社会关系抽取赛题提交指南
一、赛题背景
本次主要为大家介绍社会科学计算大赛的赛题之一---社会关系抽取。
1.技术发展
- 关系抽取(Relationship Extraction, RE)是信息抽取的一个重要任务,其目标是从文本中抽取实体之间的关系。RE技术发展历程主要有以下几个阶段:
- 1. 规则与模板匹配阶段。早期的RE系统主要依赖人工构建的规则和模板来识别关系,代表系统包括FASTUS、SRV等。这类方法高度依赖领域知识,移植性差,不适合大规模应用。
- 2. 特征工程阶段。随着机器学习的发展,特征工程阶段的RE系统开始应运而生,依靠NLP特征与机器学习算法识别关系,代表系统包括 minipar、Snowball等。这类方法效果有所提高,但特征工作量较大,探索效率较低。
- 3. 核方法阶段。21世纪初,核方法在机器学习领域获得广泛应用,核方法也被引入RE任务,利用多类分类与回归方法进行关系分类,代表系统包括SVM-RBF、SVR等。这类方法在多个数据集上取得了最先进的成绩。
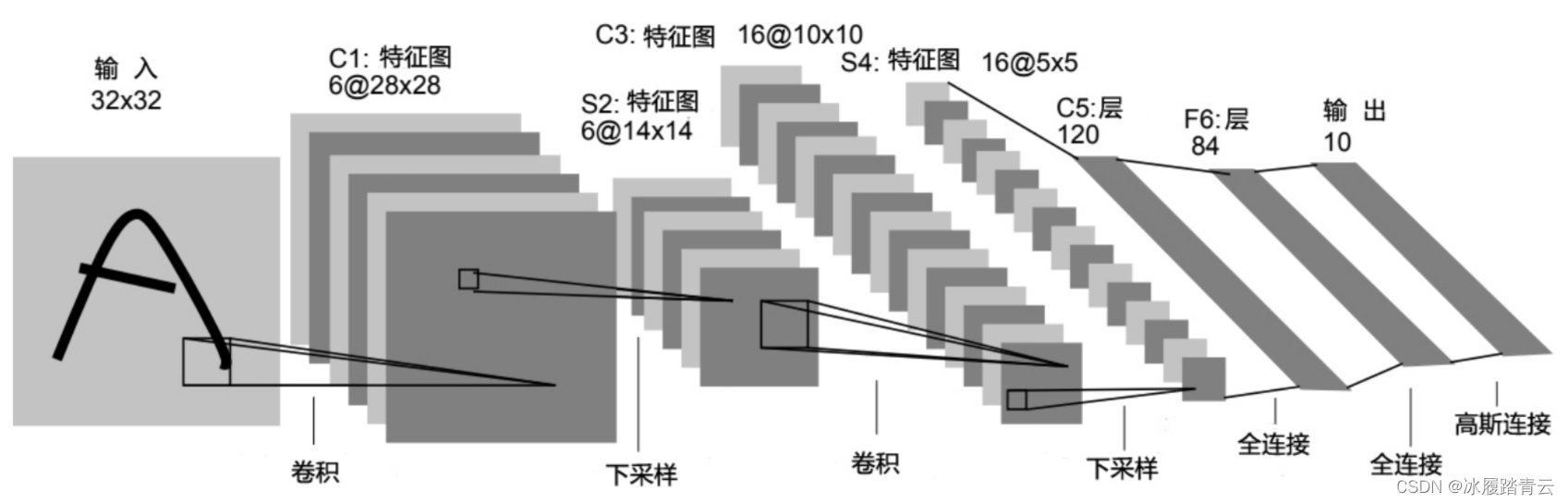
- 4. 神经网络方法阶段。近年来,深度学习技术飞速发展,各种神经网络也被广泛应用与NLP任务,RE也不例外。基于CNN、RNN和注意力机制的深度神经网络已成为RE的主流建模方法,代表系统包括CNN、LSTM、BiLSTM、BERT等。这类方法在多个RE数据集上取得了state-of-the-art的结果。
- 5. 迁移学习与多任务学习阶段。最新阶段的RE方法开始考虑不同类型关系间的内在关联,采用迁移学习与多任务学习的思想,让RE模型可以在学习一种关系的同时学习到其他关系的知识,从而提高整体效果。这是RE技术发展的新趋势。
所以,RE技术发展经历了规则到深度学习,从单任务到迁移学习的过程。随着模型与技术的发展,RE系统的效果也在持续提高。
2.技术难点
- 由于现实世界中关系比较复杂多样,隐式的间接的关系容易忽略并且关系数据相较于实体数据更为稀疏,因此关系识别比较困难。在本次比赛中使用迁移学习来泛化在新数据上的关系识别,推荐大家借鉴迁移学习的思路来训练模型。
二、赛题baseline
如果你选择的是关系抽取的baseline,那么可以看这份指南
步骤一:在官网下载、组建队伍、报名Mo-人工智能开发教程,AI人工智能编程培训,培训平台/机构/课程,在线学习AI编程,一蓦官网.
步骤二:选择关系抽取的赛道,进入环境,等待初始化完成
步骤三:在左侧目录栏中选择main.ipynb,阅读main.ipynb中的代码
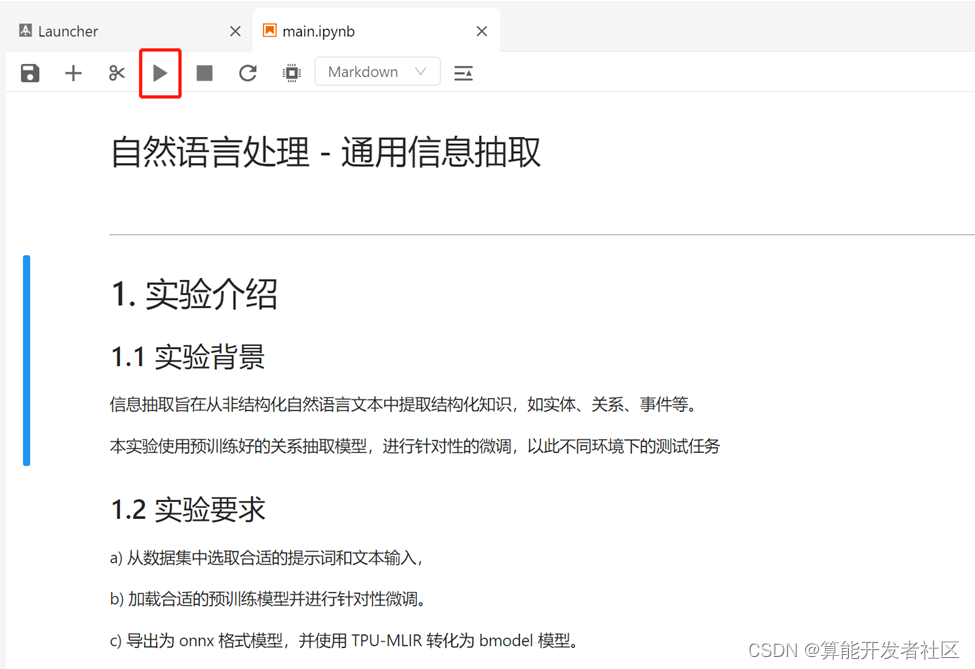
步骤四:使用Shift+Enter依次运行每一个代码块
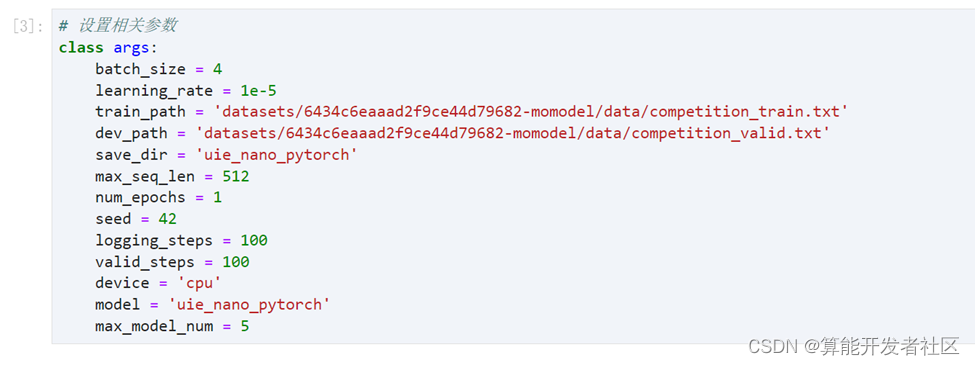
步骤五:可以根据自己实际的情况,设置相关参数,这里为了简便起见,将num_epochs设置为1
步骤六:运行训练的cell,开始对预训练模型进行微调
步骤七:微调完毕之后可以在uie_nano_pytorch下看到训练好的模型
步骤八:继续运行cell,将torch模型转换为onnx模型
步骤九:可以在uie_nano_pytorch下面看到导出的inference.onnx
步骤十:开始进行onnx转bmodel,首先开一个新的terminal 
切换到convert目录下,执行以下四行代码

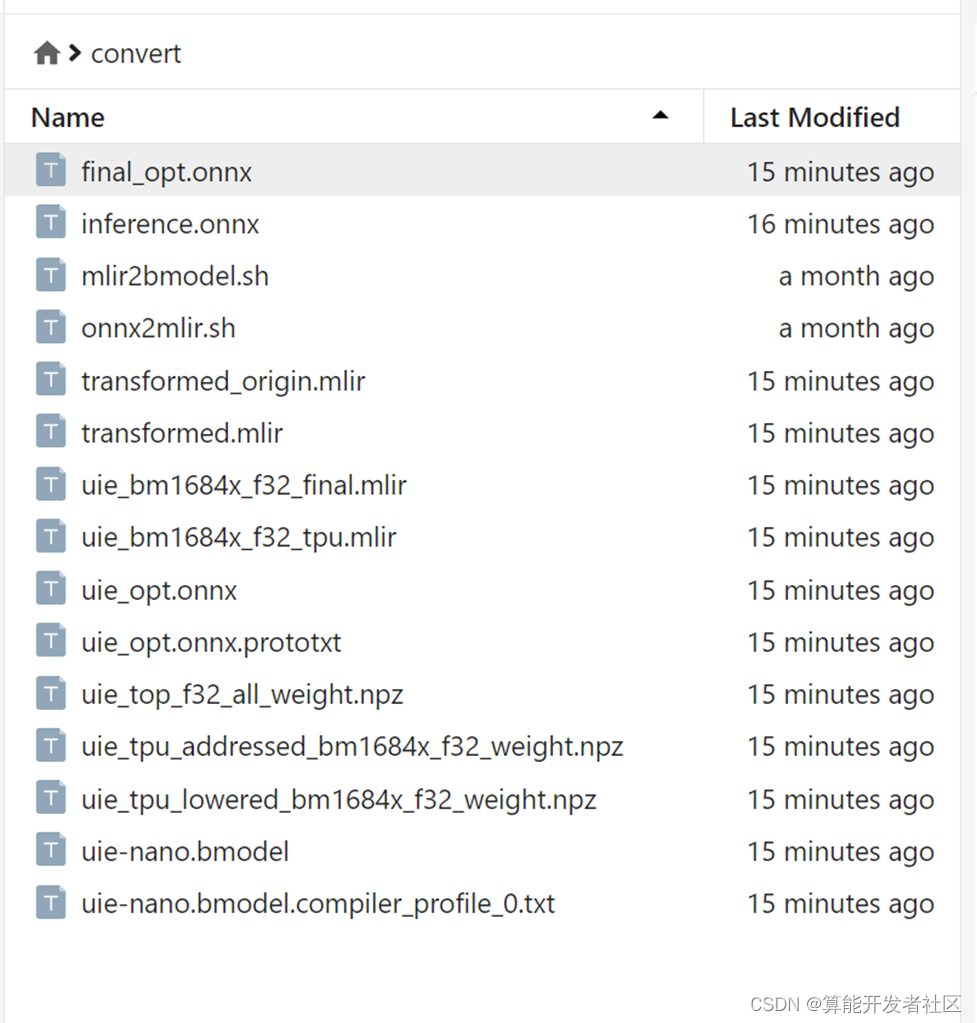
步骤十一:之后你就可以在convert目录下看到bmodel文件
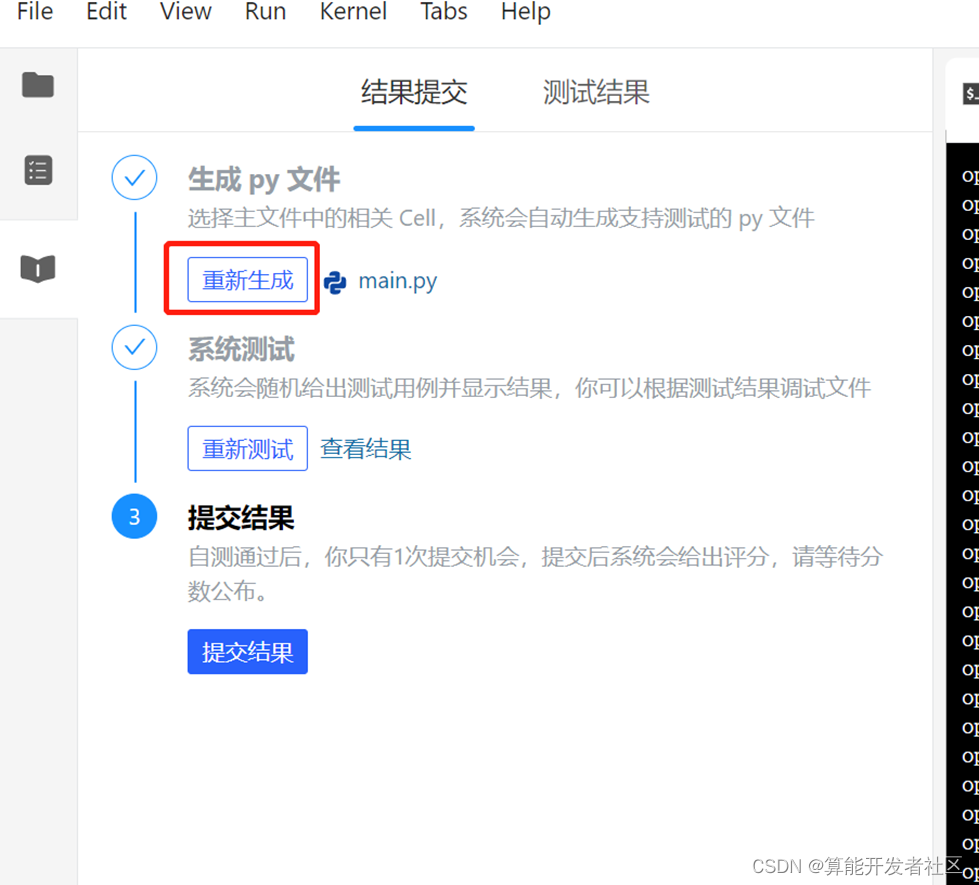
步骤十二:现在我们开始提交,首先我们点击提交,并生成提交文件
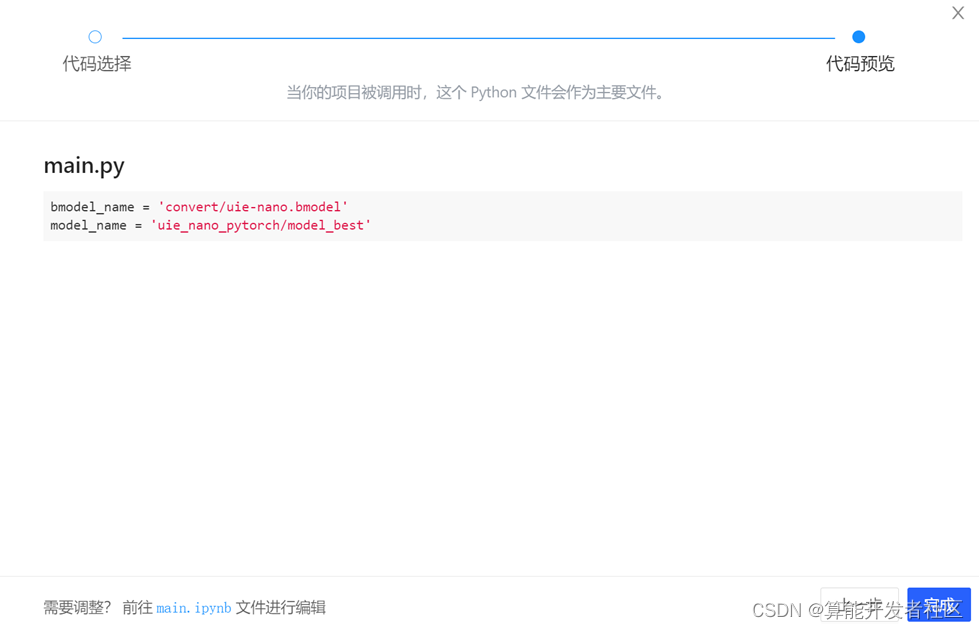
步骤十三:选择main.ipynb文件,我们只提交最后一个cell

 步骤十四:之后进行测试,我们全部勾选
步骤十四:之后进行测试,我们全部勾选
步骤十五:测试完成之后就可以开始提交了~
步骤十六:你也可以生成py文件,使用GPU来进行模型的训练
三、赛题提交
当你完成以上任务后,你就可以准备提交了。提交清单如下:
• 转换的bmodel模型文件
• 包含 bmodel_name 和 model_name 的 main.py 文件
- 其他相关模型权重及文件
接下来你可以点击项目左侧的测试按钮,查看模型是否通过接口测试以及在测试集上的分数。需要提醒大家一点,模型的测试次数每天是没有限制的,可以测试无数次,不断地提高自己模型的表现。模型的推理环境是一个 CPU 环境,推理使用的模型为转换之前的原始模型文件,而非 bmodel 格式的模型。
当您完成测试,认为模型已经满足自己的预期时,就可以进行提交。
请注意,初赛截止日期为5月26日,初赛过程中只有一次提交机会,因此需要选手们慎重考虑。我们建议您在提交前仔细检查模型的结果,确保其准确性和完整性。