操作符后有更优解不用创建临时变量:
#include <stdio.h>
int main()
{
int a = 10;
int b = 20;
a = a^b;
b = a^b;
a = a^b;
printf("a = %d b = %d\n", a, b);
return 0;
}
这里我们;来理解一下为什么这样可以交换两个值:

.我们将这几个步骤一一走下来会发现:b的值变成a了,a的值也变成b了.这里就是充分运用了一个数按位异或0和按位异或本身的结论来实现功能
其实这里还有一种解法:大家自行理解:
#include <stdio.h>
int main()
{
int a = 10;
int b = 20;
a=a+b;//a=30
b=a-b;//b=30-20=10=a
a=a-b;//a=30-10=20=b
printf("a = %d b = %d\n", a, b);
return 0;
}
除此之外,这里还有一道很经典的OJ题力扣136题也可以用按位异或做出来,大家可以自己去思考
4. sizeof和数组🚩
这里直接给出一段代码再来理解它们的区别:
#include <stdio.h>
void test1(int arr[])
{
printf("%d\n", sizeof(arr));//(2)
}
void test2(char ch[])
{
printf("%d\n", sizeof(ch));//(4)
}
int main()
{
int arr[10] = {0};
char ch[10] = {0};
printf("%d\n", sizeof(arr));//(1)
printf("%d\n", sizeof(ch));//(3)
test1(arr);
test2(ch);
return 0;
}
这里的(1)(2)(3)(4)分别打印什么呢?先来看(1)(3),我们之前提过,当数组名放在sizeof内部时代表整个数组,所以(1)就代表10个整型的大小.应该为40.(3)也是同理,代表10个字符型的大小,应该是10.
而当我们的数组名作为函数参数传到函数中时,它代表的是数组首元素地址,再将这里的数组名放在sizeof中时,这下就和我们前面的结论不同了,因为这里的数组名已经是首元素地址了,相当于它就是一个地址,而在32位机器中,地址也就是指针所占大小为4个字节,所以这里的sizeof求值相当于求得是指针得大小,就和数组得类型没有关系了,不管你是整型数组还是字符型数组,只是要指针它的大小就是4个字节(32位机器),所以(2)(4)都会打印4或8(64位机器打印8)
5. 隐式类型转换🚩
C的整型算术运算总是至少以缺省整型类型的精度来进行的。为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为整型提升。比如下面这段代码:
char a = 5;
char b = 127;
char c = a + b;
这里的将a和b相加时,系统会自己进行隐式类型转换(就是不会显现出来这种转换),将char类型整型提升至int类型再进行运算.这里我们将它们的二进制码写出来做分析
int main()
{
char c1 = 5;//char类型占一个字节,八个二进制位
//00000000000000000000000000000101
//00000101 - c1 (截断成8个二进制位)
char c2 = 127;
//00000000000000000000000001111111
//01111111 - c2 (截断成8个二进制位)
char c3 = c1 + c2;//进行运算时要整型提升.截断后第一位为0,前面就全部补0
//00000000000000000000000000000101(整型提升后的5)
//00000000000000000000000001111111(整型提升后的127)
//00000000000000000000000010000100(相加后得到的值)并且因为c也是char类型的变量,所以得到最终的值后还要发生截断
//10000100 - c3(截断成8个二进制位)
//%d - 10进制的形式打印有符号的整数
//11111111111111111111111110000100 - 补码
//11111111111111111111111110000011 - 反码
//10000000000000000000000001111100 - 源码-> -124
printf("%d\n", c3);
return 0;
我们总结一下隐式类型转换这个过程发生的事情:
- 第一步: a=5是整型放在char类型中,要从四个字节(32个二进制位)截断到一个字节(8个二进制位),b和a同理
- 第二步: 当a和b相加时,a和b会发生隐式类型转换,暂时变成整型(四个字节),然后a和b作为整型相加后,把值赋值给c
- 第三步: c也是char类型变量,所以a和b相加后的值也要从四个字节截断到一个字节.
- 第四步: printf函数要打印C,并且是按照整型%d打印,所以这里的C还要发生整型提升成四个字节后才能被打印
- 第五步: C在整型提升前的二进制码是:10000100,第一个二进制码是1所以整型提升时,前面的24位二进制位全部补1
当你真正理解了上面的五步,你也许就理解隐式类型转换是怎么回事了!
5.1 整型提升的意义🏁
整型提升的意义:
-
表达式的整型运算要在CPU的相应运算器件内执行,CPU内整型运算器(ALU)的操作数的字节长度
一般就是int的字节长度,同时也是CPU的通用寄存器的长度。 -
因此,即使两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长度。
-
通用CPU(general-purpose CPU)是难以直接实现两个8比特字节直接相加运算(虽然机器指令
中可能有这种字节相加指令)。所以,表达式中各种长度可能小于int长度的整型值,都必须先转
换为int或unsigned int,然后才能送入CPU去执行运算。
并且整形提升是按照变量的数据类型的符号位来提升的 ! ! !
//负数的整形提升
char c1 = -1;
变量c1的二进制位(补码)中只有8个比特位:
1111111
因为 char 为有符号的 char
所以整形提升的时候,高位补充符号位,即为1
提升之后的结果是:
11111111111111111111111111111111
//正数的整形提升
char c2 = 1;
变量c2的二进制位(补码)中只有8个比特位:
00000001
因为 char 为有符号的 char
所以整形提升的时候,高位补充符号位,即为0
提升之后的结果是:
00000000000000000000000000000001
//无符号整形提升,高位补0
return 0;
}
6. 操作符的属性🚩
复杂表达式的求值有三个影响的因素。
- 操作符的优先级
- 操作符的结合性
- 是否控制求值顺序。
两个相邻的操作符先执行哪个?取决于他们的优先级。如果两者的优先级相同,取决于他们的结合性。
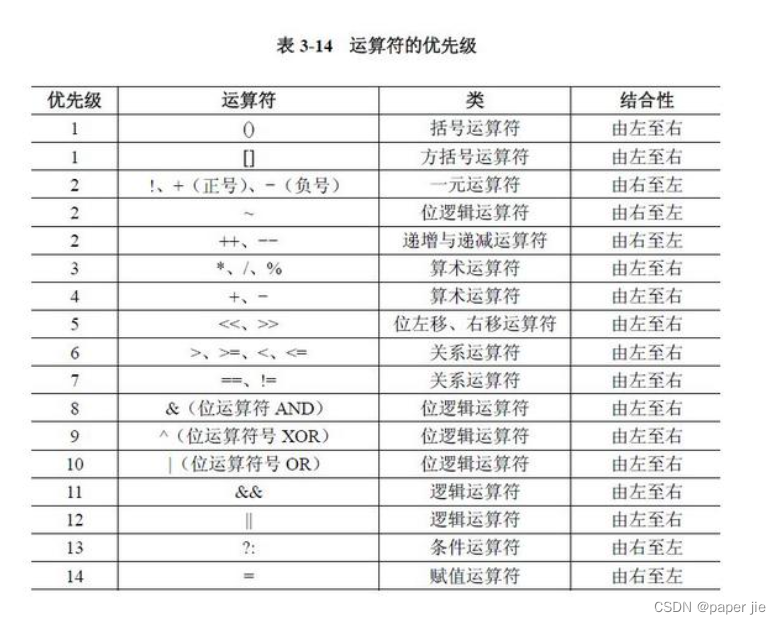
操作符优先级
这里我给出一个博客链接,大家可以去看看操作符的优先级和结合性:操作符的优先级和结合性
值得注意的是,这个表格不用全文背诵,当你要用到时可以随时查表,或者你自己不确定优先级时可以根据你的目的加上相应的括号
6.1 问题表达式🏁
即使我们知道了操作符的优先级和操作符的结合性,有些表达式的值也可以得到不同的答案,比如很经典的:
int c = 5;
int a = c + --c;
这段代码在不同编译器下求出的值可能是不一样的,因为操作符的优先级只能决定自减–的运算在+的运算的前面,但是我们并没有办法得知,+操作符的左操作数的获取在右操作数之前还是之后求值,所以结果是不可预测的,是有歧义的。
我们知道这里得加号是从右至左结合得,所以先算–c,但是前面的C你并不知道它是一开始就放进去的5还是C–之后才放进去的4 !
亦或者这段代码:
int main()
{
int i = 10;
i = i-- - --i * ( i = -3 ) * i++ + ++i;
printf("i = %d\n", i);
return 0;
}
它在不同编译器下的结果:
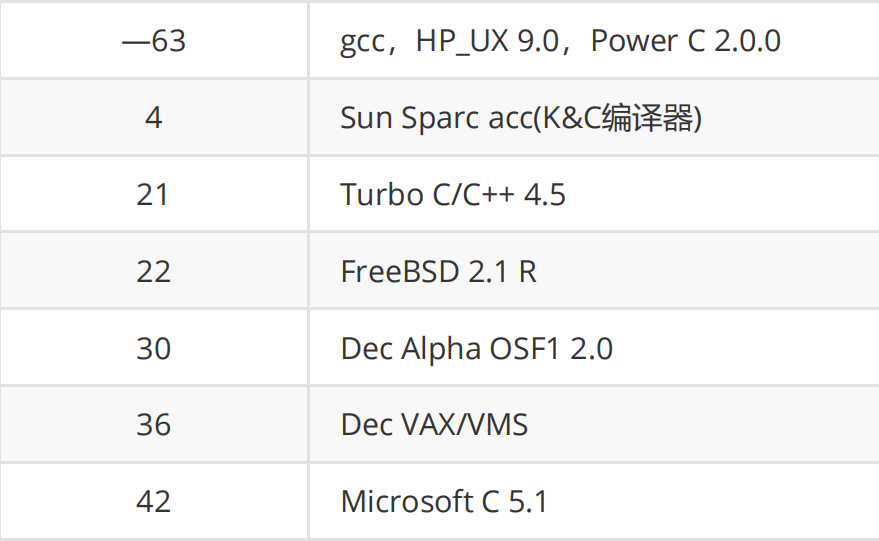
总结:我们写出的表达式如果不能通过操作符的属性确定唯一的计算路径,那这个表达式就是存在问题的。这种代码是非法表达式,我们在写代码的时候宁愿多写几行也不能写成这样图快 ! ! !
7. 总结🚩
操作符这一模块使用的还是很频繁的,有些看起来很麻烦的问题用操作符的手法来解决可能异常简单
💕 我的码云:gitee-杭电码农-NEO💕