数字信号
连续时间信号:在连续时间范围内定义的信号,信号的幅度可以是连续的(模拟信号),也可以是离散的
离散时间信号:时间为离散变量的信号,即独立变量时间被量化了,而幅度仍是连续变化的
数字信号:时间离散并且幅度量化的信号,如果是二进制量化,只有1,0两种模式的信号。四进制数字信号只有四种取值,以此类推。数字信号幅度只取几个量化的值代替区间。
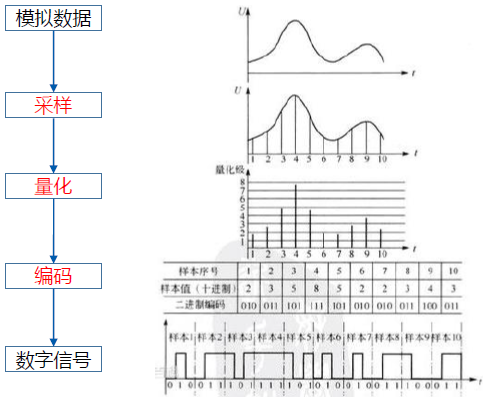
采样
采样率:每秒从连续信号中提取并组成离散信号的采样个数。用Hz表示,采样频率的倒数是相邻采样点之间的时间间隔。
采样定理(奈奎斯特采样定理):只有采样频率高于声音信号最高频率的两倍时,才能把数字信号表示的声音还原成为原来的声音。所以语音信号最大能够达到的最高频率等于采样率的一半。
举例:如果有两个频率分别为20 Hz的语音和一个20 KHz的语音,我们以44.1KHz的采样率对语音进行采样。(采样频率和语音频率单位虽然都是Hz,但是不同,注意区别)
结果:20Hz语音每次振动被采样了40K/20=2000次;
20KHz语音每次振动被采样了40K/20k=2次;
所以在相同的采样率下,记录低频的信息远远比高频的详细。混叠(欠采样):当采样频率小于最大截止频率两倍(奈奎斯特频率)的时候就会发生信号重叠,大白话就是我的信号是8kHz的频率,你却没有用16kHz的采样频率来采样,导致了我产生了混叠。
为了避免混叠现象,通常采用两种措施:
- 提高语音采样率: 到信号最高频率的两倍以上;
- 频率高于采样率一半的信号:通过抗混叠滤波器(低通滤波器) 滤除频率高于采样率一半的信号
下采样:以x(2n)为例,是以低一倍的抽样率从x(n)中每隔两点取一点,通常在抽取之前要加入一个防混叠的滤波器
上采样:以x(n/2)为例,在语音信号每两个点之间插入一个值,因为我们不知道这个插入的值是多少,一般插0,本身信息并没有增加,通常在插值之后我们还需要一个平滑,也就是在插入这些零点之后,后接一个平滑滤波器,利用相邻采样点之间的取值,把插入的值算出来。
量化
采样后的离散信号在振幅维度依然是连续的,需要经过量化才能变成数字信号,数字信号只取几个量化值代替离散信号的振幅区间。转变成数字信号后的语音信号,降低了对硬件传输和存储的要求,便于用到复杂的算法中进行计算和分析语音声学特性,并且还提高了在传输过程中的抗干扰能力、可靠性和保密性。但是,量化值和离散值之间存在一定的量化失真,会对语音信号产生类似于白噪声的干扰,在听觉表现上会出现“沙沙”声。
由于语音信号的频率不一,且量化位数和语音信噪比直接挂钩,在数字电话系统中,通常会使用“A-law”[49]或“u-law”[50,51]量化编码机制,其中“A-law”主要在欧洲使用,“u-law”主要在北美和日本使用,在低频部分语音变化小,使用较大的量化间隔,在高频部分语音变化大,使用较小的量化间隔,当语音量化分级越多时,量化失真越小。
编码
多进制量化语音信号需要在电子设备上进行传输、存储和计算,要先进行二进制编码,使用位深表示每个采样点中的信息比特数,通常麦克风的量化位深为8 比特、16 比特、24 比特和32 比特。通常使用8 比特量化位深,因此通常手机通话时麦克风采集语音的量化位深也为8 比特。
数字和模拟频率
人声的频谱范围是20Hz~20kHz,工程上信号分为 数字频率w和模拟频率f(角频率)。
其中fs是采样率,我们常说的频率就是模拟频率(Hz)。
模拟频率还有一个概念模拟角频率 Ω,单位弧度/秒(rad/s),在单位圆中转动一圈角度变化2π,旋转f圈对应2πf的弧度。
弧度转角度:弧度 * 180/π
角度转弧度:角度 * π/180
带宽(也称频带):语音的频率范围,最高频率等于采样频率的一半。
语谱图和频谱图
语音波形图
波形图表示语音信号的响度随时间变化的规律,横坐标表示时间,纵坐标表示声音响度,我们可以从时域波形图中观察语音信号随时间变化的过程以及语音能量的起伏
import matplotlib.pyplot as plt
import numpy as np
import librosa
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示符号
fs = 16000
audio, _ = librosa.load("./p225_001.wav", sr=fs)
audio = audio[5920:15000]
time = np.arange(0, len(audio)) * (1.0 / fs)
plt.title("语音信号", fontsize=14)
plt.plot(time, audio, color='C0')
plt.xlabel("时间/s", fontsize=14)
plt.ylabel("振幅", fontsize=14)
plt.tight_layout()
plt.show()
频谱图和相位图
频谱图(也称为频响图)表示语音信号的幅度随频率变化的规律,信号频率与能量的关系用频谱表示,频谱图的横轴为频率,纵轴为频率的强度(功率),以dB为单位
import matplotlib.pyplot as plt
import numpy as np
import librosa
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示符号
fs = 16000
audio, _ = librosa.load("../wav_data/p225_001.wav", sr=fs)
time = np.arange(0, len(audio)) * (1.0 / fs)
plt.subplot(2, 2, 1)
plt.title("(a) 幅度谱图")
plt.magnitude_spectrum(audio, Fs=fs, color='C1')
plt.xlabel("频率", fontsize=13)
plt.ylabel("幅度 (能量)", fontsize=13)
plt.subplot(2, 2, 2)
plt.title("(b) 对数幅度谱图")
plt.magnitude_spectrum(audio, Fs=fs, scale='dB', color='C1')
plt.xlabel("频率", fontsize=13)
plt.ylabel("幅度 (dB)", fontsize=13)
plt.subplot(2, 2, 3)
plt.title("(c) 相位谱图")
plt.phase_spectrum(audio, Fs=fs, color='C2')
plt.xlabel("频率", fontsize=13)
plt.ylabel("相位 (弧度)", fontsize=13)
plt.subplot(2, 2, 4)
plt.title("(d) 角谱图")
plt.angle_spectrum(audio, Fs=fs, color='C2')
plt.xlabel("频率", fontsize=13)
plt.ylabel("角度 (弧度)", fontsize=13)
plt.tight_layout()
plt.show()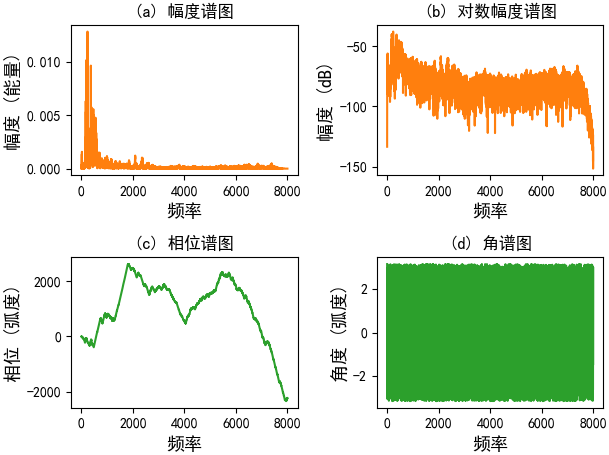
语谱图
横坐标是时间,纵坐标是频率,坐标点值为语音数据能量,能量值的大小是通过颜色来表示的,颜色越深表示该点的能量越强。一条条横方向的条纹,称为“声纹”。它因人而异,即不同讲话者语谱图声纹是不同的,因而可以用声纹鉴定不同的讲话人。语谱图中的花纹有横杠、乱纹和竖直条等,横杠是和时间轴平行的几条深色带纹,它们相应于短时谱中的几个凸出点,即共振峰,有没有横杠出现是判断它是否是浊音的重要标志。
import matplotlib.pyplot as plt
import matplotlib
import librosa
from matplotlib.ticker import FuncFormatter
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示符号
fs = 16000
audio, _ = librosa.load("../wav_data/p225_001.wav", sr=fs)
fig = plt.figure()
norm = matplotlib.colors.Normalize(vmin=-200, vmax=-40)
ax_1 = plt.subplot(1, 1, 1)
plt.title("语谱图", fontsize=14)
plt.specgram(audio, Fs=fs, scale_by_freq=True, sides='default', cmap="jet", norm=norm)
plt.xlabel('时间/s', fontsize=14)
plt.ylabel('频率/kHz', fontsize=14)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
# 左、底、右、高 设置colorbar位置
cbar_ax = fig.add_axes([0.92, 0.115, 0.015, 0.76])
plt.colorbar(norm=norm, cax=cbar_ax) # -200 -50
# https://blog.csdn.net/monotonomo/article/details/83826621
def formatnum(x, pos):
return '$%d$' % (x / 1000)
formatter = FuncFormatter(formatnum)
ax_1.yaxis.set_major_formatter(formatter)
# plt.tight_layout()
plt.show()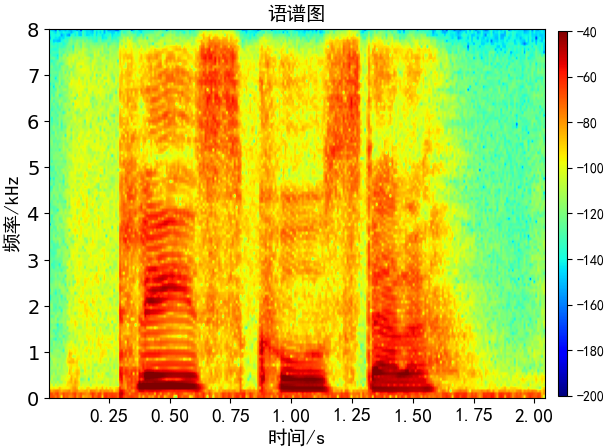
频谱图和语谱图的区别:
- 语谱图表示不同时间内不同频率的能量分布
- 频谱图表示的是不同频率下语音的能量分布
咱们趁热打铁,再来看看对比一下,了解一下幅度谱、相位谱、实部谱和虚部谱图
import librosa
import numpy as np
import scipy.signal as signal
import matplotlib.pyplot as plt
# 读取音频文件
from matplotlib.ticker import FuncFormatter
sr = 16000
wav = librosa.load("../wav_data/p225_001.wav", sr=sr)[0]
frequencies, times, stft = signal.stft(wav, sr, window='hann', nperseg=512, noverlap=256)
print(frequencies.shape, times.shape, stft.shape) # (257,) (130,) (257, 130)
# 计算幅度谱和相位谱
amplitude = np.abs(stft)
phase = np.angle(stft)
# 计算实数谱和虚数谱
real_part = np.real(stft)
imaginary_part = np.imag(stft)
# 幅度谱
ax_1 = plt.subplot(2, 2, 1)
plt.pcolormesh(times, frequencies, 10 * np.log10(amplitude ** 2 + 1e-8), cmap='jet')
plt.colorbar(format='%+2.0f dB')
plt.ylabel('Frequency [kHz]')
plt.xlabel('Time [sec]')
plt.title('Amplitude Spectrum')
# 相位谱
ax_2 = plt.subplot(2, 2, 2)
plt.pcolormesh(times, frequencies, phase, cmap='jet')
plt.colorbar(format='%+2.0f dB')
plt.ylabel('Frequency [kHz]')
plt.xlabel('Time [sec]')
plt.title('Phase Spectrum')
# 实数谱
ax_3 = plt.subplot(2, 2, 3)
plt.pcolormesh(times, frequencies, 10 * np.log10(real_part ** 2 + 1e-8), cmap='jet')
plt.colorbar(format='%+2.0f dB')
plt.ylabel('Frequency [kHz]')
plt.xlabel('Time [sec]')
plt.title('Real Part Spectrum')
# 虚数谱
ax_4 = plt.subplot(2, 2, 4)
plt.pcolormesh(times, frequencies, 10 * np.log10(imaginary_part ** 2 + 1e-8), cmap='jet')
plt.colorbar(format='%+2.0f dB')
plt.ylabel('Frequency [kHz]')
plt.xlabel('Time [sec]')
plt.title('Imaginary Part Spectrum')
# https://blog.csdn.net/monotonomo/article/details/83826621
def formatnum(x, pos):
return '$%d$' % (x / 1000)
formatter = FuncFormatter(formatnum)
ax_1.yaxis.set_major_formatter(formatter)
ax_2.yaxis.set_major_formatter(formatter)
ax_3.yaxis.set_major_formatter(formatter)
ax_4.yaxis.set_major_formatter(formatter)
plt.tight_layout()
plt.show()
画频谱图的API函数(随便选一个都可以哈):
plt.specgram(audio, Fs=fs, scale_by_freq=True, sides='default', cmap="jet")
plt.pcolormesh(times, frequencies, LogMag, cmap='jet')
plt.imshow(LogMag, cmap='jet', aspect='auto', origin='lower')
librosa.display.specshow(LogMag, y_axis='linear', x_axis='time', cmap='jet')增益单位dB
dB衡量一个数大小的单位,具体计算方法如下: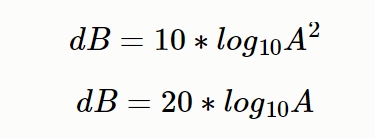
案例:

平均功率: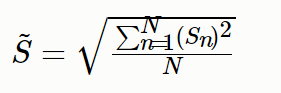
求语音的音量表示有两种表示方法:
方法一:基于语音最大峰值的dBFS
def max_dbfs(sample_data):
# 基于样本最大能量峰值的dBFS
rms = max(abs(np.min(sample_data)), abs(np.max(sample_data)))
dbfs = 20.0 * math.log10(max(1e-16, rms))
return dbfs方法二:基于语音平方根(平均功率)的dBFS
def mean_dbfs(sample_data):
rms = math.sqrt(np.mean(np.square(sample_data, dtype=np.float64)))
dbfs = 20.0 * math.log10(max(1e-16, rms)) + 3.0103
return dbfs声压级
作为音频从业人员,经常说:“大街上能到50分贝啊”,“你们新出的耳机降噪能达到35分贝啊”,“在30分贝下,声音质量...”,等等,他们说的分贝是怎么计算的呢呢?
分贝(decibel)主要用于度量声音强度,常用dB表示。音频中常用分贝来做计量单位,但是dB在不同领域有不同的物理意义,即便是在音频中,分贝也有着不同的含义。如信噪比也用dB。声压级计算公式为:

其中P是待测声压,\(P_{ref}\)是参考声压,一般取\(2e^{-5}\)pa,这个数值是正常人耳对1.4m(250Hz)机械波刚刚能觉察其存在的声压值,也就是波长1.4m(250Hz)机械波的最小可听声压,一般讲,低于这一声压值,人耳就再也不能觉察出这个机械波的存在了。显然该可听阈声压的声压级即为零分贝。
专业人士为了准确的表达声压级的概念,在使用dB时会增加一个后缀:SPL, 也就是sound pressure level的缩写,以便明确其物理意义。
再者,我们来看看主动降噪,也就是ANC 的降噪能力的评价方式,我们常常看到蓝牙耳机的宣传,ANC达到35dB啦之类,这是什么意思呢?实际上,这些宣传往往指的是,在整个耳机的频率范围内,开启和关闭主动降噪时,在人耳内部听到的环境声衰减了多少比例。借用信噪比的公示,这里应该是\(10*log_{10}\frac{P开启ANC}{P关闭ANC}\) 。
最后我们看看开头的讨论,第一个显然指的是声压级,第二个是指开启和关闭主动降噪时声音的比例,第三个是指信噪比。
EQ
EQ是均衡器的缩写。它的基本作用是通过对声音某一个或多个频段进行增益或衰减,达到调整音色的目的。当然,EQ还有一个显著的功能,降噪。EQ通常包括如下参数:F(requency),频率――这是用于设定你要进行调整的频率点用的参数;G(ain),增益――用于调整在你设定好的F值上进行增益或衰减的参数;Q(uantize)――用于设定你要进行增益或衰减的频段 “宽度”。
DRC(动态压缩控制)
当输出的音频信号不是很大的时候,系统会按照原来的设定输出,但是当输出的音频信号过大的时候,为了保护喇叭DRC会将输出信号的幅度进行压缩将其限制在一个范围内。因为输出的音频信号过大会引起削峰,从而引起音频失真,并且损坏喇叭,所以需要有DRC的作用来将输出限制在一定的范围内。在信号很小的时候DRC是不会起作用的,只有当输出信号的功率超过了你设定的DRC门限的时候DRC才会工作。
等响度
声音实际响度和人耳实际感受的响度并不完全呈线性关系,在小音量的时候,人耳对中高频的听觉会有生理性衰减,音量越小,这种衰减越明显。等响度控制其作用是在低音量时提升高频和低频成分的音量,使得低、中、高部分的响度比例保持和在大音量时的响度比例相同。等响度控制即满足此要求,等响度控制一般为8dB或10dB。 为了在小音量的时候保持人耳听觉相对大音量时高低频段听觉的等响度效果,有些前级放大器插入了等响度效果电路,原理是在小音量的时候适当提升中高频段放大比例,达到人耳听感的一致性。
3D环绕音
A3D是Aureal Semiconductor开发的一种崭新的互动3D定位音效技术,使用这一技术的软件(特别是游戏)可以根据软件中交互式的场景、声源变化而输出相应变化的音效,产生围绕听者的极其逼真的3D定位音效,带来真实的听觉体验,而这一切只需通过一对普通的音箱或耳机就能实现。
A3D技术与传统做法最大的不同之处,在于它可以只利用一组喇叭或者是耳机,就可以发出逼真的立体声效,定位出环绕使用者身边不同位置的音源。这种音源追踪的能力,就叫做定位音效,它使用当时的HRTF的功能来达到这种神奇的效果。
虚拟低音
由于具有体积小、功耗低、成本低廉的优点,小型扬声器一直是笔记本电脑、智能手机、MP3、MP4等便携式媒体设备必不可少的单元。然而,限于体积小的原因,小型扬声器的低频还原能力较差,满足不了人们对高音质的需求。如何改进小型扬声器的低频音质一直是个热门问题。基于虚拟音调现象的虚拟低音处理技术是一种有效改善小型扬声器低频音质的方法。目前,虚拟低音实现算法主要有两种:VB Phase Vocoder算法和MaxxBass算法。两种方法相比之下,VB Phase Vocoder算法比MassBass算法较为灵活、响度计算较为精确;而且VB Phase Vocoder算法的噪声控制较好,不会产生像MaxxBass算法中的非线性失真。
变音
变声模块主要实现变声功能:如娃娃音、怪兽音、男变女、女变男。
AEC
回声消除器(Acoustic Echo Chancellor),AEC可以消除各种延迟的回声。)。AEC是对扬声器信号与由它产生的多路径回声的相关性为基础,建立远端信号的语音模型(高斯模型),利用它对回声进行估计,并不断地修改滤波器的系数,使得估计值更加逼近真实的回声。然后,将回声估计值从话筒的输入信号中减去,从而达到消除回声的目的,AEC还将话筒的输入与扬声器过去的值相比较,从而消除延长延迟的多次反射的声学回声。根椐存储器存放的过去的扬声器的输出值的多少,AEC可以消除各种延迟的回声。
AGC
自动增益补偿功能(Automatic Gain Control),AGC可以自动调麦克风的收音量,使与会者收到一定的音量水平,不会因发言者与麦克风的距离改变时,声音有忽大忽小声的缺点。
ANS
背景噪音抑制功能(Automatic Noise Suppression),ANS可探测出背景固定频率的杂音并消除背景噪音,例如:风扇、空调声自动滤除。呈现出与会者清晰的声音。
数学基础
欧拉公式:\(e^{\pm ix}=\cos(x)\pm i\sin(x)\)
FFT变换:\(X(k)=\sum_{n=0}^{N-1}x(n)e^{-j\frac{2\pi kn}{N}}\)
移位:设某一序列\(x(n)\),当m>0 时,\(x(n-m)\)表示序列\(x(n)\)逐项依次延时(右移)m 位。(左加右减)
翻褶:设某一序列\(x(n)\),则\(x(-n)\)是以n=0 的纵轴为对称轴将\(x(n)\)加以翻褶。
和:\(z(n)=x(n)+y(n)\)
积:\(z(n)=x(n)·y(n)\)
累加:\(y(n)=\sum_{k=-\infty}^{n}x(k)\)
差分 (一阶):\(y(n)=x(n)-x(n-1)\)
线性卷积 (linear convolution) : \(y(n)=\sum_{m=-\infty}^{\infty} x(m) h(n-m)=x(n) * h(n)\)
由卷积的定义可知,卷积在图形表示上可分为四步:翻褶、移位、相乘、相加。

\(x_n\)的长度为\(N_1\),\(h(n)\)的长度为\(N_2\),卷积之后信号\(y(n)\)的长度为\(N_1+N_2-1\)
线性卷积的应用:模拟远场数据
近讲纯净语音信号卷积一个房间冲击响应(RIR)=远场语音信号(带有混响)
圆周移位 (circular shift) :\(x_{m}(n)=x((n+m))_{N} R_{N}(n)\)
其中,\(x((n+m))_N\)表示\(x(n)\)经过周期( N )延拓后的序列,再移位m,\(R_N(n)\)为取主值序列:
圆周卷积 (circular convolution):
如果\(x_1(n)\)和\(x_2(n)\)都是长度为 N 的有限长序列\(0\leq n\leq N-1\),并且\(\left\{\begin{matrix}D F T\left[x_{1}(n)\right]=X_{1}(k)\\ D F T\left[x_{2}(n)\right]=X_{2}(k)\end{matrix}\right.\)则\(x_1(n)\)和\(x_2(n)\)的圆周卷积定义为:
结论:在时域的圆周卷积相当于在频域这两个傅里叶变换的乘积
注意:与线性卷积相比,圆周卷积多了 周期延拓 和 取主值序列 两个步骤。因此必须指定圆周卷积的点数 N 。
圆周卷积和线性卷积的关系
圆周卷积:
线性卷积:
给定两个有限长序列\(x_1(n)\)和\(x_2(n)\),他们的长度分别为:\(N_1=5\),\(N_2=3\)。相应的取值如下图,我们重点研究\(0\leq n\leq N-1\)这个区间内,线性卷积和圆周卷积的关系。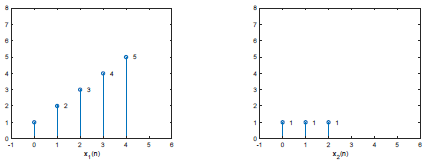
一般的,如果两个有限长序列的长度为\(N_1\)和\(N_2\),且满足\(N_1\geq N_2\),则圆周卷积的后\(N_1-N_2+1\)个点,与线性卷积的结果一致。
线性相关(linear correlation) :\(r_{x y}(m)=\sum_{n=-\infty}^{\infty} x(n) y^{*}(n-m)\)
圆周相关(circular correlation):
如果:\(R_{x y}(k)=X(k) Y^{*}(k)\)
则\(x(n)\)和\(y(n)\)的圆周相关定义为:
圆周相关和线性相关的关系线:一般的,如果两个有限长序列的长度为\(N_1\)和\(N_2\),且满足\(N_1\geq N_2\),则有圆周相关的前\(N_1-N_2+1\)个点,与线性相关的结果一致。
复数知识
复数\(D(F,T)\)的几种表示形式:
实部、虚部(直角坐标系):a+bj (\(a\)是实部,\(b\)是虚部)
幅值、相位(指数系):\(re^{j\theta }\) (\(r\)是幅值,\(\theta\)是相角(弧度),\(e^{j\theta }\)是相位)
极坐标表示法:\(r\angle \theta\)
指数系\(<-->\)指数坐标系:\(re^{j\theta }=r(cos\theta+jsin\theta)=rcos\theta+jrsin\theta\)
实部:\(a=rcos\theta\), real = np.real(D(F, T))
虚部:\(b=rsin\theta\), imag= np.imag(D(F, T))
幅值:\(r=\sqrt{a^2+b^2}\), magnitude = np.abs(D(F, T)) 或 magnitude = np.sqrt(real**2+imag**2)
相角(以弧度为单位rad):\(\theta=tan^{-1}(\frac{b}{a})\)或 \(\theta=atan2(b,a)\)。 angle = np.angle(D(F, T))
相角(以角度为单位deg):\(deg = rad*\frac{180}{\pi}\),\(\text{rad2deg}(\text{atan2}(b,a))\)。 deg = rad * 180/np.pi
相位: phase = np.exp(1j * np.angle(D(F, T)))
离散傅里叶变换的几个问题
对连续信号进行STFT处理,等价于截取一段时间信号,对齐进行周期性延拓,从而变成无限长序列,并对该无限长序列做FFT变换,这一截断并不符合FFT的定义。因此会导致 频谱泄漏 和 频谱混叠。
频谱泄漏
频谱泄漏是指由于信号截断造成的原始信号频谱扩散现象,信号的截断相当于在原始信号\(x(n)\)与一个窗函数\(w(n)\)相乘,在频域中相当于各自频谱的卷积过程。卷积的结果造成原始信号频谱的“扩散”(或拖尾、变宽),导致幅度较小的频点淹没在幅度较大的频点泄漏分量中。
频谱混叠
频谱混叠会在分段处引入虚假的峰值,进而不能获得准确的频谱情况
减少频谱泄漏和混叠的方法
- 加窗,选择合适的窗函数
- 选择更长的窗长
栅栏效应Z
因为DFT 计算频谱只限制在离散点上的频谱,也就是\(F_0\)的整数倍处的谱,而无法看到连续频谱函数,这就像通过一个“栅栏”观看景象一样,只能在离散点的地方看到真实景象。这种现象称为“栅栏效应”。
减小栅栏效应的方法就是要是频域抽样更密,即增加频域抽样点数,就好像距离“栅栏”的距离边远一些。在不改变时域信号的情况下,必然是在时域信号末端 补零 。补零后的时域数据,在频谱中的谱线更密,原来看不到的谱分量就有可能看到了。
语音信号DFT的共轭对称性
时域中的语音信号,经过离散傅里叶变换DFT后的频谱是共轭对称的。
本文转载自作者:凌逆战,地址:https://www.cnblogs.com/LXP-Never/p/10619759.html



![[JAVA] 图书管理系统](https://img-blog.csdnimg.cn/223a6a44ba4748198162d26952c70ec9.png)