背景
其实在使用正则表达式之前,我们在查找文件之类的,已经用过类似正则表达式的符号,例如:
// 匹配多个任意字符
ls *.js
// 只匹配一个任意字符
ls ?.js
这种方法很有用但也是有限的,而正则表达式则更加的完整、强大。
简单的例子
"0123abc".match(/^[0-9]+abc$/) // 0123abc
- ^ 为匹配输入字符串的开始位置。
- [0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
- abc$ 匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置。
在 js 中,我们不仅可以使用 match,这里列举了和正则相关的一些函数:js:正则表达式常用方法总结test、exec、match、matchAll、replace、replaceAll、search
语法
所有特殊符号
// 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。
.
// 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。[\s\S]
\s\S
// 匹配字母、数字、下划线。等价于 [A-Za-z0-9_],[\w]
\w
// 捕获组,获取一个匹配的元素,使用 match、exec 等函数可以拿到
()
// 匹配前面的子表达式零次或多次。
*
// 匹配前面的子表达式1次或多次。
+
// 匹配前面的子表达式0次或1次。
?
// 转义
\
// 正则的开始和结尾(可以省略),如果^在[]中使用代表非
^$
// 标记限定符表达式
{
// 中括号表达式
[
// 或
|
普通字符
匹配含有 hwl 字符
// ['h', 'l', 'l', 'w', 'l']
"hello world".match(/[hwl]/g)
匹配不含有 hwl 字符
// ['e', 'o', ' ', 'o', 'r', 'd']
"hello world".match(/[^hwl]/g)
配置字母数字
[a-z]
[A-Z]
[a-zA-Z0-9]
[a-zA-Z0-9_]
限定符
// 匹配前面的子表达式零次或多次。
*
// 匹配前面的子表达式1次或多次。
+
// 匹配前面的子表达式0次或1次。
?
// 标记限定符表达式
{n}
{n,}
{n,m}
举例:
// 第一个数字为1-9,后面的数字为0-9
/[1-9][0-9]*/
*+ 是贪婪的,会尽可能的匹配更多文字,只有在他们后面加上一个 ? 可以实现最小匹配,举例:
想要匹配包含 h1 的整个文字。
// 贪婪
"<h1>hello world</h1>".match(/<.*>/g)
// 非贪婪
"<h1>hello world</h1>".match(/<.*?>/g)
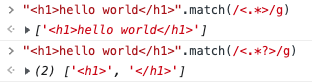
使用贪婪,会尽可能多的匹配最后一个符合条件的元素,所以匹配到了满足 . 并且最后一个以 > 结尾的元素,使用非贪婪则取最近一个。
选择符
()
这个在js:正则表达式常用方法总结test、exec、match、matchAll、replace、replaceAll、search有详细的举例。
修饰符
// 不区分大小写
i
// 全局匹配
g
// 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。
m
// 默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。
s
举例
常用正则汇总