Mysql窗口函数
- 🌾Mysql窗口函数
- 🕊️一、什么是窗口函数
- 🍃1、怎么理解窗口?
- 🍃2、什么是窗口函数
- 🍵1. 基本语法:
- 🍵2. 窗口函数多用在什么场景?主要有以下两类:
- 🍵3. 我们常见的窗口函数和聚合函数有这些:
- 🍵4. 窗口函数和普通聚合函数的区别?
- 🕊️二、窗口函数的练习
- 🍃1、序号函数
- 🍃2、分布函数:
- 🍃3、前后函数
- 🍃4、首尾函数
- 🍃5、其他函数
- 🕊️三、实战
🌾Mysql窗口函数
本文主要介绍了MySQL窗口函数的定义和具体使用。
首先窗口函数是从MySQL8.0开始支持的,如果现在使用的是MySQL5.0或者8.0一下的版本,那么非常遗憾,建议搞个8.0版本试一试,哈哈~
🕊️一、什么是窗口函数
🍃1、怎么理解窗口?
搞清楚窗口代表着啥,才知道什么时候该用它。
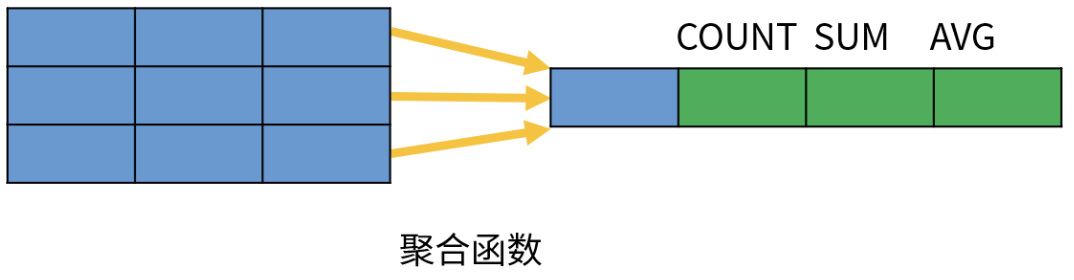
窗口函数是相对于聚函数来说的。
- 聚合函数是对一组数据计算后返回单个值(即分组)。
- 非聚合函数一次只会处理一行数据。
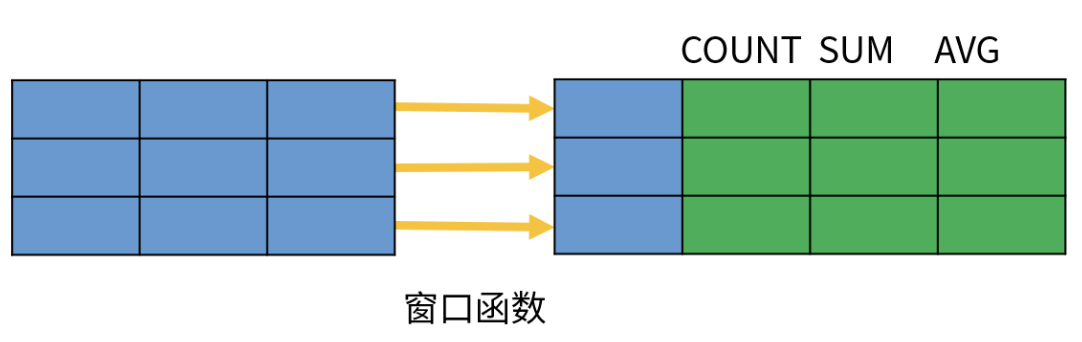
- 而窗口函数在行记录上计算某个字段的结果时,可将窗口范围内的数据输入到聚合函数中,并不改变行数。
根据上面所说,准备如下员工表信息数据
-- 员工表
create table if not exists sql_niukewang.`employee`
(
`eid` int not null auto_increment comment '员工id' primary key,
`ename` varchar(20) not null comment '员工名称',
`dname` varchar(50) not null comment '部门名称',
`hiredate` date not null comment '入职日期',
`salary` double null comment '薪资'
) comment '员工表';
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('傅嘉熙', '开发部', '2022-08-20 12:00:04', 9000);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('武晟睿', '开发部', '2022-06-12 13:54:12', 9500);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('孙弘文', '开发部', '2022-10-16 08:27:06', 9400);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('潘乐驹', '开发部', '2022-04-22 03:56:11', 9500);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('潘昊焱', '人事部', '2022-02-24 03:40:02', 5000);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('沈涛', '人事部', '2022-12-14 09:16:37', 6000);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('江峻熙', '人事部', '2022-05-12 01:17:48', 5000);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('陆远航', '人事部', '2022-04-14 03:35:57', 5500);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('姜煜祺', '销售部', '2022-03-23 03:21:05', 6000);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('邹明', '销售部', '2022-11-23 23:10:06', 6800);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('董擎苍', '销售部', '2022-02-12 07:54:32', 6500);
insert into sql_niukewang.`employee` (`ename`, `dname`, `hiredate`, `salary`) values ('钟俊驰', '销售部', '2022-04-10 12:17:06', 6000);

我们举个例子:分别使用聚合函数sum()和窗口函数sum()来根据部门求和看下两者区别
select
dname,sum(salary) sum
from employee group by dname;

select
dname,salary,
sum(salary) over(partition by dname order by salary) sum
from employee;

通过观察,正如之前所说,窗口函数相对聚合函数,聚合函数是将一组数据计算后返回单个值,而窗口函数在行记录上计算某个字段的结果时,可将窗口范围内的数据输入到聚合函数中,并不改变行数,就好比如我们刚刚根据部门开窗求和salary薪资,每一行的sum数据是将前面范围内的数据都聚合到当前结果中。
所以可见,窗口就是范围的意思,可以理解为一些记录(行)的集合;窗口函数也就是在满足某种条件的记录集合上执行计算的特殊函数。

🍃2、什么是窗口函数
窗口函数也叫
OLAP函数(Online Anallytical Processing),可以对数据进行实时分析处理。
🍵1. 基本语法:
<窗口函数> OVER (PARTITION BY <用于分组的列名> ORDER BY <用于排序的列名>);
-- over关键字用于指定函数的窗口范围,
-- partition by 用于对表分组,
-- order by子句用于对分组后的结果进行排序。
注意:窗口函数是对
where或者group by子句处理后的结果再进行二次操作,因此会按照SQL语句的运行顺序,窗口函数一般放在select子句中(from前),例如上一条SQL,可以往上拖着看看~
🍵2. 窗口函数多用在什么场景?主要有以下两类:
- 排名问题,例如:查包子铺利润月排名;
- TOPN问题,例如:查每种包子利润最高的两个月;
🍵3. 我们常见的窗口函数和聚合函数有这些:
- 专用窗口函数:
rank(),dense_rank(),row_number() - 聚合函数:
max(),min(),count(),sum(),avg()
窗口函数都有哪些?
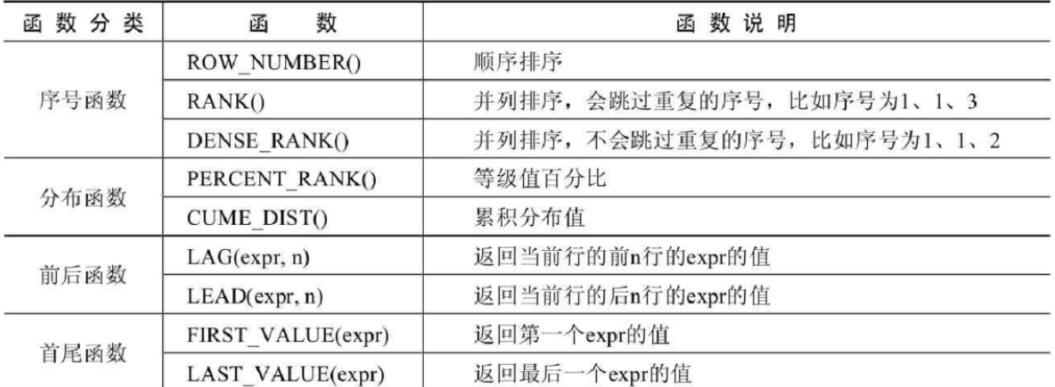

- 序号函数:row_number() / rank() / dense_rank()
- 分布函数:percent_rank() / cume_dist()
- 前后函数:lag() / lead()
- 头尾函数:first_val() / last_val()
- 其他函数:nth_value() / nfile()
🍵4. 窗口函数和普通聚合函数的区别?
因为聚合函数也可以放在窗口函数中使用,因此窗口函数和普通聚合函数也很容易被混淆,二者区别如下:
聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,有几条记录执行完还是几条。- 聚合函数也可以用于窗口函数中,这个我会举例说明。
🕊️二、窗口函数的练习
还是使用上面的员工表信息完成下面的练习。
🍃1、序号函数
序号函数有:ROW_NUMBER、RANK、DENSE_RANK,也就是序号排名的意思。
ROW_NUMBER():顺序排序 —— 1、2、3
RANK():并列排序,跳过重复序号 —— 1、1、3
DENSE_RANK():并列排序,不跳过重复序号 —— 1、1、2
**应用场景:**求每个部门的员工薪资排名
- ROW_NUMBER()函数
select
dname,salary,
row_number() over(partition by dname order by salary) sum
from employee;

- RANK()函数
select
dname,salary,
rank() over(partition by dname order by salary) ranking
from employee;

- DENSE_RANK()函数
select
dname,salary,
dense_rank() over(partition by dname order by salary) ranking
from employee;

总结:
上面针对同一个应用场景使用三种不同的序号函数,得到三种不同的结果,我们重点需要注意在三种结果的区别。
row_number()函数只是做一个顺序排序 —— 1、2、3…rank()函数做了顺序排序,但是做了并列排序,并跳过重复序号 —— 1、1、3dense_rank()函数
🍃2、分布函数:
分布函数有:percent_rank() 、 cume_dist()
cume_dist():分组内小于、等于当前rank值的行数 / 分组内总行数
percent_rank():每行按照公式(rank-1) / (rows-1)进行计算
- CUME_DIST()函数
**应用场景:**查询小于等于当前薪资(salary)的比例
select
dname,ename,salary,
rank() over(partition by dname order by salary) ranking,
cume_dist() over(order by salary) dist1,
cume_dist() over(partition by dname order by salary) dist2
from employee;

这里使用了序号函数 row_number(),目的是为了更好的理解分布函数的cume_dist()函数。
cume_dist()函数作用是分组内小于、等于当前rank值的行数 / 分组内总行数,如上结果人事部的rank值为4行,
<=5000的rank值行数为2,分组内总行数为4,所以cume_dist的值=(2/4)=0.5。
以此类推,下面的结果都是这样的。
注意:没有使用partition by 分组的默认是所有数据为一组,比如上面的dist1列的数据
- percent_rank()函数
用途:每行按照公式(rank-1) / (rows-1)进行计算。
其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数
应用场景:不常用
select
dname,ename,salary,
rank() over(partition by dname order by salary) ranking,
percent_rank() over(partition by dname order by salary) per
from employee;

/*
per:
第一行: (1 - 1) / (4 - 1) = 0
第二行: (1 - 1) / (4 - 1) = 0
第三行: (3 - 1) / (4 - 1) = 0.6666666666666666
第四行:(4 - 1) / (4 - 1) = 1
*/
由上面的注释我们可以理解percent_rank()函数的使用,我们可以把它转换为
- 如果是升序排列,前面比你小的还有多少
- 如果是降序排列,前面比你大的还有多少
应用场景不是很多,但是咱们也可以学习一下,万一以后遇到了也知道之前好像接触过~
🍃3、前后函数
前后函数有:LAG、LEAD
LAG(expr,n):返回位于当前行的前n行
LEAD(expr,n):后n行的expr的值
- 返回当前行的前n行(本组)的expr值
- lag允许你在每一个分组内, 从当前行向前看n行数据
- n(也叫offset)是从当前行偏移的行数,以获取值。offset必须是一个非负整数。如果offset为零,则LAG()函数计算当前行的值。如果省略 offset,则LAG()函数默认使用n=1, 向前看一个数据。
- LAG(expr,n)前函数
应用场景:求各部门内部相邻组员的薪资差
第一步:先使用前函数查出前一个员工薪资
select dname,ename,salary,
lag(salary,1) over(partition by dname order by salary) presalary from employee;

第二步:把第一步的结果作为表进行查询,并做-运算
select * ,(salary-presalary) from (
select dname,ename,salary,
lag(salary,1) over(partition by dname order by salary) presalary from employee
) pre_table;

- LEAD(expr,n)后函数
应用场景:求各部门内部相邻组员的薪资差
其实和上面的LAG函数一样,只不过就是一个是向上偏移,一个是向下偏移。
第一步:先使用前函数查出后一个员工薪资
select dname,ename,salary,
lead(salary,1) over(partition by dname order by salary) presalary from employee;
第二步:把第一步的结果作为表进行查询,并做-运算
select * ,(salary-presalary) from (
select dname,ename,salary,
lead(salary,1) over(partition by dname order by salary) presalary from employee
) pre_table;

总结:对于前后函数,向前还是向后偏移大家可以灵活使用。
🍃4、首尾函数
首尾也叫头尾函数,有first_value(expr) 、last_value(expr)
first_value(expr):取分组排序后,截止到当前第一个值
last_value(expr):取分组排序后,截止到当前最后一个值
需求:截止到当前,按照日期排序查询第1个入职和最后1个入职员工的薪资
first_value(expr)函数
select * ,first_value(salary) over(partition by dname order by hiredate) first from employee;

last_value(expr)函数和first_value(expr)函数是一样的,这里就不再模拟演示了。
🍃5、其他函数
NTH_VALUE(expr, n)、NTILE(n)
NTILE(n):将分区中的有序数据分为n个等级,记录等级数
NTH_VALUE(expr, n):返回窗口中第n个expr的值。expr可以是表达式,也可以是列名
- ntile(n)函数
需求:将每个部门员工按照入职日期分成2组
select * ,
ntile(2) over(partition by dname order by hiredate) `group`
from employee;

- nth_value(expr,n)函数
需求:截止到当前薪资,显示每个员工的薪资中排名第2或者第3的薪资
select * ,
nth_value(salary,2) over(partition by dname order by hiredate) twoSalary ,
nth_value(salary,3) over(partition by dname order by hiredate) threeSalary
from employee;

🕊️三、实战
- 牛客网:[SQL33 找出每个学校GPA最低的同学](找出每个学校GPA最低的同学_牛客题霸_牛客网 (nowcoder.com))
还有其他的,比如说力扣上等等,这里之举个例子,没事多可以刷刷

【数据库基础】数据库介绍和三大范式
【数据库基础】MySQL增删改查基础操作命令
【数据库高级】数据完整性和多表查询
【数据库】事务
【数据库高级】Mysql窗口函数的使用和练习